15 C 语言字符类型详解:转义字符、格式化输出、字符类型本质、ASCII 码编程实战、最值宏汇总
1 字符类型概述
在 C 语言中,字符类型 char 用于表示单个字符,例如一个数字、一个字母或一个符号。
char 类型的字面量是用单引号括起来的单个字符,例如 'A'、'5' 或 '#'。
当需要表示多个字符组成的序列时,就涉及到了字符串。在 C 语言中,字符串是通过 char 数组来实现的,数组属于构造类型,而非基本数据类型。关于数组和字符串的详细内容,我们将在后续章节专门讲解。
// 定义并初始化 char 类型变量
char letter = 'A'; // 字母
char digit = '5'; // 数字
char symbol1 = '#'; // 符号
char symbol2 = '\n'; // 转义字符,换行符// 错误定义:不是单个字符
// char letters = 'AB'; // 错误:字符常量只能包含一个字符
// char digits = '12'; // 错误:字符常量只能包含一个字符
// char symbols = '#$'; // 错误:字符常量只能包含一个字符
// char chinese = '中'; // 错误:一个汉字字符在 UTF-8 编码中占用多个字节// 可以通过后续学习字符串来存储多个字符
// char str1[] = "Hello"; // 正确:字符串常量可以包含多个字符2 转义字符
在 C 语言中,可以使用以反斜杠 \ 开头的转义字符来表示一些具有特殊含义的字符。这些转义字符为程序提供了处理特殊字符和格式化输出的能力。
2.1 常见转义字符说明
以下是常见的转义字符及其说明:
| 转义字符 | 字符名称 | 说明 |
|---|---|---|
| \n | 换行符 | 将光标移动到下一行的开头(换行),两个 \n 表示空一行 |
| \t | 水平制表符 | 插入一个水平制表符(通常等效于 4 或 8 个空格,具体取决于实现) |
| \\ | 反斜杠字符 | 由于反斜杠在 C 语言中用作转义字符的引导,所以表示它自身时需要使用两个反斜杠 |
| \' | 单引号字符 | 因为在 C 语言中字符常量是由单引号括起来的,所以要在字符串中表示单引号,就需要使用转义字符 |
\" | 双引号字符 | 因为 C 语言中的字符串是由双引号括起来的,所以要在字符串中表示双引号,就需要使用转义字符 |
| \a | 响铃(BEL)字符 | 产生声音或可视信号(具体效果取决于系统和终端) |
| \b | 退格符 | 将光标向左移动一个位置(可能删除左侧字符,具体行为依赖实现) |
| \f | 换页符 | 将光标移动到下一页的开头(具体效果取决于系统和终端) |
| \r | 回车符 | 将光标移动到当前行的开头(可能覆盖已有内容,不换行) |
| \v | 垂直制表符 | 在垂直方向上移动光标(效果因系统而异) |
