LLMTIME: 不用微调!如何用大模型玩转时间序列预测?
今天是端午节,端午安康!值此传统佳节之际,我想和大家分享一篇关于基于大语言模型的时序预测算法——LLMTIME。随着人工智能技术的飞速发展,利用大型预训练语言模型(LLM)进行时间序列预测成为一个新兴且极具潜力的研究方向。LLMTIME通过将数值数据转化为文本格式,借助语言模型强大的模式学习能力,实现了对复杂时间序列的高效预测和不确定性建模。
接下来,我将深入对这篇论文展开全面解读。和以往一样,我会严格依照论文的结构框架,从研究背景、核心论点、实验设计到最终结论,逐一对文章的各个关键部分进行细致剖析 ,力求为大家呈现这篇时间序列预测论文的全貌,挖掘其中的研究价值与创新点。
1. Abstract
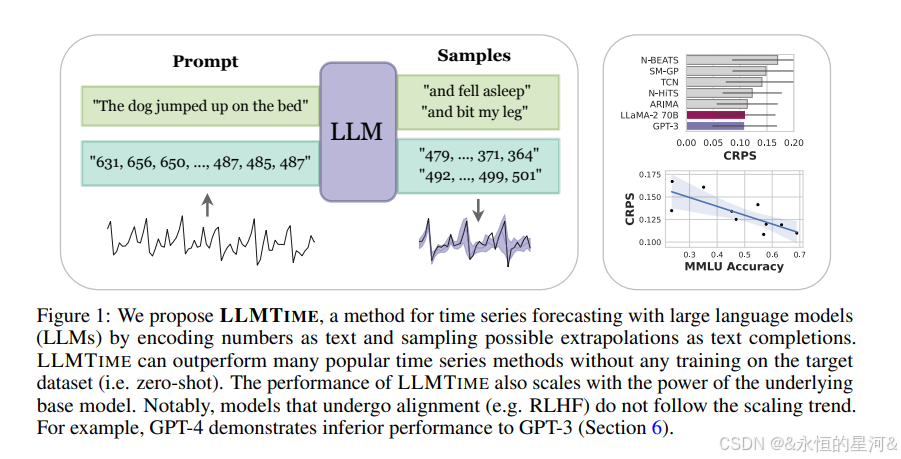
通过将时间序列编码为数字字符串,可以将时间序列预测重新表述为文本中的“下一个 token 预测”问题。在这一思路基础上,本文发现大型语言模型(LLMs),如 GPT-3 和 LLaMA-2,竟然能够在零样本(zero-shot)条件下进行时间序列外推,其表现与为下游任务专门设计的时间序列模型相当,甚至更优。为了实现这种性能,提出了一些方法,用于有效地对时间序列数据进行 token 化,并将模型输出的离散 token 分布转化为对连续数值的高灵活度密度分布。作者认为,LLMs 在时间序列任务中取得成功,源于它们能够自然表示多峰分布(multimodal distributions),以及它们在训练中表现出的对简洁性和重复性的偏好——这正与许多时间序列中的显著特征(如周期性趋势的重复)高度一致。作者还展示了 LLMs 如何无需插值就能自然地处理缺失数据(通过非数值文本进行处理),如何融合文本型辅助信息,以及如何通过问答形式解释预测结果。虽然发现模型规模的增加通常会带来时间序列任务性能的提升,但也观察到 GPT-4 的表现可能低于 GPT-3,原因包括其对数字的 token 化方式不理想,以及其不佳的不确定性校准能力。这些问题可能是由于诸如强化学习人类反馈(RLHF)等对齐干预所造成的。
2. Introduction
尽管与其他序列建模问题(如文本、音频或视频)存在相似之处,时间序列具有两个特别具有挑战性的属性。与视频或音频通常具有一致的输入尺度和采样率不同,聚合的时间序列数据集通常包含来自截然不同来源的序列,有时还存在缺失值。此外,时间序列预测的常见应用,例如天气或金融数据,需要从仅包含极少部分可能信息的观测中进行外推,这使得准确的点预测几乎不可能,而不确定性估计则尤为重要。尽管大规模预训练已成为视觉和文本中训练大型神经网络的关键要素,使性能能够直接随着数据可用性扩展而提高,但在时间序列建模中通常并不使用预训练,因为缺乏共识的无监督目标以及缺少大型、统一的预训练数据集。因此,在一些流行的基准测试中,简单的时
完整文章链接:LLMTIME: 不用微调!如何用大模型玩转时间序列预测?