Java 进阶 1.0.1
I/O流
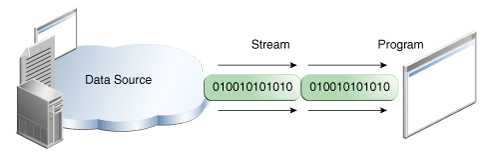
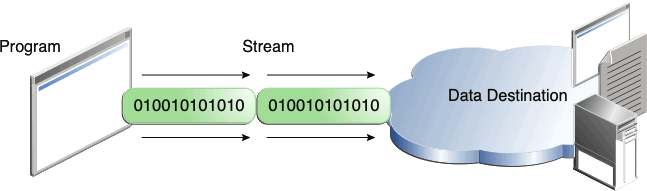
输入输出是相对于数据源来说的
当我们打开一个记事本往里面写东西的时候,就相当于是数据源在往外发送东西,所以是output
当我们读取文件的时候,相当于数据源接受东西,是Input
input
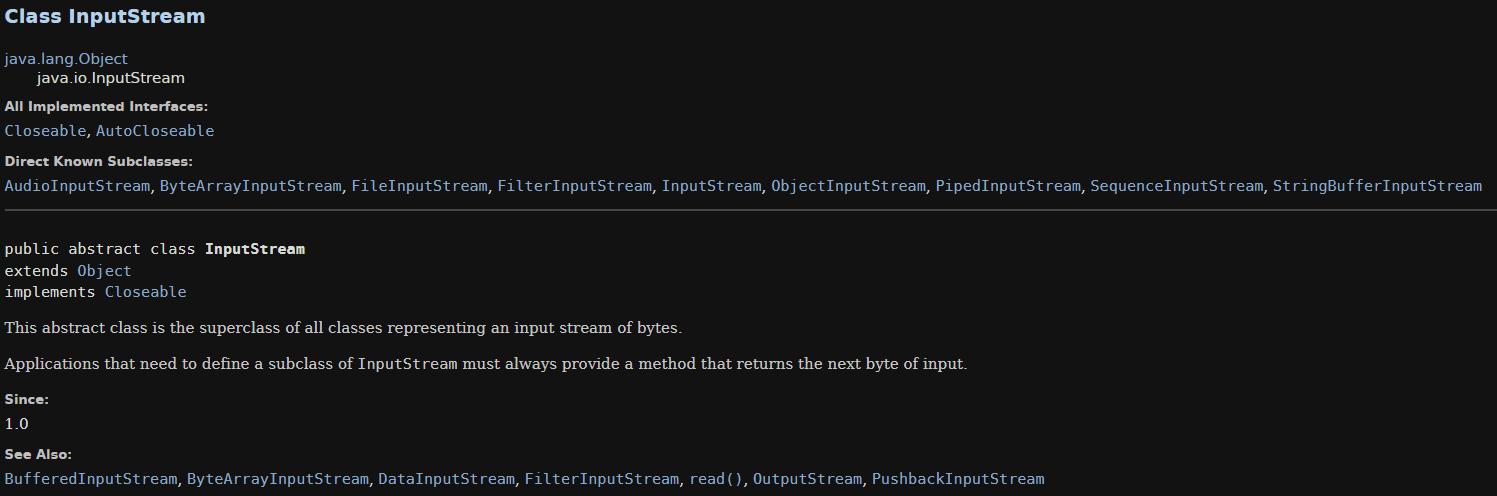
下面是这个接口的子类,可以直接new
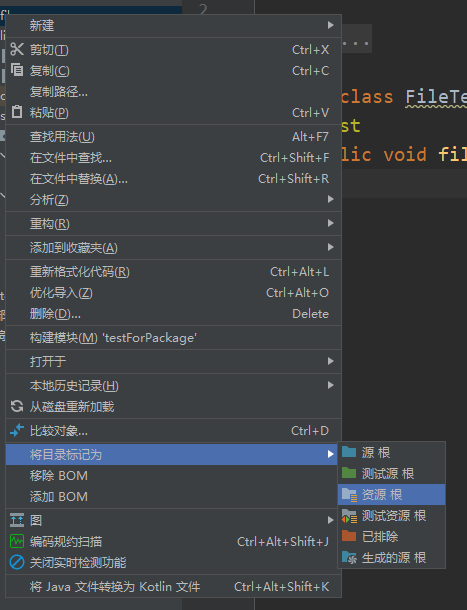
新建一个file文件夹,然后选择将目录标记为资源根,之后在这个目录下面创建1.txt文本文件
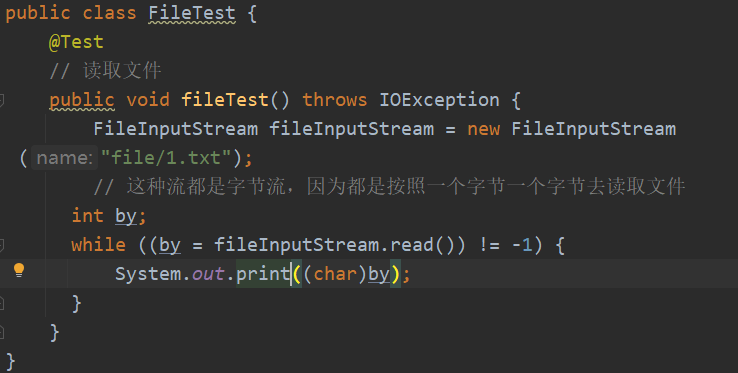
啊这里一定要记得加上.close
一定一定一定记得关上close
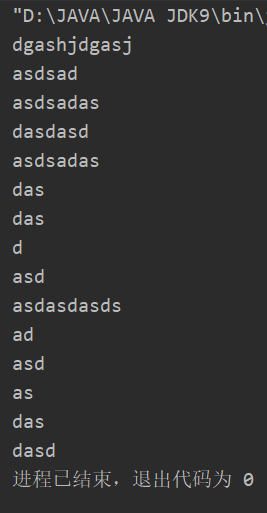
因为是一个字节一个字节读取的,所以要进行(char)的强制转换,为什么用int by是因为-1代表文件流的结束
同时这里需要加入异常签名,防止读取不到文件
output
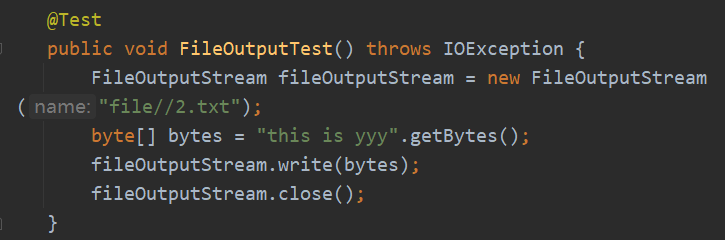
向路径写入文件,如果路径不存在则会创建一个文件夹
文件的复制
@Testpublic void copyFileBase() throws IOException {// 这一步是读InputStream fileInputStream = new FileInputStream("imageTest//haokan.png");// 这一步是写FileOutputStream fileOutputStream = new FileOutputStream("imageTest//target.png");// 创建一个缓冲区// 总好比一个字节一个字节崩好一些byte[] buff = new byte[1024];// 判断标志位int by;// 啥也能copy啊// 这一步是将读取的字节存储到buff中// 这样就是不断的循环了while ((by = fileInputStream.read(buff)) != -1) {fileOutputStream.write(buff, 0, by);}fileInputStream.close();fileOutputStream.close();}
进阶版,不需要自己创建缓冲区了
@Testpublic void bufferFileBse() throws IOException {// 有自带Buffer的函数// 里面的参数是一个流,但是后续也不会需要用到这个流,所以直接在参数里面new一个流就行BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("file/1.txt"));BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("file//3.txt"));int by;// 从缓冲流中读取单个字节(每次调用可能触发缓冲区填充)'// 这个就相当于上面创建字符区// bufferedInputStream.read()这一步就是直接把数据放进了一个8kb的缓冲区// 这种感觉就像是加了一层包装while ((by = bufferedInputStream.read()) != -1) {
