Linux(8)——进程(控制篇——上)

目录
编辑
一、进程创建
1.fork函数的回顾
2.fork的返回值
3.写时拷贝
4.fork的常规用法
5.fork调用失败的原因
二、进程终止
1.进程退出的场景
2.进程常见的退出方法
3.进程退出码
4.进程正常退出
1)_exit函数
2)exit函数
3)return退出
4)进程异常退出
一、进程创建
1.fork函数的回顾
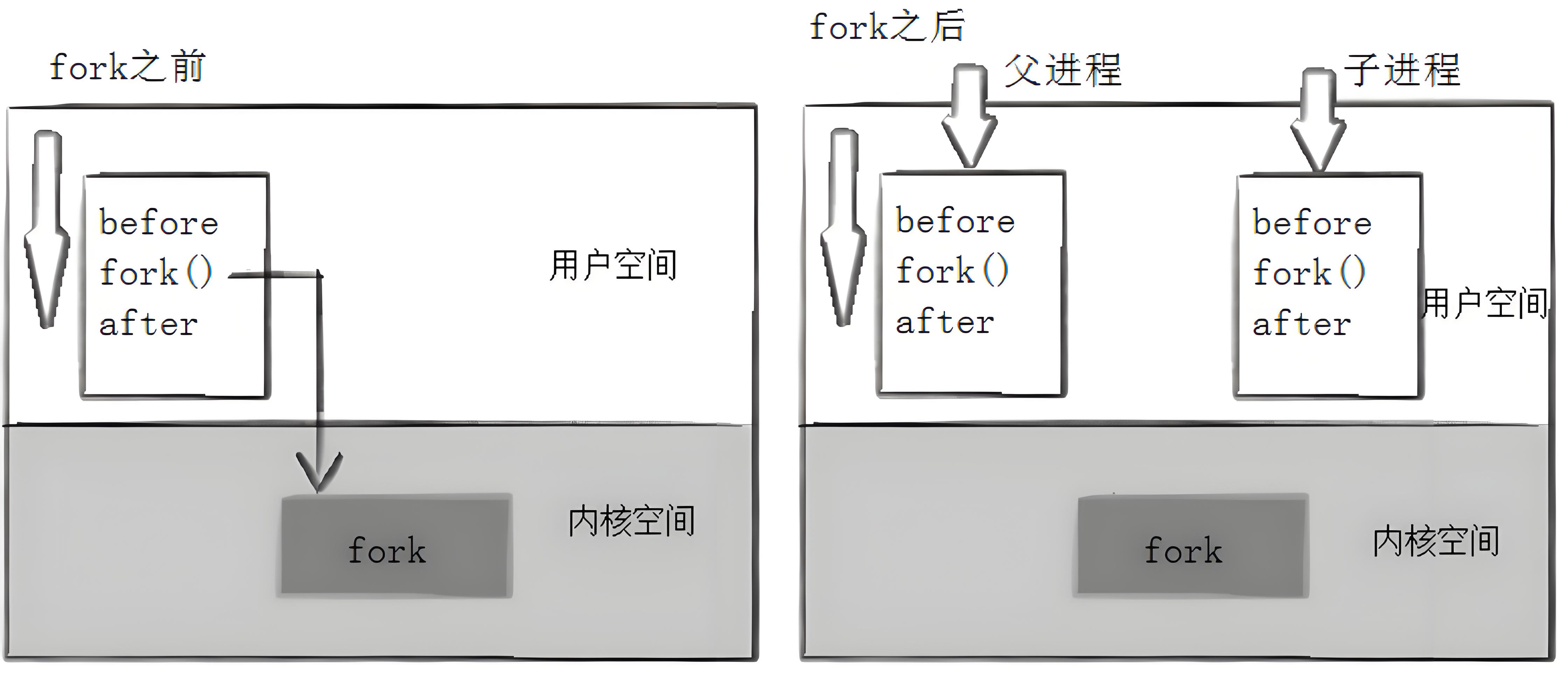
在Linux中fork函数是非常重要的函数,它可以在已经存在的进程中创建一个新的进程,新的进程就是子进程,而创建它的进程就是父进程。
返回值:
在子进程中返回0,在父进程中返回子进程的PID,子进程创建失败返回-1。
进程调用fork函数,当控制转移到内核中的fork代码后,内核会做:
- 分配新的内存块和内核数据给子进程
- 将父进程部分数据结构内容拷贝到子进程中
- 添加子进程到系统进程列表中
- fork返回,开始调度器调度
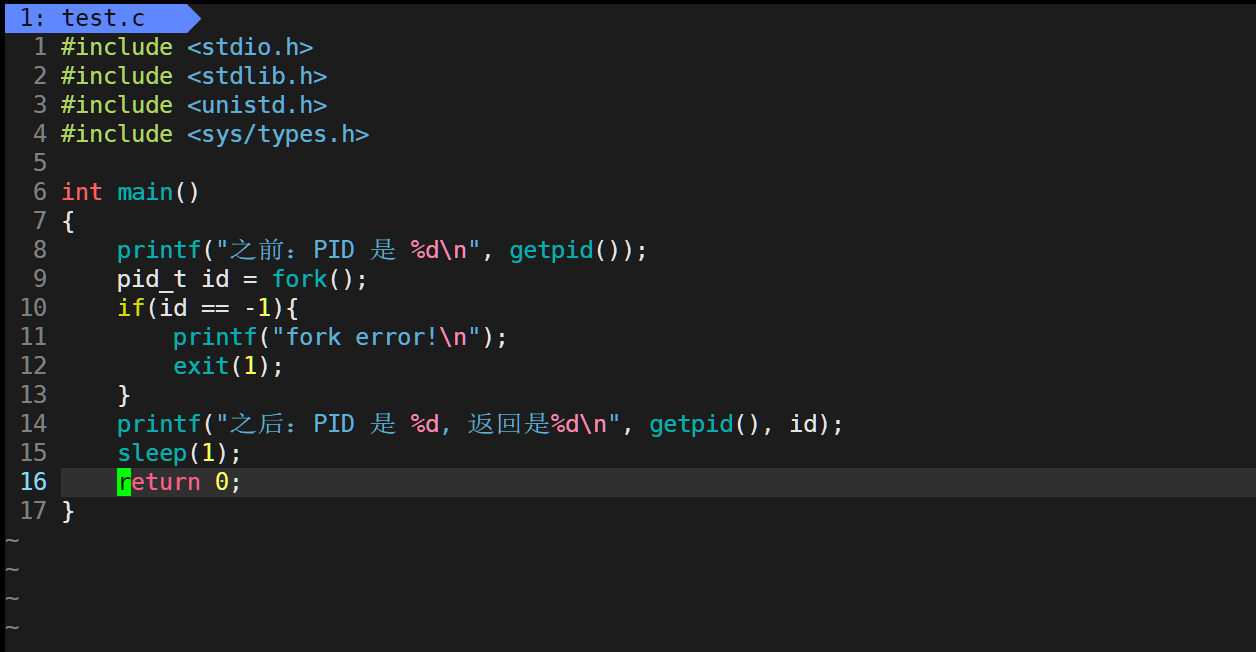
