机器学习-KNN算法示例
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
# 导入K近邻分类器
from sklearn.neighbors import KNeighborsClassifier
# 导入标准化预处理器
from sklearn.preprocessing import StandardScaler
# 导入数据集划分工具
from sklearn.model_selection import train_test_split# 加载鸢尾花数据集
data1 = load_iris()
# 将数据集划分为训练集和测试集,random_state=22 保证每次划分结果一致
x_train, x_test, y_train, y_test = train_test_split(data1.data, data1.target, random_state=22)# 创建标准化对象
trans = StandardScaler()
# 对训练集进行标准化拟合与转换
x_train = trans.fit_transform(x_train)
# 对测试集进行标准化转换(使用训练集的统计信息)##这样才能保证准确性
x_test = trans.transform(x_test)# 创建K近邻分类器对象,设置邻居数为5
em = KNeighborsClassifier(n_neighbors=5)
# 使用训练集数据训练模型
em.fit(x_train, y_train)
# 使用测试集特征数据进行预测
y_predict = em.predict(x_test)
# 输出模型在测试集上的准确率
print(em.score(x_test, y_test))使用交叉验证与网格搜索优化
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
# 导入K近邻分类器
from sklearn.neighbors import KNeighborsClassifier
# 导入标准化预处理器
from sklearn.preprocessing import StandardScaler
# 导入数据集划分工具
from sklearn.model_selection import train_test_split,GridSearchCV# 加载鸢尾花数据集
data1 = load_iris()
# 将数据集划分为训练集和测试集,random_state=22 保证每次划分结果一致
x_train, x_test, y_train, y_test = train_test_split(data1.data, data1.target, random_state=22)# 创建标准化对象
trans = StandardScaler()
# 对训练集进行标准化拟合与转换
x_train = trans.fit_transform(x_train)
# 对测试集进行标准化转换(使用训练集的统计信息)##这样才能保证准确性
x_test = trans.transform(x_test)# 创建K近邻分类器对象
em = KNeighborsClassifier()
##使用网格搜索与交叉验证实现最优K值的搜索param_grid要用字典的形式给出,cv=10表示是10折
em=GridSearchCV(em,param_grid={'n_neighbors':[1,2,3,4,5,6,7,8,9,10]},cv=10)# 使用训练集数据训练模型,模型进行训练和预测的时候是把param_grid中的每一个值都测试了一遍
em.fit(x_train, y_train)
# 使用测试集特征数据进行预测,选用测试结果最好的哪个进行预测
y_predict = em.predict(x_test)
# 输出模型在测试集上的准确率
print(em.score(x_test, y_test))##整体最好的准确率
print(em.best_params_)##最好的K值
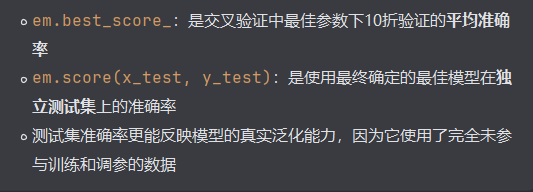
print(em.best_score_)##10折里最优的准确率score与best_score的不同: