Postgre数据库分区生产实战
1.分区背景

随着业务的发展,单表数据量日益增加,服务端对数据查询时长逐步的在增大,单表已经不能满足正常的查询需求了。所以,对于Postgre数据库最好的办法就是针对这个一个数据量比较大的表,对其进行分区处理。为啥采用分区呢?有以下几方面原因:
1.1. 数据量膨胀与查询性能瓶颈
随着数据量的持续增长,单表存储的数据可能达到千万甚至亿级,导致查询性能显著下降。传统全表扫描或索引检索在大型表上效率低下,而分区通过将数据物理分散到多个小表中,使查询只需扫描特定分区,减少I/O和内存消耗,性能可提升数倍至数十倍。例如,时间序列数据(如日志、交易记录)按月份分区后,查询某月数据只需扫描单个分区而非全表。
1.1.2.历史数据管理需求
业务中常存在“热数据”与“冷数据”的区分。例如,电商订单表可能仅需频繁访问最近3个月的数据,而历史数据很少使用但仍需保留。分区允许将冷数据归档到低成本存储(如慢速磁盘),或直接删除旧分区(如
DROP TABLE partition_2022),比DELETE操作更高效且避免VACUUM压力。
1.1.3.运维灵活性的提升
- 维护操作隔离:可单独对分区进行备份、恢复、重建索引等操作,例如仅优化活跃分区的索引,而不影响其他分区 。
- 动态扩展:通过添加新分区(如每月自动创建下月分区)实现无缝扩展,避免传统分库分表的复杂迁移 。
1.1.4. PostgreSQL版本演进推动
- 早期方案(PG9.x及之前):需手动通过表继承(
INHERITS)和触发器实现分区,步骤繁琐且功能受限(如无自动路由) 。- PG10+的声明式分区:引入
PARTITION BY RANGE/LIST语法,简化分区表创建和管理,支持自动数据路由,但初期仅支持范围与列表分区 。- PG11+的增强:加入哈希分区、默认分区、全局索引等功能,并支持分区键更新(需不跨分区),进一步降低使用门槛 。
1.1.5. 多租户与业务隔离需求
在SaaS等场景中,按租户ID(
tenant_id)分区可天然隔离不同租户数据,提升查询效率(如WHERE tenant_id='A'仅扫描对应分区),同时便于按租户进行资源分配或迁移。
2.具体方法
2.1.分区类型
2.1.1.范围分区(Range Partitioning)
- 适用场景:适用于具有连续值范围的列,如日期、时间戳或数值范围。
- 特点:
- 数据按范围划分,每个分区包含特定范围内的数据。
- 常用于时间序列数据(如日志、订单表)。
- 示例:
CREATE TABLE sales (id SERIAL,sale_date DATE,amount NUMERIC
) PARTITION BY RANGE (sale_date);CREATE TABLE sales_2023_q1 PARTITION OF salesFOR VALUES FROM ('2023-01-01') TO ('2023-04-01');- 优势:查询时可通过分区裁剪(Partition Pruning)显著提升性能 。
2.1.2.列表分区(List Partitioning)
- 适用场景:适用于离散值,如地区代码、状态或类别。
- 特点:
- 数据按明确的列表值划分,每个分区包含特定值的数据。
- 适合固定分类的数据。
- 示例:
CREATE TABLE sales_by_region (id SERIAL,region VARCHAR(20),amount NUMERIC ) PARTITION BY LIST (region);CREATE TABLE sales_region_east PARTITION OF sales_by_regionFOR VALUES IN ('NY', 'NJ', 'CT'); - 优势:查询时可直接定位到特定分区,适合高频查询固定分类的场景 。
2.1.3.哈希分区(Hash Partitioning)
- 适用场景:适用于需要均匀分布数据的列,如用户ID或随机键。
- 特点:
- 数据通过哈希函数均匀分布到多个分区。
- 适合无自然分区键但需要平衡负载的场景。
- 示例:
CREATE TABLE users (id SERIAL,username VARCHAR(50),email VARCHAR(100) ) PARTITION BY HASH (id);CREATE TABLE users_p0 PARTITION OF usersFOR VALUES WITH (MODULUS 4, REMAINDER 0); - 优势:数据分布均匀,避免热点问题。
2.1.4. 复合分区(Composite Partitioning)
- 适用场景:需要多级分区的复杂场景,如先按时间范围再按地区。
- 特点:
- 结合多种分区策略(如范围+列表)。
- 支持更灵活的数据管理。
- 示例:
CREATE TABLE customer_orders (region VARCHAR(20),order_date DATE,amount NUMERIC ) PARTITION BY LIST (region), RANGE (order_date);CREATE TABLE orders_asia_2023 PARTITION OF customer_ordersFOR VALUES IN ('asia') PARTITION BY RANGE (order_date); - 优势:适用于多维查询需求 。
2.2.分区实战
我们来用过列表分区来实现一下线上分区实战。假如我们有一张表,数据量现在非常大,这个表现在需要进行分区操作,这个表的结构如下:
CREATE TABLE "mx_dw"."mx_wide_table" ("id" int8 NOT NULL DEFAULT nextval('"mx_dw".id_seq'::regclass),"tenant_id" int2,"app" varchar(64) COLLATE "pg_catalog"."default","mid" int8,"create_time" timestamptz(6),CONSTRAINT "mx_wide_pkey" PRIMARY KEY ("id")