 我们也可以写个代码来验证:
我们也可以写个代码来验证:
运行结果如下:
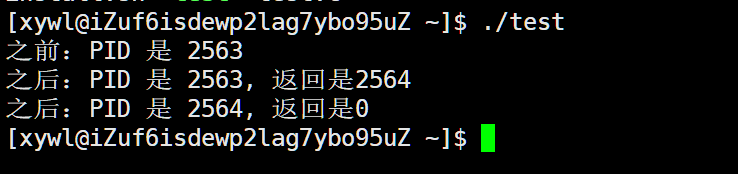 这里可以看见,“之前”出现了一次,而“之后”出现了两次, 这是因为之前属于父进程,而fork之后父子共享代码,也就是父子进程分流执行代码。
这里可以看见,“之前”出现了一次,而“之后”出现了两次, 这是因为之前属于父进程,而fork之后父子共享代码,也就是父子进程分流执行代码。
敲黑板:这里父子进程谁先执行并不是依据我们写出来的代码顺序而是完全由操作系统的调度器决定的。
2.fork的返回值
第一个疑问:
为什么fork函数给子进程返回0,而给父进程返回子进程的PID呢?
答:一个父进程有多个子进程,而子进程只有一个父进程。所以对子进程来说并不用特意标明其父进程,而对于父进程来说得到其子进程的PID是很必要的,因为父进程创建子进程的目的就是让子进程去干活,只有父进程得到了子进程的PID才好给子进程分配任务。
第二个疑问:
为什么fork函数可以有两个返回值?