| \ooo | 八进制转义序列 | 用 1 到 3 位八进制数字(0~7)表示字符,示例:\101 → 八进制 101(十进制 65)→ 字符 'A' 注意:位数不足 3 时,编译器按实际八进制值解析(如 \12 等价于 \012,表示换行符 \n) |
| \xhh | 十六进制转义序列 | 用 1 到多位十六进制数字(0~9、A~F、a~f)表示字符,示例:\x41 → 十六进制 41(十进制 65)→ 字符 'A' 注意:通常用 2 位表示 ASCII 字符(如 \x41),但长度灵活(如 \x1F600 表示 Unicode 笑脸 😀) |
- 某些转义字符(如 \a、\b、\f、\v)的效果可能因终端或系统而异。
- 八进制和十六进制转义序列直接对应 ASCII 码,可通过查表验证输出。
扩展:转义字符中的 \r(回车)与 \n(换行)
- 起源与功能
- \r(回车):将光标移回行首(打字机时代功能),不换行。
- \n(换行):将光标移到下一行(纸张滚动功能),不移动行首位置。
- 系统差异
- Unix/Linux/macOS:仅用 \n 表示换行。
- Windows:传统用 \r\n 组合,但现代工具兼容 \n(网络协议仍需 \r\n)。
- C 语言中的抽象
- C 语言统一用 \n 表示换行,实际行为由系统底层决定(如 Unix 直接换行,Windows 可能转换为 \r\n)。
2.2 案例演示
以下是一个 C 程序,演示了上表中所列出的转义字符的用法,并附有详细注释:
#include <stdio.h>int main()
{// 1. 换行符 \n:将光标移动到下一行的开头(换行)printf("这是第一行\n这是第二行\n\n"); // 两个 \n 表示空一行// 2. 水平制表符 \t:插入一个水平制表符(通常等效于 4 或 8 个空格,具体取决于实现)printf("姓名:\t张三\n年龄:\t25\n\n");// 3. 反斜杠字符 \\:表示一个反斜杠本身printf("路径示例: C:\\\\Program Files\\\n\n"); // 路径示例: C:\\Program Files\// 4. 单引号字符 \':在字符常量中表示单引号printf("单引号示例: \'A\'\n\n"); // 单引号示例: 'A'// 5. 双引号字符 \":在字符串中表示双引号printf("双引号示例: \"Hello\"\n\n"); // 双引号示例: "Hello"// 6. 响铃字符 \a:产生声音或可视信号(具体效果取决于系统和终端)printf("响铃提示:\a 请注意!\n\n");// 7. 退格符 \b:将光标向左移动一个位置(可能删除左侧字符,具体行为依赖实现)printf("退格示例: 12\b3\n\n"); // 输出可能为 "13",因为 \b 可能会删除左侧的字符 '2'// 8. 换页符 \f:将光标移动到下一页的开头(具体效果取决于系统和终端)printf("第一页\f这是第二页的内容\n\n");// 9. 