OpenCV 级联分类器目标检测
参考
opencv cpp 传统目标检测方法
opencv 官方级联分类器训练教程
opencv3.4 分支 github 上 cv3.4 源码地址
背景
需要在没有 gpu 和 npu,且算力有限的情况下检测目标。
通常 cv 的级联分类器用来检测人脸,但是官方也提供了些工具给用户用来训练自己的目标模型。
环境
ubuntu20.04,opencv3.4,opencv4.2,核显
样本准备
图像样本的尺寸必须一致。
- 正样本描述文件:包含目标的图像,保存为 ".txt"
描述文件内容格式:
图像0名 目标数目 x y w h
图像1名 目标数目 x y w h
图像2名 目标数目 x y w h
...正样本描述文件中只需要描述图像样本的名称,cv 会自动在描述文件目录中去找这些图像。
x y w h 分别表示目标检测框的左上角像素坐标,以及检测框的宽度和高度。
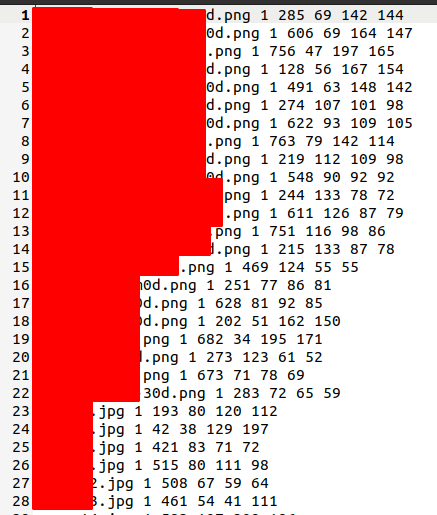
- 负样本描述文件:不包含目标的图像,保存为 ".txt"。负样本有时候也被称作背景bg。
描述文件内容格式:
图像0绝对路径(这里是负样本图像的绝对路径)
图像1绝对路径
图像2绝对路径
...负样本描述文件中需要说明负样本图像的绝对路径!╮(╯_╰)╭
描述文件和样本图像在同一个目录下,大概如下:
.
├── backlight_1.0m-0.1m0d.png # 图像样本
├── backlight_1.0m0.1m0d.png # 图像样本
. . . . . .
├── cv_label_positive.txt # 样本描述文件
. . . . . .
├── day_1.5m0.3m0d.png # 图像样本
└── night_09.png # 图像样本0 directories, 67 files生成 cv 样本描述文件
官方似乎没有提供生成 cv 样本描述文件的工具,第三方更找不到了。
我考虑用通用的标注工具标注出图像中的目标,导出文件(例如 json)后用 py 读取转为 cv 的描述文件内容。
这里使用 label-studio 标记出图像中的目标。导出 mini-json 格式如下:
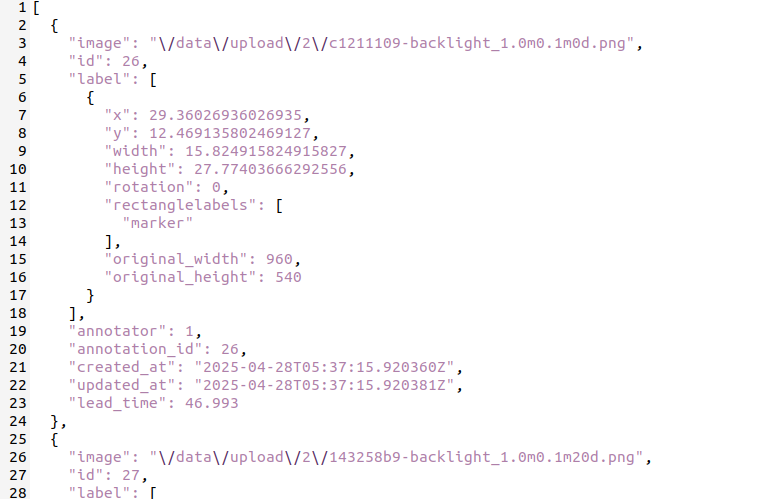
label-studio 中 x,y,width,height 单位是 % 而不是像素!
用 py 脚本转换输出为 cv 描述文件
安装 cv3.4
opencv_createsamples 和 opencv_traincascade 在 opencv4 以上已经不支持了。需要使用 cv3.4 分支。
cv3.4 和 cv4.x 的模型格式一致。cv3.4 的级联分类器模型可以在 cv4.x 中继续使用。
下载 3.4 分支代码,解压后再解压目录执行:
mkdir build
cd build
cmake -D WITH_TBB=ON ..
make -j8-D WITH_TBB=ON 开启多线程加速,本地需要安装 libtbb-dev。
这里不执行 cmake install 避免影响到系统原来的 cv4.x。
在 build/bin 目录中生成了模型训练需要的应用软件:

设备端不需要安装 cv3.4,但运行可能报错:
symbol lookup error: /usr/lib/libCLC.so: undefined symbol: gcSHADER_UpdateTargetRegMemorySameFormat
这里要在设备端安装 libclc-dev。
cv 样本制作
使用 cv3.4 的 opencv_createsamples 的软件制作
./opencv_createsamples \-info $positive_file \ # 正样本描述文件路径-vec $positive_cv_file \ # cv 样本文件保存路径-show \ # 调试查看样本效果,尽量用小尺寸样本-num $num \ # 样本数目-maxxangle $x_max_angle \ # 绕轴旋转生成样本-maxyangle $y_max_angle \-maxzangle $z_max_angle \-maxidev $maxidev \ # 最大像素偏移,模拟光照影响-w $photo_w \ # 样本宽度,一般为 24-h $photo_h # 样本高度-num 的样本数目需要略小于实际提供的样本数目。
-w 和 -h 是opencv_createsamples 对图像目标处理后生成的 cv 目标样本。可以参考图像样本中目标大小的最小值。cv 样本尺寸越大,训练的时候越吃内存。
-show 可以看到生成的 cv 样本。如果样本太小了,你自己都认不出目标来,可以考虑把 -w 和 -h 参数设置大一点。
注意最后生成 cv 样本的日志,实际生成的 cv 样本数目可能小于你的设置参数。
模型训练
使用 cv3.4 的 opencv_traincascade 的软件训练模型
./opencv_traincascade \-data $model_path \ # 训练后模型保存路径,cv 不会自动创建路径,确保这里的目录存在-vec $positive_cv_file \ # 正样本文件路径-bg $negativate_file \ # 负样本描述文件路径-numPos $pos_train_num \ # 每阶段正样本训练数,略小于总样本数,大概 90% 左右-numNeg $neg_train_num \ # 每阶段负样本训练数,小于总样本数,负样本数目与正样本数目相当-numStages $train_num \ # 训练阶段次数,训练越多模型越准,最好 