【火山引擎 大模型批量处理数据教程-详细】
相关的文档
!!先注册账号第一步!!
- 批量处理文档
- 费用接口
- 对象存储地址
- 提交批量处理网页
1. 准备jsonl数据集
- 官网网页地址
- 样例,需要根据你自己的数据进行需改
import jsonsystem_prompt = """
你的任务是根据用户提供的药品名称,规格参数以及治疗的疾病名称,返回该药品的使用方式、使用频次、使用量!认真、仔细阅读以下任务信息,保质保量完成任务!## 返回示例
1. 必须按此药品的规格配置做计量的基本单位
2. 如果可能用片、粒等基本单位,则必须使用
3. 如果只有ul、ml等液体类型的剂量,则用对应的剂量- 例子1
口服,1日1次,1次3粒- 例子2
皮下注射,1日1次,1次30IU## 返回格式
<使用方式>,<使用频次>,<使用量>!必须是返回上述格式,否则会解析出错
""".strip()huoshan_data_jsonl = [[{"custom_id": f"{cid}-{idx}", # 必须唯一"body": {"messages": [{"role": "system", "content": system_prompt},{"role": "user","content": f"药品名称:{d[0]}\n规格:{d[1]}/{d[2]}\n疾病名称:{di}",},],"temperature": 0.0,},}for idx, di in enumerate(d[3:])]for d, cid in zip(data, ruuid_gen())
]