回车符 \r:将光标移动到当前行的开头(可能覆盖已有内容,不换行)printf("123\r456\n\n"); // 输出 "456",因为 \r 覆盖了前面的 "123"// 10. 垂直制表符 \v:在垂直方向上移动光标(效果因系统而异)printf("垂直制表符:\v新行1\v新行2\n\n");// 11. 八进制转义序列 \ooo:用 1 到 3 位八进制数字(0~7)表示字符printf("八进制示例: \101\n"); // \101 对应 ASCII 码 65,即 'A'printf("八进制示例: \12\n"); // \12 对应 ASCII 码 10,即换行符 \nprintf("八进制示例: \141\n\n"); // \141 对应 ASCII 码 97,即 'a'// 12. 十六进制转义序列 \xhh:用 1 到多位十六进制数字(0~9、A~F、a~f)表示字符printf("十六进制示例: \x41\n"); // \x41 对应 ASCII 码 65,即 'A'printf("十六进制示例: \x0A\n"); // \x0A 对应 ASCII 码 10,即换行符 \nprintf("十六进制示例: \x61\n"); // \x61 对应 ASCII 码 97,即 'a'return 0;
}程序在 VS Code 中的运行结果如下所示:
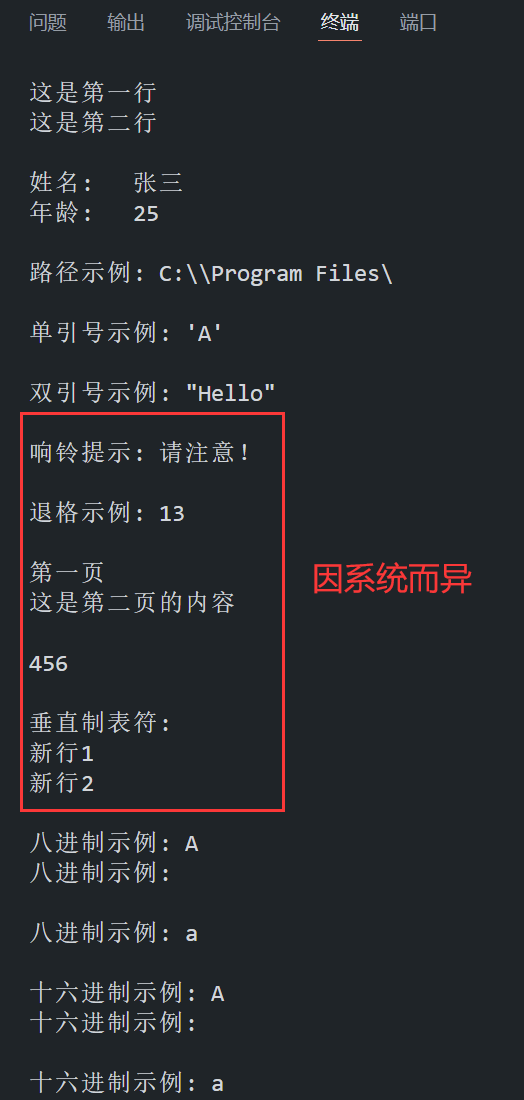
2.3 单双引号转义使用要点
在 C 语言中,字符串是由双引号 " " 括起来的字符序列。当我们需要在字符串中合理使用单引号和双引号时,需要遵循特定规则:
- 单引号在字符串中的使用:在由双引号包围的字符串内部,可以直接使用单引号,无需进行转义。因为单引号在这里被当作字符串的普通字符内容,而非界定字符常量的符号。例如:
printf("This is a 'character' inside a string.\n");
// 输出结果:This is a 'character' inside a string.上述代码执行后,会正常输出字符串,其中单引号会被当作字符串的一部分输出,输出结果为:This is a 'character' inside a string.
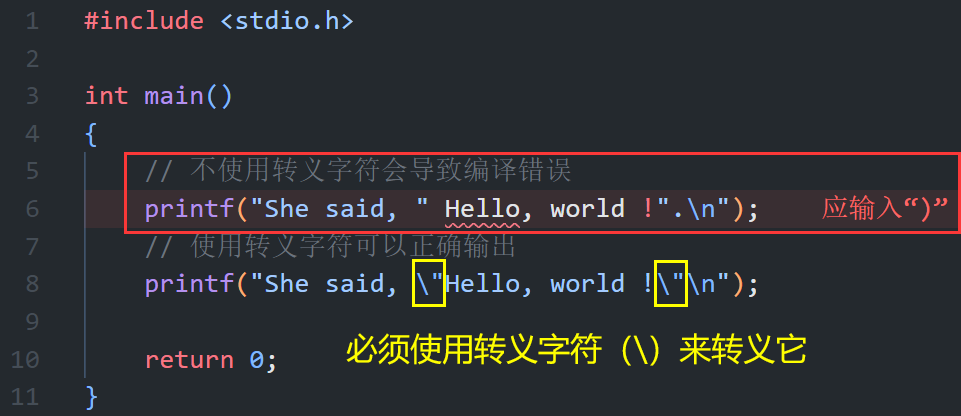
- 双引号在字符串中的使用:由于双引号本身用于界定字符串的开始和结束,所以不能直接在双引号界定的字符串内部使用另一个未转义的双引号。若要在字符串中包含双引号字符,必须使用转义字符 \ 对其进行转义。经过转义后,紧随转义字符的双引号就会被视为字符串的一部分,而非字符串的结束标志。如下图所示:
3 字符类型格式占位符
在 C 语言中,使用格式化输出函数(如 printf)时,针对 char 类型的数据,有不同的格式占位符来满足不同的输出需求:
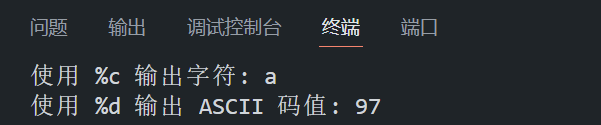
- 使用 %c 格式化占位符,可以直接输出 char 类型的字符本身。例如,printf("%c", 'a'); 会输出字符 a。
