BERT***
1.预训练(Pre-training)
是深度学习中的一种训练策略,指在大规模无标注数据上预先训练模型,使其学习通用的特征表示,再通过微调(Fine-tuning) 适配到具体任务
2.sentence-level(句子级任务)和token-level(词元级任务)
自然语言处理(NLP)中,sentence-level(句子级任务)和token-level(词元级任务)是根据任务处理的文本粒度划分的两类任务。
在自然语言处理(NLP)中,Feature-based (Elmo) 与 Fine-tuning (GPT) 是两种使用预训练语言模型的策略。它们的主要区别在于 如何将预训练模型应用到下游任务 中。
在自然语言处理(NLP)中,sentence-level(句子级任务)和token-level(词元级任务)是根据任务处理的文本粒度划分的两类任务。它们的区别主要体现在输入输出的形式和应用场景上:
1. Sentence-Level(句子级任务)
定义:以整个句子或句子对作为输入,输出是对句子整体属性的预测或分类。
特点:
- 输入是一个完整的句子(或两个句子的组合)。
- 输出是句子级别的标签或分数。
- 通常用于理解句子的语义、情感或关系。
典型任务:
- 文本分类(如情感分析、主题分类)
- 输入:
"这部电影太精彩了!" - 输出:
正面情感
- 输入:
- 自然语言推理(NLI)
- 输入:
"句子A:猫在沙发上。句子B:沙发上有一只动物。" - 输出:
蕴含(Entailment)
- 输入:
- 句子相似度
- 输入:
"句子A:天气真好。句子B:今天阳光明媚。" - 输出:
相似度0.9(0-1范围)
- 输入:
BERT中的应用:
- 使用
[CLS]标签的最终隐藏状态作为整个句子的表示,接分类器输出结果。
2. Token-Level(词元级任务)
定义:以句子中的每个词或子词(Token)为处理单元,输出对每个Token的预测或标注。
特点:
- 输入是一个句子,但需要对每个Token单独处理。
- 输出是Token级别的标签序列。
- 通常用于细粒度的语言分析。
典型任务:
- 命名实体识别(NER)
- 输入:
"马云在杭州创立了阿里巴巴。" - 输出:
[B-PER, I-PER, O, B-LOC, O, O, B-ORG]
- 输入:
- 词性标注(POS Tagging)
- 输入:
"我爱自然语言处理" - 输出:
[代词, 动词, 名词, 名词, 名词]
- 输入:
- 问答任务(QA)
- 输入:
"问题:谁写了《哈利波特》? 上下文:J.K.罗琳是《哈利波特》的作者。" - 输出:答案跨度
"J.K.罗琳"(定位起始和结束Token的位置)。
- 输入:
3.Feature-based (Elmo) 与 Fine-tuning (GPT)
Feature-based(基于特征的方法,如 ELMo)
-
核心思想:
使用预训练模型(如 ELMo)提取每个词的上下文表示作为“静态特征”,然后将这些特征作为输入提供给一个单独训练的下游模型(如 BiLSTM+CRF)。 -
过程如下:
-
用预训练好的语言模型(如 ELMo)生成文本的上下文嵌入(embeddings)。
-
将这些嵌入作为特征输入到任务特定的模型中(如文本分类器、NER模型等)。
-
只训练下游模型的参数,ELMo参数保持不变(有时可以微调,但本质上是特征提取)。
-
Fine-tuning(微调方法,如 GPT/BERT)
代表模型:GPT、BERT、T5、LLAMA 等
-
核心思想:
将整个预训练模型和下游任务模型作为一个整体进行端到端训练。 -
