java基础 之 Hash家族(一)
文章目录
- HashCode
- 定义
- 代码使用
- 使用场景
- HashMap
- 定义
- 常用方法
- 使用场景
- ConcurrentHashMap
- 定义
- 常用方法
- 使用场景
- HashTable
- 定义
- 常用方法
- 使用场景
- HashSet
- 定义
- 常用方法
- 使用场景
- 你想到过吗?
- HashMap、ConcurrentHashMap、HashTable的对比
- 总结
HashCode
定义
-
hashcode是Object类的一个方法。它返回一个对象的哈希码值。哈希码是一个整数,它用于在哈希表(如HashMap、HashSet等)中确定该对象的存储位置,从而能够快速的对对象进行存取操作
例如,当我们存储一个对象到HashMap中时,HashMap会使用该对象的HashCode值来确定应该将对象存储在哈希表的哪个桶(bucket)中。如果两个对象的hashCode值不同,它们通常会被存储在不同的桶中,这样可以减少查找时的比较次数
代码使用
-
未重写hashCode
public class HashCodeTest {public static void main(String[] args) {Person p1 = new Person("张三", 18, "男");Person p2 = new Person("张三", 18, "男");System.out.println(p1.hashCode()); // 结果:1268447657System.out.println(p2.hashCode()); // 结果:1401420256System.out.println(p1.equals(p2)); // 结果:false} }class Person {private String name;private int age;private String gender;public Person(String name, int age, String gender) {this.name = name;this.age = age;this.gender = gender;} } -
重写hashCode(对Person类添加如下方法)
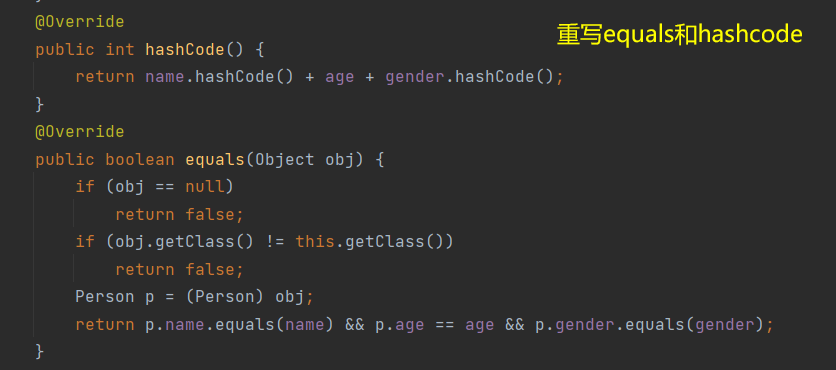
再运行上述代码,结果为:
804914
804914
true
使用场景
- 如果两个对象根据equals(Object)方法比较是想等的,那么它们的hashCode必须相同
点击跳转 → java基础 之 重写equals时为什么要重写hashCode
HashMap
定义
- 1、是基于哈希表的Map接口的实现
- 2、允许使用null值和null键,但是不能保证映射顺序
- 3、时间复杂度在大多数情况下为O(1),最坏情况下(如哈希冲突严重)会退化到O(N)
- 4、hashMap的key与value类型可以相同也可以不同
- 5、内部实现原理:
(1)底层是一个哈希表数组,每个哈希表元素是一个链表(在java8及以后,当链表长度超过一定阈值时会转换为红黑树)
(2)当存储键值对时,会根据键对象的hashCode计算出其哈希值,然后确定在哈希表数组中的存储位置
(3)如果多个键的哈希值相同(即哈希冲突),则它们会被存储在同一个链表或红黑树中
常用方法
public static void main(String[] args) {Map<Integer,String> map = new HashMap<>();map.put(1,"hello"); // 添加键值对Map<Integer,String> mapTemp = new HashMap<>();mapTemp.put(2,"world");map.putAll(mapTemp); // 添加mapTemp的键值对到map中map.putIfAbsent(2,"java"); // 先判断key为2是否存在,不存在则添加,存在则不添加System.out.println(map.get(2)); // 结果为:worldmap.putIfAbsent(3,"java");System.out.println(map.get(3)); // 结果为:javamap.remove(3); // 删除键为3的键值对boolean contains = map.containsKey(3); // 判断键为3的键值对是否存在map.replace(2, "java2"); // 替换键为2的值为java2map.replaceAll((key, value)-> value.toUpperCase());// 将hashMap中的所有映射关系替换成给定的函数所执行的结果,即map中所有值都变成大写String value2 =map.get(2); // 获取指定key对应的value值:结果为:java2// 获取指定key对应的value值,如果key不存在则返回给定的默认值:结果为java4String vaule4 = map.getOrDefault(4, "java4");map.forEach((key, value)-> System.out.println(key + ":" + value)); // 遍历Set<Integer> set = map.keySet(); // 获取map中所有keySystem.out.println("---------");Collection<String> values = map.values();// 获取map中所有valueInteger size = map.size(); // 计算map大小System.out.println(size);boolean isEmpty = map.isEmpty(); // 判断map是否为空map.clear(); // 清空map}
使用场景
单线程环境。如果不需要线程安全,HashMap 是最佳选择,因为它性能高且灵活。
需要支持空键和空值。如果需要存储 null 键或 null 值,HashMap 是唯一的选择。
ConcurrentHashMap
定义
- 1、是java中一个线程安全的哈希表实现类,属于java.util.concurrent包
- 2、 ConcurrentHashMap在多线程环境下可以高效的进行并发操作,而不会出现线程安全问题;
- 3、在java1.8之前,ConcurrentHashMap通过分段锁(Segment)机制来保证线程安全;从java1.8开始,ConcurrentHashMap基于CAS(Compare And Swap)操作和synchronized锁来保证线程安全
常用方法
-
1、常用方法同HashMap,此处不多说
-
2、下面的方法是用来验证ConcurrentHashMap的线程安全的
public static void main(String[] args) throws InterruptedException {ConcurrentHashMap<String,Integer> map = new ConcurrentHashMap<>();int threadCount = 10;CountDownLatch latch = new CountDownLatch(threadCount);// 启动多个线程并发写入for(int i=1;i<threadCount+1;i++){new Thread(()->{for(int j=1;j<1001;j++){String key = "key"+j;map.merge(key,1,Integer::sum);}latch.countDown();}).start();}latch.await();int total = map.values().stream().mapToInt(Integer::intValue).sum();System.out.println("总数为"+total); }代码说明:
- 1、无论打印几次,结果都是10000
- 2、使用 map.merge(key, 1, Integer::sum) 原子性地更新键值对:
(1)如果键不存在,直接将键值对 (“key” + j, 1) 写入 map。
(2)如果键已经存在,调用 Integer::sum 方法,将当前值与 1 相加,然后更新键值对。 - 3、每个线程完成写入操作后,调用 latch.countDown(),表示该线程已完成
- 4、使用 map.values() 获取 map 中的所有值:
(1)使用 stream() 将值集合转换为流。
(2)使用 mapToInt(Integer::intValue) 将 Integer 对象转换为原始 int 类型。
(3)使用 sum() 计算所有值的总和。
-
大家也可以将ConCurrentHashMap替换成HashMap,然后运行,运行结果一定是小于10000的;
使用场景
- 1、多线程环境下的缓存
在多线程应用中,ConcurrentHashMap常用于实现线程安全的缓存。
多个线程可以并发的读取和更新缓存数据,而不会出现数据不一致的问题。 - 2、统计和计数
ConcurrentHashMap适用于需要统计或计数的场景,尤其是多线程环境下
- 3、线程安全的共享数据结构
在多线程应用中,ConcurrentHashMap可以作为共享数据结构,允许多个线程安全的读取和更新数据
- 4、分布式系统中的本地缓存
在分布式系统中,ConcurrentHashMap可以用作本地缓存,存储从远程服务器获取的数据。多个线程可以并发的访问和更新缓存,提高系统的性能和响应速度
- 5、高并发的web应用
在高并发的web应用中,ConcurrentHashMap可以用于存储用户会话信息、配置信息等。它能够高效的处理多个请求的并发访问,提高系统的吞吐量。
- 6、实时数据处理
在实时数据处理系统中,ConcurrentHashMap可以用于存储和更新试试数据,例如股票价格、传感器数据等。多个线程可以并发的读取和更新数据,确保数据的实时性和准确性。
HashTable
定义
-
1、HashTable是java中一个古老的线程安全的哈希表实现类,继承了Dictionary类,并实现了Map接口

-
2、HashTable的设计目标是提供线程安全的哈希表操作,但它在性能和灵活性上不如ConcurrentHashMap和HashMap
-
3、HashTable是一个线程安全的哈希表,它通过同步方法(synchronized)来保证线程安全。即在多线程环境下,多个线程可以并发的访问和修改HashTable,而不会出现数据不一致的问题。
常用方法
- 同HashMap
使用场景
- 1、线程安全的共享数据
- 2、HashTable可以存储配置信息
- 3、旧代码兼容
HashSet
定义
- 1、HashSet是java中一个基于哈希表实现的集合类,属于java.util包
- 2、HashSet不允许重复的元素,并且不保证元素的顺序
- 3、HashSet是线程不安全的,如果需要线程安全的集合,可以使用Collections.synchronizedSet或ConcurrentHashMap.newKeySet()
- 4、HashSet是一个实现了Set接口的集合类。它使用哈希表来存储元素。由于哈希表的特性,HashSet提供了高效的添加、删除和查找操作,平均时间复杂度为O(1)

常用方法
public static void main(String[] args) {HashSet<String> set = new HashSet<>();// 添加元素set.add("hello");set.add("world");set.add("hello");set.add("java");// 遍历集合for(String s : set){System.out.print(s+" "); // hello world java(顺序可能不同)}// 集合的长度System.out.println(set.size()); // 3// 判断集合中是否包含某个元素System.out.println(set.contains("hello")); // trueSystem.out.println(set.contains("python")); // false// 删除集合中的元素System.out.println(set.remove("hello")); // trueSystem.out.println(set.remove("python")); // falseSystem.out.println(set.size()); // 2 只剩下了world javaHashSet<String> anotherSet = new HashSet<>();anotherSet.add("apple");anotherSet.add("banana");anotherSet.add("watermelon");// 添加另一个集合的元素set.addAll(anotherSet);for(String s : set){System.out.print(s+" "); // banana apple world java watermelon(顺序可能不同)}System.out.println();// 迭代器遍历Iterator<String> iterator = set.iterator();while(iterator.hasNext()){System.out.print(iterator.next()+" "); // banana apple world java watermelon(顺序可能不同)}// 转换成数组Object[] arr = set.toArray(); // set集合转换成数组String[] strArr = set.toArray(new String[0]); // set集合转换成String数组// retainAll(): 交集,返回的结果是该集合有没有被更改(假设set中有world、java、banana、orange、watermelon )System.out.println(set.retainAll(anotherSet)); // true:保留的是banana、apple、watermelonSystem.out.println("-------");// removeAll(): 差集,返回的结果是该集合有没有被更改(假设set中有world、java、banana、orange、watermelon )System.out.println(set.removeAll(anotherSet)); // true;保留的是world javaset.clear();System.out.println(set.isEmpty());// true}
使用场景
- 去重:可以用来去除重复的元素
- 快速查找:HashSet提供了高效的查找操作,适用于快速判断某个元素是否存在的场景
- 存储唯一标识符:HashSet可以用来存储唯一标识符,例如用户ID、文件名等
- 集合运算:addAll实现集合的并集、retainAll 实现集合的交集、removeAll实现集合的差集
你想到过吗?
-
如果hashset中的内容不变,每次遍历出来的内容顺序应该是固定的吧
如果
HashSet中的内容不变,每次遍历出来的内容顺序应该是一个固定的顺序,但这个顺序是不确定的,无法预先知晓。-
固定的顺序(在内容不变的情况下)
-
当
HashSet中的元素确定后,只要没有对集合进行任何修改操作(如添加、删除元素等),那么元素在哈希表中的存储位置就不会改变。在遍历时,会按照桶的顺序以及桶中元素的存储顺序来访问元素。对于具体的实现(如 Java 中的HashSet实现),如果没有对集合进行修改,每次遍历都会按照相同的顺序访问元素。 -
例如:
public static void main(String[] args) {Set<String> hashSet = new HashSet<>();hashSet.add("hello");hashSet.add("world");hashSet.add("java");hashSet.add("java");hashSet.add("python");for(String s : hashSet){System.out.print(s+" "); // python world java hello}System.out.println();Iterator<String> iterator = hashSet.iterator();while(iterator.hasNext()){System.out.print(iterator.next()+" "); // python world java hello} } -
