WWW22-可解释推荐|用于推荐的神经符号描述性规则学习

论文来源:WWW 2022
论文链接:https://web.archive.org/web/20220504023001id_/https://dl.acm.org/doi/pdf/10.1145/3485447.3512042
最近读到一篇神经符号集成的论文24年底TOIS的,神经符号集成是人工智能领域中,将符号推理与深度学习两大范式融合为一体的方法论。其核心目标在于让能够对“逻辑规则”做出明确、可解释推理的符号系统,同时具备对“噪声、非结构化数据”具有鲁棒处理能力的神经网络,得以相互补足,发挥各自优势。NS-ICF是这个方向的代表性工作之一,先讲解这篇。首先说一下神经符号推理和神经符号集成吧,都是致力于提升可解释性的,缓解推荐的黑盒问题。
1 神经符号推理
在推荐系统的研究与实践中,我们长期依赖基于用户-物品交互的深度学习模型来建模偏好。然而,传统神经网络虽能自动提取特征,却很难解释模型为何推荐某个物品。这不仅削弱了用户信任,也限制了系统的调试与监管能力。为解决这一问题,近年来一种新兴范式逐渐受到关注 —— 神经符号推理。神经符号推理是一种融合 符号逻辑系统 与 神经网络表示学习 的方法。它的核心理念是:用逻辑规则表达可解释的推荐偏好,用神经网络学习这些规则的表达与组合方式(两篇论文我都大致看了一下,最重要的就是表达与组合方式,两者有所不同)
在推荐场景中,这种方法不再仅仅关注用户交互 embedding,而是尝试将用户偏好建模为逻辑表达式,如:(偏好:男装 ∧ 羊毛)∨(偏好:冬季 ∧ 大码),也就是说,系统不仅知道用户喜欢某个 item,还能以逻辑因果的方式解释:用户喜欢它是因为它是“男装”和“羊毛”属性的组合。
推荐系统中的“符号”通常基于离散的item 属性、用户标签或上下文信息。
-
属性 A = “男装”
-
属性 B = “羊毛”
-
属性 C = “冬季”
-
属性 D = “大码”
神经符号模型会通过逻辑运算符(如 AND、OR)组合这些属性:
-
AND (∧):用户偏好同时具备 A 和 B 的物品。
-
OR (∨):用户偏好 A 或 B 中的任意一个。
-
NOT (¬):用户不喜欢包含某个属性的物品。
2 神经符号集成
神经符号推理的核心目标,是将逻辑结构编码进神经网络中,使得模型能学习并解释用户的偏好组合规则:首先将 AND、OR 等符号运算 映射为神经网络可学习的算子。例如:
AND 运算的建模方式:![]()
OR 运算的建模方式:![]()
e为属性的嵌入, 每种运算符都有独立的 MLP 参数,把逻辑算子作为一个可学习的运算单元,实现从离散符号到连续空间的映射。
其次要选择用“AND”还是“OR”连接:
例如使用Gumbel-Softmax(TOIS24)或者Soft Controller(WWW22)
流程:属性向量化,属性对选择,逻辑操作建模,逻辑结构构建,生成预测
预测的公式:![]() ,也就是最终生成逻辑操作的embedding和用户的cancat
,也就是最终生成逻辑操作的embedding和用户的cancat
3 动机
推荐系统的可解释性研究大致可分为三个层次:特征级、结果级和模型级,然而:
-
特征级解释主要基于注意力权重或属性贡献度评分,尽管可以揭示个别属性对推荐的影响,但仍高度依赖深度模型中的隐向量表示,缺乏结构化和直观性,用户难以理解推荐背后的真正逻辑。
-
结果级解释则常通过后处理方式(如生成推荐理由)向用户展示“看似合理”的解释,但这些解释往往并未参与模型建模过程,无法反映模型本身的行为或决策依据。
-
模型级解释理应具备端到端的可解释性,即通过观察模型结构或参数即可获得解释(如决策树)。然而推荐系统常采用深度神经网络等复杂结构,这种模型级解释难以实现。即便部分方法尝试利用知识图谱生成推理路径,或借助逻辑规则定义辅助损失函数,仍然无法有效增强模型的整体可解释性。
4 贡献
第一个无需依赖外部资源就能为推荐系统学习逻辑规则的神经符号架构。 将嵌入与提出的神经符号架构融合,不仅实现了个性化的规则权重,而且保留了可解释性。
-
提出了一个神经符号推荐框架 NS-ICF,引入一个三塔结构:分别用于建模用户项目嵌入和属性级的符号组合。该结构通过逻辑表达式的方式显式表示用户对属性组合的偏好,支持生成可解释推荐理由。
-
设计了一个评分监督的表达式构建机制,通过构造逻辑表达式树来组合属性嵌入,学习逻辑结构( conjunction ∧ 和 disjunction ∨)与评分信号的一致性,实现在评分驱动下的表达式学习。
-
提出了一种训练策略和优化目标,使模型可以自动搜索具有良好表示性和可解释性的表达式结构,并保持推荐准确性,无需外部规则或先验知识。
5 Preliminaries
![]() 预测在使用用户和项目的嵌入基础上还使用了属性
预测在使用用户和项目的嵌入基础上还使用了属性
RRL:学习物品属性的逻辑组合规则(逻辑表达式),作为可解释表示。包含:
Binarization Layer(离散化层):将输入的属性值划分为多个区间(年龄、价格得分一下,性别职业不用)
Logical Layers(逻辑层):包含两个类型的节点:和以及与,构造逻辑表达树
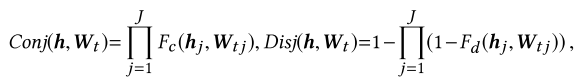
Linear Layer(线性层):每个逻辑规则分配一个权重,做加权组合
6 模型
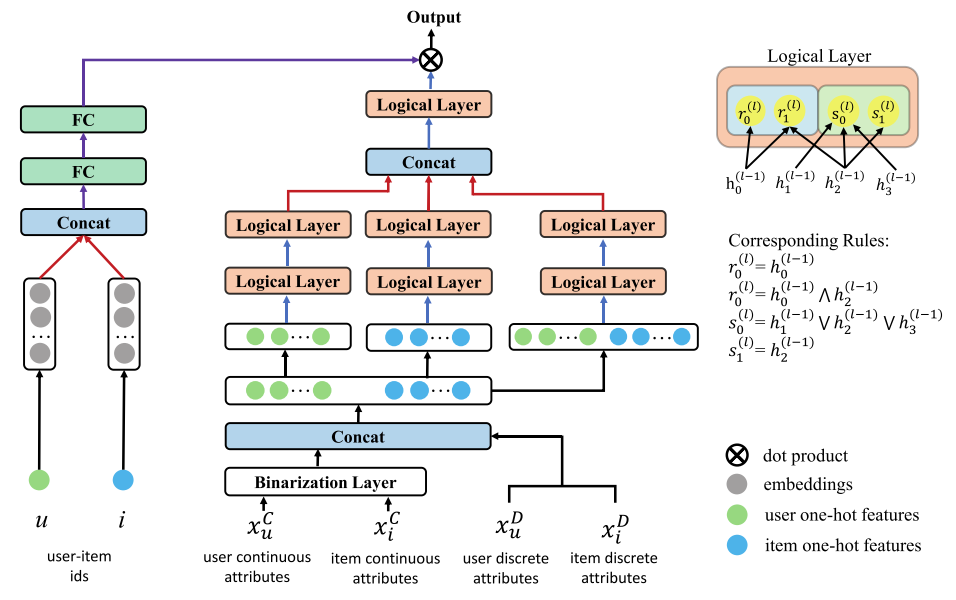
6.1 三塔结构
输入用户和物品的属性,使用Binarization Layer(离散化层)离散化为多个区间(年龄)
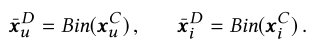
然后将离散化后的连续值和原始离散值拼接,构造逻辑层的输入:
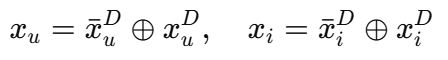
构造三个逻辑塔,用户塔使用用户所有属性,用户-物品塔使用拼接后的用户-物品属性,建模交互规则:
![]()
每一层逻辑操作都基于Preliminaries提到的运算函数,三塔输出结果再次拼接,送入顶层逻辑层,构造最终的规则表示:
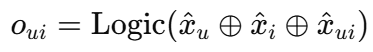
oui∈{0,1}(维度为K的0-1 向量):每个维度代表一个可解释规则是否成立(对应规则是否从逻辑层输出使用),什么叫成立呢:如果用户性别是男性 ∧ 物品是冬季外套 → 成立
4.2 用户项目嵌入融合
引入用户嵌入 eu 和物品嵌入ei,用以生成个性化的规则权重向量:

使用两层全连接层映射到规则维度的权重空间,这里使用到了用户和项目嵌入,最终进行预测:
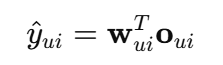
W为 个性化逻辑权重,O为规则表示,训练使用BCE
4.3 模型使用
模型实际上是一个逻辑集,具有个性化的逻辑权重来组合逻辑。 因此,可以提取出符合模型推理过程的逻辑推荐规则。 每个规则都是通过以下过程提取的:
对于顶层逻辑层中的节点,将其作为起始位置,并对低层的所有节点进行路径搜索。 搜索路径中的边对应二值化后权值为1的边(o)。
然后将其转化为多分支树结构的遍历问题,并采用序遍历算法。 如果当前搜索到达某个输入属性,则可以将该属性添加到逻辑中。
所提取的推荐规则集具有许多内在优点:(1)易于使用。 即使没有人工智能背景知识的用户也很容易知道规则的机制。 (2)在不同的计算环境(包括轻量级移动设备)上易于部署。 (3)有助于避免伦理和社会问题。 政府监管机构、系统管理员或领域专家可以删除可能导致公平性等问题的规则。
5 总结
论文说了其实是一个路径搜索问题,那么三塔结构在输入当前用户和项目对应的属性后,进行搜索路径中的边对应二值化后权值为1的边,也就是Oui,例如有三条:Rule 1 男装 ∧ 冬季;Rule 2 女性 ∧ 连衣裙;Rule 3 青年 ∧ 潮流。那么在搜索时Rule 1和3的Oui是1,Rule 2是0
wui 是一次性生成的 K-维向量,输入只依赖于当前用户和项目的ID embedding,每一维度是独立可学习的,每个维度都可以在训练中自由学习如何映射出个性化权重。因此使用权重结合所有Oui为1的逻辑规则进行预测。