Better Faster Large Language Models via Multi-token Prediction 原理
目录
模型结构:
Memory-efficient implementation:
实验:
1. 在大规模模型上效果显著:
2. 在不同类型任务上的效果:
为什么MLP对效果有提升的几点猜测:
1. 并非所有token对生成质量的影响相同
2. 关键选择点的权重累积机制
3. 从互信息的角度解释
4. 因果语言模型的传统因子化顺序
屈折语中的语法一致性挑战
非因果因子化顺序的优势(多token预测提升对复杂语法结构(如屈折、一致关系)的处理能力)
通过隐式建模非因果依赖,减少因局部错误导致的全局矛盾
问题:
模型结构:
单token预测:
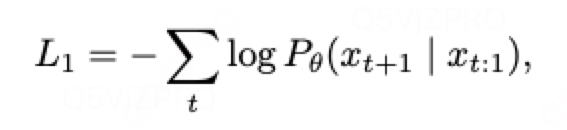
多token预测:
model 应用一个共享trunk来针对
产生一个latent 表示
,接着送入到n个独立的head来并行预测未来n个tokens。
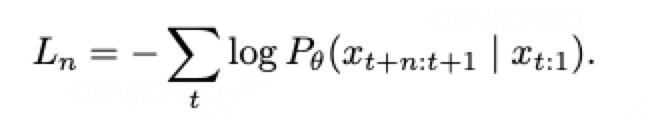
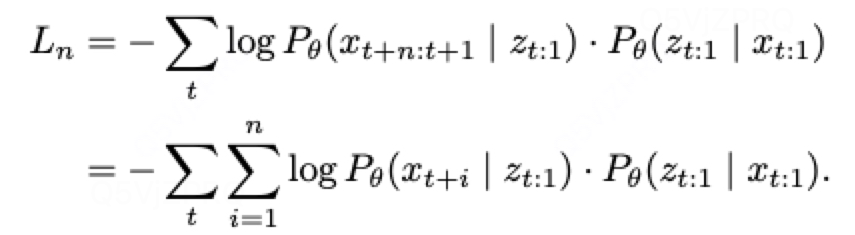
其中:
![]()
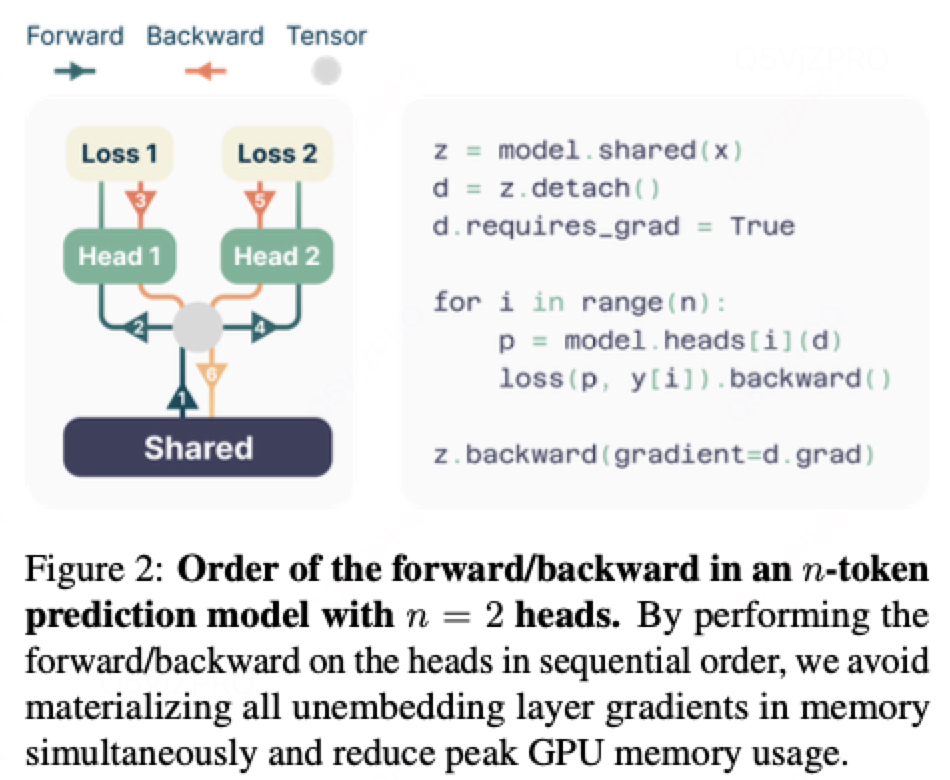
Memory-efficient implementation:
由于词表大小V远大于维度d,所以logit的计算,由(d,V)变化为 (d,V*N),是GPU memery使用的瓶颈。解决办法为序列话的计算每个独立输出头的前向和反向传播过程,在trunk进行梯度累加。在计算
之前
的计算已经被释放掉。将CPU的memery峰值从
降低为
。
实验:
1. 在大规模模型上效果显著:
小规模模型的局限性
-
模型容量不足:小模型(如百万或十亿参数级)难以同时捕捉多个时间步的复杂依赖关系。多令牌预测需要模型理解长距离上下文和跨步关联,这对小模型来说过于困难。
-
边际收益低:在小规模实验中,多令牌预测可能仅带来微弱的效果提升(如困惑度略微下降),无法证明其额外计算成本是合理的。
2. 在不同类型任务上的效果:
2.1在choice task上面没有提升性能,可能需要放大模型大小才能看到效果。
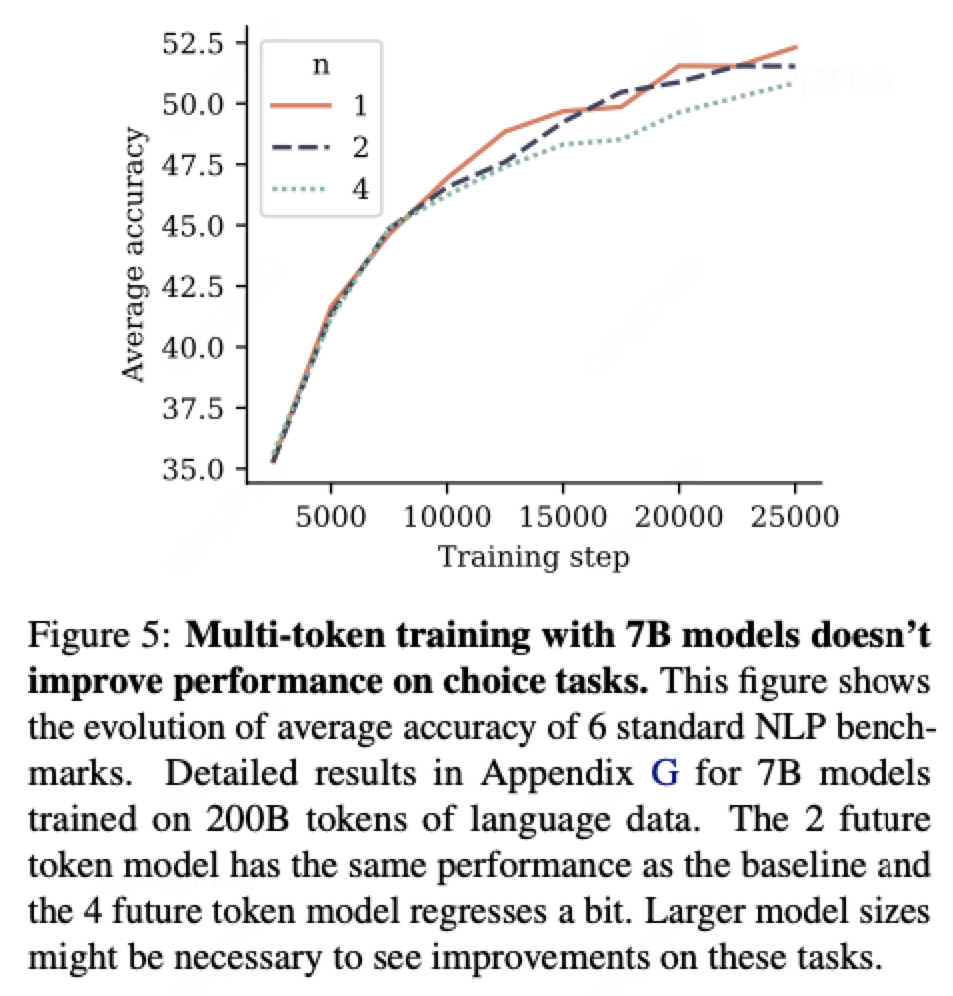
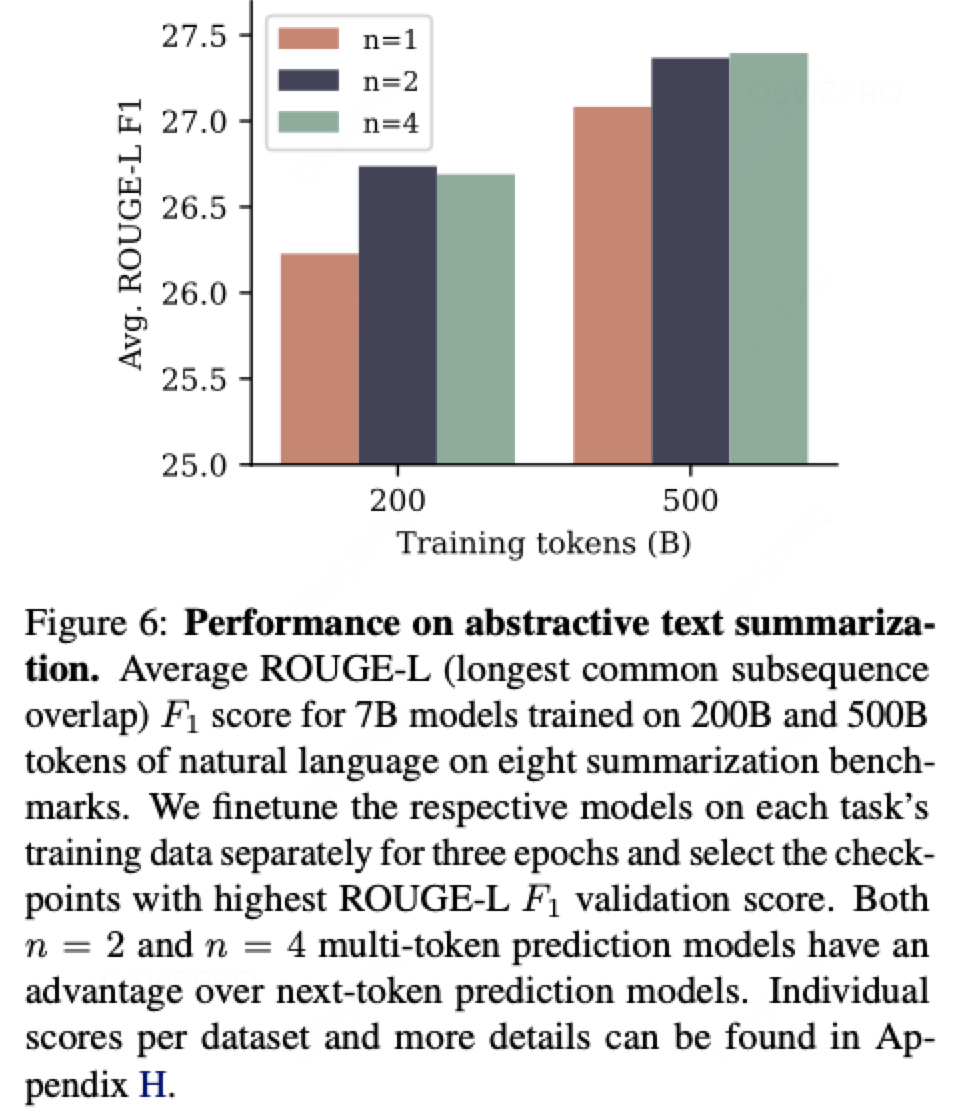
2.2 在抽象文本总结任务上有提升:
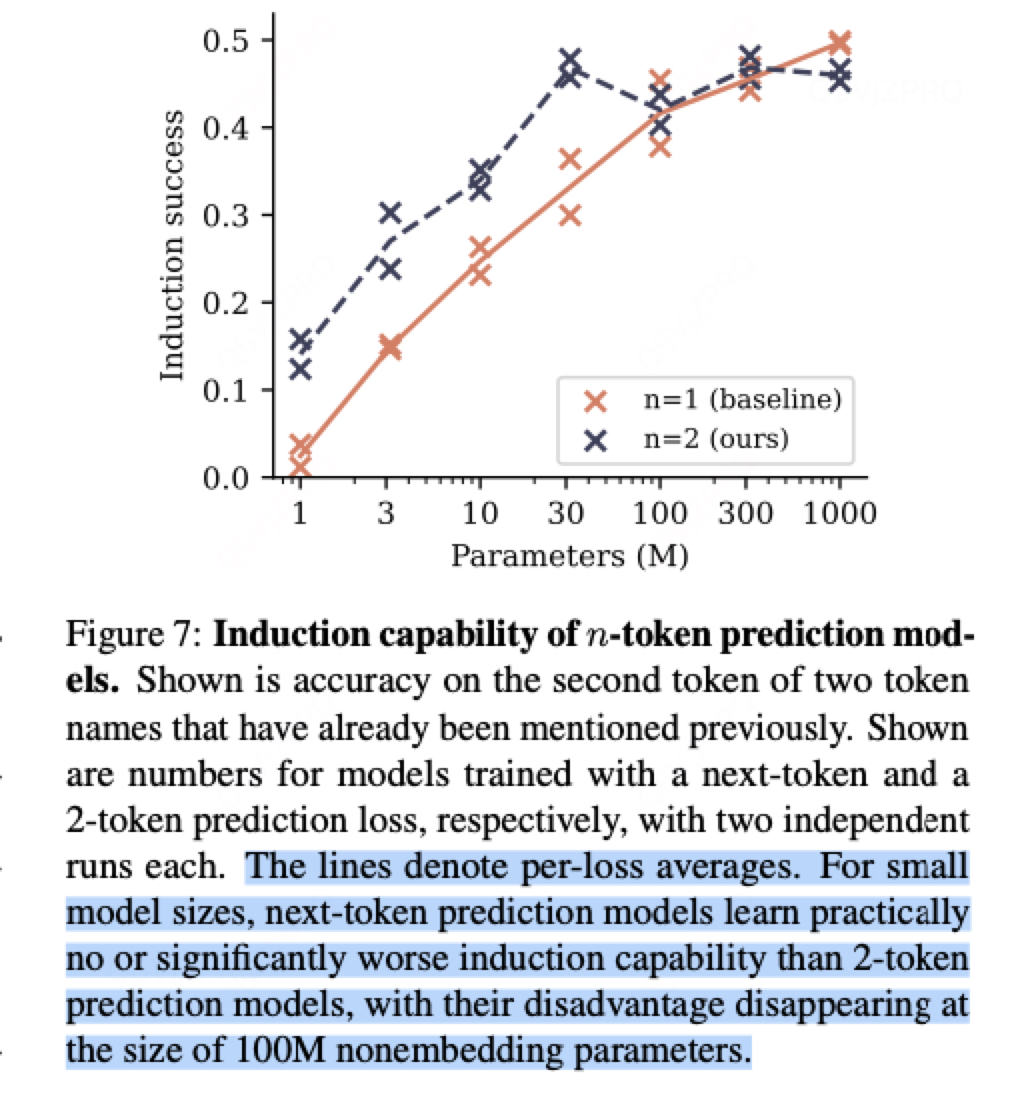
2.3:归纳能力:随着模型大小增大,两者能力趋于相同。
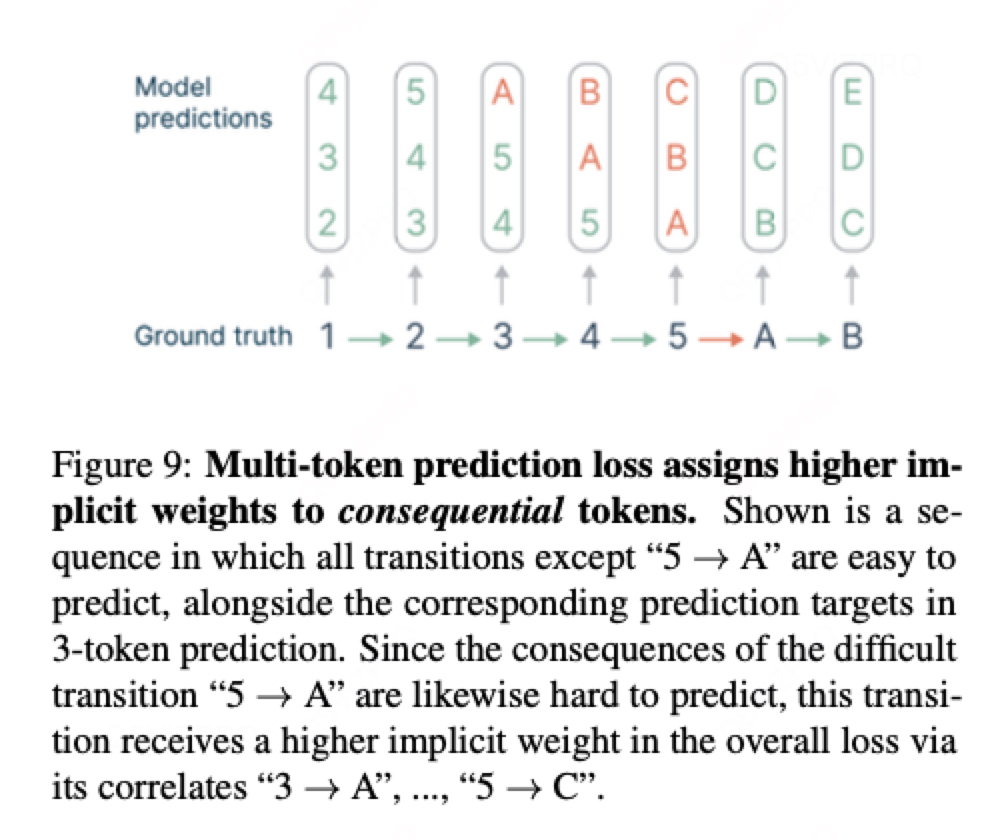
为什么MLP对效果有提升的几点猜测:
1. 并非所有token对生成质量的影响相同
在语言模型生成文本时,某些token的决策对整体质量至关重要,而另一些则影响较小(如风格变化)。
-
关键选择点(Choice Points):影响文本高层语义的token(例如问答中的核心术语、逻辑转折词),错误会导致回答偏离主题。
-
无关紧要的token(Inconsequential Transitions):仅影响局部风格(如近义词替换),不影响后续内容。
2. 关键选择点的权重累积机制
关键选择点(如位置 t)的决策错误会直接影响后续多个token的生成。例如:
-
若模型在 t 处预测错误,可能导致 t+1,t+2,…,t+n 的预测全部偏离正确路径。
-
此时,总损失中会包含 Lt+1,Lt+2,…,Lt+n,这些损失均与 t 处的错误相关。
数学推导(以n=5为例):
-
关键选择点(如位置 t)的错误会影响后续5个token的预测,其总权重为:
这里的权重 k 表示第 k 步的损失对关键点的梯度贡献。
-
无关紧要的token(如位置 t+1)仅影响后续4个token,总权重为
,但实际实现中可能简化为固定权重 n。
多token预测的损失函数在反向传播时,关键点的梯度会从多个未来位置的损失中累积:
-
传统自回归:位置 t 的错误仅通过 Lt+1的梯度更新参数。
-
多token预测:位置 t 的错误通过 Lt+1,Lt+2,…,Lt+n 的梯度叠加更新参数,形成更高的有效权重(梯度在反向传播时会自然累积到共同依赖的关键点上)。
例如,若位置 t 是生成回答中的核心术语(如“量子力学”),其错误会导致后续所有相关解释偏离正轨。此时,模型从多个未来位置的损失中接收到更强的信号,迫使它优先学习正确预测此类关键点。
3. 从互信息的角度解释
还没完全理解,理解后再更新
4. 因果语言模型的传统因子化顺序
-
基本公式:因果语言模型(如GPT)将文本序列的联合概率分解为自回归形式,即按时间顺序逐个预测下一个token
-
特点:生成顺序严格从前向后(如首先生成 x1,再基于 x1 生成 x2,依此类推)。
-
局限性:某些语言结构(如屈折语中的语法一致性)需要逆向或跳跃式依赖,传统顺序可能不高效。
屈折语中的语法一致性挑战
-
示例:德语句子
Wie konnten auch Worte meiner durstenden Seele genügen?
包含以下语法依赖:-
动词 genügen 要求其宾语为与格(Dative Case)。
-
名词 Seele 为阴性单数与格,因此所有修饰成分(如物主代词 meiner 和分词 durstenden)必须与其在性、数、格上一致。
-
-
关键矛盾:
-
传统自回归顺序需先生成 meiner 和 durstenden,再生成 Seele 和 genügen。
-
但实际上,后续的 genügen 和 Seele 的语法要求决定了前面的 meiner 和 durstenden 的形式。
-
非因果因子化顺序的优势(多token预测提升对复杂语法结构(如屈折、一致关系)的处理能力)
-
逆向推理:若模型能先预测后续关键token(如 genügen 和 Seele),再生成前面的修饰词(如 meiner 和 durstenden),可更高效确保语法一致性。
-
示例中的理想顺序:
主句→genu¨gen→Seele→meiner→durstenden主句→genu¨gen→Seele→meiner→durstenden -
优势:先生成核心动词和名词,再根据其语法要求调整修饰词形态,避免回溯错误。
通过隐式建模非因果依赖,减少因局部错误导致的全局矛盾
-
传统单步预测:模型仅基于上文生成下一个token,无法显式利用后续token的语法信息。
-
多token预测(如4-token):
-
强制模型在生成当前token时,潜在表示(latent activations)中需编码后续多个token的信息。
-
例如,生成 meiner 时,模型已隐式预判后续的 durstenden、Seele、genügen 的语法要求,从而正确选择与格阴性单数形式。
-
-
训练机制:多token预测损失函数要求模型同时预测多个位置,迫使潜在表示包含未来上下文信息。
问题:
为什么多token预测可以对关键点错误施加高权重惩罚?loss不是独立的?为什么损失函数中每个token的权重与其对后续token的影响相关?