假设在这两次遍历之间没有对
hashSet进行修改,那么两次遍历的输出顺序是相同的
-
-
顺序不确定的原因(从整体特性角度)
HashSet是基于哈希表实现的,元素的存储位置主要由元素的哈希值决定。它不保证集合中元素的顺序,因为哈希表的存储机制不是按照元素的添加顺序或者其他自然顺序来组织的。- 不同的元素可能因为哈希值和桶的分配规则而有不同的存储位置顺序,这个顺序与元素添加的顺序无关。
-
不能保证顺序固定的原因(从不同实现或环境角度)
- 不同的 Java 实现(如不同供应商的 JDK)可能会对
HashSet的内部实现进行优化,例如改变桶的分配策略或者哈希值的计算方式等。这些改变可能会导致元素的存储顺序不同,从而影响遍历顺序。 - 即使在同一个 Java 实现中,不同的运行环境(如不同的硬件架构、操作系统等)也可能导致
HashSet的内部存储和遍历顺序出现差异,因为底层的内存管理等因素可能会间接影响哈希表的存储和访问方式。
- 不同的 Java 实现(如不同供应商的 JDK)可能会对
-
HashMap、ConcurrentHashMap、HashTable的对比
- 线程安全性
- HashMap是非线程安全
HashMap 的方法(如 put、get、remove 等)没有同步机制,因此在多线程环境中,多个线程同时对 HashMap 进行写操作可能会导致数据不一致或并发错误
- Hashtable是线程安全
Hashtable 的方法是同步的(synchronized),这意味着在多线程环境中,多个线程可以安全地并发访问和修改 Hashtable,而不会导致数据不一致。
- ConcurrentHashMap是线程安全
ConcurrentHashMap 使用了更细粒度的锁(分段锁或基于 CAS 的锁)来实现线程安全,而不是像 Hashtable 那样对整个表进行同步。这使得 ConcurrentHashMap 在多线程环境中性能更高。
- HashMap是非线程安全
- 性能
-
HashMap性能高
由于没有同步机制,HashMap 在单线程环境中性能非常高,适合频繁的读写操作。
在多线程环境中,需要额外的同步机制(如 Collections.synchronizedMap)来保证线程安全,但这会增加性能开销。 -
Hashtable性能低
由于所有方法都是同步的,Hashtable 在多线程环境中虽然安全,但性能较差。每次只有一个线程可以访问表,这会导致较高的锁开销。
-
ConcurrentHashMap性能高
ConcurrentHashMap 使用了分段锁或基于 CAS 的锁机制,允许多个线程同时访问不同的段,从而显著提高了并发性能。
-
在高并发场景中,ConcurrentHashMap 的性能远优于 Hashtable
-
- 空值处理
- HashMap支持空键和空值
HashMap 允许一个键为 null,也允许多个值为 null。
- Hashtable不支持空键和空值
Hashtable 不允许键或值为 null,否则会抛出 NullPointerException。
- ConcurrentHashMap不支持空键,但支持空值
ConcurrentHashMap 不允许键为 null,但允许值为 null。
- HashMap支持空键和空值
- 迭代器
-
HashMap迭代器是快速失败的(fail-fast)
如果在迭代过程中修改了集合(除了通过迭代器的 remove 方法),会抛出 ConcurrentModificationException。
Iterator<Map.Entry<String, Integer>> iterator = hashMap.entrySet().iterator(); while (iterator.hasNext()) {Map.Entry<String, Integer> entry = iterator.next();hashMap.put("newKey", 2); // 抛出 ConcurrentModificationException } -
Hashtable迭代器也是快速失败的
与 HashMap 类似,如果在迭代过程中修改了集合,会抛出 ConcurrentModificationException
-
ConcurrentHashMap迭代器是弱一致的(weakly consistent)
迭代器不会抛出 ConcurrentModificationException,并且在迭代过程中允许对集合进行修改。迭代器返回的元素是基于当前迭代状态的快照,可能会遗漏或重复某些元素。
-
- 使用场景
- Hashtable过时的类
Hashtable 是早期 Java 中的类,现在不推荐使用。如果需要线程安全,建议使用 ConcurrentHashMap 或通过 Collections.synchronizedMap 包装 HashMap。
- ConcurrentHashMap高并发环境
在多线程环境中,ConcurrentHashMap 是最佳选择,因为它提供了高性能的线程安全机制。
需要线程安全且不支持空键。如果需要线程安全且不允许空键,ConcurrentHashMap 是合适的选择。
- Hashtable过时的类
总结
- HashMap:单线程环境,高性能,支持空键和空值。
- Hashtable:线程安全但性能低,不支持空键和空值,已过时。
- ConcurrentHashMap:高并发环境,高性能,线程安全,不支持空键但支持空值。
在实际开发中,推荐使用 HashMap 和 ConcurrentHashMap,尽量避免使用 Hashtable。