- 使用 %d 格式化占位符,可以输出该字符对应的 ASCII 码值。例如,printf("%d", 'a'); 会输出 97,即字符 'a' 在 ASCII 码表中的十进制数值。
#include <stdio.h>int main()
{// 定义一个字符变量char c = 'a';// 使用 %c 输出字符本身printf("使用 %%c 输出字符: %c\n", c); // 输出: a// 使用 %d 输出字符对应的 ASCII 码值printf("使用 %%d 输出 ASCII 码值: %d\n", c); // 输出: 97return 0;
}程序在 VS Code 中的运行结果如下所示:
4 字符类型的本质
在 C 语言中,char 类型本质上是一个整数类型,它对应着 ASCII 码表中的数字,其存储长度固定为 1 个字节(8 位)。
字符型可进一步细分为 signed char(有符号字符类型)和 unsigned char(无符号字符类型)。
- signed char 的取值范围是 -128 到 127。
- unsigned char 的取值范围是 0 到 255。
在实际使用中,char 类型默认是否带符号取决于当前的运行环境。
可通过 <limits.h> 头文件中的宏定义直接获取取值范围:
- SCHAR_MIN / SCHAR_MAX:signed char 的最小 / 最大值。
- UCHAR_MAX:unsigned char 的最大值(最小值固定为 0)。
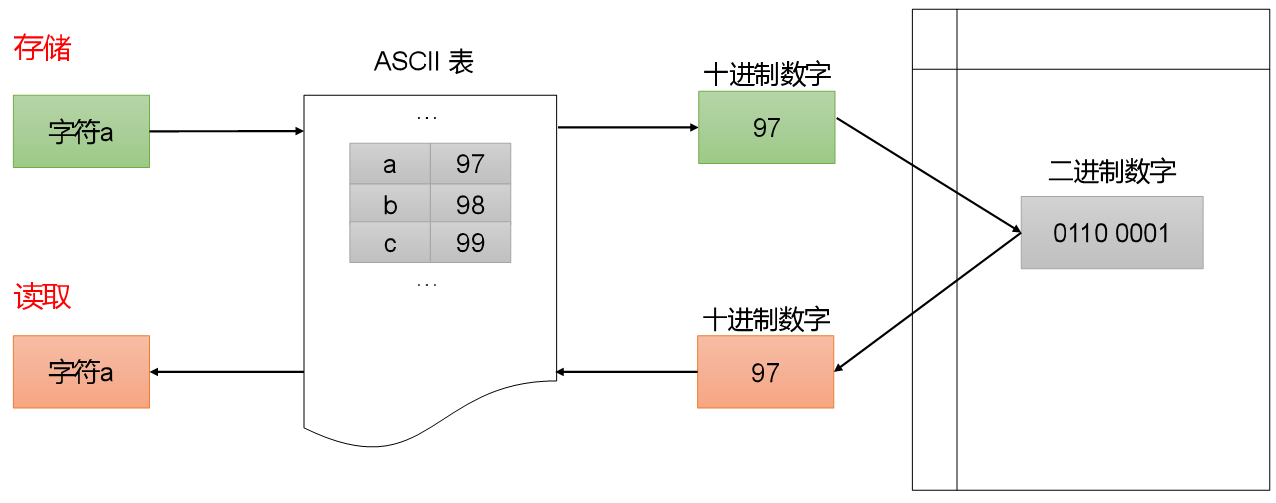
字符型数据在存储和读取过程中,会涉及到 ASCII 码的转换。例如,字符 'a' 在 ASCII 码表中对应的十进制数字是 97,在存储时以二进制形式存储,读取时再根据 ASCII 码表还原为字符 'a'。具体过程可参考下图:
#include <stdio.h>
#include <limits.h> // 用于获取字符类型的范围int main()
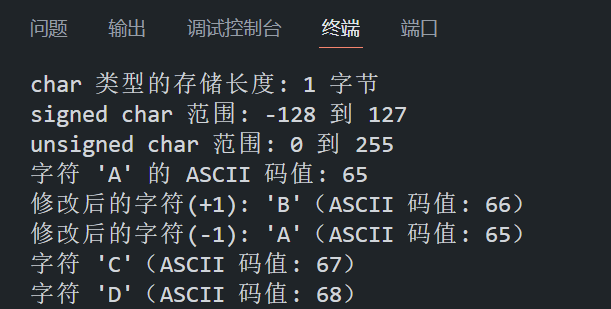
{// 1. 验证 char 类型的存储长度printf("char 类型的存储长度: %zu 字节\n", sizeof(char)); // 输出: 1 字节// 2. 输出 signed char 和 unsigned char 的范围printf("signed char 范围: %d 到 %d\n", SCHAR_MIN, SCHAR_MAX); // -128 到 127printf("unsigned char 范围: 0 到 %u\n", UCHAR_MAX); // 0 到 255// 3. 