近期手上的一个基于Function Grap(类AWS的Lambda)小项目的改造引发的思考
函数式Function是云计算里最近几年流行起来的新的架构和模式,因为它不依赖云主机,非常轻量,按需使用,甚至是免费使用,特别适合哪种数据同步,数据转发,本身不需要保存数据的业务场景,或者通过一个输入转换或者变化,处理以后流转到下一个输出。
我们刚好有这样的业务,云云对接,把一个储能云的数据,经过接口查询以后,转换后保存到我们的私有云平台上(内部是微软提供的IoT平台底座)。
但是在实际开发中发现了有两个痛点,
触发方式,云厂商一般会提供2个方式,
1.基于事件的调用,比如Python语言的固定式的函数,比如
def handler(event, context)
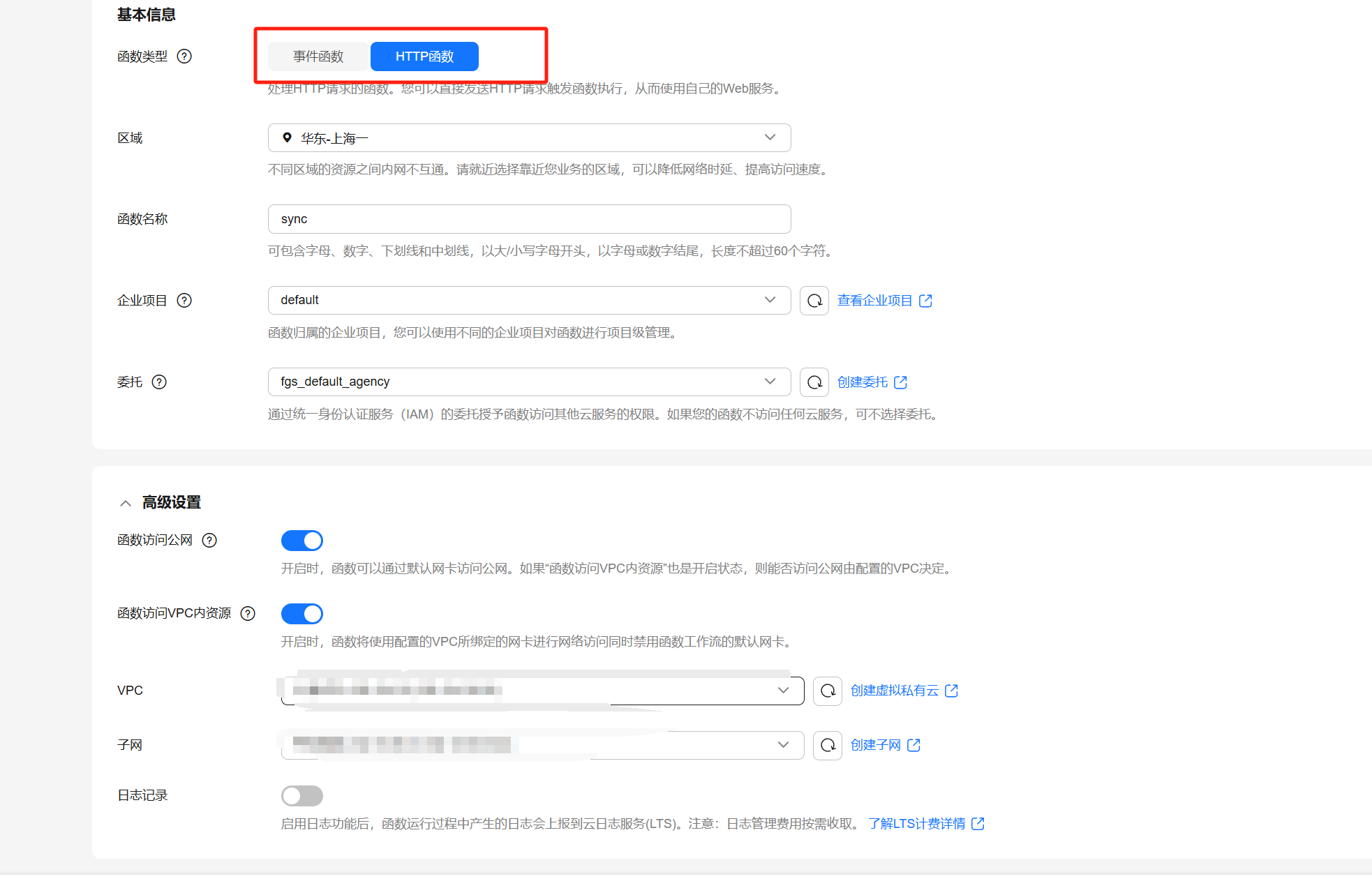
,函数名和内存占用,网络设置等配置,这里有一个重要的设置就是触发器,
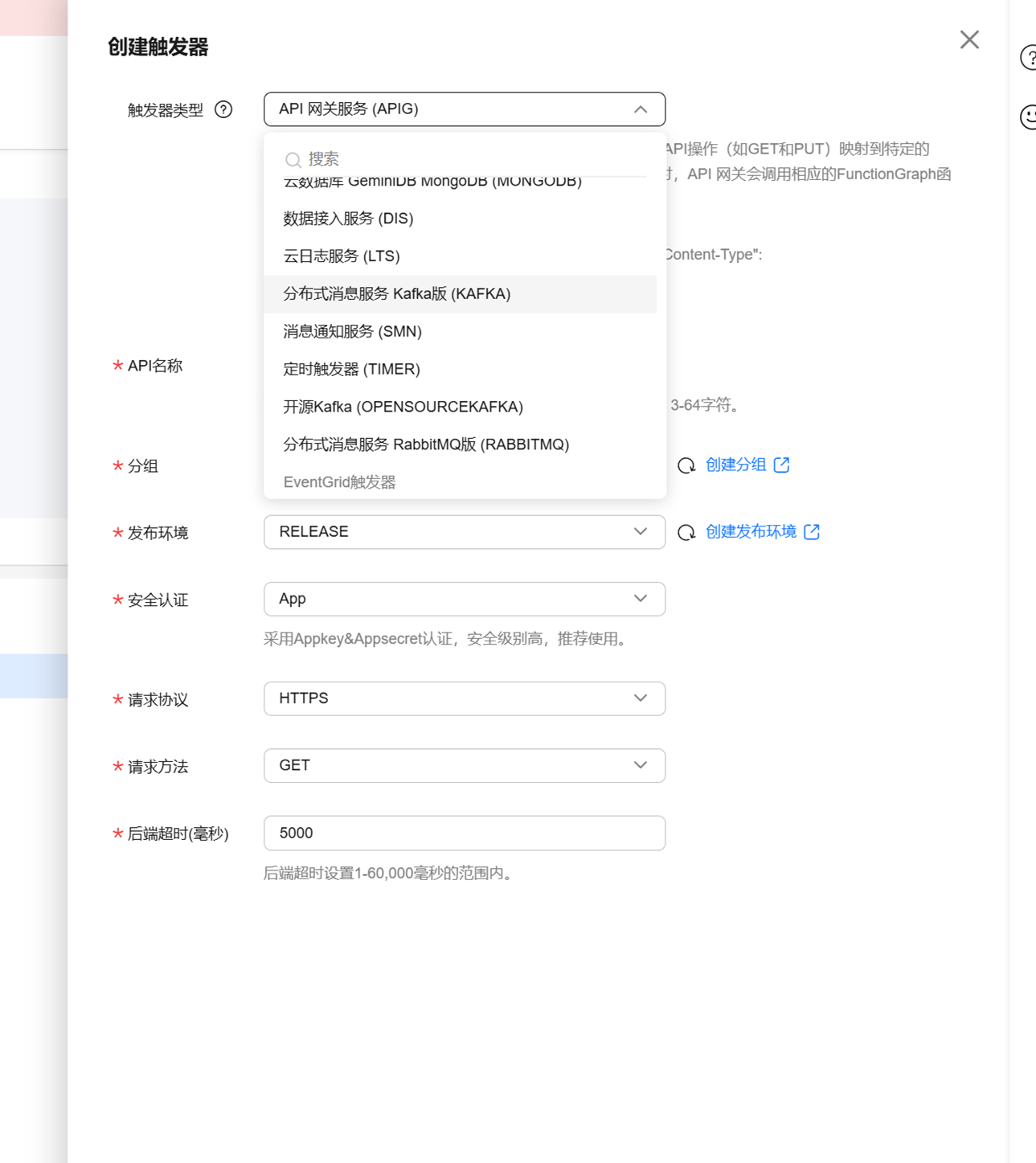
一般最常用的是定时触发器:
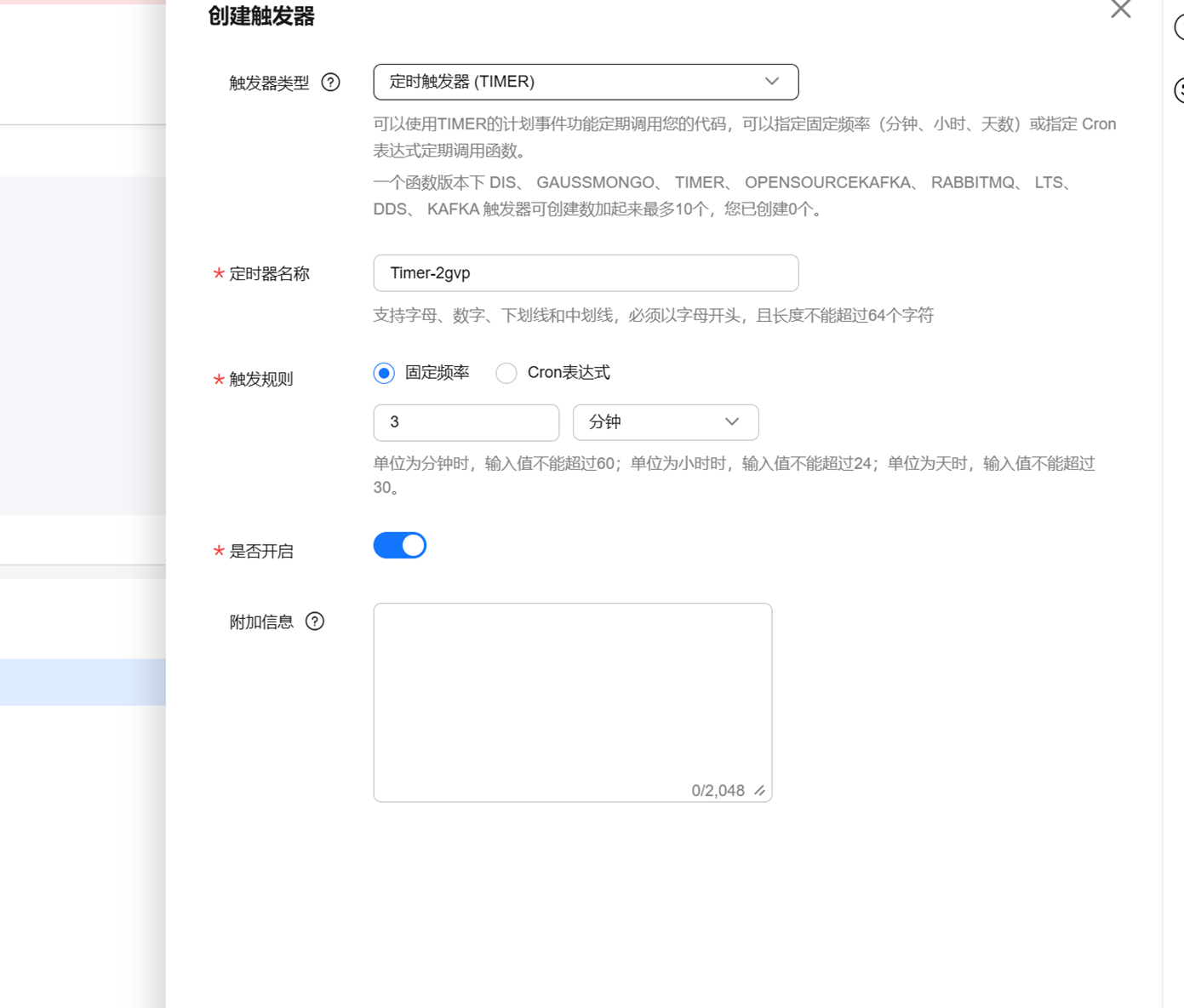
当你编写好以后,在云平台上直接点击运行测试,云平台会调用你的这个handler,你也可以通过参数event, context 获取运行时的一些数据。如果是简单任务,只需要在这里调用你的业务代码就开发完成。
一切都很自然,这里的定时器,相当于linux里的cronjob, 最后运行的python ss.py 这样的方式会导致每次启动都会把代码重新执行一遍,但是如果你的业务要求严格的话,希望这个程序运行了以后一直不退出,在程序内部运行Schedule,这样的好处会节省调用方的资源,比如代码需要访问MQ,每隔3分钟程序重新执行的时候,会频繁得创建TCP连接。会给MQ broker的连接创造一定的压力,我刚好遇到了对方投诉我们占用了他们的连接资源。所以我需要改造程序,让程序一直不退出的方式,复用创建好的连接。一共经历了3次优化
- 修改代码,创建一个全局的Connection对象,然后在handler里直接写while True的方式执行,发现云平台给的handler函数,有个限制,如果超时没有返回,平台强制终止程序,可以在日志里查看到,程序超时被终止。这条路走不通
- 不改架构使用异步,handler里启动一个线程,在线程里while True,后来发现执行一段时间后,效果并不好。
通过Schedule包,顺便说一下,Python竟然没有一个特别强大的定时器,非常不好用,想这样, import schedule schedule.every(3).minutes.do(job1)需要设置好了以后,还需要 if __name __ =="__main__": schedule.run_pending()为了防止程序退出还有在主线程里写上while True: time.sleep(5) 或者类似这样的代码
import time
import threadingdef background_task():print("后台任务开始")time.sleep(5) # 模拟长时间任务print("后台任务完成")def handler(event, context):print("收到请求")def delayed_run():time.sleep(0.1)background_task()thread = threading.Thread(target=delayed_run)thread.start()# 主线程故意睡一会儿,防止函数提前退出time.sleep(6)return {"statusCode": 200, "body": "已尝试启动后台任务"}这样恶心的代码,非常的不优雅。
3. 改动架构,使用彻底异步
- 使用redis的发布订阅模式(或者其他MQ),把启动和执行分开。在执行同步的代码里,handler里把连接建立好,就等待redis的消息通知,代码如下:
- def handler(event, context):
- localtime = time.asctime(time.localtime(time.time()))
- print(f"execution at {localtime}.")
- startConn()
- start_redis_listener()
- print("??",client)
- return {"statusCode": 200, "isBase64Encoded": False, "headers": {"Content-Type": "application/json;charset=UTF-8"},
- "body": "sucess"}
这样非常优雅,如下:- def sync_data():
- print("开始执行耗时的数据同步任务...")
- print(client)
- try:
- while True:
- time.sleep(5)
- print("开始处理站点列表")
- for conf in configLs:
- print(f"开始处理站点: {conf.station_name} 数据")
- site = AccessSite(conf)
- site.publish_mqtt()
- # msg = msg + f"{conf.station_name}"
- print("成功处理站点数据至能源平台!")
- except Exception as e:
- print("同步出错:", str(e))
- # Redis 订阅客户端
- def start_redis_listener():
- pubsub = redisClient.pubsub()
- pubsub.subscribe(["stored_energy_sync_channel"])
- print("等待 Redis 消息...")
- for message in pubsub.listen():
- if message['type'] == 'message':
- print(f"收到消息: {message['data'].decode()}")
- if message['data'].decode() == "start_sync":
- sync_data()
至于程序何时启动,只需要在另外一个FG里,通过调用redis的pub接口,把这个sync_data()给启动。
非常的完美,容易维护。而第二个版本,使用线程和使用定时器都无法取得满意的效果。
注意这里的redis还可以替换成Kafka, RocketMQ,或者其他通知SMN, SQS。
2. 还有一个方式是基于http或者https的方式启动任务,方式大同小异,都是一次执行完成以后,需要再次触发才能继续执行。如下图: