单卡4090部署Qwen3-32B-AWQ(4bit量化)-vllm
单卡4090部署Qwen3-32B-AWQ(4bit量化)
-
模型:Qwen3-32B-AWQ(4bit量化)
-
显卡:4090 1 张
-
python版本
python 3.12
-
推理框架“vllm
-
重要包的版本
vllm==0.9.0
创建GPU云主机
-
这里我使用的是优云智算平台的GPU,使用链接可以看下面的
https://blog.csdn.net/hbkybkzw/article/details/148310288
-
注册链接如下
https://passport.compshare.cn/register?referral_code=tRej61o0bLFAfC9mS6Php
创建
-
这一步非必须,如果有自己的GPU机器则可以直接跳过
我们进入
部署GPU实例选择平台镜像,具体操作如下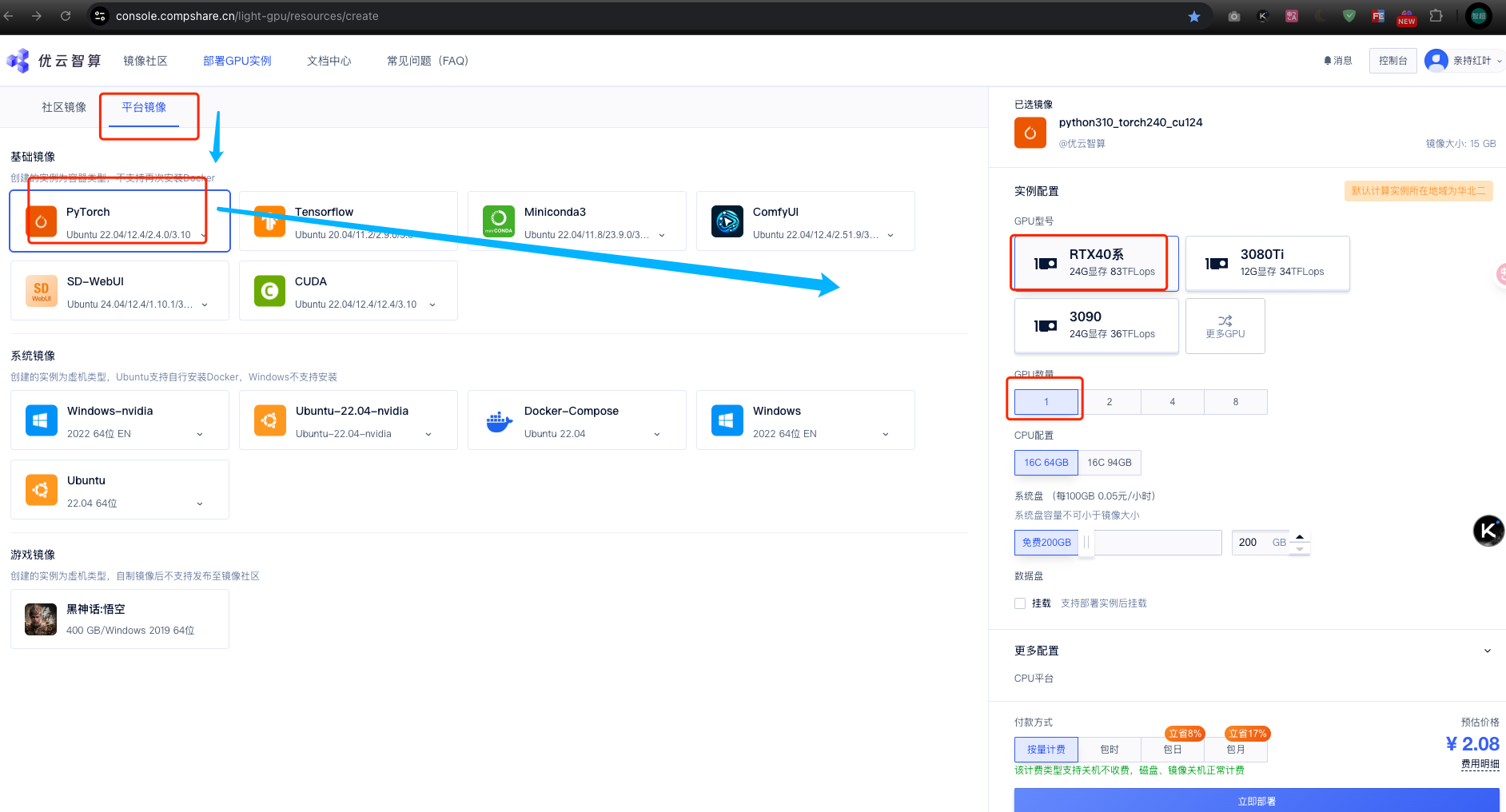