演示 char 类型的整数特性(ASCII 码值)char c = 'A'; // 字符 'A' 对应 ASCII 码 65printf("字符 '%c' 的 ASCII 码值: %d\n", c, c); // 输出: 65// 3.1 通过整数操作修改字符,验证 char 类型的整数特性c = c + 1; // ASCII 码值 +1,'A' -> 'B'printf("修改后的字符(+1): '%c'(ASCII 码值: %d)\n", c, c); // 输出: 'B' 和 66c = c - 1; // ASCII 码值 -1,'B' -> 'A'printf("修改后的字符(-1): '%c'(ASCII 码值: %d)\n", c, c); // 输出: 'A' 和 65// 3.2 定义 unsigned char 类型变量,存储整数值,验证 char 类型的整数特性unsigned char d = 67; // 存储 ASCII 码值 67,对应字符 'C'// char 类型整数字面量没有后缀形式,这里的 67 其实是 int 类型,编译器进行了隐式类型转换printf("字符 '%c'(ASCII 码值: %d)\n", d, d); // 输出: 'C' 和 67// 3.3 定义 int 类型数据,存储整数值,验证 char 类型的整数特性int i = 68;printf("字符 '%c'(ASCII 码值: %d)\n", i, i); // 输出: 'D' 和 68return 0;
}程序在 VS Code 中的运行结果如下所示:
5 整数/浮点/字符类型的最值宏汇总
在 C 语言中,可以通过引入头文件 <limits.h>(整数 / 字符类型)和 <float.h>(浮点数类型),使用宏定义来获取各种类型的取值范围。以下是分类总结:
5.1 整数类型(包括 char)
需引入头文件:#include <limits.h>
最值宏名称及其含义:
| 类型 | 宏定义 | 含义 | 示例值(32 位系统) |
|---|---|---|---|
char | CHAR_MIN / CHAR_MAX | 默认 char 的最小 / 最大值(符号性取决于环境) | 依赖编译器(可能是 -128 到 127 或 0 到 255) |
signed char | SCHAR_MIN | signed char 的最小值 | -128 |
SCHAR_MAX | signed char 的最大值 | 127 | |
unsigned char | UCHAR_MAX | unsigned char 的最大值 | 255 |
short | SHRT_MIN | short 的最小值 | -32768 |
SHRT_MAX | short 的最大值 | 32767 | |
unsigned short | USHRT_MAX | unsigned short 的最大值 | 65535 |
int | INT_MIN | int 的最小值 | -2147483648 |
INT_MAX | int 的最大值 | 2147483647 | |
unsigned int | UINT_MAX | unsigned int 的最大值 | 4294967295 |
long | LONG_MIN | long 的最小值 | 依赖系统(如 -2147483648) |
LONG_MAX | long 的最大值 | 依赖系统(如 2147483647) | |
unsigned long | ULONG_MAX | unsigned long 的最大值 | 依赖系统(如 4294967295) |
long long | LLONG_MIN | long long 的最小值 | -9223372036854775808 |
LLONG_MAX | long long 的最大值 | 9223372036854775807 | |
unsigned long long | ULLONG_MAX | unsigned long long 的最大值 | 18446744073709551615 |
5.2 浮点数类型
需引入头文件:#include <float.h>
最值宏名称及其含义:
| 类型 | 宏定义 | 含义 | 示例值(IEEE 754 标准) |
|---|---|---|---|
float | FLT_MIN | 最小正规范化值(非零最小值) | 1.175494e-38 |
FLT_MAX | 最大有限值 | 3.402823e+38 | |
FLT_EPSILON | 机器 epsilon(最小可表示差值) 即 1.0 与比 1.0 大的最小可表示单精度浮点数之间的差值,用于判断单精度浮点数的近似相等性或分析数值稳定性 | 1.192093e-7 | |
double | DBL_MIN | 最小正规范化值(非零最小值) | 2.225074e-308 |
DBL_MAX | 最大有限值 | 1.797693e+308 | |
DBL_EPSILON | 机器 epsilon(最小可表示差值) 即 1.0 与比 1.0 大的最小可表示双精度浮点数之间的差值,用于双精度浮点数的误差分析和比较 | 2.220446e-16 | |
long double | LDBL_MIN | 最小正规范化值(非零最小值) | 依赖系统(如 3.362103e-4932) |
LDBL_MAX | 最大有限值 | 依赖系统(如 1.189731e+4932) | |
LDBL_EPSILON | 机器 epsilon(最小可表示差值) 即 1.0 与比 1.0 大的最小可表示长双精度浮点数之间的差值,用于长双精度浮点数的高精度计算 | 依赖系统(如 1.084202e-19) |
- 机器 epsilon 是浮点数格式的最小上界,使得 1.0 + ε > 1.0 为真。它反映了浮点数的相对精度。典型用途如下:
- 浮点数比较(判断近似相等性)。
- 数值算法的误差分析。
- 避免浮点运算中的累积误差问题。
6 ASCII 码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是一种用于表示文本字符的字符编码标准。它总共规定了 128 个字符的编码。
