经典启发算法【早期/启发式/HC爬山/SA模拟退火/TS禁忌搜/IA免疫 思想流程举例全】
文章目录
- 一、早期算法
- 二、启发式算法
- 三、爬山法HC
- 3.1 基本思路
- 3.2 伪代码
- 四、模拟退火SA
- 4.1 算法思想
- 4.2 基本流程
- 4.3 再究原理
- 4.3.1 Metropolis准则
- 4.3.2 再理解
- 4.4 小Tips
- 4.5 应用举例
- 4.5.1 背包问题:
- 分析:
- 求解:
- 4.5.2 TSP问题:
- 附图解:
- 4.6 优缺点
- 优点:
- 缺点:
- 五、禁忌搜索TS
- 5.1 基本概念
- 5.2 思想风暴
- 5.3 基本流程
- 5.4 应用举例
- 问题:
- 求解:
- 另附手写例题:
- 六、人工免疫算法IA
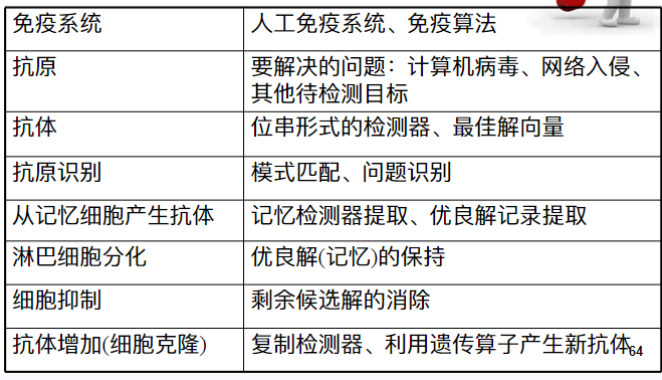
- 6.1 必知专有名词
- 6.2 深入理解免疫系统模型
- 6.2.1 免疫系统VS免疫算法
- 6.2.2 免疫算法详解
- 6.2.3 阴性选择算法
- 1. 什么是阴性选择算法?
- 2. 流程图
- 3. 算法步骤
- 6.3 免疫算法流程
- 步骤描述:
- 6.4 算法改进
- 6.4.1 克隆选择CSA
- 1. 为什么要克隆选择?
- 2. 案例
- 6.4.2 基于抗体浓度的克隆选择
- 创新又在哪里?
- 6.4 免疫算法和进化算法区别
一、早期算法
也就是一些精确算法,包括:
- 分支定界法
- 背景分割法
- 动态规划
无法精确,我们就用近似算法,比如启发式算法,如下
二、启发式算法
首先我们要知道启发式算法包括:
-
元启发
- 基于个体:
- 爬山法HC
- 模拟退火SA
- 禁忌搜索TS
- 基于群体:(群智能优化算法)
- 蚁群算法ACA
- 粒子群算法PSO
- 人工蜂群ABC
- 人工鱼群AFSA
- 基于个体:
-
Specific
主包还没涉猎
三、爬山法HC
3.1 基本思路
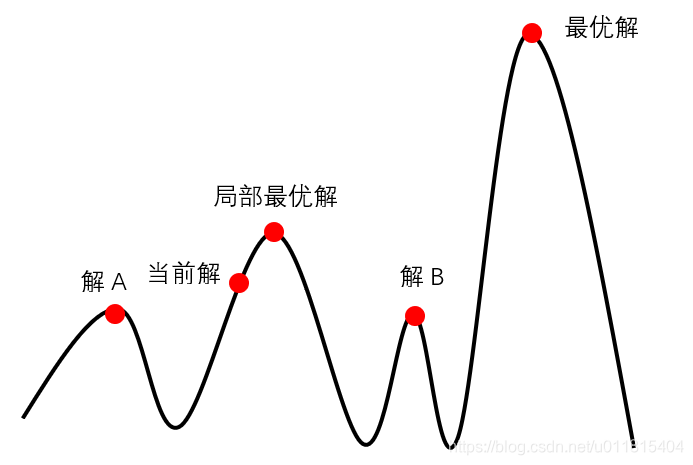
学过机器学习的同学可以不用看了,这不就是梯度下降法吗。其实是一种局部则有的贪心搜索算法:
每次从当前节点出发,与周围邻接点比较:
- 若当前节点是最大的,那么返回当前节点,作为最大值
- 若当前节点是最小的,就用最高的邻接点替换当前节点,从而实现向山峰的高处攀爬的目的
爬山法搜索到局部最优解后,就会停止搜索,因为在局部最优解这个点,无论向哪个方向小幅度的移动,都无法得到更优解
3.2 伪代码
int getPos(double x) {//比较答案并获取新坐标点int pos;//新坐标点double res = -INF;for (int i = 1; i <= n; i++) {double newRes = getRes(x, node[i]);//获取新状态答案if (newRes > res) { //比较答案res = newRes; //更新结果pos = i; //记录新坐标点}}return pos;
}
void HC(double &x,double &y) {double T = 1;while (T > EPS) {int pos = getPos(x);//获取下一状态的坐标sta = sta + (node[pos] - x) * T;//转移x状态T *= 0.96;}
}
四、模拟退火SA
关于爬⼭算法与模拟退⽕,有⼀个有趣的⽐喻:
- 爬⼭算法:兔⼦朝着⽐现在⾼的地⽅跳去,找到了不远处的最⾼⼭峰,但不⼀定是珠穆朗玛峰。
- 模拟退⽕:兔⼦喝醉随机地跳了很⻓时间,可能⾛向⾼处,也可能踏⼊平地。但是,它渐渐清醒了并朝最⾼⽅向跳去。
4.1 算法思想
一听这个名字我想多数人头脑都会冒出“???”,这咋还得退火嘞,难不成还能上火的吗?我们不妨想一想物理热力学的知识:
-
T高:固体内部粒子无序,内能大 -
T低:固体内部粒子逐渐有序,在每个温度达平衡态 -
T常温:内能最小
其实模拟退火(SImulated Annealing)算法的思想就是来源于物理的退火原理,也就是降温原理。先在一个高温状态下(相当于算法随机搜索),然后逐渐退火(引入随机因素,以一定概率接受一个更差解),在每个温度下(相当于算法的每一次状态转移)徐徐冷却(相当于算法局部搜索),最终达到物理基态(相当于算法找到最优解)。
不多说,上图:

4.2 基本流程
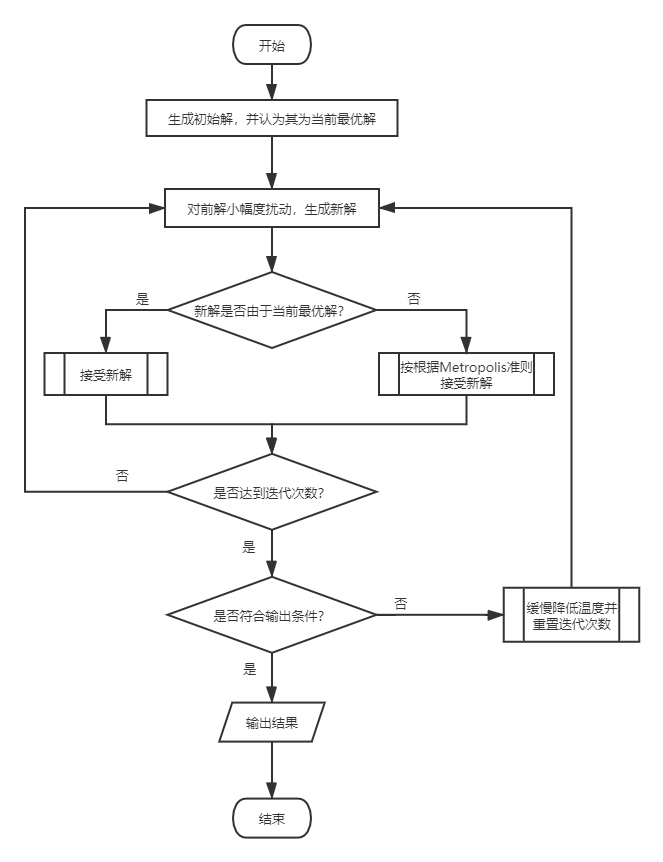
先附上模拟退火算法求解最优化问题的基本流程图和伪代码

其实这里算是有两层循环:
- 内循环:在给定温度系统下达到平衡的过程。内循环中,每次都从当前解
i的领域中随机找出一个新解j,按照Metropolis准则概率的接受新解。 - 外循环:降温的过程,内循环结束后,即在一个温度下达到平衡后,开始外层的降温,然后再新的温度下重新开始内循环。
如果没有内循环:(领域变成不断地随机扰动)
4.3 再究原理
4.3.1 Metropolis准则
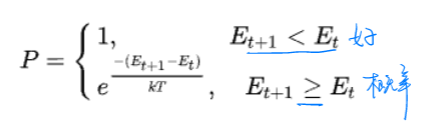
- 新解更优:接受新解
- 新解不优:一定概率接受新解(并不是完全不接受),属于随机扰动
4.3.2 再理解
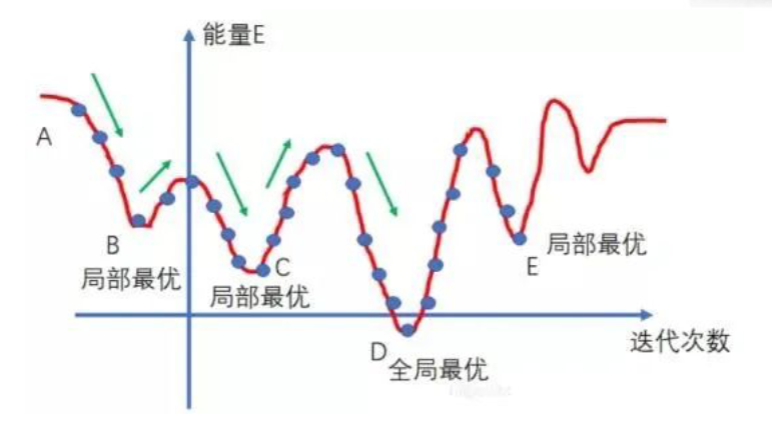
一开始在A,能量不断减小,100%接受新解;到达B后,发现新解不如旧解,(梯度下降法是不允许向前的),但用Metropolis准则,会以P(ΔE)跳出这个坑;如果B最终跳出来了,则会到达C,直到到达D后,就会稳定下来。
4.4 小Tips
- 初始点选取对算法有一定影响
- 初期温度下降快,避免接受过多的差结果;运行时间增加时,温度下降减缓(ΔE>0更有可能,P<1更有可能),以便于更快稳定结果。