// System.out.println((char)by);// 每次写入都是一个字节bufferedOutputStream.write(by);}bufferedInputStream.close();bufferedOutputStream.close();}
FileOutputStream 和 FileInputStream都是字节流,这种是不管什么类型的文件都可以读取
但是如果只想操作文件的话,就可以使用字符流
FIleReader和FileWriter
给人一种感觉就像是字符节版本的,一个一个字符去读取
@Testpublic void FileReaderTest() throws IOException {FileReader fileReader = new FileReader("file//1.txt");int ch;while ((ch = fileReader.read()) != -1) {System.out.print((char) ch);}fileReader.close();}@Testpublic void FileWriterTest() throws IOException {FileWriter fileWriter = new FileWriter("file//4.txt");fileWriter.write("sdhsakdhaskdhasjdkahsjkd");fileWriter.close();}
Buffered版本的
@Testpublic void BufferedWriterTest() throws IOException {BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter("file//555.txt"));bufferedWriter.write("asdsadasdadas");bufferedWriter.newLine();bufferedWriter.write("sdasdasdadasds");bufferedWriter.close();}@Testpublic void BufferedReaderTest() throws IOException {BufferedReader bufferedReader = new BufferedReader(new FileReader("file//555.txt"));String str;while ((str = bufferedReader.readLine()) != null) {System.out.println(str);}bufferedReader.close();}
这里使用Buffered写入的时候需要注意不能使用\n
因为不用的系统对换行的定义是不一样的,所以需要使用newline来代替换行