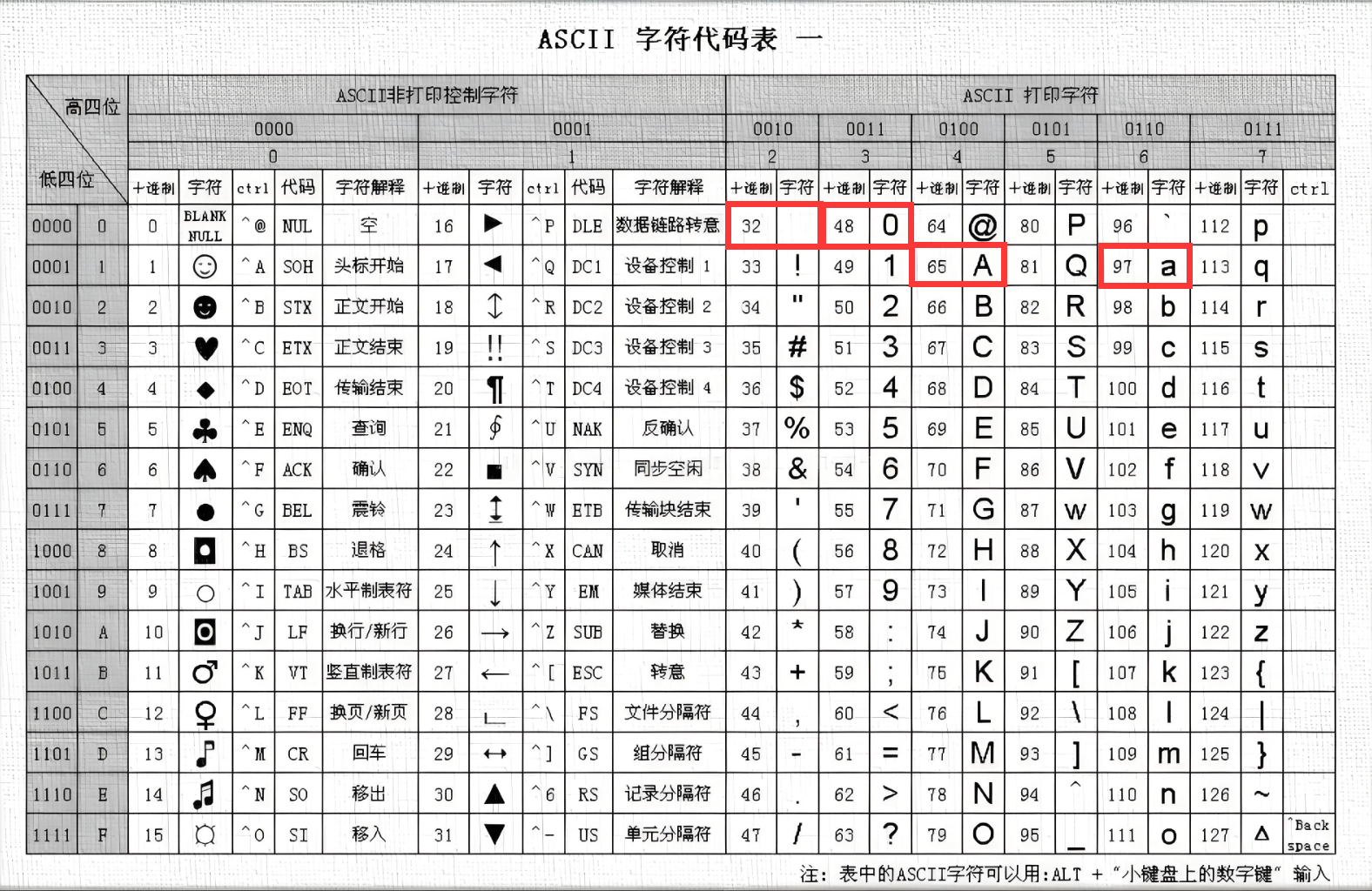
在 ASCII 码体系中,不同字符对应着特定的十进制和二进制编码。例如:
- 空格字符 “SPACE” 的 ASCII 码值为 32,其二进制表示为 0010 0000。
- 数字字符 0 的 ASCII 码值为 48,二进制表示为 0011 0000。
- 大写字母 A 的 ASCII 码值为 65,二进制表示为 0100 0001。
- 小写字母 a 的 ASCII 码值为 97,二进制表示为 0110 0001。
通过 ASCII 码,计算机能够以统一的方式存储、处理和传输文本字符,确保不同系统之间文本信息的准确交互。
7 编程练习
7.1 字符输出与格式化
定义三个 char 变量,分别存储字母、数字和符号,然后使用 printf 格式化输出它们的值和 ASCII 码。
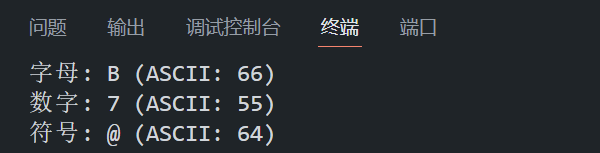
#include <stdio.h>int main()
{char letter = 'B';char digit = '7';char symbol = '@';printf("字母: %c (ASCII: %d)\n", letter, letter); // 字母: B (ASCII: 66)printf("数字: %c (ASCII: %d)\n", digit, digit); // 数字: 7 (ASCII: 55)printf("符号: %c (ASCII: %d)\n", symbol, symbol); // 符号: @ (ASCII: 64)return 0;
}程序在 VS Code 中的运行结果如下所示:
7.2 固定字母大小写转换
定义一个 char 变量存储大写字母 'A',通过算术运算将其转换为小写字母 'a' 并输出。再定义一个 char 变量存储小写字母 'z',通过算术运算将其转换为大写字母 'Z' 并输出。
#include <stdio.h>int main()
{// 大写字母 'A' 转小写字母 'a'char upper = 'A';upper = upper + 32; // ASCII 码 +32printf("大写 'A' 转换为小写: %c\n", upper); // 输出 'a'// 小写字母 'z' 转大写字母 'Z'char lower = 'z';lower = lower - 32; // ASCII 码 -32printf("小写 'z' 转换为大写: %c\n", lower); // 输出 'Z'return 0;
}- 掌握大小写字母的转换方法(大写字母的 ASCII 码 +32 得到小写字母,反之 -32)。
程序在 VS Code 中的运行结果如下所示:

7.3 字符与数字的混合运算
- 定义一个 char 变量存储数字字符 '5',通过算术运算将其转换为整数 5 并输出。
- 定义一个 int 变量存储整数 3,通过算术运算将其转换为字符 '3' 并输出。