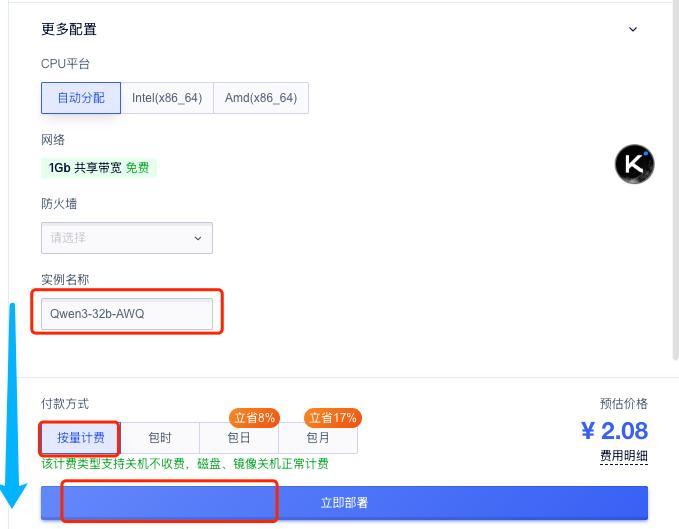
在更多配置中设置实例名称,付款方式使用按量计费,点击立即部署
等待状态变为
运行中,复制登录指令和密码进行登录,这里我们使用finalshell进行连接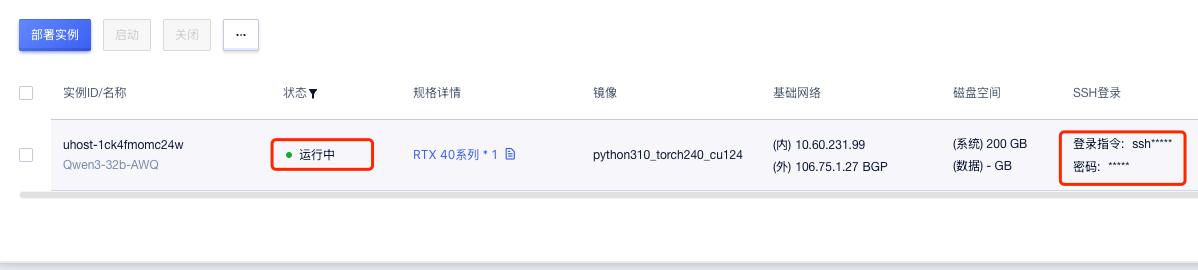
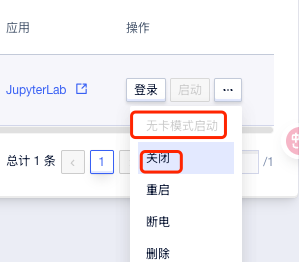
下载模型以及安装python环境会花费一部分时间,这部分时间我们可以先将实例关闭后选择
无卡模式启动,这样就节省费用了
开放端口(非必须)
-
配置防火墙
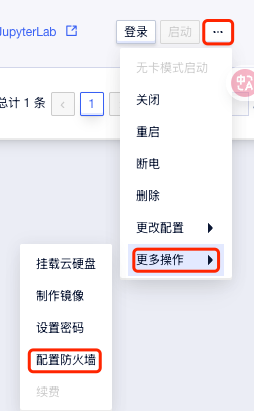
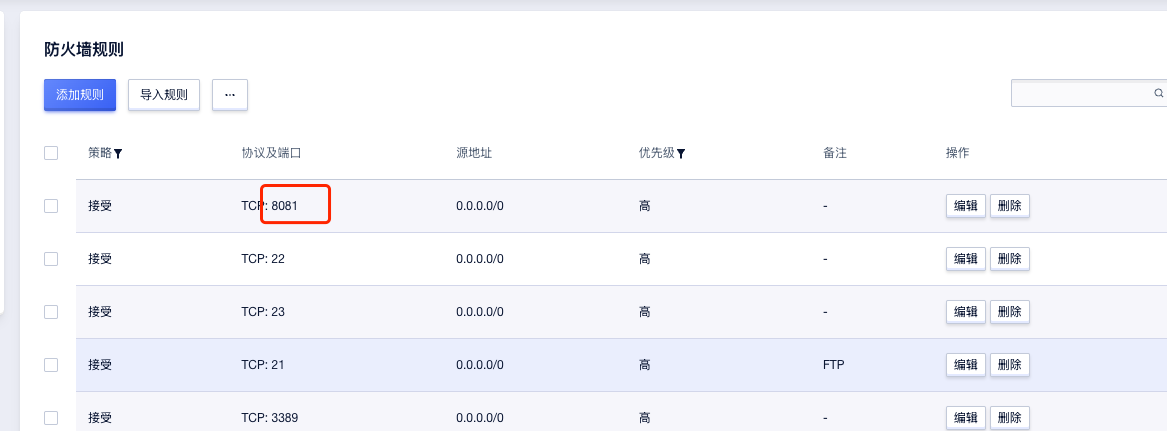
添加规则,这里我开放了8081端口
安装C编译器(必须)
-
当前使用的这个镜像是没有c编译器的,需要安装一下
apt-get update apt-get install build-essential -
