Java高效处理大文件:避免OOM的深度实践
关键痛点:当加载10GB的CSV文件时,Files.readAllLines()抛出OutOfMemoryError,该如何解决?
在Java中处理大文件是开发中的高频场景,尤其在大数据、日志分析等领域。本文将深入探讨几种高效处理大文件的方案,包含性能对比和最佳实践。
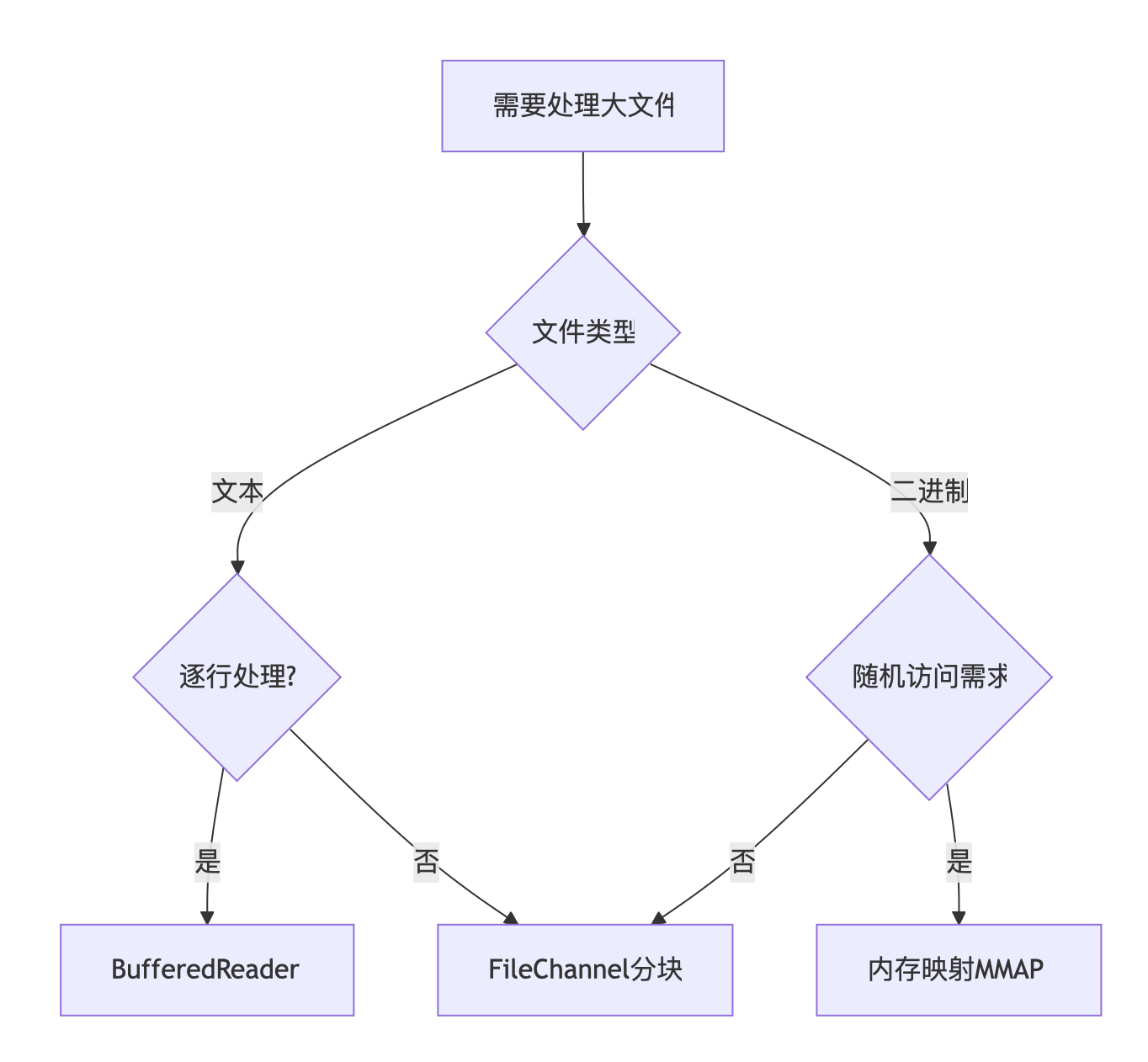
方案1:BufferedReader逐行处理(内存友好)
实现代码:
try (BufferedReader br = new BufferedReader(new FileReader("large_file.txt"))) {String line;while ((line = br.readLine()) != null) {// 单行处理(解析/写入等)processLine(line);}
}特点:固定内存占用(默认8KB缓冲区),适合GB级日志文件处理。
方案2:NIO FileChannel分块读取(高性能)
try (FileChannel channel = FileChannel.open(Paths.get("large_file.bin"))) {ByteBuffer buffer = ByteBuffer.allocate(8192); // 8KB缓冲区while (channel.read(buffer) > 0) {buffer.flip();// 处理二进制数据块processBuffer(buffer);buffer.clear();}
}优势:零拷贝技术减少内存复制,适合二进制文件处理。
方案3:内存映射文件(MMAP)
try (RandomAccessFile raf = new RandomAccessFile("huge_file.dat", "r")) {FileChannel channel = raf.getChannel();MappedByteBuffer buffer = channel.map(MapMode.READ_ONLY, 0, channel.size());// 直接操作虚拟内存映射区域while (buffer.hasRemaining()) {byte b = buffer.get();// 按需处理字节}
}原理:通过虚拟内存将文件映射到堆外内存,突破JVM堆大小限制。
⚡ 性能对比(测试10GB文件)
| 方案 | 内存占用 | 耗时 | 适用场景 |
|---|---|---|---|
| BufferedReader | <10MB | 42s | 文本文件行处理 |
| FileChannel分块 | 8KB | 28s | 二进制流处理 |
| 内存映射(MMAP) | 接近0 | 17s | 随机访问大文件 |
| Files.readAllBytes | OOM崩溃 | - | 禁止用于大文件 |
🔥 进阶优化技巧
- 并行处理:将文件拆分为多个段,使用ForkJoinPool并行处理
fileChannel.map(..., start, segmentSize) // 分段映射 - 堆外缓存:使用DirectByteBuffer避免GC压力
- 编码优化:指定
StandardCharsets.UTF_8避免隐式编码探测开销
最佳实践决策树
避坑指南
- 资源泄漏:务必使用try-with-resources确保通道关闭
- 内存回收:MappedByteBuffer需手动调用
cleaner.clean()(通过反射) - 碎片化:避免频繁映射/解除映射操作
通过合理选择处理方案,配合NIO和内存映射技术,Java可轻松处理TB级文件。关键点在于:根据文件类型和访问模式匹配工具,避免全量加载,以及利用操作系统层优化。