15~20 个阶段-w $photo_w -h $photo_h \ # 样本尺寸,和增强样本尺寸一致,uint:pixel-featureType $feature_type \ # 特征类型,HAAR(精度高,训练慢)或者LBP(精度低,训练快),在训练数据量足够大的情况下性能相当-minHitRate $min_hit_rate \ # 单阶段最小命中率-maxFalseAlarmRate $max_false_alarm_rate \ # 单阶段最大误检率,训练中低于该值结束训练-maxWeakCount $max_weak_count \ # 每层弱分类器最大数目,弱分类器数目越多精度越高,训练越久,默认 100-precalcValBufSize $memory_size \ # 内存分配,uint:MB-precalcIdxBufSize $memory_size-numStages:一开始把参数设置小一点例如 7 次,验证下流程是否打通。
训练成功后可以在模型的保存目录看到:
cascade/├── cascade.xml # 最终模型文件├── params.xml # 参数文件├── stage0.xml # 各阶段中间模型├── stage1.xml└── ...训练工具的使用可以在官网找到资料

在 cv3.4 源码安装目录中搜索 "traincascade.markdown",打开在 “Cascade Training” 可以看到相关参数:

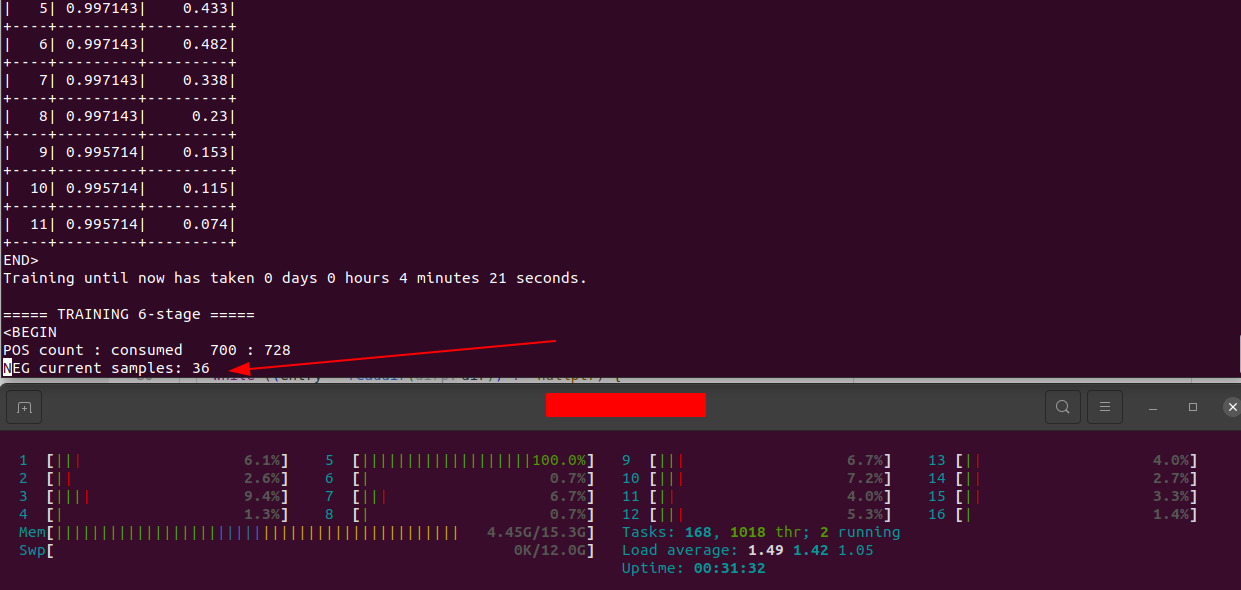
这里要吐槽下“多线程”加速功能,我只在模型训练的“pos count”阶段观察到多线加速。(°ー°〃)
最耗时的“neg current samples”阶段一直是单线程在训练。
测试模型
使用 cv4.x 的接口来测试模型。
#include <opencv2/opencv.hpp>
using namespace cv;int main() {CascadeClassifier cascade;if (!cascade.load("cascade/cascade.xml")) {std::cerr << "Error loading cascade model!" << std::endl;return -1;}Mat img = imread("test.jpg");Mat gray;cvtColor(img, gray, COLOR_BGR2GRAY);std::vector<Rect> objects;cascade.detectMultiScale(gray, objects, 1.1, 3);for (const Rect& obj : objects) {rectangle(img, obj, Scalar(0, 255, 0), 2);}imshow("Result", img);waitKey(0);return 0;
}这里不展示具体的测试样本和测试效果。
优缺点
-
优点
仅靠 cpu 就可以训练。
操作方便简单。
缩放图像仍然可以检测。
-
缺点
不支持中断后继续训练,cv 中的训练是一次性的。
对于立体目标的多个面检测不佳,所以一般只识别物体的单个面。级联分类器的论文中也只是识别人的正脸。