答:在我的印象里Python是可以的,但是这是C语言。其实我们只有了解了fork函数在执行的时候干了什么才可以明白,其实在fork函数运行时内部创建了子进程的进程控制块,子进程的进程地址空间,子进程对应的页表等等。子进程创建结束后操作系统需要将他的进程控制块放到系统的进程列表中,这样才结束了子进程的创建。
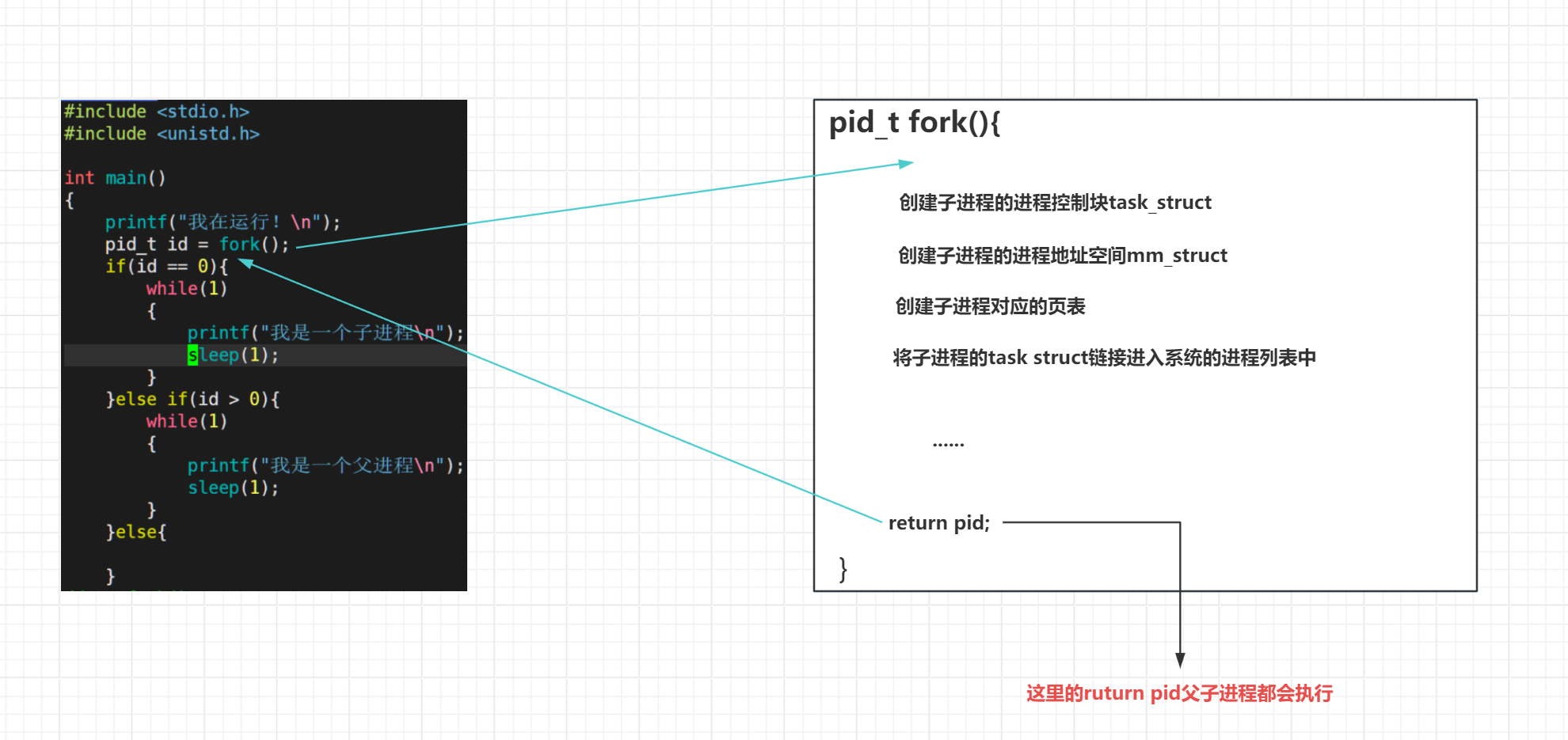 可以从图中看出return语句是在fork创建好子进程之后才生成的,也就是父子进程共享了return语句,所以有了两个返回值。
可以从图中看出return语句是在fork创建好子进程之后才生成的,也就是父子进程共享了return语句,所以有了两个返回值。
3.写时拷贝