- 对字符 '5' 和整数 3 进行混合运算(如相加),并分别以字符和整数形式输出结果。
#include <stdio.h>int main()
{// 数字字符 '5' 转整数 5char digit_char = '5';int digit_int = digit_char - '0'; // ASCII 码相减printf("字符 '%c' 对应的整数: %d\n", digit_char, digit_int); // 输出 5// 整数 3 转字符 '3'int num = 3;char num_char = num + '0'; // ASCII 码相加printf("整数 %d 对应的字符: %c\n", num, num_char); // 输出 '3'// 混合运算char mixed_char = digit_char + num; // '5' + 3 = '8'// 以 %c 和 %d 输出结果printf("混合运算结果(字符:): %c\n", mixed_char); // 输出 '8'printf("混合运算结果(整数:): %d\n", mixed_char); // 输出 56(53+3)return 0;
}程序在 VS Code 中的运行结果如下所示:

7.4 字符的对称转换
定义一个 char 变量存储字母 'd',通过算术运算将其转换为字母表中对称的字母(如 'a' ↔ 'z','b' ↔ 'y','c' ↔ 'x','d' ↔ 'w')并输出。
#include <stdio.h>int main()
{char c = 'd';// 计算对称字母:'a' + ('z' - c)c = 'a' + ('z' - c);printf("字母 '%c' 的对称字母: %c\n", 'd', c); // 输出 'w'return 0;
}- 对称字母 = 字母表起始位置 + (字母表末尾位置 - 当前字母位置)
程序在 VS Code 中的运行结果如下所示:

7.5 字符的循环偏移
定义一个 char 变量存储字母 'X',通过算术运算将其转换为字母表中后第 5 个字母(如 'X' → 'C',注意字母表的循环)。
#include <stdio.h>int main()
{char c = 'X';// 计算循环偏移:((c - 'A' + 5) % 26) + 'A'// % 是求余数运算符c = ((c - 'A' + 5) % 26) + 'A';printf("字母 '%c' 后第 5 个字母(循环): %c\n", 'X', c); // 输出 'C'return 0;
}- 偏移后字母 = 'A' + ((当前字母位置 + 偏移量) % 26)
- c - 'A':将字母转换为 0 到 25 的位置。
- + n:向后偏移 n 个位置。
- % 26:处理字母表的循环(超过 'Z' 时回到 'A')。
- + 'A':将位置转换回 ASCII 字符。
程序在 VS Code 中的运行结果如下所示:
