强化学习鱼书(7)——神经网络和Q学习
代码地址
书内附代码地址
https://github.com/oreilly-japan/deep-learning-from-scratch-4
环境搭建
0.建立虚拟环境
conda create -n env_test python=3.10
conda activate env_test
1.安装cuda
50系的显卡只支持torch的nightly+cuda12.8版本,别的版本会显示no kernel问题
pip install --upgrade --pre torch torchvision --index-url \ https://download.pytorch.org/whl/nightly/cu128
2.安装Dezero
直接从github上拉<深度学习从零开始3项目>的代码,批量安装依赖
深度学习从零开始3项目
pip install .#测试代码
import numpy as np
from dezero import Variable
x_np = np.array(5.0)
x = Variable(x_np)
y = 3 * x ** 2
print(y) #输出variable(75.0)
线性回归
梯度表示在每个点上函数输出增加最快的方向。反过来说,梯度乘以-1得到的方向就是y值减少最快的方向。因此,如果重复进行沿着梯度的方向前进某个距离 、在新的地点再次求出梯度 ,我们就有望慢慢接近目标位置(最大值或最小值 )。这就是梯度下降法
import numpy as np
from dezero import Variable
import dezero.functions as F
#玩具数据集
np.random.seed(0)
x = np.random.rand(100, 1) #生成 100 行 1 列的二维数组,区间[0,1)
y=5+2*x+ np.random.rand(100, 1)
x, y = Variable(x), Variable(y)
W = Variable(np.zeros((1, 1)))
b = Variable(np.zeros(1))def predict(x):y = F.matmul(x, W) + breturn ydef mean_squared_error(x0, xl):diff = x0 - xlreturn F.sum(diff ** 2) / len(diff)lr = 0.1
iters = 100
for i in range(iters):y_pred = predict(x)loss = mean_squared_error(y, y_pred) #实际y和y=Wx+b的误差W.cleargrad()b.cleargrad()loss.backward()W.data -= lr * W.grad.datab.data -= lr * b.grad.data #求(W,b)的梯度if i % 10 == 0: print(loss.data)
损失函数: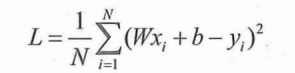
神经网络
进行非线性变换的函数叫作“激活函数”。典型的神经网络会交替使用线性变换和激活函数。
#参数的初始化
I,H,O = 1, 10, 1 #分别为Input维度,Hidden层维度,Output维度
W1 = Variable(0.01 * np.random.randn(I, H))
b1 = Variable(np.zeros(H))
W2 = Variable(0.01 + np.random.randn(H, O))
b2 = Variable(np.zeros(0))#推理
def predict(x):y = F.linear(x, W1, b1)y = F.sigmoid(y)y = F.linear(y, W2, b2)return y#训练
for i in range(iters):ypred = predict(x)loss = F.mean squared error(y, ypred)Wl.cleargrad()bl.cleargrad()W2.cleargrad()b2.cleargrad()loss.backward()W1.data -= lr * W1.grad.datab1.data -= lr * b1.grad.dataW2.data -= lr * W2.grad.datab2.data -= lr * b2.grad.dataif i % 1000 == 0:print(loss.data)
也可以使用Linear类进行线性变换。权重和偏置在linear实例内部,我们可以通过linear.W和linear.b访问它们。另外,也可以通过linear.params访问所有参数。

通过继承Model类可以实现模型,并自定义层的组合来构建神经网络。可以通过model.params()依次访问所有参数。
下面的forward即为推理过程,实现predict(x)一样的效果

因此实际训练过程可以优化成:
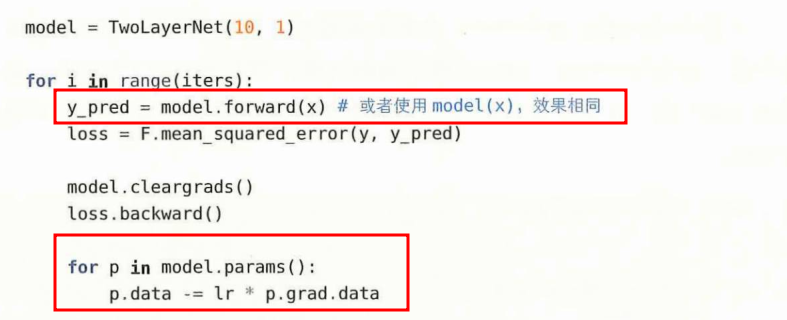
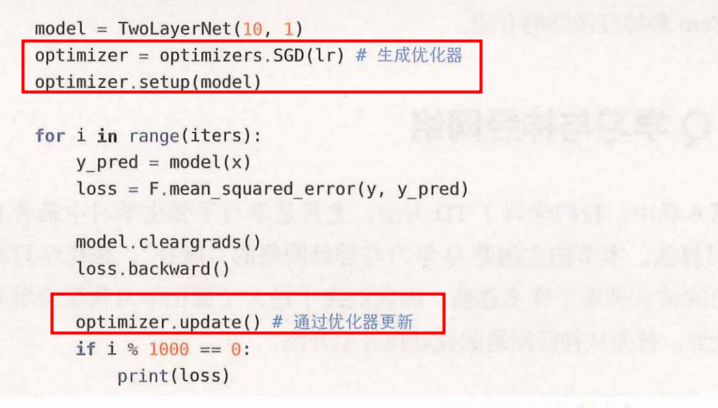
可以使用from dezero import optimizers导入optimizers包,optimizers包中有多种最优化方法。(比如随机梯度下降)。上述代码可更新成
Q学习和神经网络
3X4的网格问题,状态将智能代理的位置以(y,x)这样的数据格式表示
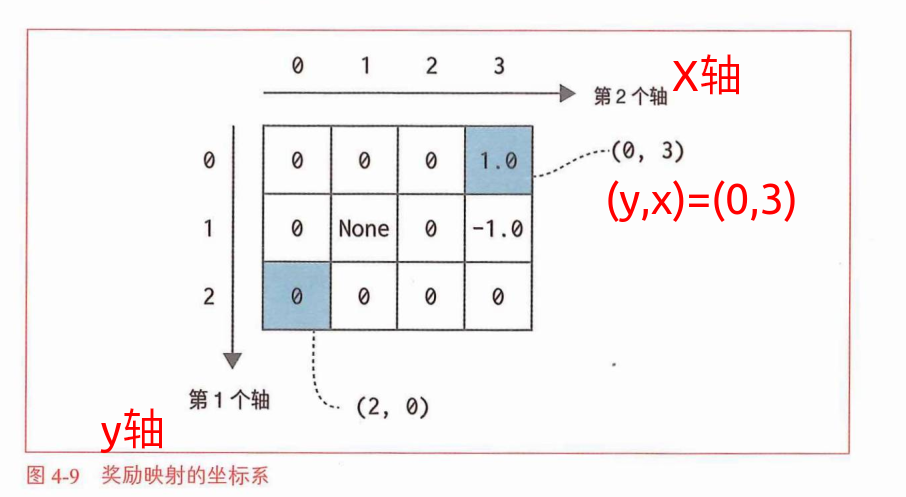
按照从左到右、上到下编号,所以(y,x)=(0,3)=3,idx=4*y+x把[3,4]的矩阵转成[1,12]的矩阵——one-hot
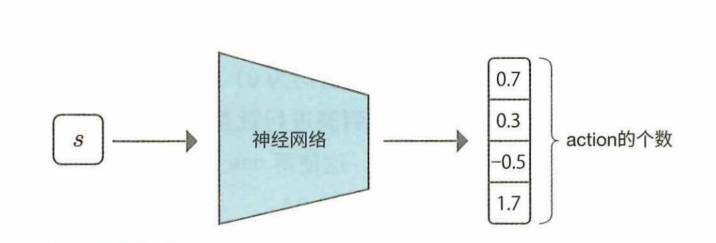
只将“状态”作为输入,输出多个(数量为action个数)Q函数值