父子进程在创建之初,父子进程的代码和数据是共享的,即父子进程的代码和数据通过页表映射到了同一块物理内存,只有当父进程或子进程修改数据时,才将父进程的数据(要修改的)拷贝一份出来,然后进行修改。
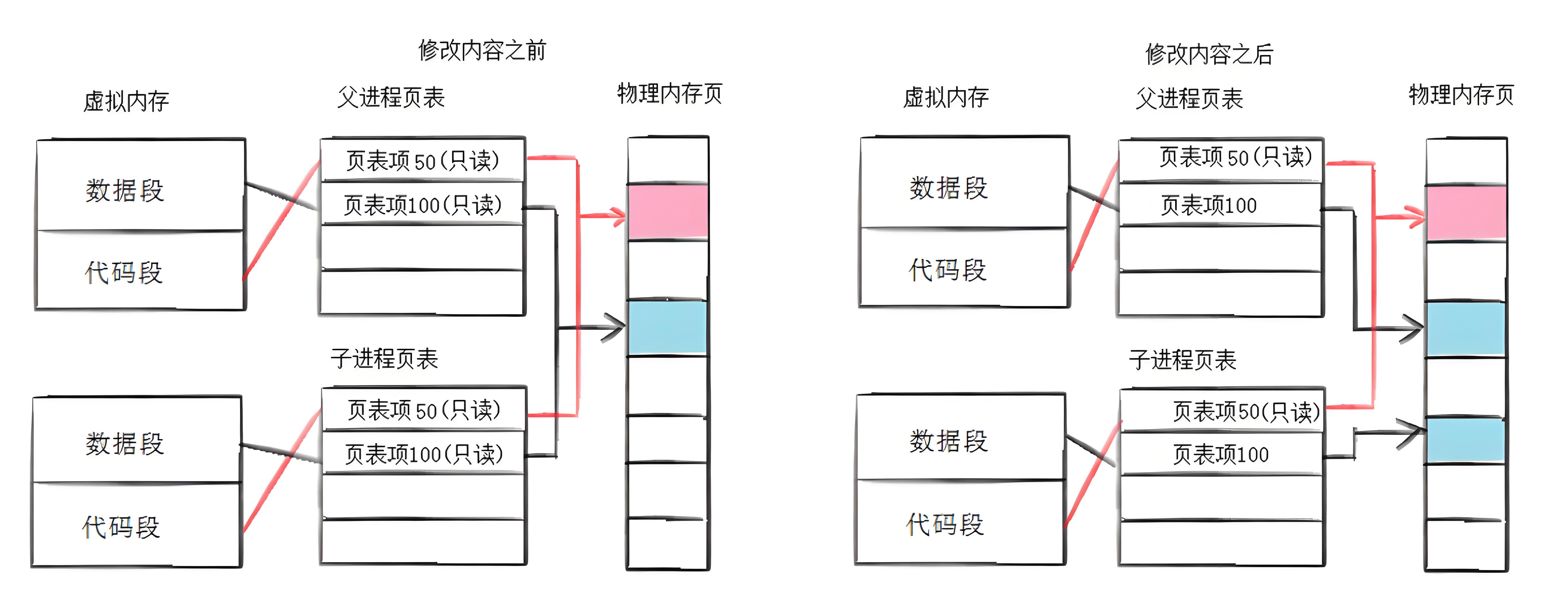
这个在需要时才拷贝数据出来的技术叫写时拷贝。
由此引发了几个问题:
第一问题:
我们为什么要进行写时拷贝呢?
我们知道进程是具有独立性的,多个进程在运行时是独享各种资源的,多进程在运行期间互不干扰,子进程的运行不能影响到父进程。
第二个问题:
为什么不在创建子进程时就进行写时拷贝呢?
我们知道子进程不一定会使用父进程的全部数据,并且在子进程不对数据进行修改时,我们就没有必要对数据进行拷贝,我们应该做到按需分配,在需要修改数据时再进行分配(延时分配),这样就可以高效的使用内存空间。
第三个问题:
我们写的代码会不会写时拷贝呢?
绝大部分的情况是不会的,但也不是说代码就不能进行写时拷贝,例如进程替换时就是需要代码的写时拷贝的。
4.fork的常规用法
- 一个进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
- 一进程要执行一个不同的程序。例如子进程从fork返回后,掉用exec函数。
5.fork调用失败的原因
有以下两种原因:
- 系统中有太多的进程,内存空间不足,子进程创建失败。
- 实际用户的进程超过了限制,子进程创建失败。
二、进程终止
1.进程退出的场景
- 代码运行完毕,结果正确。
- 代码运行完毕,结果不正确。
- 代码异常终止。
2.进程常见的退出方法
正常终止(可以通过echo $?查看进程退出码):
- 1.从main返回
- 2.调用exit
- 3._exit
异常退出:
- ctrl + c,信号终止
3.进程退出码
我们知道main函数是代码的入口,但实际上main函数只是对于用户代码的入口,main函数也是被其他函数调用的,比如在VS2022中,main函数就是被一个名为__tmainCRTStartup的函数调用的,而这个函数又是通过加载器被操作系统调用的,也就是说main函数是间接性被操作系统所调用的。
既然main函数是被操作系统调用的,那么main函数调用结束就要向操作系统返回对应的退出信息,而这个退出信息就是以退出码的形式作为main函数返回的,0代表代码执行成功,非0代表执行过程中出现了错误,这就是为什么我们都在main函数的最后返回0。
我们写个代码来验证一下:
运行一下这个代码,然后通过下面这个命令查看他的退出码信息。
echo $?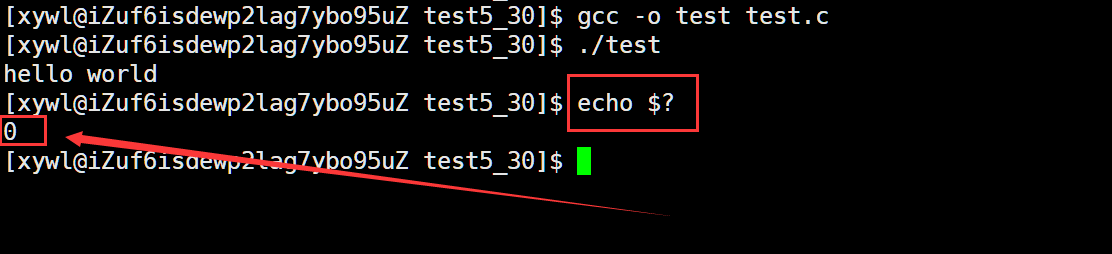 返回的是0,也就是代码成功执行了。
返回的是0,也就是代码成功执行了。
那么我们就会有一个疑问了:
那就是为什么0代表代码执行成功,而非0代表执行过程中出现了错误呢?
因为代码执行成功了就是这一种情况,而代码执行错误就会有多中情况,比如:内存空间不足、栈溢出以及非法访问等,我们就可以采用非0的值来标识代码执行错误的原因了。
在C语言当中strerror函数可以通过错误码来获取对应错误码的错误信息:
运行之后我们就可以看到每个错误码对应的信息(部分):
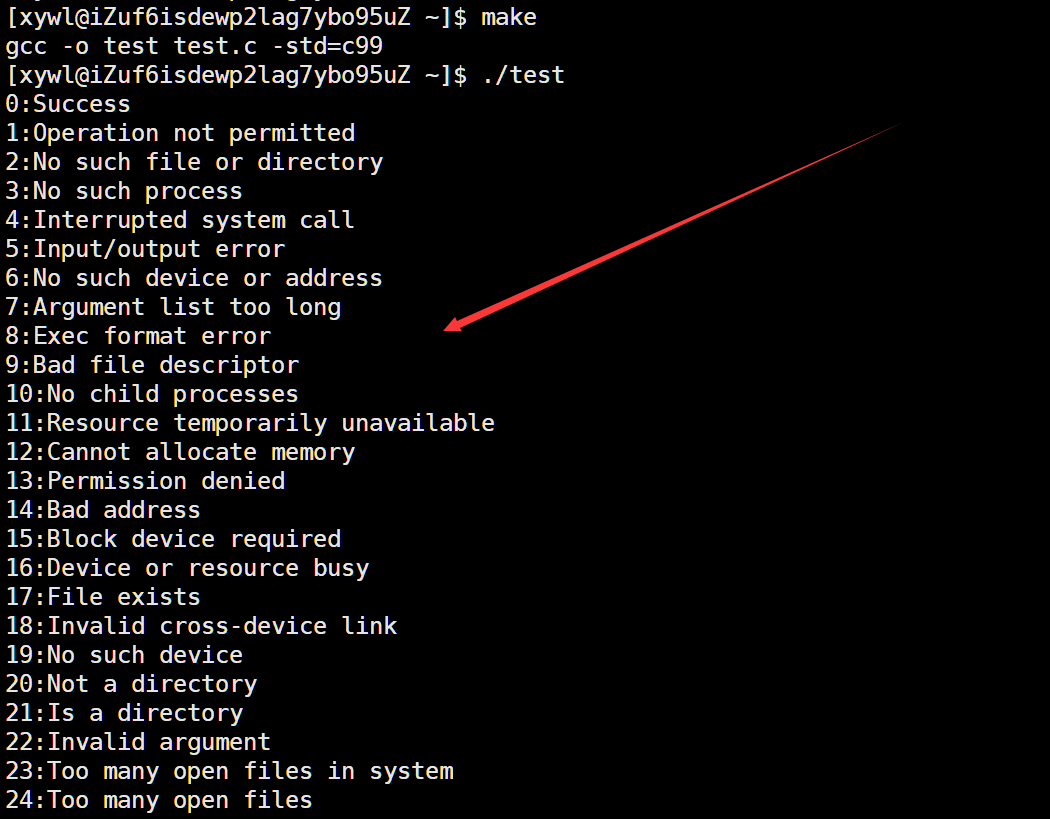
我们知道,在Linux中ls,pwd等命令也都是可执行程序,使用这些程序后应该也都有对应的退出码信息的。
我们可以实验一下:
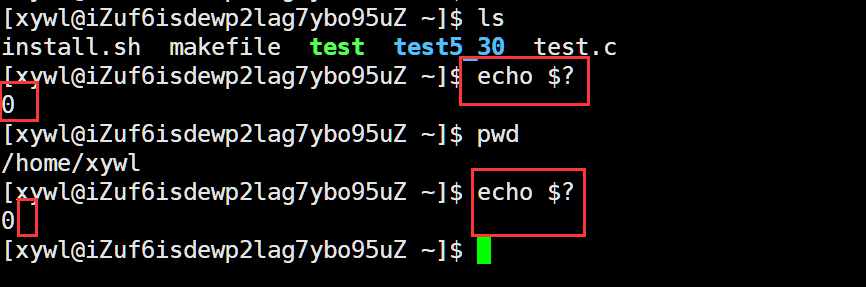 而当我们执行一些错误命令后,返回的退出码就是非0的:
而当我们执行一些错误命令后,返回的退出码就是非0的:
 敲黑板:
敲黑板:
这里的退出码都是对应字符串含义的,而这些含义通常是人来确定的,在不同的环境下这些含义可能是不同的。
4.进程正常退出
1)_exit函数
这个函数在我们写代码时并不多见,_exit函数可在代码的任何位置退出进程,这种退出是不加什么后续操作的退出。
例如,下面的代码执行完_exit函数之后就不会将缓冲区的内容刷新出来:
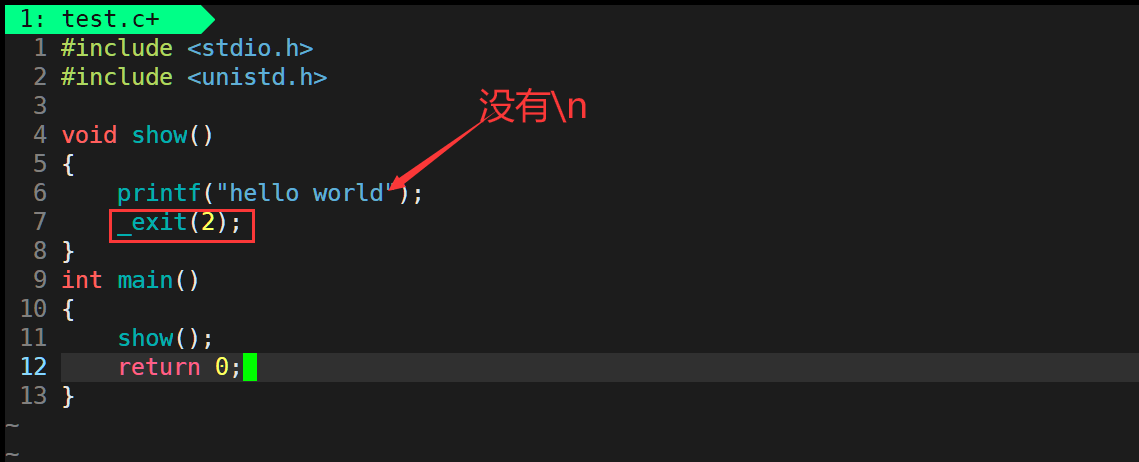
运行结果:

2)exit函数
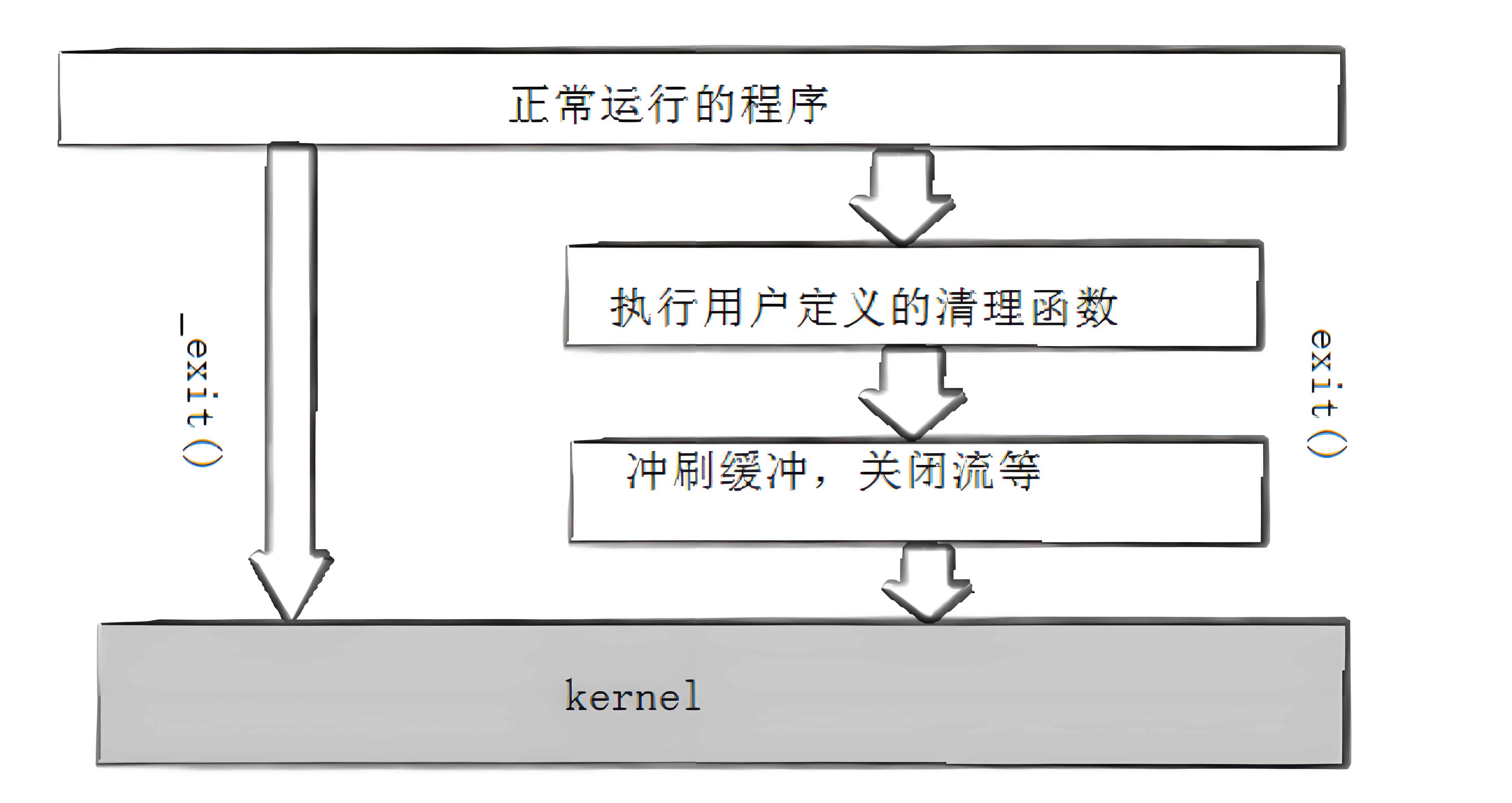
和_exit函数不同的是exit函数不光可以在代码的任何位置退出,退出前还会做一系列的工作:
- 执行用户通过atexit或on _exit定义的清理函数。
- 关闭所有打开的流,所有的缓存数据均被写入
- 调用_exit
例如,下面的代码在执行exit函数时会缓冲区的内容输出:
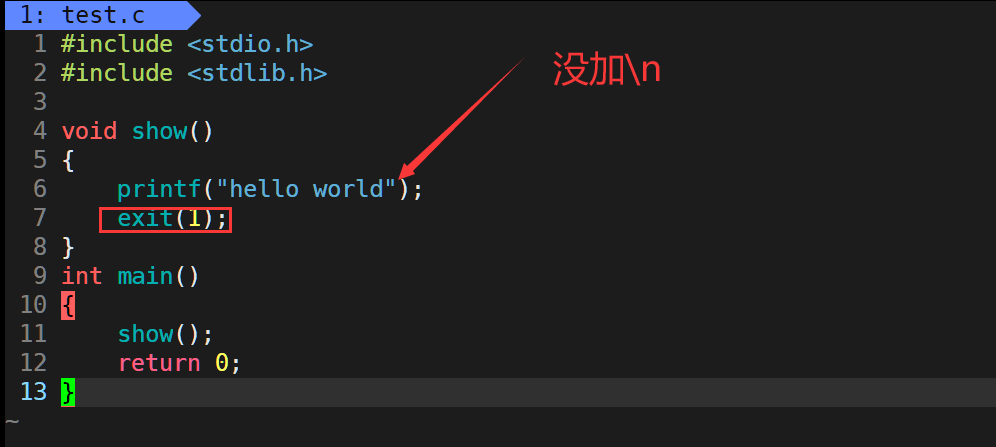
运行结果:

3)return退出
return是一种更常见的退出进程方法。执行return n等同于执行exit(n),因为调用main的运行时函数会将main的返回值当做 exit的参数。