)
;为了方便我们查看,我们向上述表增加一些数据,来作为没有分区前的表数据:
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (40, 1000, 'Apple', 123451, '2025-05-29 18:10:46.227406+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (41, 1000, 'Apple', 123452, '2025-05-29 18:10:46.24465+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (42, 1000, 'Apple', 123453, '2025-05-29 18:10:46.255477+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (43, 1000, 'Apple', 123454, '2025-05-29 18:10:46.265751+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (44, 1000, 'Apple', 123455, '2025-05-29 18:10:46.277289+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (45, 1000, 'Apple', 123456, '2025-05-29 18:10:46.287904+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (46, 1000, 'Apple', 123457, '2025-05-29 18:10:46.298228+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (47, 1000, 'Apple', 123458, '2025-05-29 18:10:46.308736+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (48, 1000, 'Apple', 123459, '2025-05-29 18:10:46.319316+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (49, 1000, 'Apple', 123450, '2025-05-29 18:10:46.33004+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (50, 2000, 'Orange', 234561, '2025-05-29 18:10:46.340377+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (51, 2000, 'Orange', 234562, '2025-05-29 18:10:46.3509+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (52, 2000, 'Orange', 234563, '2025-05-29 18:10:46.368057+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (53, 2000, 'Orange', 234564, '2025-05-29 18:10:46.389174+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (54, 2000, 'Orange', 234565, '2025-05-29 18:10:46.422074+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (55, 2000, 'Orange', 234566, '2025-05-29 18:10:46.448014+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (56, 2000, 'Orange', 234567, '2025-05-29 18:10:46.458576+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (57, 2000, 'Orange', 234568, '2025-05-29 18:10:46.470304+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (58, 2000, 'Orange', 234569, '2025-05-29 18:10:46.484155+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (59, 2000, 'Orange', 234560, '2025-05-29 18:10:46.501001+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (60, 3000, 'Banana', 323451, '2025-05-29 18:10:46.544632+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (61, 3000, 'Banana', 323452, '2025-05-29 