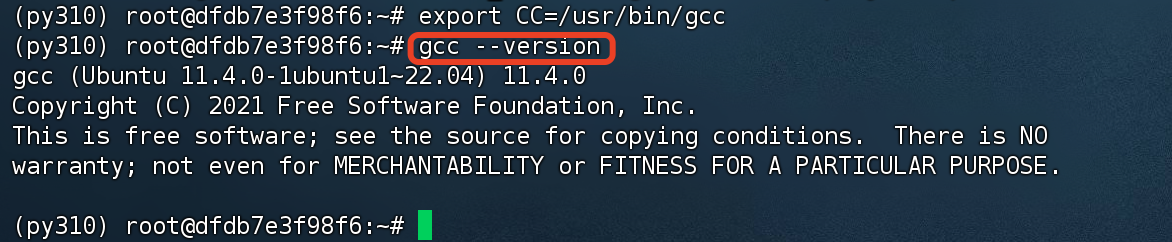
设置环境变量
export CC=/usr/bin/gcc -
检查C编译器是否正确安装
gcc --version
安装
模型下载
-
Qwen3-32B-AWQ模型的modelscope和huggingface地址如下modelscope: https://modelscope.cn/models/Qwen/Qwen3-32B-AWQ
huggingface: https://huggingface.co/Qwen/Qwen3-32B-AWQ
这里我们以modelscope为例,复制模型名称
Qwen/Qwen3-30B-A3B, 这个名称在我们下载的时候会用到
-
使用modelscope下载,需要安装modelscope库
pip install modelscope已经有modelscope库的需要升级下面的几个包
