C语言数据结构:算法复杂度(1)
目录
前言
一、数据结构与算法的介绍
介绍
1.数据结构讲解
2.算法
算法的本质与核心特征
3.数据结构和算法的重要性
二、算法效率
介绍
1.复杂度的概念
三、时间复杂度
介绍
⼤O的渐进表⽰法:
1
2
3
4
5
6
总结
前言
我将数据结构内容分为初阶数据结构和⾼阶数据结构,由于目前是C语言知识结束,没有开始C++语言,有很多数据结构通过C语言来实现会相对困难很多,所以当前讲解以及之后很多内容都是数据结构初阶知识,但初阶数据结构知识量也不少的,在讲解完初阶数据结构之后,我会开始讲解C++语言的知识,在讲解知识途中,我也会顺带用C++语言风格实现C语言数据结构知识涉及的代码的C++语言版本。
本篇文章将讲解数据结构与算法的介绍、算法效率、时间复杂度、空间复杂度、常见复杂度对比等知识的相关内容, 为本章节知识的内容。
一、数据结构与算法的介绍
介绍
1.数据结构讲解
数据结构是计算机存储、组织数据的⽅式,指相互之间存在⼀种或多种特定关系的数据元素的集合。没有⼀种单⼀的数据结构对所有⽤途都有⽤,所以我们要学各式各样的数据结构, 如:线性表、树、图、哈希等。
2.算法
算法:就是定义良好的计算过程,他取⼀个或⼀组的值为输⼊,并产⽣出⼀个或⼀组值作为 输出。简单来说算法就是⼀系列的计算步骤,⽤来将输⼊数据转化成输出结果。
算法的本质与核心特征
- 定义:算法是对解题方案的精准描述,能够接收输入、在有限时间内输出结果,并通过时间复杂度(执行效率)和空间复杂度(资源消耗)衡量优劣。(后面会讲)
- 五大特征(缺一不可):
- 输入:0个或多个初始数据(如排序算法的待排数组)。
- 输出:至少1个结果(如排序后的数组)。
- 有穷性:必须在有限步骤内终止(避免无限循环)。
- 确定性:每个步骤无歧义(如“除以n”不能表述为“除n”)。
- 有效性:步骤可通过基本操作实现(如算术运算、逻辑判断)。
3.数据结构和算法的重要性
数据结构与算法的重要性在校园招聘的笔试和面试中体现的非常明显,企业的笔试和面试对求职者的代码能力是有一定的要求的,特别是现在越来越多公司更注重编程题的考察,以此来更好的筛选人才,所以学习数据结构和算法很重要。
二、算法效率
介绍
算法效率,顾名思义,即算法的好坏,大家在做一些leetcode或刷题网站的题时应该都遇到过代码点击执⾏可以通过,然⽽点击提交却⽆法通过的情况,我当初并不懂其中的原理,通过学习数据结构后,我才了解了这方面的知识:
举个例题:
189. 轮转数组 - 力扣(LeetCode)
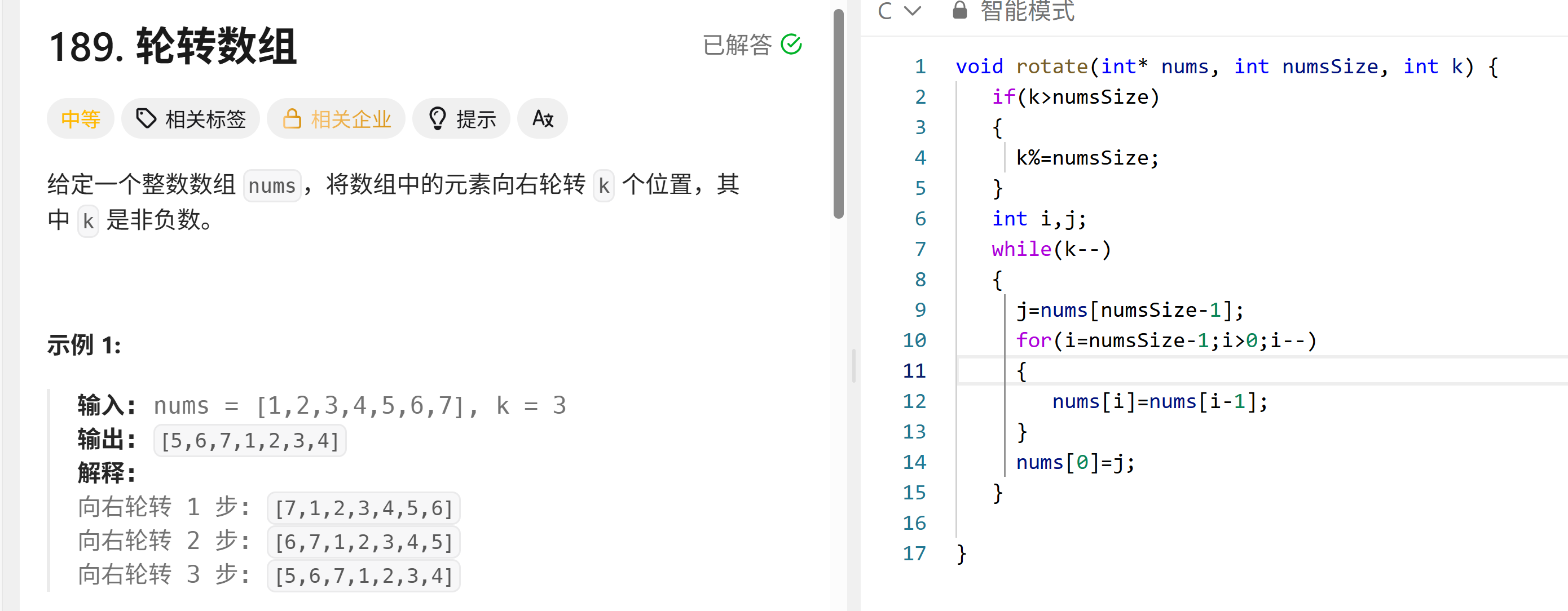
我写的代码为:
void rotate(int* nums, int numsSize, int k) {if(k>numsSize){k%=numsSize;}int i,j;while(k--){j=nums[numsSize-1];for(i=numsSize-1;i>0;i--){nums[i]=nums[i-1];}nums[0]=j;}}该思路讲解:
本题为将数组
nums向右旋转k个位置,而存在数组长度小于k的情况:所以:
- 处理
k大于数组长度的情况:通过k %= numsSize确保旋转次数不超过数组长度(例如,数组长度为5,k=7等效于k=2)。- 旋转方式:采用 逐次右移1位,重复
k次 的策略:
- 每次循环先保存数组最后一个元素
nums[numsSize-1]。- 将所有元素从后往前依次右移1位(
nums[i] = nums[i-1])。- 将保存的最后一个元素放到数组首位
nums[0]。
写出的代码点击执⾏可以通过,然⽽点击提交却⽆法通过。
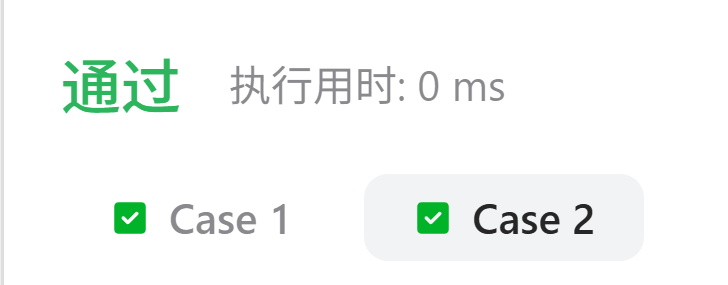
而他的错误提示为:

我们可以发现,自测运行是可以通过的,但是提交后会提示我们超过时间限制,那说明我们设计的算法不够好,效率不够高,我们需要通过更好的算法来实现本题,接下来我将讲解优化算法的知识,首先先讲解下复杂度的概念。
1.复杂度的概念
- 算法在编写成可执⾏程序后,运⾏时需要耗费时间资源和空间(内存)资源。因此衡量⼀个算法的好坏,⼀般是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度。
- 时间复杂度主要衡量⼀个算法的运⾏快慢,⽽空间复杂度主要衡量⼀个算法运⾏所需要的额外空间。 在计算机发展的早期,计算机的存储容量很⼩。所以对空间复杂度很是在乎。但是经过计算机⾏业的迅速发展,计算机的存储容量已经达到了很⾼的程度。所以我们如今已经不需要再特别关注⼀个算法的空间复杂度。
复杂度对于我们做算法题起到了很大的作用,我们题的提交成功于否也与之相关。
三、时间复杂度
介绍
定义:在计算机科学中,算法的时间复杂度是一个函数式T(N),它定量描述了该算法的运行时间。时间复杂度可以衡量程序的时间效率,那我们为什么不直接计算程序的运行时间呢?
- 因为程序运行时间和编译环境和运行机器的配置都有关系,比如同一个算法程序,用一个老编译器进行编译和新编译器编译,在同样机器下运行时间不同。
- 同一个算法程序,用⼀个老低配置机器和新高配置机器,运行时间也不同。
- 并且时间只能程序写好后测试,不能写程序前通过理论思想计算评估。
那么算法的时间复杂度是⼀个函数式T(N)到底是什么呢?这个T(N)函数式计算了程序的执⾏次数。算法程序被编译后⽣成⼆进制指令,程序运⾏,就是cpu执⾏编译好的指令。那么我们通过程序代码或者理论思想计算出程序的执⾏次数的函数式T(N),假设每句指令执⾏时间基本⼀样(实际中有差别,但是微乎其微),那么执⾏次数和运⾏时间就是等⽐正相关, 这样也脱离了具体的编译运⾏环境。执⾏次数就可以代表程序时间效率的优劣。⽐如解决⼀个问题的 算法a程序T(N)=N,算法b程序T(N)=N^2,那么算法a的效率⼀定优于算法b。
总结结论:
程序的执行时间 = 二进制指令运行时间 * 执行次数
上文中有提及:假设每句指令执⾏时间基本⼀样(实际中有差别,但是微乎其微),那么执⾏次数和运⾏时间就是等⽐正相关,最重要的是执行次数,在比较多个算法程序的优劣性时,基本以执行次数为准。
举例:
#include<stdio.h>
#include <string.h>
#include<stdlib.h>
void test(int n)
{int i,j;for(i=0; i<n; i++){for(j=0; j<n; j++){printf("a");}}for(i=0; i<n*2; i++){printf("b");}int m=10;for(i=0; i<m; i++){printf("c");}
}
int main()
{test(10);return 0;
}运行结果为:

test函数执⾏的基本操作次数:
for(i=0; i<n; i++)
{
for(j=0; j<n; j++)
{
printf("a");
}
} 是嵌套循环:外循环每循环一次,内循环都要进行n次的,所以执行次数为:n*n=n^2次
for(i=0; i<n*2; i++)
{
printf("b");
} 为一层循环,结合循环可知:执行次数为:2*n次int m=10;
for(i=0; i<m; i++)
{
printf("c");
} 为一层循环,结合循环可知:执行次数为:10次所以循环次数为:n^2+2*n+10
而随着n的值越来越大,n^2 为对结果影响最⼤的⼀项。
在实际计算时间复杂度时,计算的也不是程序的精确执行次数,因为精确执行次数计算起来很麻烦而且意义不大,当n不断变⼤时常数和低阶项对结果的影响很⼩,所以我们只需要计算程序能代表增⻓量级的⼤概执⾏次数,复杂度的表⽰通常使⽤⼤O的渐进表⽰法。
⼤O的渐进表⽰法:
⼤O :是⽤于描述函数渐进⾏为的数学符号,我们在计算复杂度时以⼤O阶规则为准。
- 时间复杂度函数式 T(N) 中,只保留最⾼阶项,去掉那些低阶项,因为当 N 不断变⼤时, 低阶项对结果影响越来越⼩,当 N ⽆穷⼤时,就可以忽略不计了。
- 如果最⾼阶项存在且不是 1 ,则去除这个项⽬的常数系数,因为当 N 不断变⼤,这个系数 对结果影响越来越⼩,当 N ⽆穷⼤时,就可以忽略不计了。
- T(N) 中如果没有 N 相关的项⽬,只有常数项,⽤常数 1 取代所有加法常数。
根据⼤O的渐进表⽰法的⼤O阶规则,上面代码的复杂度可以得知:为n^2。
接下来,根据⼤O阶规则举几个例子:
1
#include<stdio.h>
#include <string.h>
#include<stdlib.h>
void test2(int n)
{int i,j;for(i=0; i<n*2; i++){printf("b");}int m=10;for(i=0; i<m; i++){printf("c");}
}
int main()
{test2(10);return 0;
}时间复杂度:
for(i=0; i<n*2; i++)
{
printf("b");
} 为一层循环,结合循环可知:执行次数为:2*n次int m=10;
for(i=0; i<m; i++)
{
printf("c");
} 为一层循环,结合循环可知:执行次数为:10次所以循环次数为:2*n+10
而只保留最高项和系数取1可知:时间复杂度为: O(n)

2
#include<stdio.h>
#include <string.h>
#include<stdlib.h>
void test3(int n)
{int i,j;for(i=0; i<n; i++){printf("b");}// int m=10;for(i=0; i<n; i++){printf("c");}
}
int main()
{test3(10);return 0;
}时间复杂度:
for(i=0; i<n; i++)
{
printf("b");
} 为一层循环,结合循环可知:执行次数为:n次
for(i=0; i<n; i++)
{
printf("c");
} 为一层循环,结合循环可知:执行次数为:n次而只保留最高项和系数取1可知:时间复杂度为: O(n)
3
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include<stdlib.h>
void test(int m,int n)
{int count=0,i;for(i=0; i<m; i++){count++;}for(i=0; i<n; i++){count++;}printf("%d ",count);
}
int main()
{int m,n;scanf("%d,%d",&m,&n);test(m,n);
}

可知执行的基本次数为m+n次, 两个独立的
for循环,分别执行m次和n次,总循环次数为m + n,因此时间复杂度为 O(m + n)。我们也可以进一步借助m n的值推理结果。
- if(m==n) 可以为 O(m )或 O(n)。
- if(m>>n) 则可以为 O(m )。
- if(m<<n) 则可以为 O(n)。
4
#include<stdio.h>
#include <string.h>
#include<stdlib.h>
void test4(int n)
{int i,j;int m=1000;for(i=0; i<m; i++){printf("c");}
}
int main()
{test4(10);return 0;
}int m=1000;
for(i=0; i<m; i++)
{
printf("c");
} 为一层循环,结合循环可知:执行次数为:1000次而只保留最高项和系数取1可知:时间复杂度为: O(1)
也有一些算法并不能简单的看出时间复杂度,例如:查找算法等。
举一个简单的代码示例:
5
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include<stdlib.h>
#include<time.h>
void test(int *a,int m,int n)
{int j;for(j=0; j<n; j++){if(a[j]==m){printf("%d ",j);return;}}printf("没找到\n");
}
int main()
{srand(time(0));int m,n;printf("请输入数组中值的个数\n");scanf("%d",&n);int i;int * a=(int *)malloc(sizeof(int)*n);for(i=0; i<n; i++){a[i]=rand()%100;}printf("请输入要查找值\n");scanf("%d",&m);test(a,m,n);
}
- 最佳情况:目标值
m位于数组第一个位置,只需 1次比较,时间复杂度为 O(1)。- 最坏情况:目标值
m不存在或位于数组最后一个位置,需遍历 整个数组(n次比较),时间复杂度为 O(n)。- 平均情况:假设目标值在数组中每个位置的概率相等,平均比较次数为 n/2,时间复杂度仍为 O(n)。
由以上示例可知:
总结:
通过上面我们会发现,有些算法的时间复杂度是存在最好、平均和最坏情况的。
- 最坏情况:任意输⼊规模的最大运行次数(上界)。
- 平均情况:任意输⼊规模的期望运行次数。
- 最好情况:任意输⼊规模的最小运行次数(下界)
而大O的渐进表示法在实际中⼀般情况关注的是算法的上界,也就是最坏运行情况。
所以遇到这种情况算法时,关注的是算法的上界,也就是最坏运行情况即可。
6
根据刚刚的总结:讲解一个偏复杂的上下界的案例:
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include<stdlib.h>
#include<time.h>
void test(int *a, int n)
{int i, j;for (i = 0; i < n - 1; i++) // 外层循环:n-1轮(每轮确定一个最小元素的位置){int exchange = 0; // 优化标志:判断本轮是否发生交换// 内层循环:从左向右遍历,将最小元素"冒泡"到数组前端(i位置)for (j = 1; j < n - i; j++) // 终止条件:j < n - i(已排序部分无需再比较){if (a[j] > a[j - 1]) // 降序排序:前一个元素 < 后一个元素时交换{int t = a[j];a[j] = a[j - 1];a[j - 1] = t;exchange = 1; // 标记发生交换}}if (exchange == 0) // 若本轮无交换,数组已有序,提前退出{break;}}
}
int main()
{srand(time(0));int m,n;printf("请输入数组中值的个数\n");scanf("%d",&n);int i;int * a=(int *)malloc(sizeof(int)*n);for(i=0; i<n; i++){a[i]=rand()%100;}test(a,n);
}冒泡排序代码:
void test(int *a, int n)
{
int i, j;
for (i = 0; i < n - 1; i++) // 外层循环:n-1轮(每轮确定一个最小元素的位置)
{
int exchange = 0; // 优化标志:判断本轮是否发生交换
// 内层循环:从左向右遍历,将最小元素"冒泡"到数组前端(i位置)
for (j = 1; j < n - i; j++) // 终止条件:j < n - i(已排序部分无需再比较)
{
if (a[j] > a[j - 1]) // 降序排序:前一个元素 < 后一个元素时交换
{
int t = a[j];
a[j] = a[j - 1];
a[j - 1] = t;
exchange = 1; // 标记发生交换
}
}
if (exchange == 0) // 若本轮无交换,数组已有序,提前退出
{
break;
}
}
}
讲解:

冒泡排序: 基本实现次数:
每当进行一次外层循环时,都会进行多次的内层循环for (j = 1; j < n - i; j++)
对应的实现次数如上图: 若将执行次数求和,为等差数列型求和:
1.最坏时间复杂度
- 场景:数组完全逆序(如
[1,2,3,4,5]需排成降序),或数组中不存在提前有序的子序列。- 执行过程:外层循环执行
n-1次(i从0到n-2),内层循环每次执行n-i-1次(j从1到n-i-1)。- 计算:总比较次数为
(n-1) + (n-2) + ... + 1 = n(n-1)/2,属于 O(n²) 量级。2. 最好时间复杂度
- 场景:数组已完全有序(如
[5,4,3,2,1]本身就是降序)。- 执行过程:外层循环第
1次(i=0)时,内层循环遍历后exchange=0,触发break提前退出。- 计算:仅需 1 次外层循环 + n-1 次内层比较,总操作次数为 O(n)。
3. 平均时间复杂度
- 场景:随机输入数组(元素无序且无规律)。
- 结论:提前退出优化对平均情况影响有限,复杂度仍为 O(n²)(需遍历大部分元素并交换)。
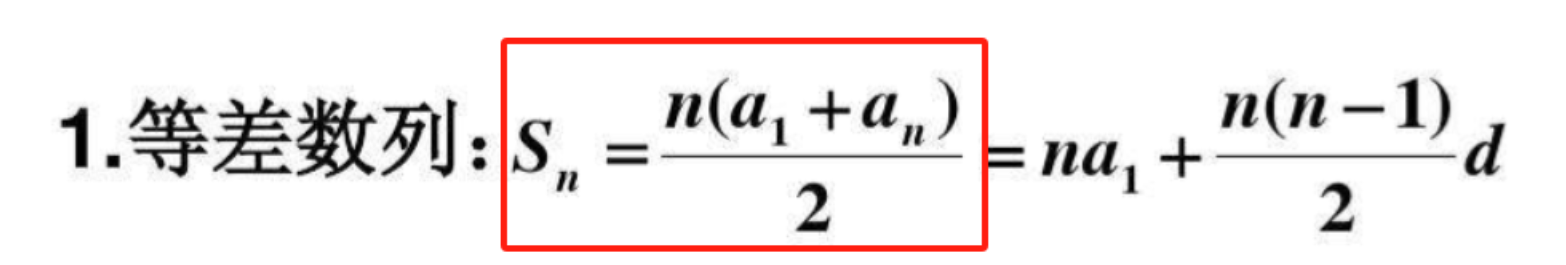
总结
以上就是今天要讲的内容,本篇文章涉及的知识点为:数据结构与算法的介绍、算法效率、时间复杂度知识的相关内容,为本章节知识的内容,希望大家能喜欢我的文章,谢谢各位,接下来的内容我会很快更新。