huoshan_data_jsonl = sum(huoshan_data_jsonl, [])with open("hs_data.jsonl", "w", encoding="utf-8") as f:for d in huoshan_data_jsonl:f.write(json.dumps(d, ensure_ascii=False) + "\n")len(huoshan_data_jsonl), huoshan_data_jsonl[0]
- 检查数据是否符合规定
import jsondef check_jsonl_file(file_path):with open(file_path, "r", encoding="utf-8") as file:total = 0custom_id_set = set()for line in file:if line.strip() == "":continuetry:line_dict = json.loads(line)except json.decoder.JSONDecodeError:raise Exception(f"批量推理输入文件格式错误,第{total + 1}行非json数据")if not line_dict.get("custom_id"):raise Exception(f"批量推理输入文件格式错误,第{total + 1}行custom_id不存在")if not isinstance(line_dict.get("custom_id"), str):raise Exception(f"批量推理输入文件格式错误, 第{total + 1}行custom_id不是string")if line_dict.get("custom_id") in custom_id_set:raise Exception(f"批量推理输入文件格式错误,custom_id={line_dict.get('custom_id', '')}存在重复")else:custom_id_set.add(line_dict.get("custom_id"))if not isinstance(line_dict.get("body", ""), dict):raise Exception(f"批量推理输入文件格式错误,custom_id={line_dict.get('custom_id', '')}的body非json字符串")total += 1return totalfile_path = "hs_data.jsonl"
total_lines = check_jsonl_file(file_path)
print(f"文件中有效JSON数据的行数为: {total_lines}")
2. 创建桶 【必须,存储数据】
- 官网地址
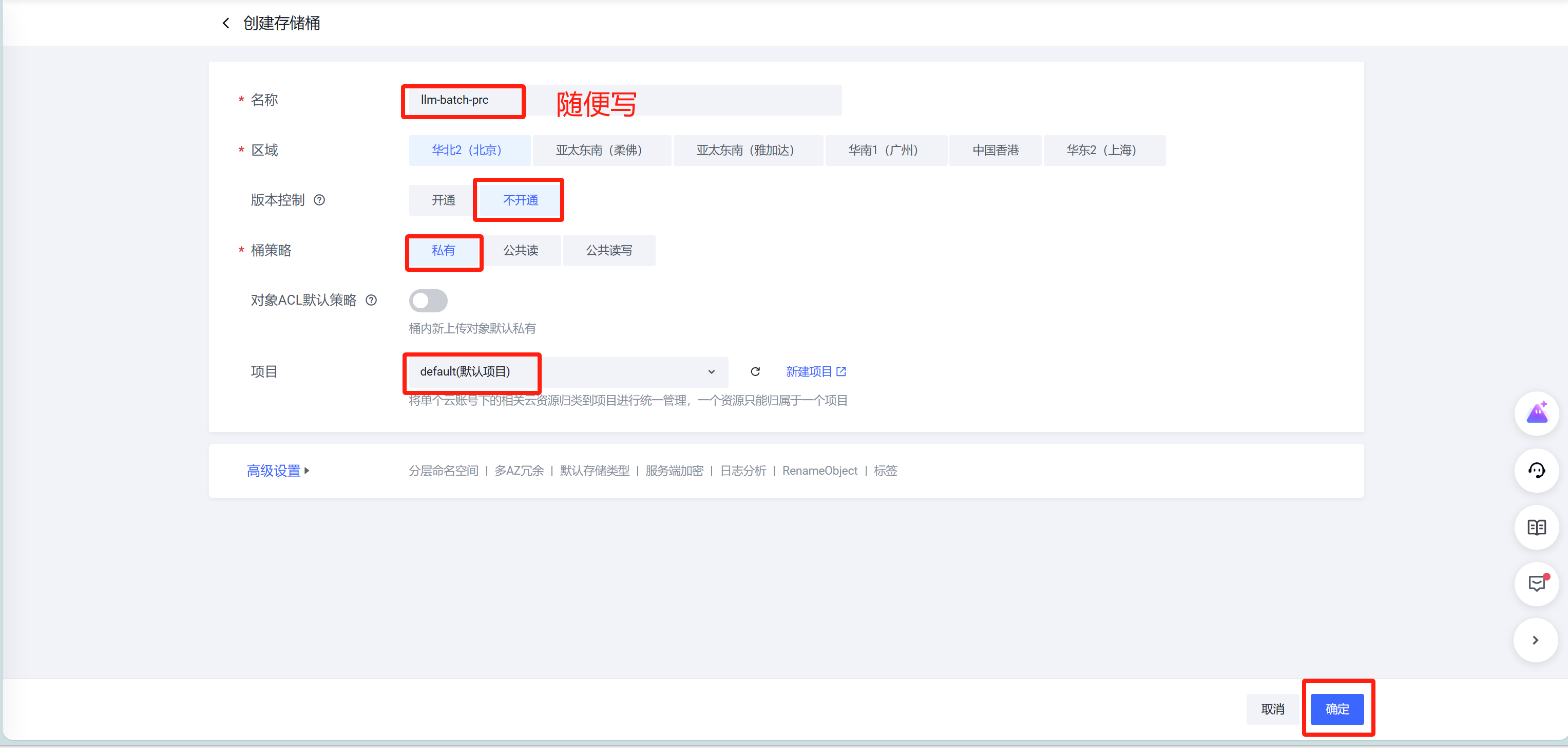



3. 开始批量处理
- 官网地址
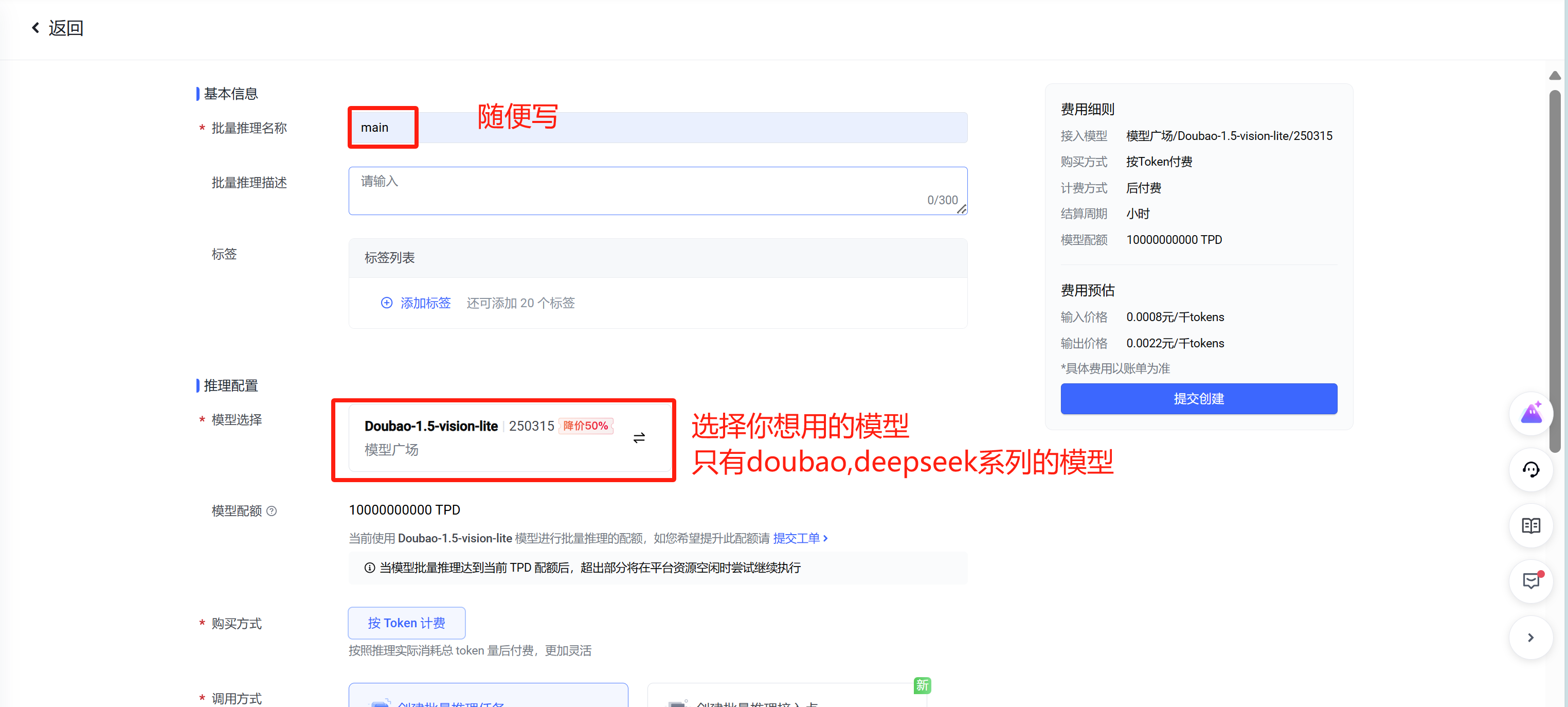
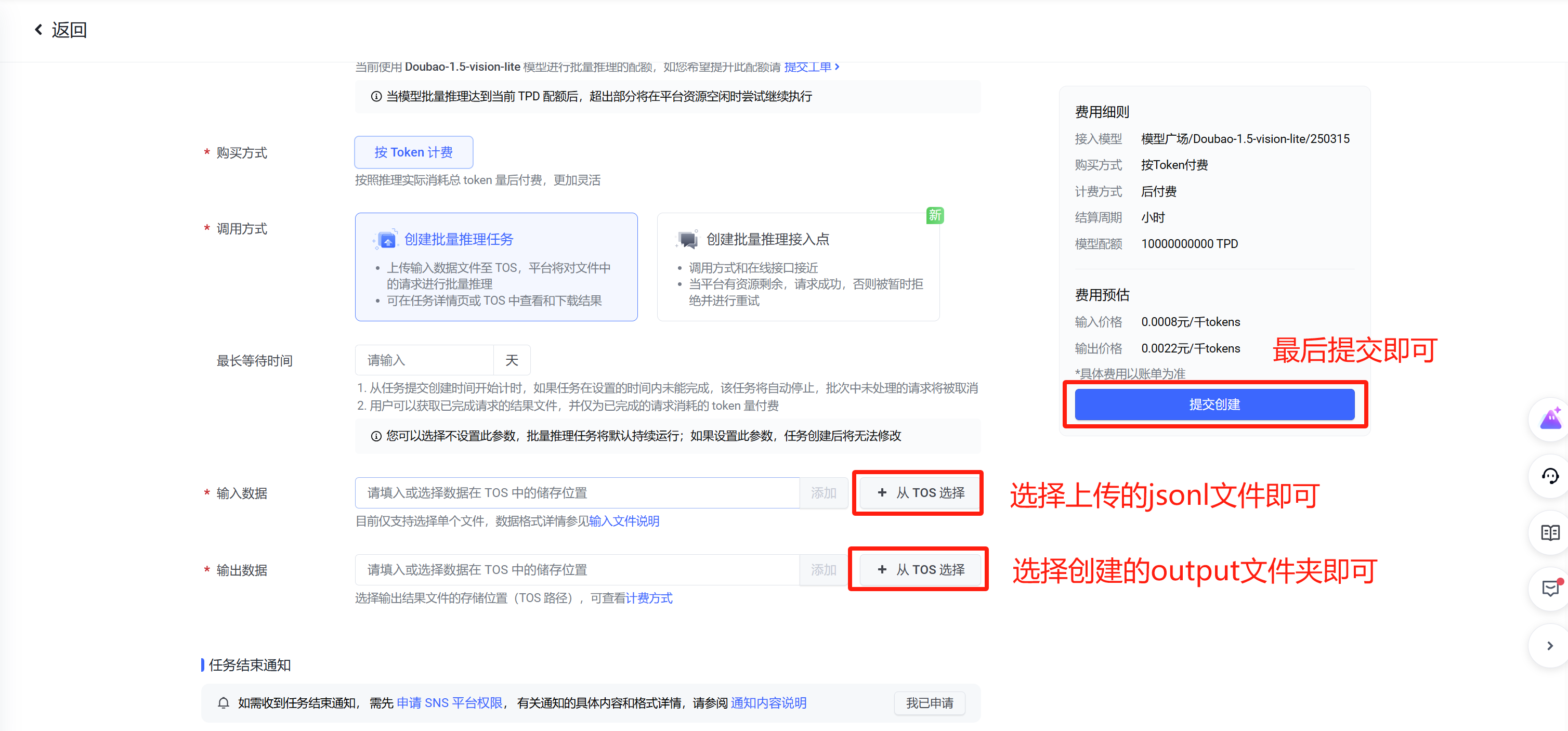
4. 最后【一定看!】
官网地址
- 处理完后,及时下载结果,然后删除你后创建的桶,是收费的!!
- 处理完后,及时下载结果,然后删除你后创建的桶,是收费的!!
- 处理完后,及时下载结果,然后删除你后创建的桶,是收费的!!