pip install --upgrade modelscope -i https://pypi.tuna.tsinghua.edu.cn/simplepip install --upgrade transformers -i https://pypi.tuna.tsinghua.edu.cn/simple pip install --upgrade peft -i https://pypi.tuna.tsinghua.edu.cn/simple pip install --upgrade diffusers -i https://pypi.tuna.tsinghua.edu.cn/simple -
下载
默认下载在当前用户的.cache文件夹下,比如现在是root用户,则默认在
/root/.cache/modelscope/hub/models/Qwen/Qwen3-32B-AWQ
我们希望将其下载在
/root/Qwen/Qwen/Qwen3-32B-AWQ
from modelscope.hub.snapshot_download import snapshot_downloadmodel_name = "Qwen/Qwen3-32B-AWQ"cache_dir = "/root" # 替换为你希望的路径snapshot_download(model_name, cache_dir=cache_dir)

-
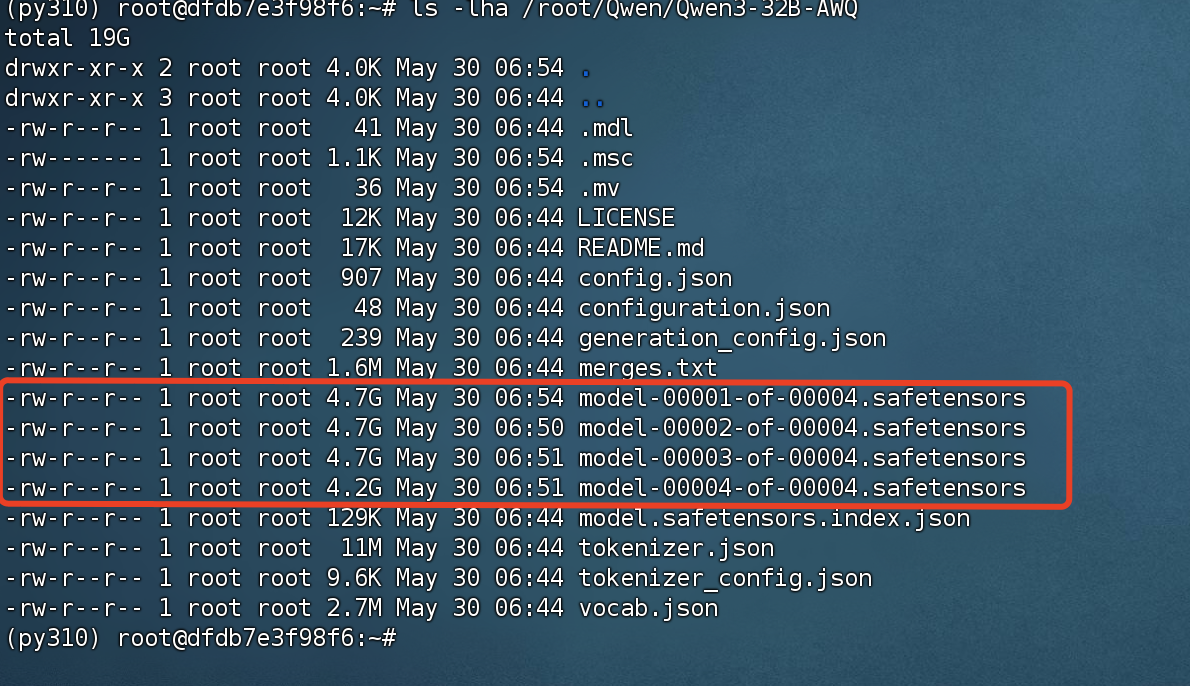
在下载完成后,我们查看下
ls -lha /root/Qwen/Qwen3-32B-AWQ
环境安装
-
使用conda创建虚拟环境
conda create --name qwen3-awq python=3.12conda activate qwen3-awq -
下载vllm(指定清华源,否则极慢)
pip install "vllm>=0.8.5" -i https://pypi.tuna.tsinghua.edu.cn/simple -
需要注意的是transformers的版本需要>=4.51.0
pip show transformers
vllm启动
-
llm启动命令
vllm serve /root/Qwen/Qwen3-32B-AWQ \--max-model-len 8192 \--enable-reasoning --reasoning-parser deepseek_r1 \--gpu-memory-utilization 0.95 \--host 0.0.0.0 \--port 8081 \--served-model-name Qwen3-32B-AWQ-vllm以下是对VLLM启动命令参数的简要说明
参数 简要说明 vllm serve /root/Qwen/Qwen3-32B-AWQ启动VLLM服务、指定模型路径 --enable-reasoning启用推理功能(think) --reasoning-parser指定推理解析器 --max-model-len模型处理的最大序列长度 --gpu-memory-utilization预分配的GPU内存比例 (vllm默认为0.9) --host设置服务监听的主机地址,0.0.0.0表示监听所有网络接口 --port设置服务监听的端口号 --served-model-name设置模型名 -
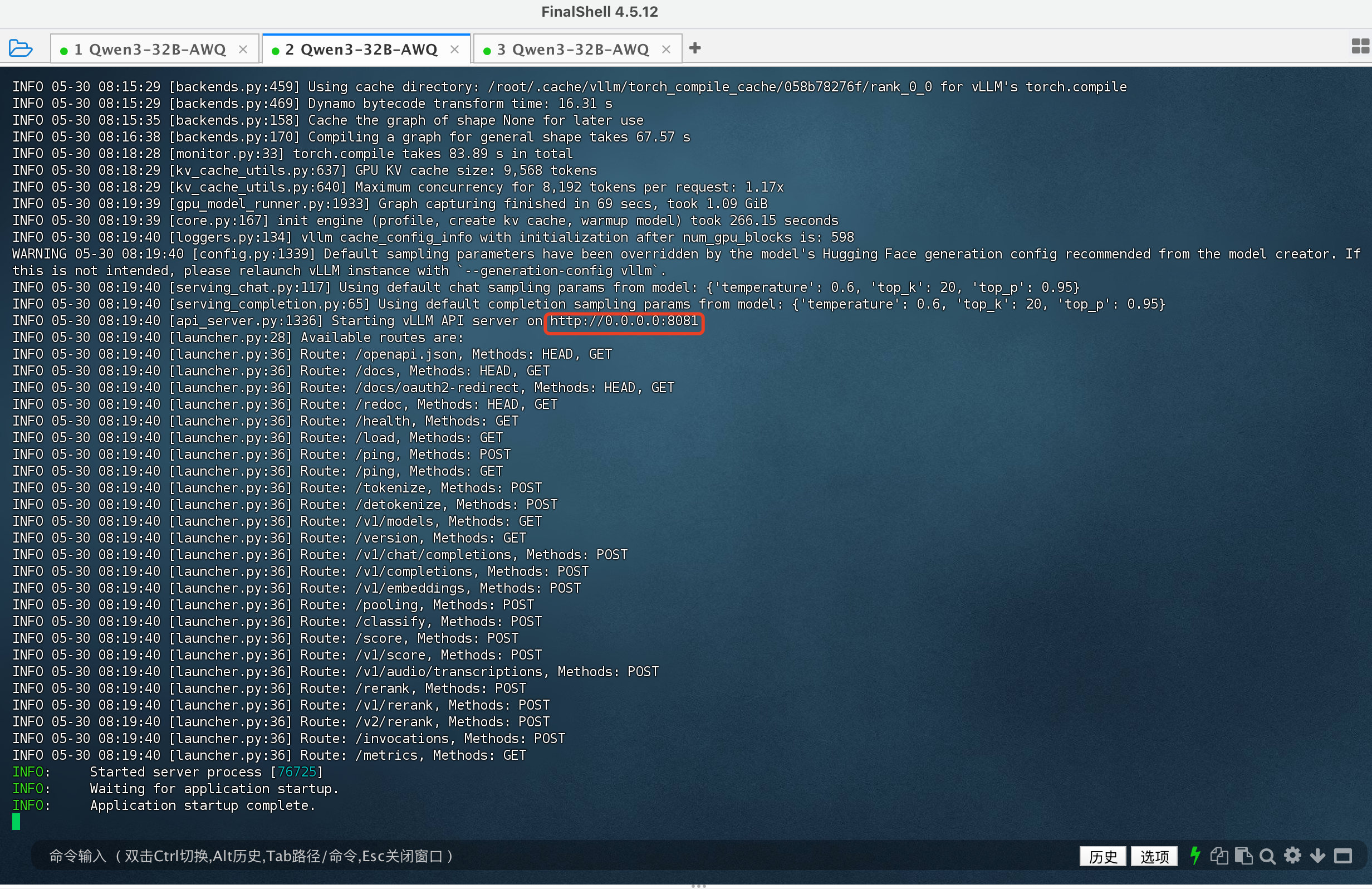
以8081端口启动成功
-
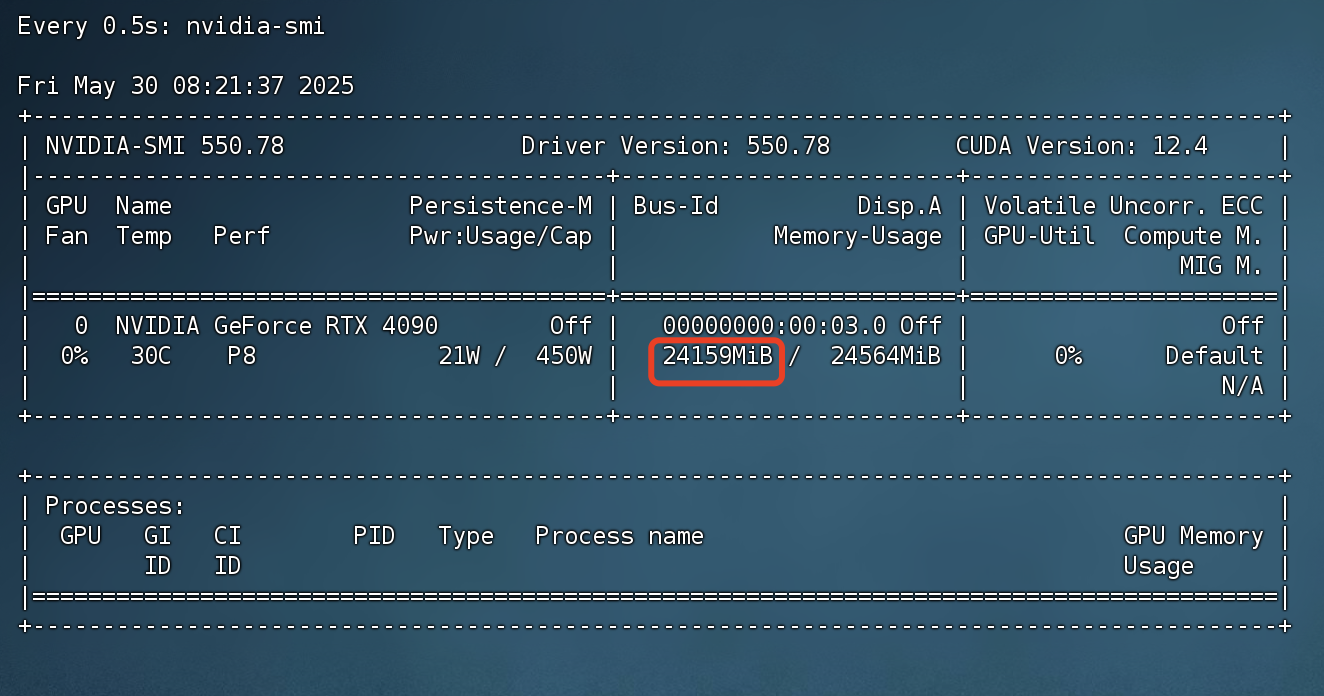
显存占用情况
-
测试
测试代码
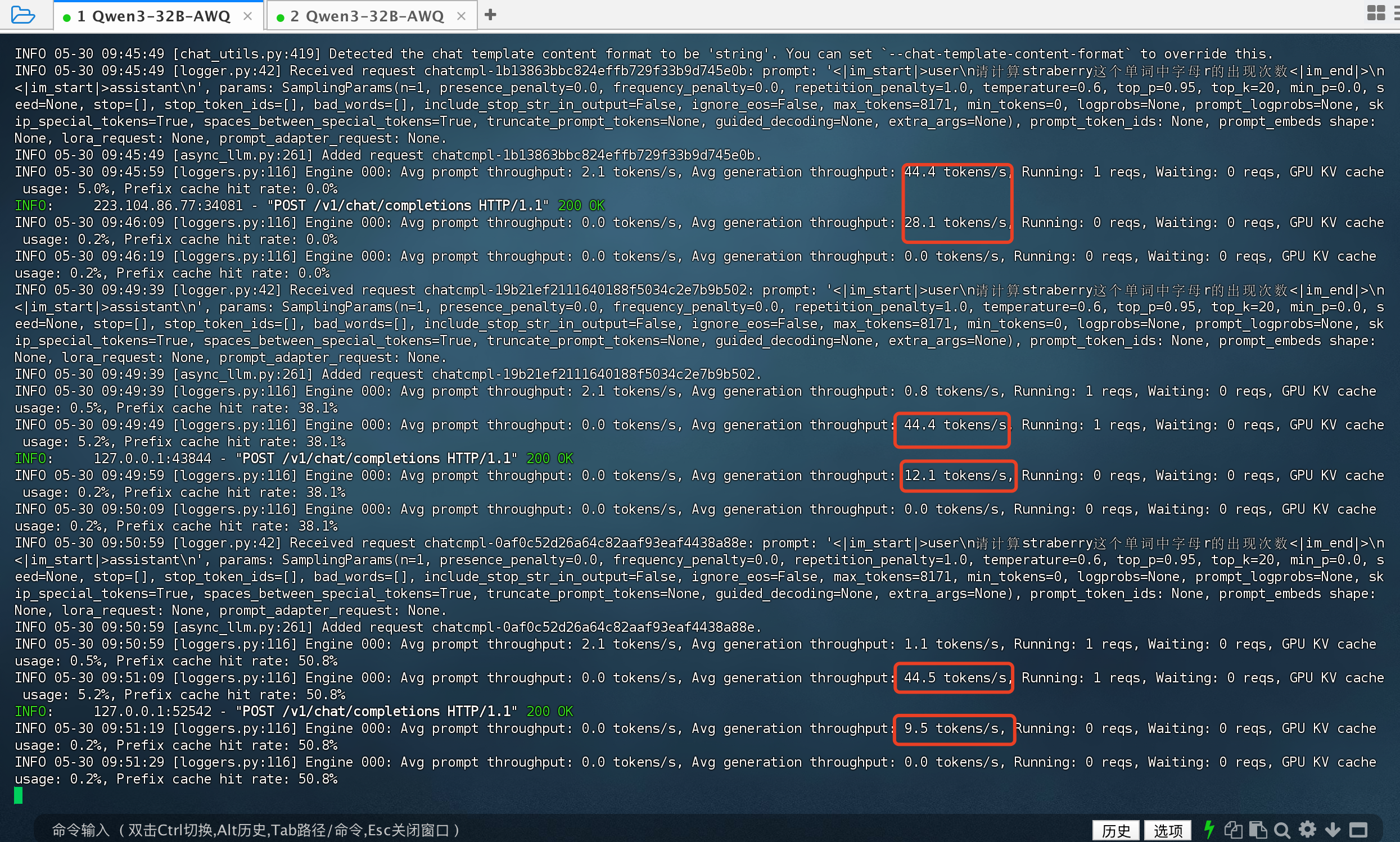
from openai import OpenAI import openaiopenai.api_key = '1111111' # 这里随便填一个 openai.base_url = 'http://127.0.0.1:8081/v1'def get_completion(prompt, model="QwQ-32B"):client = OpenAI(api_key=openai.api_key,base_url=openai.base_url)messages = [{"role": "user", "content": prompt}]response = client.chat.completions.create(model=model,messages=messages,stream=False)reasoning_content = response.choices[0].message.reasoning_contentcontent = response.choices[0].message.contentreturn reasoning_content,contentprompt = '请计算straberry这个单词中字母r的出现次数'reasoning_content,content = get_completion(prompt, model="Qwen3-32B-AWQ-vllm") print('reasoning_content',reasoning_content) print('content',content)
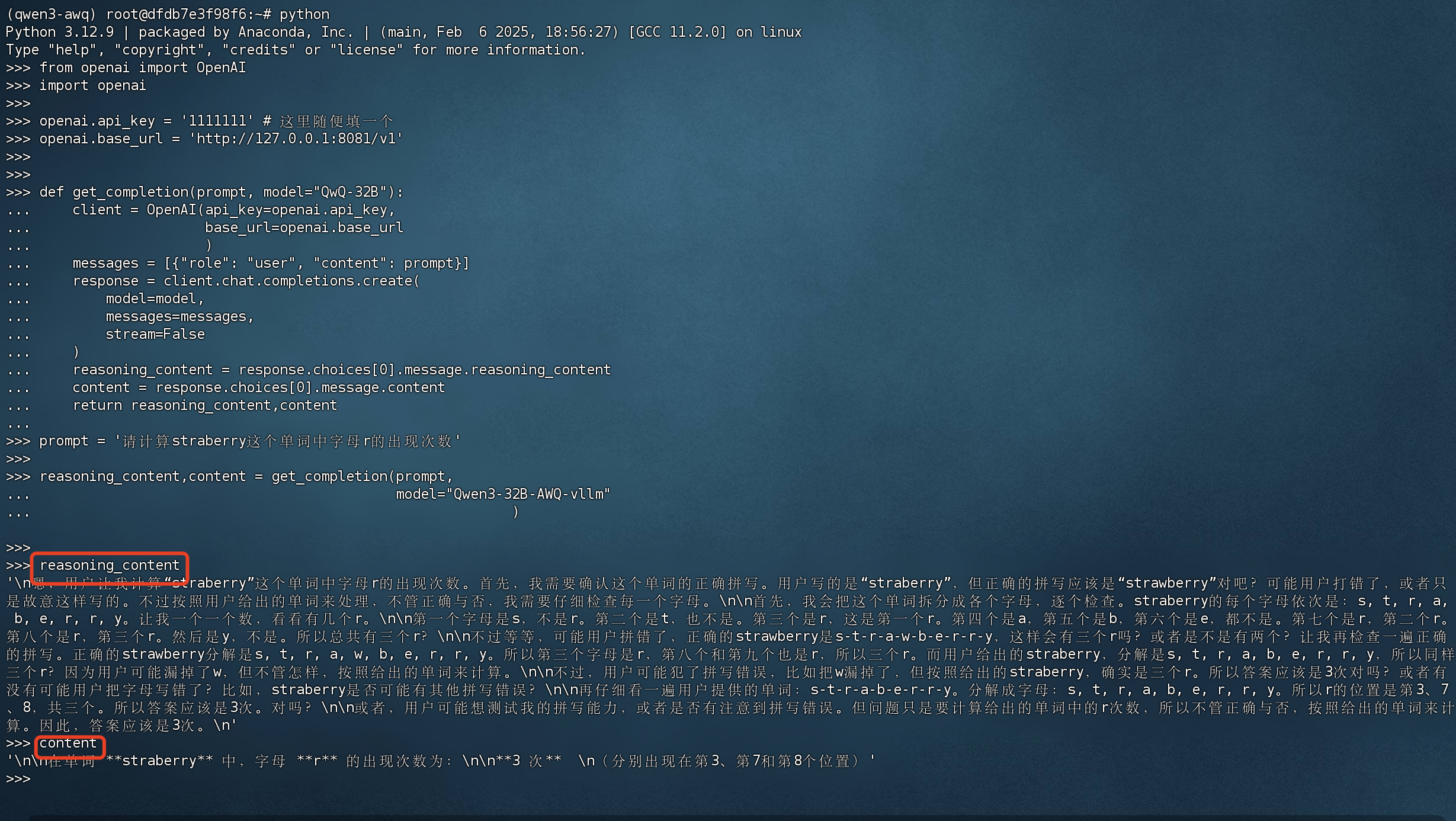
看看每秒tokens数