大模型小课堂开课啦!!!
什么是大模型(LLM)
大模型,即大型预训练模型(Large Pre-trained Model),是一类基于海量数据、通过大规模参数训练获得强大通用能力的人工智能模型。其核心特点是通过“预训练+微调”或直接基于强大的基础能力实现对多种任务的处理,是当前人工智能领域的核心技术方向之一。
核心定义与技术特征
- “大”的内涵
- **参数量**级:通常拥有数十亿(1B)到数万亿(100T+)级可训练参数(如GPT-4参数量推测超万亿,DeepSeek-R1-65B为650亿参数),远超传统模型(如早期BERT仅3.4亿参数)。
- 数据规模:基于TB级到PB级的海量数据训练(如GPT-3训练数据量超45TB,涵盖互联网文本、书籍、代码等),数据类型包括文本、图像、语音、视频等多模态信息。
- 技术架构
- 普遍采用Transformer架构(如GPT系列、LLama、DeepSeek等),支持并行计算和长距离依赖建模,能够捕捉复杂语义关联。
- 训练模式分为“预训练”(在通用数据上学习基础能力)和“微调”(针对特定任务优化,如翻译、问答),或直接通过“提示工程”实现零样本/少样本学习(无需额外训练即可处理新任务)。
- 技术原理
大模型(以语言模型为例)是基于 Transformer 架构,通过对大量文本数据的学习,捕捉文本中 token(可以是词、子词等)之间的统计关系。模型将输入的文本转换为数字向量表示,通过多层神经网络计算每个 token 的概率分布,选择概率最高的 token 作为输出。例如,当输入 “我喜欢吃”,模型会根据训练数据中常见的搭配,预测下一个 token 可能是 “苹果”“蛋糕” 等,并输出概率较高的选项。但模型并不知道 “苹果”“蛋糕” 的实际意义,只是基于数据中的模式和概率进行预测。
关键能力与优势
- 涌现能力(Emergent Abilities)
- 随着参数量和数据规模增长,模型会“涌现”出训练数据中未明确编码的能力,如逻辑推理(解决数学题)、创意生成(写故事、代码)、跨语言理解(翻译陌生语言)等。
当AI模型变得超级大(比如千亿参数!),可能就会突然解锁“超能力”——比如无师自通奥数题、还会编故事、甚至会玩网络热梗了!这就是「涌现」
- 例如: * GPT-4能通过律师资格考试、理解复杂逻辑题; * DeepSeek-R1在代码生成和数学推理上表现突出。
-
- 通用任务处理能力
- 打破传统AI“单一任务专项模型”的局限,一个大模型可同时处理自然语言理解(NLP)(问答、摘要)、生成任务(文本、图像、语音合成)、跨模态任务(图文交互,如根据图片生成描述)等。
- 例:MidJourney(图像生成大模型)、ChatGPT(语言大模型)、GPT-4(多模态大模型)。
- 泛化与迁移能力
- 对未见过的场景或任务具备适应性,通过“提示词(Prompt)”调整即可完成新任务,无需重新训练。例如:
- 输入“用Python写一个冒泡排序算法”,大模型可直接生成代码;
- 输入“总结以下论文摘要”,无需微调即可完成文本摘要。
- 对未见过的场景或任务具备适应性,通过“提示词(Prompt)”调整即可完成新任务,无需重新训练。例如:
典型应用场景
- 自然语言处理(NLP)
- 对话交互(ChatGPT、豆包)、文本生成(写邮件、小说)、知识问答(百科查询)、机器翻译等。
- 多模态生成
- 图像生成(MidJourney、DALL-E)、视频生成(Runway)、语音合成(ChatGPT语音功能)、图文混合创作(GPT-4的图文理解)。
- 专业领域辅助
- 代码开发(GitHub Copilot自动补全代码)、教育(智能辅导、作业批改)、医疗(病历分析、辅助诊断)、科研(论文生成、数据分析)等。
- 行业智能化
- 客服机器人(降低人力成本)、内容审核(识别违规信息)、智能营销(个性化文案生成)等。
挑战与争议
- 算力与成本
- 训练大模型需数千张高端GPU(如NVIDIA H100),单次训练成本可达数百万美元,加剧技术垄断风险。
- 数据质量与偏见
- 训练数据可能包含虚假信息、偏见(如性别/种族刻板印象),导致模型输出错误或不公平内容。
- “幻觉”问题
- 如前所述,模型可能生成逻辑合理但违背事实的内容(详见历史对话中“大模型幻觉”的解释),在医疗、法律等领域可能引发风险。
- 伦理与社会影响
- 虚假内容生成(如深度伪造)、就业冲击(替代部分重复性工作)、用户隐私(训练数据可能包含敏感信息)等。
大模型是AI从“专项工具”迈向“通用智能”的关键一步,其核心价值在于通过“规模化”(大参数、大数据)实现能力的“涌现”和“泛化”,让AI具备接近人类的多任务处理能力。尽管存在算力门槛、幻觉、伦理等挑战,但其在效率提升、创新赋能上的潜力巨大,正深刻改变互联网、教育、科研、生产等多个领域。未来,大模型将与行业深度融合,推动AI从“辅助工具”向“智能伙伴”进化。
大模型,如常见的语言模型,从本质上来说是基于概率预测下一个可能出现的 token,而并非像人类一样真正理解内容或掌握事实,以下从技术原理、训练方式等角度详细阐述:
大模型知识点
推理模型 vs 通用模型
推理模型 = 学霸解题 (大模型有自己的思考过程)
生成模型 = 才子写诗(直接输出答案)
推理模型
推理模型(Reasoning Models)主要聚焦于分析、理解和推断已有信息,以解决逻辑性强或需要深度思考的问题。这类模型通过对输入数据的模式识别、因果分析或规则应用,得出结论或预测结果。它们擅长处理需要逐步推导的任务,比如数学运算、逻辑推理、问题诊断或决策支持。推理模型的核心在于“理解”和“推演”,强调准确性和可解释性。例如,在一个复杂的多步骤数学问题中,推理模型会分解问题、应用规则,并逐步得出答案。实际应用中,推理模型常用于知识问答、法律分析、科学假设验证等领域。目前主要的推理模型有:DeepSeek R1、Kimi 1.5、OpenAI o1、OpenAI o3-mini、Gemini 2.0、Grok3
生成模型(通用模型)
生成模型(Generative Models)则侧重于创造新内容,根据输入的提示或上下文生成符合逻辑或具有创造性的输出。这类模型基于大量数据的概率分布,学习如何“生成”看似合理的文本、图像或其他形式的内容。它们更擅长发散性任务,比如写文章、生成对话、创作艺术作品或模拟人类语言。生成模型的核心在于“创造”和“流畅性”,更强调输出的自然性和多样性。例如,给定一句开场白,生成模型可以续写一个完整的故事。应用场景包括内容创作、对话系统、图像生成(如DALL·E)等。目前主要的生成模型有:文心一言、GPT-3.5
双休模型
即支持推理也支持生成:Qwen3
推理模型和生成模型的区别:
- 目标:推理模型追求准确的结论,生成模型追求自然的内容。
- 过程:推理模型依赖逻辑推导,生成模型依赖模式生成。
- 输出:推理模型输出通常是结构化的答案或预测,生成模型输出是开放性的内容。
- 应用:推理模型适合需要严谨分析的场景,生成模型适合需要创意表达的场景。
在实际产品设计中,这两者可以互补。例如,一个智能助手可能用推理模型解答用户的逻辑问题(如“如何优化投资组合”),再用生成模型生成用户友好的解释或建议。两者的结合能够提升产品的智能性和用户体验。
模型类型
- 文本生成
- 嵌入模型
- 重排序模型
- 语音识别
- 语音合成
- 视觉模型
- 图片生成
参数
在大模型命名中,数字 + B 的组合(如 671B)是参数规模的标准表示方式:
- B = Billion(十亿):671B 即 6710 亿 个可训练参数。
- 参数的本质:参数是模型在训练过程中学习到的权重和偏差,类似于人类大脑的 “神经元连接”。参数越多,模型理论上能捕捉的语言模式越复杂,推理能力越强。
示例:
- DeepSeek-R1 系列中,671B 是 “满血版” 基础模型,而 1.5B、7B、70B 等是蒸馏后的轻量化版本。
- 其他主流模型如 GPT-3(175B)、Llama 3(70B/405B)也采用相同命名规则。
蒸馏
DeepSeek-R1 系列中,671B 是 “满血版” 基础模型,而 1.5B、7B、70B 等是蒸馏后的轻量化版本
那么蒸馏啥意思呢?
蒸馏的本质:让小模型 “偷学” 大模型的知识
- 类比理解
- 大模型(如 671B 参数的 DeepSeek)是 “学霸老师”,知识丰富但体积庞大、运行慢;
- 小模型(如 7B 参数的轻量化版本)是 “聪明学生”,通过观察老师的解题过程(输出结果),学会用更少的 “大脑资源” 达到接近老师的水平。
- 核心目标:把大模型的 “隐性知识”(如对数据的深层理解)提炼到小模型中,让小模型在保持高性能的同时,体积更小、速度更快、能耗更低。
Prompt(提示词)
Prompt 的本质:给模型的 “行动指南”
Prompt 是人与 AI 沟通的 “语言桥梁”,其质量直接决定模型输出的效果。无论是简单的指令、复杂的思维链,还是角色扮演,本质都是通过精心设计的提示词,引导模型调用正确的知识和推理路径。掌握 Prompt 设计技巧,能让普通人更高效地使用 AI,也让开发者能解锁模型的更多潜力。
- 核心作用:通过设计恰当的提示词,让模型理解用户意图,生成符合预期的内容。
- 为什么 Prompt 如此重要?
- 大模型本身不具备真正的 “理解” 能力,而是基于训练数据中的统计规律生成内容。
- 优质 Prompt 能引导模型聚焦正确的知识领域,避免生成无关或错误的信息。
示例:
- <font style="color:rgba(0, 0, 0, 0.85) !important;">模糊 Prompt:“写点关于环保的东西” → 模型可能生成泛泛而谈的内容。</font>
- <font style="color:rgba(0, 0, 0, 0.85) !important;">精确 Prompt:“以海洋塑料污染为主题,写一篇 300 字的新闻稿,包括现状、危害和解决方案” → 模型输出更结构化、针对性更强的内容。</font>
飞桨AI Studio星河社区-人工智能学习与实训社区
Token(词元)
Token 的本质:文本的 “数字化切片”
简单来说,Token 是将文本拆解后的最小意义单元,模型通过处理这些单元的数字编码来理解语言。
- 举例
- 英文句子 “I love AI” 可能被拆分为
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">["I", "love", "AI"]</font>三个 Token; - 中文句子 “我爱人工智能” 可能被拆分为
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">["我", "爱", "人工", "智能"]</font>(按词语拆分),或<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">["我", "爱", "人", "工", "智", "能"]</font>(按单字拆分),甚至更小的子词单元(如 “人工智能” 拆为 “人工”+“智能”)。
- 英文句子 “I love AI” 可能被拆分为
- 核心作用:将人类语言(文本)转化为模型能处理的数字序列(如
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">[101, 200, 300, 400]</font>),类似将文字转化为模型的 “密码”。
SSE
SSE(Server-Sent Events,服务器发送事件)
- 特点:
- 单向通信(服务器 → 客户端),适用于大模型输出流式文本的场景。
- 基于 HTTP/1.1 及 EventSource API,兼容性较好,易于集成。
- 自动重连,如果连接断开,浏览器会自动尝试重新连接。
- 轻量级,开销小,适合传输文本数据。
- 缺点:
- 只支持 服务器推送,客户端无法主动发送消息(需要用 AJAX/Fetch 结合)。
- 受 同源策略 影响,跨域时需要 CORS 配置。
- 在 HTTP/2 之前,SSE 只能打开 6 个连接(浏览器限制),但在 HTTP/2 上可复用单连接,问题减小。
- 适用场景:
✔ 流式返回(如 ChatGPT 逐字输出)
✔ 服务器向前端持续推送数据(如股票行情、日志监控)

deepseek


文心一言

chatgpt

大模型幻觉
什么是大模型幻觉?
大模型“幻觉”是指大型语言模型(LLMs)生成的内容与现实世界事实或用户输入不一致的现象。
大模型“幻觉”是指模型自信地生成了看似真实、实则虚构或错误的信息。从使用者角度来看,模型表面上博学多才,实际上可能只是一本正经地“胡说八道”。
幻觉分类
忠实性幻觉
模型生成的内容与用户的指令或上下文不一致
可分为三种情况:
- 生成内容不遵循用户指令
例子:用户让大模型翻译“I love sleeping.”,大模型回答“我也喜欢睡觉”。
- 生成内容和用户提供的上下文信息冲突
例子:让大模型总结一篇文章,文章明确写着“《阿凡达2》在2022年上映”,但模型总结时却写成了“《阿凡达2》在2021年上映”。
- 生成内容逻辑前后矛盾
例子:大模型生成的内容上半部分说“企鹅不会飞”,下半部分又说“企鹅能飞到南极”,前后自相矛盾。
事实性幻觉
指生成内容与真实世界知识不符或无法考证,
可分为两种情况:
- 生成内容与世界知识不符
例子:用户问“自由女神像在哪”,模型回答“英国”,实际上位于美国。
- 生成内容无法考证
例子:用户问“独角兽起源于哪个国家”,模型回答“古希腊”,但独角兽的存在并未证实,因此其起源国家也无法被历史资料验证。

为什么会产生幻觉?
- 概率问题:大模型推理本质是根据上下文,基于概率预测下一个最可能出现的token,并不是真正理解内容或掌握事实。
- 训练数据质量:模型学习的数据中本身可能包含错误、虚假或过时的信息,导致生成内容时复现这些问题。
- 缺乏实时事实验证:大模型生成内容时无法实时核查事实真假,因此容易在细节、数字、引用等方面出现偏差或错误。
- 提示词问题:如果输入的提示词本身含糊、带有错误或具有误导性,模型很容易沿着错误方向生成回答。
如何缓解大模型幻觉?
- 提示词工程优化:通过清晰、具体、有背景的提示词减少理解偏差,结合多轮对话引导用户补充信息,使模型持续校正回答
- RAG或工具辅助:在生成前检索知识库或调用工具,提供可靠信息作为参考,提升回答的准确性和一致性
- 提升训练数据质量:筛选干净、准确、权威的数据进行训练,定期更新,减少模型学习到过时或错误的信息
- 模型能力增强:让模型同时学习文本生成和事实验证任务,从而在生成内容时具备自我检查和纠错的能力
向量化
什么是向量化?
向量化是将非数值型的数据,如文本、图像、音频等,转化为数值向量的过程。通过向量化,能将各种类型的数据转化为计算机易于处理和分析的数字形式,以便于机器学习和其他数据处理算法进行操作。以下是一些常见数据类型向量化的方法
白话说向量
向量化听起来很复杂,但其实就是把东西变成数字。比如,你有一本书,里面有很多文字,计算机不太擅长直接理解文字,所以我们就把文字转化成一串串数字,这样计算机就能更容易地处理和理解这些信息了。这个过程就叫做“向量化”。打个比方,就像把一本书的内容转化成一串串密码,计算机可以更容易地“读”懂这些密码。
向量数据库
向量数据库是一种专门用于存储和管理向量数据的数据库系统。它能够高效地处理大规模的向量数据,支持快速的向量检索和相似性计算,在人工智能、机器学习、信息检索等领域有着广泛的应用。
在文本、图像、音频等多媒体信息检索中,将这些信息转化为向量后存储在向量数据库中。用户可以通过输入相似的查询向量来快速找到与之相似的文本、图像或音频文件。
Embedding Models(嵌入模型)
嵌入模型是一种将离散数据(如文本中的词语、句子、段落或文档)转换为连续向量的技术。这些向量在多维空间中表示不同的语义信息,通过计算向量间的距离或相似度,我们可以判断文本间的语义相似性。
什么是 Embedding?
Embedding(嵌入),就是把“人类能理解的信息”变成“机器能理解的数字”!
知识库
知识库的技术架构分为两部分:
第一、离线的知识数据向量化
- 加载:加载数据/知识库。
- 拆分:将大型文档拆分为较小的块。便于向量或和后续检索。
- 向量:对拆分的数据块,进行 Embedding 向量化处理。
- 存储:存储到向量数据库中,方便进行搜索。
第二、在线的知识检索返回
- 检索:根据用户输入,使用检索器从存储中检索相关的数据块。
- 生成:使用包含问题和检索到的知识提示词,交给大语言模型生成答案。
总之,知识库是 AI 大模型应用的知识基础。
嵌入模型在本地知识库中的应用
- 知识库数据预处理
- 将知识库中的文档、段落、问答对转化为向量,构建向量数据库;
- 一篇文档 → 分割为段落 → 每个段落生成向量 → 存入向量库。
- 语义搜索与检索
- 用户输入查询语句 → 转化为查询向量 → 与知识库向量比对(余弦相似度)→ 返回最相关结果。
- 将用户问题与知识库问答对向量匹配,实现智能客服。
Rerank Models(重排模型)
重排序模型是指在初步检索(如基于嵌入模型计算相似度)后,进一步对候选结果进行二次排序的模型。它的目的是根据更多细粒度的信息和上下文特征,调整候选结果的排序,使最终输出更加精准、符合用户需求;
- 提高检索准确性:初步检索可能返回较多噪声,重排序模型通过更精细的特征融合,对结果进行优化排序。
- 利用更多信息:可以结合查询和候选结果的上下文信息、结构信息等,提供更全面的评分依据。
温度系数
模型输出逻辑:
大模型(如GPT)在生成文本时,每一步都会计算所有可能候选词(Token)的概率分布,然后根据这个分布选择下一个词。
温度的作用:
温度系数会修改这个概率分布,具体公式是: 调整后的概率=exp(原始概率/temperature) 温度系数通过这个公式改变概率分布的“尖锐程度”,控制生成结果的随机性。
温度系数的直观理解
- 低温:相当于“严格遵循课本知识”,模型不敢冒险,确定性高,适合严肃任务。
- 高温:相当于“喝醉的诗人”,模型可能说出意想不到的句子,但也可能胡言乱语,创意爆炸,适合探索性任务。
- 温度=0:完全确定性的输出(选择概率最高的词),但实际应用中通常不会设为0。
RAG (检索增强生成)
RAG为大模型提供一些外部知识库,通过"检索"外部信息,"增强"模型对用户问题的理解,从而优化"生成"质量
为什么需要RAG?
因为原始的大模型,主要依赖预训练数据(即模型的内部知识)来处理问题,无法获取更新的数据,也难以掌握更专业更私有的信息,比如最新的科技发明、某公司的内部政策,这就导致它在回答相关问题时,在时效性和准确度方面都大打折扣,容易出现 “AI幻觉”(即自信地瞎编)
RAG,在不改变模型本身的情况下,扩大了模型的知识面,不仅使AI生成的内容更精准,还大大提高了模型的泛化能力(即灵活处理不同类型、不同场景下的新任务的能力)
Function Call(函数调用)
什么是Function Call?
函数调用允许将gpt-4o等大模型连接到外部工具和系统。就像大模型的“手和脚”,让大模型具备更多和外部交互的能力。
核心作用
Function Call本质上只做了一件事,那就是准确识别用户的语义,将其转为结构化的指令。这里的结构化的指令其实指的就是要调用的函数的名称和入参,有了函数名称和调用参数,我们就可以调用函数并把结果发送给LLM,让LLM给出更个性化的回答
原理和步骤
- 按照特定的规范将函数绑定到大模型上,这个定义通常会以json格式列出函数名、函数描述、参数、参数描述、参数类型等信息;用户向发出提示词(prompt)
- 根据函数的定义,大模型判断是否调用某个或多个函数,大模型会给出工具选取建议和相关的请求参数。
- 应用程序根据模型响应调用相关函数
- 应用程序将函数响应的内容和用户prompt再次输入给模型,生成人类可读的内容
- 应用程序将最终响应返回给用户,然后再次回到第 2 步,如此循环往复
MCP
MCP(Model Context Protocol,模型上下文协议) 是Anthropic公司(Claude)推出的AI“万能接口”,相当于AI界的USB-C,它能通过统一的通信标准,一键连接大模型和外部工具(浏览器、数据库、代码库等),让AI直接操作真实世界的数据和系统。
示例:用ChatGPT写代码后,AI能直接通过MCP提交到GitHub,无需手动操作!
为什么需要MCP?
痛点:以前AI就像个“哑巴”,想让它查资料、改文件、发邮件,得程序员专门写代码“翻译”需求。
MCP的作用:给AI配个“智能翻译器”,让它能和数据库、手机APP、办公软件等直接进行“对话”,自己解决问题!
MCP和API、Functional的区别
- MCP 就像给AI装了个智能工具箱,能自动识别各种工具并协作完成复杂任务(比如你让AI助手订旅行行程,它会自己查机票、比价格、订酒店,过程中还能实时反馈进度)
- 传统API 像是固定电话,每次只能问一个问题且必须等回复(比如查天气只能单独问一次)
- Function Calling 则像智能音箱的快捷指令,虽然方便但只能控制特定品牌的设备
ModelScope - MCP 广场
Agent(智能体)
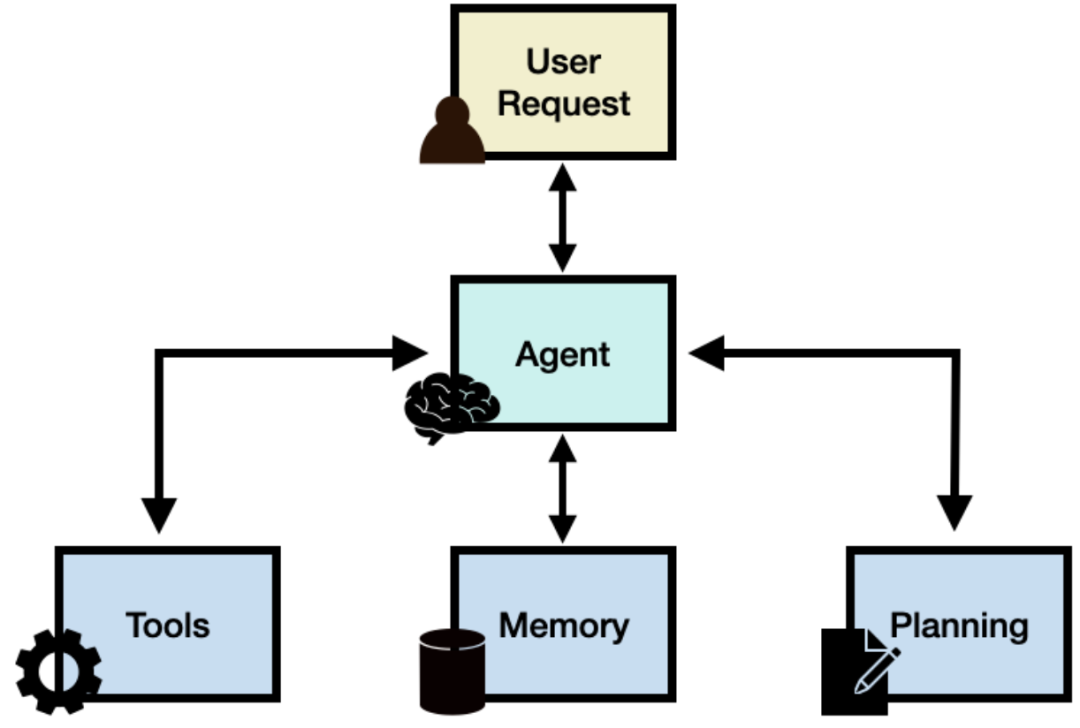
任何具备独立思考能力并能与环境进行交互的实体,都可以被抽象地描述为智能体(Agent)。 Agent构建在大语言模型的推理能力基础上,对大语言模型的 Planning 规划的方案使用工具执行(Action) ,并对执行的过程进行观测(Observation),保证任务的落地执行。
Agent 智能体 = 大语言模型的推理能力 + 使用工具行动的能力。
大模型(LLM):作为 Agent 的 “大脑”,大模型在系统中提供推理、规划等能力,负责理解自然语言输入,生成相应的输出,是 AI Agent 实现的前提和基础。
规划:这是 Agent 的思维模型,负责将复杂任务拆解为可执行的子任务,并评估执行策略。通过大模型提示工程(如 ReAct、CoT 推理模式),使 Agent 能够精准拆解任务,分步解决。
记忆:即信息存储与回忆,包括短期记忆和长期记忆。短期记忆用于存储会话上下文,支持多轮对话;长期记忆则存储用户特征、业务数据等,通常通过向量数据库等技术实现快速存取。
工具使用:工具是 Agent 感知环境、执行决策的辅助手段,如 API 调用、插件扩展等。通过使用各种工具,Agent 能够与外部环境进行交互,获取更多信息,完成各种复杂任务。
那么如何部署一套自己的大模型呢
大模型推理引擎
- ollama
Ollama
- vllm
欢迎来到 vLLM! | vLLM 中文站
- Xinference
示例 — Xinference
- 等等
一文了解八款主流大模型推理框架_大模型推理引擎-CSDN博客
- gpustack
https://gpustack.ai/
可视化
Open WebUI
Dify.AI · 生成式 AI 应用创新引擎
MaxKB:强大易用的 AI 助手
AnythingLLM | The all-in-one AI application for everyone
项目简介 | CherryStudio
openai-openapi
api标准规范
进阶
有机会下次再讲
- 模型微调
- 模型调参
- 模型预训练
- MOE
- 精度
其他
ModelScope - 模型列表页
MCP Server(MCP 服务器)
DeepSeek