同理使用buffered读取的时候也需要按行来读,同时输出的时候需要加上println这个符号,这样才能实现换行的效果,因为newline是不会读到换行符的
各种流的一次性讲解
很多可能用不到,工作之后慢慢找文档看咯
IO流一般建议使用jar包,因为有很多很好的方法可以去使用
一般不会用这种很傻逼的形式,因为太低效了
apache Common IO,这个高级
直接搜多apache commons IO进入他的官网,然后查看api文档
frank给的啥jb示例啊,主包还得看java版本的数据结构
这个commons IO 还需要看看文档查一下
软件或者各种文件都存在两种情况
一种是编码一种是解码
java中可以选择编码的方式
public class FileTest {@Testpublic void codeTest() throws UnsupportedEncodingException {byte[] str = "yyy牛逼".getBytes();System.out.println(Arrays.toString(str));byte[] gbk = "yyyniubi".getBytes("gbk");System.out.println(Arrays.toString(gbk));}
}

输出结果就是这样的
字符编码不正确的话一般就是utf8转bgk的问题
Java支持把utf8文件转换成gbk文件
package test;import java.io.File;
import java.util.Collection;import org.apache.commons.io.FileUtils;/*** @author caogenjava.com* @date 2021年6月17日 下午3:57:12*/
public class Convert {public static void main(String[] args) throws Exception {// GBK编码格式源码路径String srcDirPath = "F:\\workspaces\\blog\\src";// 转为UTF-8编码格式源码路径String utf8DirPath = "D:\\UTF8\\src";// 获取所有java文件Collection<File> javaGbkFileCol = FileUtils.listFiles(new File(srcDirPath), new String[] { "java" }, true);for (File javaGbkFile : javaGbkFileCol) {// UTF8格式文件路径String utf8FilePath = utf8DirPath + javaGbkFile.getAbsolutePath().substring(srcDirPath.length());// 使用GBK读取数据,然后用UTF-8写入数据FileUtils.writeLines(new File(utf8FilePath), "UTF-8", FileUtils.readLines(javaGbkFile, "GBK"));}System.out.println("ok");}}
这行代码主包现在看不懂捏,也许日后可以拿下吧
micro_frank