- 加入适当的输出条件,满足则可以结束程序。
4.5 应用举例
4.5.1 背包问题:
已知背包的装载量为c=8,现有n=5个物品,它们的重量和价值分别是(2, 3, 5, 1, 4)和(2, 5, 8, 3, 6)。试使用模拟退火算法求解该背包问题,写出关键的步骤。
分析:
背包问题本身是一个组合优化问题,也是一个典型的NP难问题。如果使用枚举的方法,我们需要找到n个物品的所有子集,然后在那些满足约束条件的子集中比较物品的总价值,找到总价值最大的子集,也就是问题的最优解。
但是我们知道,大小为n的集合的子集数目为2^n ,所以当背包问题的规模变大(n变大)的时候,要找出所有的子集是一个不现实的做法,因为计算复杂度的指数级增长已经使得问题在规模稍大的时候就无法在可以接受的时间内得到解决。
因此背包问题需要采用一些计算复杂度较低的,但是能够提供令人满意的解的算法,而模拟退火算法是解决背包问题的重要手段。
求解:
假设问题的一个可行解用0和1的序列表示,例如i=(1010)表示选择第1和第3个物品,而不选择第2和第4个物品。用模拟退火算法求解例10.1的关键过程如图所示:

4.5.2 TSP问题:
附图解:
4.6 优缺点
优点:
- 对全局最优解进行随机搜索,避免跳入局部最优解
- 时间空间复杂度相对较低
- 对问题的领域知识所知甚少
缺点:
- 简单问题效率不高,较慢,降温方法较为严格
- 已知待解问题相关知识用不上
五、禁忌搜索TS
5.1 基本概念
-
禁忌表:存放记忆禁忌对象的表(有容量限制)
-
禁忌对象:禁忌表中被禁的元素(TSP中可以是城市)
-
禁忌期限:禁忌长度,指的是禁忌对象不能被选取的周期。期限太短就容易出现循环,跳不出局部最优;期限太长则计算周期过长。
到底怎么理解?就是未来
L代不计算/考虑该领域的候选解 -
特赦准则:(所谓特赦:禁忌期限还没到就赦免!!)所有对象被禁忌之后,可以让其中性能最好的被禁忌的对象解禁;或者某个对象会带来目标值大幅改进