18:10:46.556297+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (62, 3000, 'Banana', 323453, '2025-05-29 18:10:46.56707+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (63, 3000, 'Banana', 323454, '2025-05-29 18:10:46.577595+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (64, 3000, 'Banana', 323455, '2025-05-29 18:10:46.587941+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (65, 3000, 'Banana', 323456, '2025-05-29 18:10:46.602008+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (66, 3000, 'Banana', 323457, '2025-05-29 18:10:46.62536+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (67, 3000, 'Banana', 323458, '2025-05-29 18:10:46.635666+08');
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (68, 3000, 'Banana', 323459, '2025-05-29 18:10:46.647001+08');
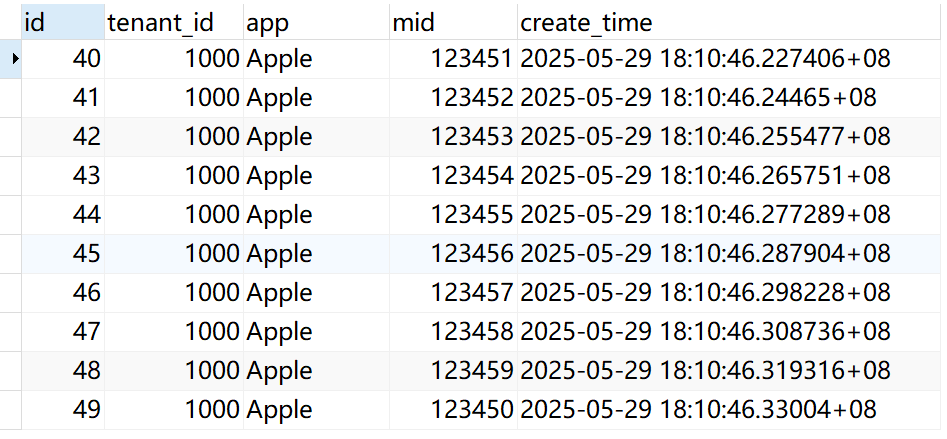
INSERT INTO "mx_dw"."mx_wide_table" ("id", "tenant_id", "app", "mid", "create_time") VALUES (69, 3000, 'Banana', 323450, '2025-05-29 18:10:46.657946+08');开始创建分区主表,我们根据租户进行分区,为一个租户建立一个单独的分区表,需要把分区字段放入主键集合,我们通过列表分区方式:PARTITION BY LIST (tenant_id) ,创建分区主表的SQL如下:
CREATE TABLE partitioned_wide_table ("id" int8 NOT NULL DEFAULT nextval('"mx_dw".id_seq'::regclass),"tenant_id" int2 NOT NULL,"app" varchar(64) COLLATE "pg_catalog"."default","mid" int8,"create_time" timestamptz(6),PRIMARY KEY (id, tenant_id)
) PARTITION BY LIST (tenant_id);创建分区表并关联分区主表:partitioned_wide_table_Apple 和partitioned_wide_table_Orange ,其中partitioned_wide_table_Apple中存储的是tenant_id=1000的数据,而partitioned_wide_table_Orange中存储的是tenant_id=2000的数据:
CREATE TABLE partitioned_wide_table_Apple PARTITION OF partitioned_wide_table FOR VALUES IN (1000);CREATE TABLE partitioned_wide_table_Orange PARTITION OF partitioned_wide_table FOR VALUES IN (2000);以上创建完分区表和分区主表,那么我们需要将原始表的数据来同步到对应的分区表:partitioned_wide_table_Apple分区表数据导入:
INSERT INTO partitioned_wide_table_Apple
SELECT * FROM mx_wide_table where tenant_id = 1000;
partitioned_wide_table_Orange分区表数据导入:
INSERT INTO partitioned_wide_table_Orange
SELECT * FROM mx_wide_table where tenant_id = 2000;
3.分区验证
执行以下SQL:
SELECT relname, pg_get_expr(relpartbound, oid)
FROM pg_class WHERE relispartition AND relname like'partitioned_wide_table%';结果为:
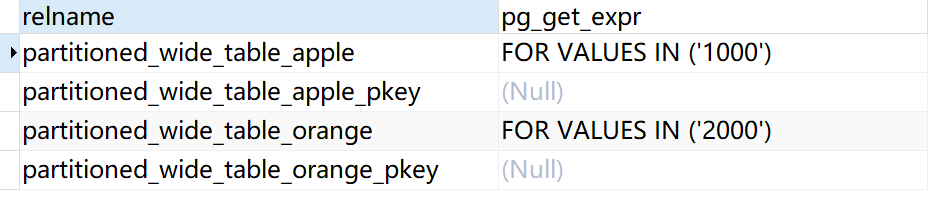
从上面可以看到两个分区已经分区成功。
4.执行查询
我们现在对以上分区后的数据执行查询,我们查询的时候只需要执行主表的查询语句,postgre查询引擎会根据查询条件会路由到对应的分区表,比如我们查询tenant_id = 1000的数据:
select * from partitioned_wide_table where tenant_id = 1000结果集为:
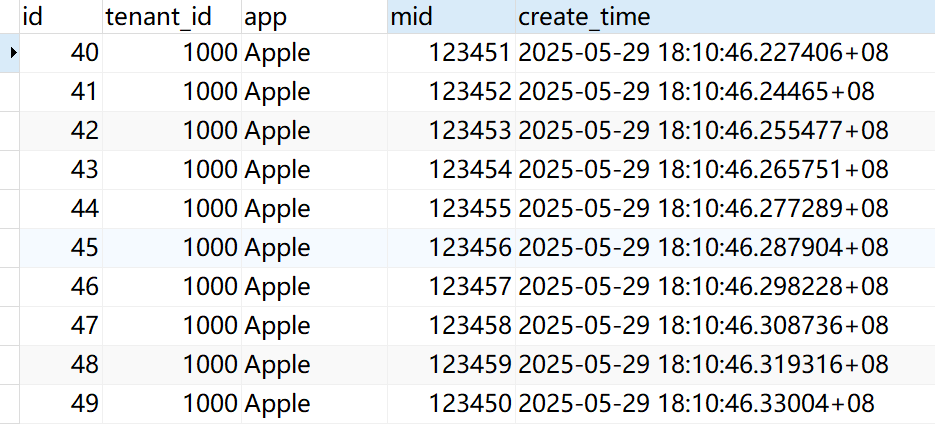
同样地,我们还可以通过分区表来进行查询:
select * from partitioned_wide_table_Apple where tenant_id = 1000