例如,在main函数的最后退出进程:
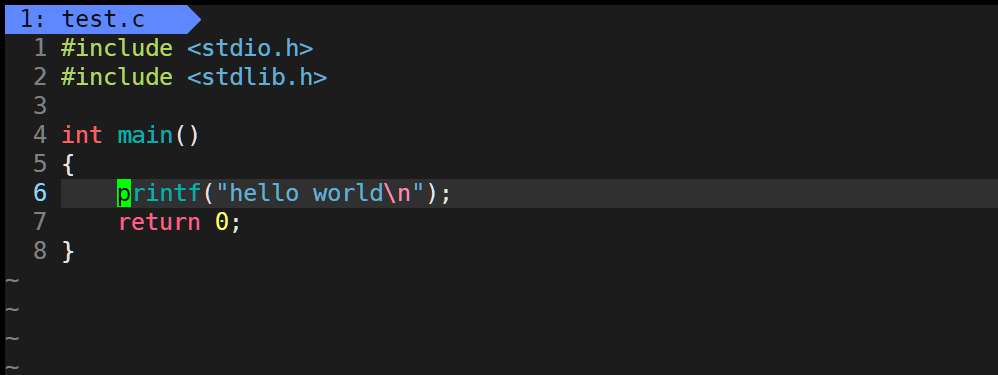

那么我们来总结一下这三个函数的区别与联系:
他们之间的区别:
使用_exit函数和exit函数都可以在代码的任何位置退出进程,而对于return而言,return只有在main函数中才能起到结束进程的作用,在子函数中是没有用的。
使用exit函数退出进程前,exit函数会执行用户自定义的清理、冲刷缓冲,关闭流等操作,然后才是真正的结束进程,而_exit函数会直接终止进程,不会做任何的收尾工作。
他们之间的联系:
执行return num等于执行了exit(num),因为调用main函数运行结束后,会将main函数的返回值当做是exit的参数来调用exit函数。而使用exit函数退出进程之前,exit函数会执行用户定义的清理函数、冲刷缓冲区,关闭流等操作,最后执行_exit函数终止进程。
4)进程异常退出
第一种情况:向进程发出信号使其退出。
例如,在进程运行时发送kill -9信号使其异常退出,或者是Ctrl+C来使得进程异常退出。
第二种情况:代码错误导致进程运行时异常退出。
例如,代码中出现野指针问题导致进程运行时异常退出,或者是出现除0错误时使得进程异常退出。