5.2 思想风暴
- 初始化领域范围、禁忌长度和初始解
- 在领域范围内计算候选解并选择最优解
- 最优解加入
TT禁忌表,设置为禁忌长度(每一步禁忌表内禁忌长度都要更新) - 更新当前解为最优解(不妨更新全局最优解)
- 判断是否为终止条件
5.3 基本流程

5.4 应用举例
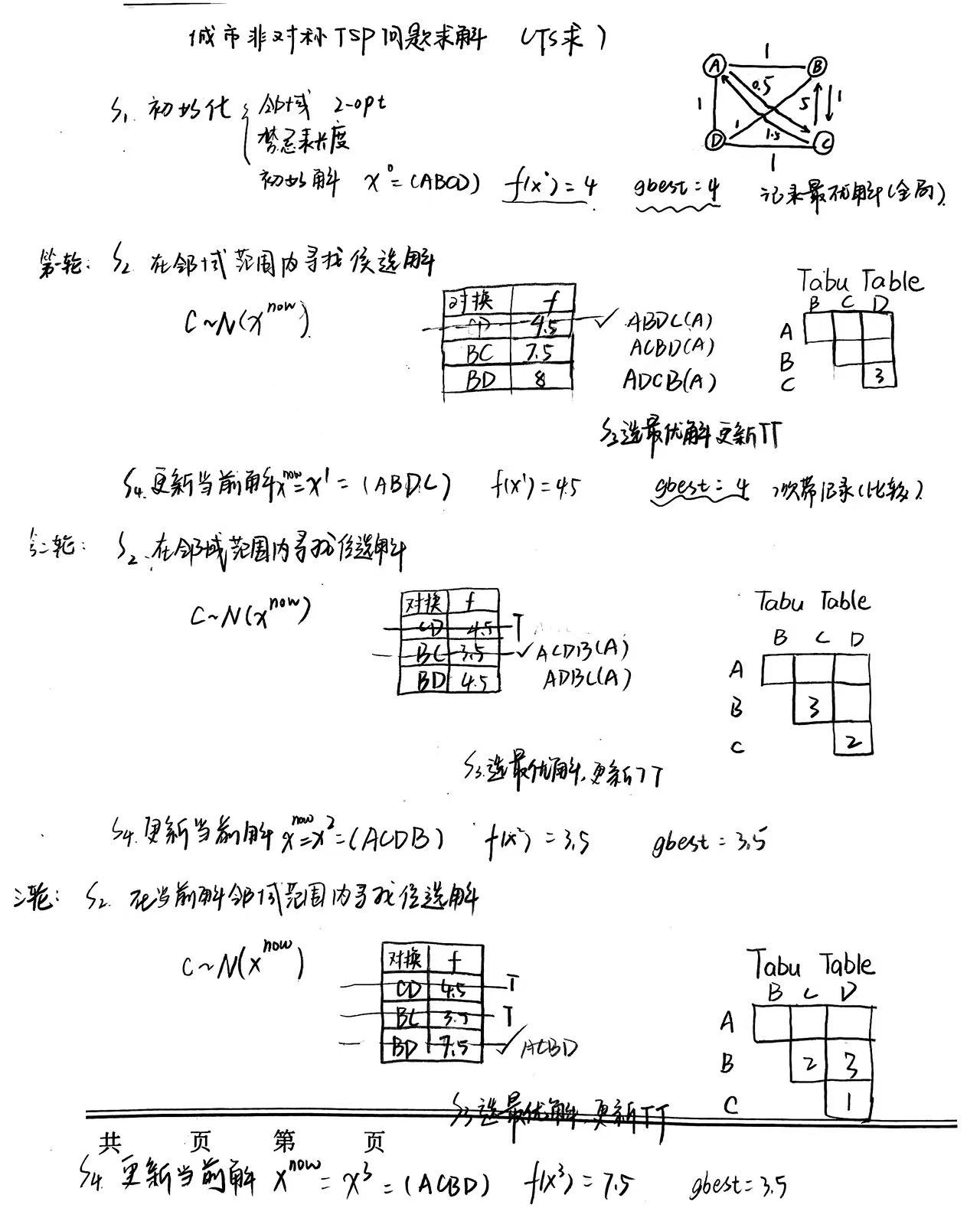
问题:
已知一个旅行商问题为四城市(a,b,c,d)问题,城市间的距离如矩阵D所示,为方便起见,假设邻域映射定义为两个城市位置对换,而始点和终点城市都是a。请分析使用禁忌搜索算法求解该问题的前面三代的过程与主要步骤。

求解:

另附手写例题:
六、人工免疫算法IA
6.1 必知专有名词
人体的免疫系统:
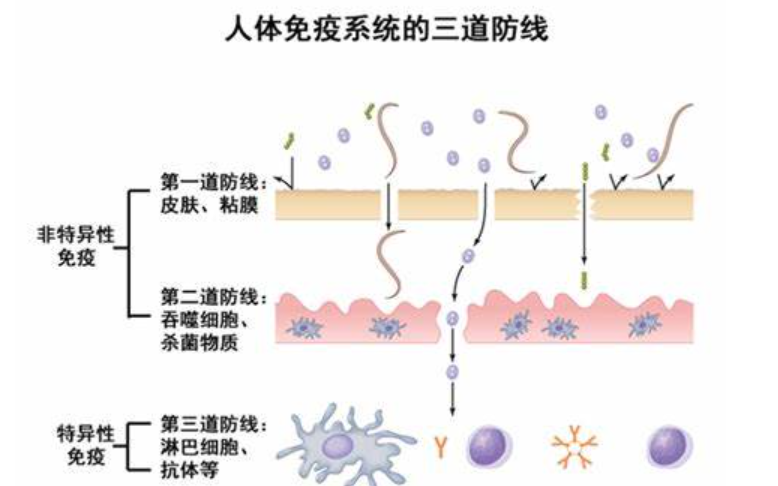
这里,我们着重借鉴特异性免疫并解释:
- 抗原:异体,与抗体/淋巴细胞进行结合
- 抗体:用来鉴别和移植外援物质的一种蛋白质复合体,每种抗体可以识别一种抗原
- 淋巴细胞:
- B细胞:B淋巴细胞,在骨髓分化成熟
- T细胞:T淋巴细胞,在胸腺中成熟
- 记忆细胞:包括记忆B细胞、记忆T细胞,在初次免疫应答后长期存活。二次感染时快速活化,产生更强、更迅速的免疫应答
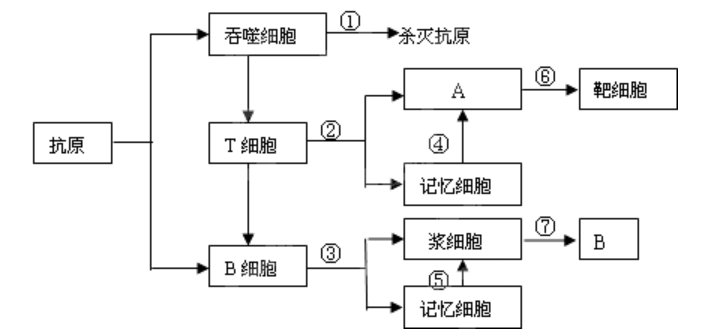
滴滴,来回忆高中生物了,大家可以看看这个图,填一填空。
6.2 深入理解免疫系统模型
6.2.1 免疫系统VS免疫算法

- 把重心放在B细胞表层的抗体和抗原之间的机制上
- 抗体和抗原的亲和程度由它的抗体决定簇和抗原的决定基的匹配程度决定假设每个抗原和每个抗体型分别只有一个抗原决定簇(实际它们都有许多不同类型的抗原决定基)
- 通过这些决定基之间的匹配程度控制不同类型抗体的复制和减少,以达到优化系统的目的.
6.2.2 免疫算法详解
一般免疫算法就是对免疫系统机理的模拟,包括:
-
免疫识别(免疫系统IS的主要功能,也是AIS的核心之一),识别的本质是区分"自我"和“非我”
核心机制:根据识别的对象特征进行编码,定义一个自我集合随机产生一系列检测器,用于检测自我集合变化
-
免疫学习:免疫系统通过学习促使免疫细胞的个体亲和度提⾼、群体规模扩⼤。
最优个体以免疫记忆的形式得到保存当机体重复遇到同⼀抗原时,由于免疫记忆机制的作⽤,免疫系统对该抗原的应答速度⼤⼤提⾼。
途径:
- 增强学习
- 遗传学习
- 联想式学习
-
免疫记忆
- 初次应答:识别之后保留最优抗体、产生记忆细胞的形式保留对某抗原的记忆信息
- 二次应答:仍存在的B细胞作为免疫记忆细胞快速与抗原反应(加快学习过程并提高学习质量)
二次免疫应答:更迅速,无需重新学习
6.2.3 阴性选择算法
1. 什么是阴性选择算法?
- 训练阶段:随机生成大量初识检测器,并逐一与系统定义的⾃体数据集进⾏匹配。若检测器能够识别某条⾃体数据,则被删除。那些与所有⾃体数据均不能匹配的检测器成为有效检测器,并被存⼊检测器集合。
- 检测阶段:未知类别数据与有效检测器进⾏匹配。如果⾄少有⼀个检测器能够识别该数据,则该数据被归类为⾮⾃体;否则归为⾃体。
2. 流程图
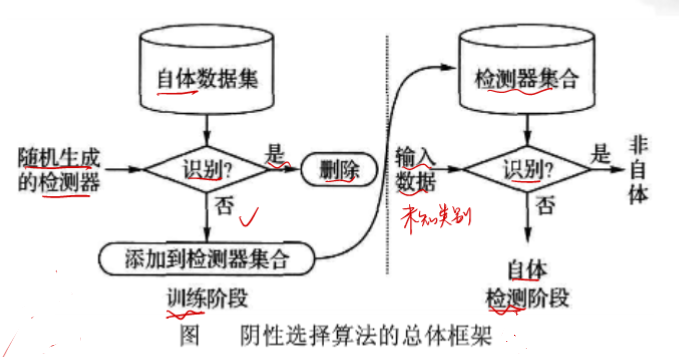
3. 算法步骤
- 定义一个自身集合S,每个字符串由n个字母组成,字符串可以是一个网络数据包,电子邮件特征向量或程序的一般行为模式。
- 产生一个初始检测器集合R(随机产生)
- (训练阶段)R每个检测器经历阴性选择。R只要与自身集合S中的任意一个字符串相匹配,则删除该检测器;无任何字符串匹配,就保留,作为有效检测器。
- (测试阶段)通过与R集合的匹配不断检测S的变化,一旦发生任何匹配,则说明S集合有了外来抗原侵入。
虽然一开始我们会疑问:为什么匹配就要删除这个检测器?看到测试阶段应该大家就明白了,当然要删除,留下的才可以识别外来的!