1. 建立神经网络模型:输入s,输出Q
建立模型qnet,比如我们的模型是linear+relu+linear——用来计算Q值

2.get_action:St进行At

get_action方法基于e-greedy选择行动。也就是说,它会以e的概率选择随机的行动,否则就选择Q函数值最大的行动
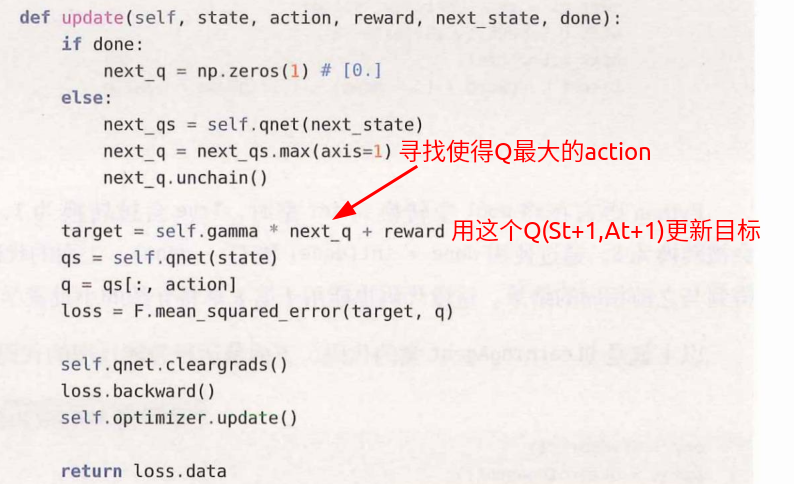
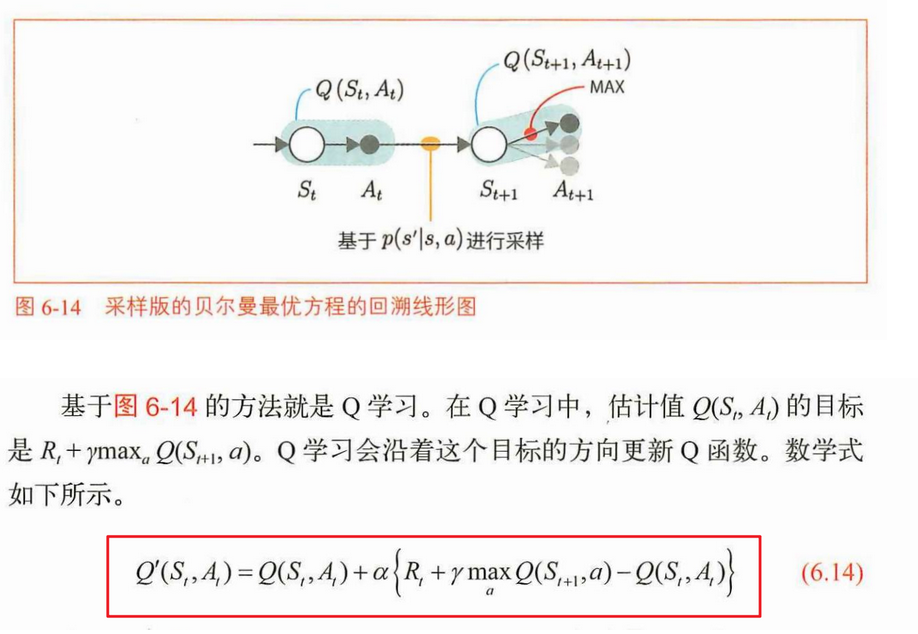
3.update:更新Qt
监督学习不需要与正确答案标签相关的梯度,因此我们使用next_q.unchain()将next_q排除在反向传
播之外(unchain的意思是"解链")。
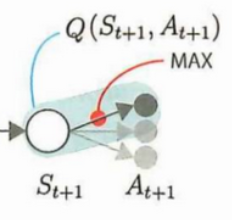
nextq = nextqs.max(axis=1)这一句的意思是St+1 —Qt+1(MAX)— At+1的过程,也就是下面的图