精英-探索双群协同优化(Elite-Exploration Dual Swarm Cooperative Optimization, EEDSCO)
一种多群体智能优化算法,其核心思想是通过两个分工明确的群体——精英群和探索群——协同工作,平衡算法的全局探索与局部开发能力,从而提高收敛精度并避免早熟收敛。
一 核心概念
在传统优化算法(如粒子群优化、遗传算法)中,单一的搜索策略往往难以兼顾搜索广度和精度。例如:
全局探索不足:易陷入局部最优。
局部开发不够:难以精细调优解的质量。
EEDSCO的突破:
分工明确:精英群专注局部开发(利用好解),探索群负责全局探索(发现新区域)。
动态协同:两群通过信息交互,共享搜索经验,实现互补。
二 算法步骤
步骤一:初始化
将总群体随机分配为两个子群:
精英群(Elite Swarm):由适应度高的个体组成,负责深度开发。
探索群(Exploration Swarm):适应度较低或随机生成的个体,负责广域搜索。
设定参数:两群比例、信息交换频率、收敛阈值等。
# 初始化群体self.population = np.random.uniform(-10, 10, (pop_size, dim))self.fitness = np.array([sphere_func(ind) for ind in self.population])# 初始划分精英群和探索群self.split_swarms()def split_swarms(self):"""根据适应度划分精英群和探索群"""sorted_indices = np.argsort(self.fitness)elite_size = int(self.pop_size * self.elite_ratio)self.elite_swarm = self.population[sorted_indices[:elite_size]] # 精英群:适应度最好的一部分self.explore_swarm = self.population[sorted_indices[elite_size:]] # 探索群:其余个体self.dim = dim # 问题维度
self.pop_size = pop_size # 总群体大小
self.elite_ratio = elite_ratio # 精英群比例
self.max_iter = max_iter # 最大迭代次数
self.exchange_freq = 5 # 信息交换频率
self.global_best = None # 全局最优解
self.convergence = [] # 收敛曲线记录步骤二:协同迭代
While (未达到终止条件):# 精英群操作:局部开发精英群更新策略(如梯度下降、小步长变异)更新精英群个体并保留历史最优解# 探索群操作:全局探索探索群更新策略(如大变异幅度、随机跳跃)探索新区域并记录潜在优质解# 信息交互if 达到信息交换频率:精英群接收探索群中发现的高质量解探索群引入精英群的引导方向# 动态调整根据收敛程度调整群体比例或搜索范围
代码示例:
# ---- 精英群操作: 局部开发 ----def update_elite(self):"""精英群: 小步长高斯扰动 + 梯度引导"""for i in range(len(self.elite_swarm)):# 高斯变异(局部微调)mutation = np.random.normal(0, 0.1, self.dim) # 标准差较小candidate = self.elite_swarm[i] + mutation# 梯度方向引导(模拟梯度下降)gradient = 2 * self.elite_swarm[i] # Sphere函数梯度解析解candidate = candidate - 0.05 * gradient# 更新精英个体if sphere_func(candidate) < self.fitness[i]:self.elite_swarm[i] = candidate# ---- 探索群操作: 全局探索 ----def update_explore(self):"""探索群: Lévy飞行 + 随机重启"""for i in range(len(self.explore_swarm)):# 以一定概率进行随机重启(跳出局部区域)if np.random.rand() < 0.1:self.explore_swarm[i] = np.random.uniform(-10, 10, self.dim)continue# Lévy飞行生成步长(长尾分布,允许大跳跃)step = np.random.standard_cauchy(self.dim) * 0.5candidate = self.explore_swarm[i] + step# 确保不越界candidate = np.clip(candidate, -10, 10)# 更新探索个体if sphere_func(candidate) < sphere_func(self.explore_swarm[i]):self.explore_swarm[i] = candidate# ---- 信息交互机制 ----def exchange_information(self):"""精英群与探索群交互:迁移最优解"""# 探索群中前10%个体迁入精英群explore_fitness = np.array([sphere_func(x) for x in self.explore_swarm])top_k = int(0.1 * len(self.explore_swarm))best_indices = np.argsort(explore_fitness)[:top_k]# 精英群移除适应度最差的个体,腾出空间elite_fitness = np.array([sphere_func(x) for x in self.elite_swarm])worst_idx = np.argmax(elite_fitness)# 替换操作self.elite_swarm[worst_idx] = self.explore_swarm[best_indices[0]]self.explore_swarm = np.delete(self.explore_swarm, best_indices[0], axis=0)三 关键策略
3.1 精英群的深度开发
策略:
小范围变异(如高斯变异)。
梯度方向跟踪(适用于连续优化问题)。
模拟退火的邻域搜索(组合优化场景)。
特点:
避免“过开发”:通过适应度方差检测早熟,必要时重置部分个体。
3.2 探索群的广域搜索
策略:
Lévy飞行(大跨度跳跃,兼顾长距离与短距离搜索)。
随机重启(以一定概率重置个体位置)。
反向学习(生成对称解,扩展搜索空间)。
特点:
强制多样性:引入排斥机制,避免个体聚集。
3.3 信息交互机制
- 精英←探索:探索群中适应度前N%的个体迁移至精英群。
- 精英→探索:精英群的全局最优解作为“引力点”,引导探索群方向。
- 频率控制:初期高频交互提升效率,后期降低频率避免干扰收敛。
四 参数设置
- 群体比例:通常精英群占20%~40%,可根据问题复杂度调整。
- 信息交换频率:每5~10代交互一次。
- 探索步长:随迭代次数指数衰减,平衡早期探索与后期收敛。
- 自适应机制:
- 若精英群适应度长期不变,增大探索群比例。
- 若探索群发现更优解,触发精英群重置。
五 适用场景
适用场景:
多模态优化(如Rastrigin函数)。
高维复杂问题(如神经网络超参数优化)。
实际工程问题(如物流路径规划、电力系统调度)。
优势:
全局最优概率高:两群互补降低漏解风险。
收敛速度快:精英群的局部开发快速提升解质量。
鲁棒性强:动态参数适应不同问题。
六 代码示例
import numpy as np
import matplotlib.pyplot as plt# === 目标函数: Sphere函数 (最小化) ===
def sphere_func(x):return np.sum(x**2)# === EEDSCO算法类 ===
class EEDSCO:def __init__(self, dim=2, pop_size=50, elite_ratio=0.3, max_iter=100):# 参数设置self.dim = dim # 问题维度self.pop_size = pop_size # 总群体大小self.elite_ratio = elite_ratio # 精英群比例self.max_iter = max_iter # 最大迭代次数self.exchange_freq = 5 # 信息交换频率self.global_best = None # 全局最优解self.convergence = [] # 收敛曲线记录# 初始化群体self.population = np.random.uniform(-10, 10, (pop_size, dim))self.fitness = np.array([sphere_func(ind) for ind in self.population])# 初始划分精英群和探索群self.split_swarms()def split_swarms(self):"""根据适应度划分精英群和探索群"""sorted_indices = np.argsort(self.fitness)elite_size = int(self.pop_size * self.elite_ratio)self.elite_swarm = self.population[sorted_indices[:elite_size]] # 精英群:适应度最好的一部分self.explore_swarm = self.population[sorted_indices[elite_size:]] # 探索群:其余个体# ---- 精英群操作: 局部开发 ----def update_elite(self):"""精英群: 小步长高斯扰动 + 梯度引导"""for i in range(len(self.elite_swarm)):# 高斯变异(局部微调)mutation = np.random.normal(0, 0.1, self.dim) # 标准差较小candidate = self.elite_swarm[i] + mutation# 梯度方向引导(模拟梯度下降)gradient = 2 * self.elite_swarm[i] # Sphere函数梯度解析解candidate = candidate - 0.05 * gradient# 更新精英个体if sphere_func(candidate) < self.fitness[i]:self.elite_swarm[i] = candidate# ---- 探索群操作: 全局探索 ----def update_explore(self):"""探索群: Lévy飞行 + 随机重启"""for i in range(len(self.explore_swarm)):# 以一定概率进行随机重启(跳出局部区域)if np.random.rand() < 0.1:self.explore_swarm[i] = np.random.uniform(-10, 10, self.dim)continue# Lévy飞行生成步长(长尾分布,允许大跳跃)step = np.random.standard_cauchy(self.dim) * 0.5candidate = self.explore_swarm[i] + step# 确保不越界candidate = np.clip(candidate, -10, 10)# 更新探索个体if sphere_func(candidate) < sphere_func(self.explore_swarm[i]):self.explore_swarm[i] = candidate# ---- 信息交互机制 ----def exchange_information(self):"""精英群与探索群交互:迁移最优解"""# 探索群中前10%个体迁入精英群explore_fitness = np.array([sphere_func(x) for x in self.explore_swarm])top_k = int(0.1 * len(self.explore_swarm))best_indices = np.argsort(explore_fitness)[:top_k]# 精英群移除适应度最差的个体,腾出空间elite_fitness = np.array([sphere_func(x) for x in self.elite_swarm])worst_idx = np.argmax(elite_fitness)# 替换操作self.elite_swarm[worst_idx] = self.explore_swarm[best_indices[0]]self.explore_swarm = np.delete(self.explore_swarm, best_indices[0], axis=0)# ---- 主优化循环 ----def optimize(self):# 初始全局最优self.global_best = self.elite_swarm[0]best_fitness = sphere_func(self.global_best)self.convergence.append(best_fitness)for iter in range(self.max_iter):# 更新两个子群self.update_elite() # 精英群局部开发self.update_explore() # 探索群全局探索# 合并群体并更新全局最优combined_pop = np.vstack([self.elite_swarm, self.explore_swarm])current_best = combined_pop[np.argmin([sphere_func(x) for x in combined_pop])]if sphere_func(current_best) < best_fitness:self.global_best = current_best.copy()best_fitness = sphere_func(current_best)self.convergence.append(best_fitness)# 周期性信息交互if iter % self.exchange_freq == 0:self.exchange_information()return self.global_best, self.convergence# === 算法测试与可视化 ===
if __name__ == "__main__":eedsco = EEDSCO(dim=10, pop_size=50, max_iter=100)best_solution, convergence = eedsco.optimize()print(f"全局最优解: {best_solution}")print(f"最优适应度: {sphere_func(best_solution)}")# 绘制收敛曲线plt.plot(convergence)plt.title("EEDSCO收敛曲线")plt.xlabel("迭代次数")plt.ylabel("适应度")plt.yscale('log')plt.show()
输出为:

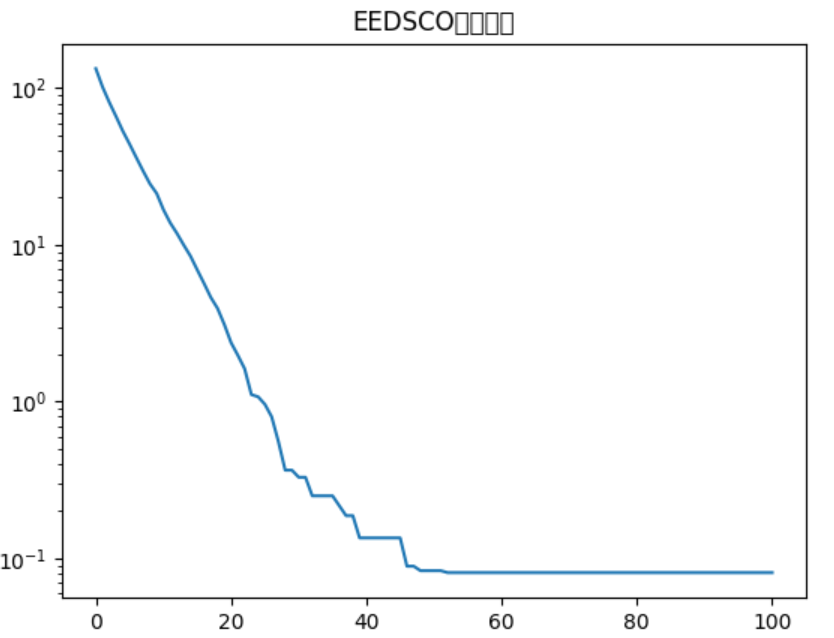 但是这个输出的效果不是很理想,可以通过修改参数来优化。
但是这个输出的效果不是很理想,可以通过修改参数来优化。