6.3 免疫算法流程
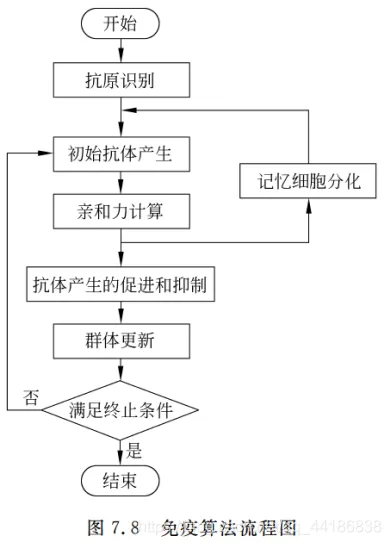
步骤描述:
- 抗原识别:免疫系统确认抗原入侵
- 初始抗体产生:激活记忆细胞分化,产生抗体
- 亲和力计算:计算抗体和抗原之间的亲和力
- 记忆细胞分化:T淋巴细胞刺激B细胞增殖、分化产生和记忆细胞(伏笔!? 怎么增值分化–>借鉴GA)
- 促进和抑制:亲和力搞得抗体受到促进,高密度抗体会被排挤(保证多样性)
- 终止条件判断
6.4 算法改进
6.4.1 克隆选择CSA
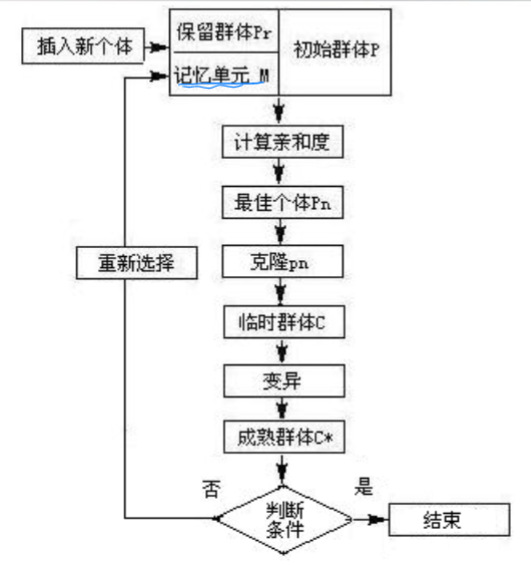
1. 为什么要克隆选择?
其实改进在哪里,就是分化产生记忆细胞,既然是一种遗传,为什么不利用遗传择优的思想筛选更好的记忆细胞去产生抗体?**亲和度高就克隆!**都克隆了那就也来个变异吧。。
2. 案例
以下是一个使用克隆选择算法解决旅行商问题的案例:
- 初始化抗体种群:随机生成一定数量的抗体,每个抗体代表一个旅行路线。
- 评估抗体亲和度:计算每个抗体路线的总距离。
- 克隆选择:选择亲和度较高的抗体进行克隆,克隆的个数根据亲和度大小决定。
- 变异:对克隆的抗体进行变异,如交换两条路线中的城市顺序。
- 迭代:重复步骤2-4,直到满足终止条件。
通过多次迭代,算法可以找到较短的旅行路线。
6.4.2 基于抗体浓度的克隆选择
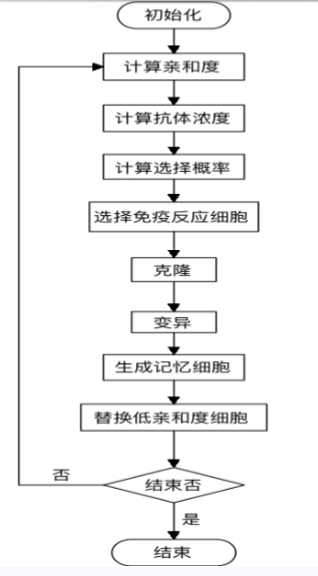
创新又在哪里?
亲和力高的记忆细胞将会被克隆,如何保证记忆细胞的多样性?抗体浓度高的被抑制,浓度低的会促进。
6.4 免疫算法和进化算法区别
-
记忆单元基础上进行,确保可以收敛到全局最优解;进化算法不可以
-
亲和力有两种形式:
- 抗体和抗原的关系:目标和解的匹配程度
- 抗体之间的关系:保证免疫算法具有多样性
而进化算法只是简单的计算个体适应度
-
通过促进或抑制抗体的产生,体现了自我调节功能;而进化算法根据适应度选择⽗代个体,并没有对个体多样性进⾏调节