过程如下:
-
将下游任务的数据输入预训练模型(如 GPT/BERT)。
-
在其顶层添加一个或多个任务特定的层(如分类器)。
-
使用任务数据对整个模型进行微调,包括预训练模型本身。
-
4.BERT
1.BERT结构
1.输入
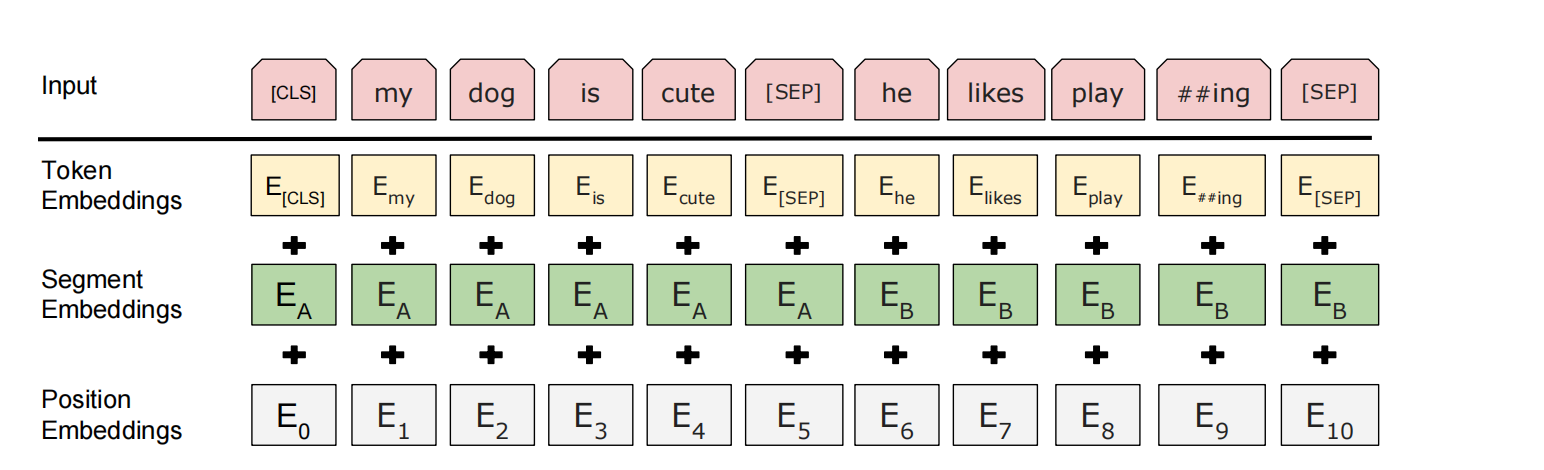
BERT的输入由三部分嵌入(Embedding)相加组成:
-
Token Embeddings(词嵌入)
- 使用WordPiece分词(30,000词表),解决未登录词(OOV)问题。
- 特殊标记:
[CLS]:分类任务的聚合表示(位于序列开头)。[SEP]:分隔句子对(如问答中的问题和答案)。[MASK]:预训练时用于掩码语言模型(MLM)。
-
Segment Embeddings(句子嵌入)
- 区分句子A和句子B(如问答对、句对任务),用
E_A和E_B表示。
- 区分句子A和句子B(如问答对、句对任务),用
-
Position Embeddings(位置嵌入)
- 使用可学习的位置编码(而非Transformer的固定正弦/余弦函数),支持最长512个Token的序列。
2.BERT通过两个无监督任务预训练:
(1) 掩码语言模型(Masked Language Model, MLM)
- 方法:随机掩盖15%的输入Token,其中:
- 80%替换为
[MASK]。 - 10%替换为随机Token。
- 10%保持不变(缓解预训练-微调不一致)。
- 80%替换为
- 目标:基于上下文预测被掩盖的原始Token。
(2) 下一句预测(Next Sentence Prediction, NSP)
- 方法:给定句子A和B,预测B是否是A的下一句(50%正例,50%随机负例)。
- 目标:学习句子间关系,提升问答(QA)、自然语言推理(NLI)等任务性能。
2.Bert用途
语言模型(Language Model, LM) 的目标是:给定前面的词序列,预测下一个词的概率。
Transformer 本身只是一个神经网络架构,包含以下两种主要模块:
-
Encoder:用于建模整段输入(如 BERT)
-
Decoder:用于按序生成词(如 GPT)
| Transformer 结构 | 能不能用来做语言模型? |
|---|---|
| Encoder-only(如 BERT) | ❌ 不能做自回归语言模型(会信息泄露) |
| Decoder-only(如 GPT) | ✅ 可以做语言模型(逐词生成) |
| Encoder-Decoder(如 T5) | ✅ 可用于生成任务,也能做语言建模(但更常用于翻译、摘要) |
-
BERT 不是用来生成句子的(不像 GPT);
-
它做的是填空、理解,不会从左到右一步步生成;
-
BERT 的核心用途是做“理解”类任务,是为各种 NLP 下游任务提供语义理解的预训练模型。
| 应用 | 举例 | 用 BERT 怎么做 |
|---|---|---|
| 1️⃣ 文本分类 | 情感分析、垃圾邮件检测 | 将整段文本喂给 BERT,取 [CLS] 向量接全连接层做分类 |
| 2️⃣ 序列标注 | 命名实体识别(NER)、分词 | 每个词有一个表示,接一个分类器预测标签(如人名、地名) |
| 3️⃣ 句子对判断 | 语义相似度、句子关系判断 | 把两个句子拼在一起,让 BERT 判断是否相关 |
| 4️⃣ 问答系统(QA) | 给你一段文章,问“谁是美国总统” | BERT 提取答案的起止位置 |
| 5️⃣ 多轮对话理解 | 对话状态跟踪、意图识别 | 同样是对语言的“理解” |