selenium替代----playwright
安装
好处特点:这个东西不像selenium需要固定版本的驱动
pip config set global.index-url https://mirrors.aliyun.com/pypi/simplepip install --upgrade pippip install playwright playwright installplaywright install ffmpeg (处理音视频的)
验证:
from playwright.sync_api import sync_playwright
pw =sync_playwright().start()
driver = pw.chromium.launch(headless=False)
page =driver.new_page()
page.goto("https://www.baidu.com")
input("回车结束")加等待
page.wait_for_timeout(3000) # 等待3秒定位元素
1.locator (唯一才行,不然要报错)、介绍有哪些
- id

- text (似乎a标签才可以)

- tag name

- css

百度首页、案例、 简单定位
from playwright.sync_api import sync_playwright
pw = sync_playwright().start()
driver = pw.chromium.launch(headless=False)
page = driver.new_page()
page.goto("https://www.baidu.com")
page.locator("#kw").fill("python") # css定位(推荐)
page.wait_for_timeout(1500)
page.locator("id=kw").fill("java") # id定位
page.wait_for_timeout(1500)
page.locator("text=百度首页").click() # (a标签)的文本定位方式input("回车结束")
2.query_selector (找一个的)
(找不到时报错,找一个,若有多个,也返回第一个)
![]()
3. query_selector_all (找多个,若没有是空列表)
![]()
css定位
【总结】ui自动化selenium知识点总结-CSDN博客
补充
- 通用选择器 * ,比如div>* 表示div下面的所有儿子
- 可以用, 逗号分割,一起多定位一些元素 (用query_selector_all 查时 ,如下:
-
from playwright.sync_api import sync_playwright pw = sync_playwright().start() driver = pw.chromium.launch(headless=False) page = driver.new_page() page.goto("https://www.baidu.com")list1 = page.query_selector_all("#kw,#su") print(list1) for i in list1:print(i.get_attribute("id")) input("回车结束")
Xpath定位(css没有的):
//*[text(),"文本"] //*[contains(text(),"文本")]
//input[@id='kw' and @class=‘xx’] ---多属性联合查
//xxx/.. 用..找到上级
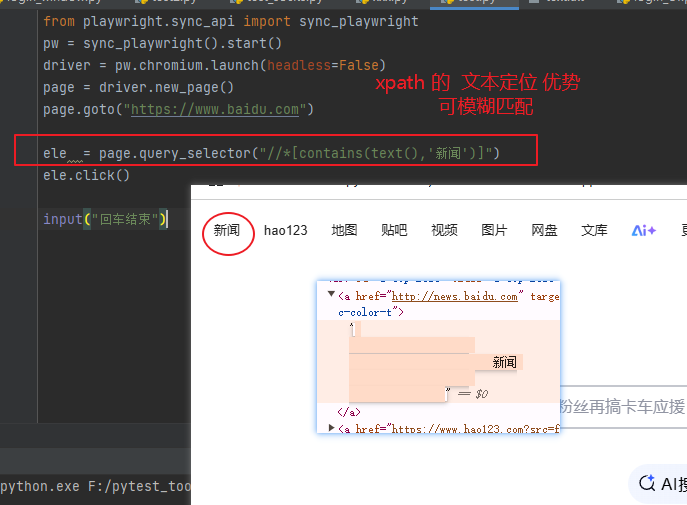
元素操作
- .fill("xxxx") 覆盖写入 .click() .press() .hover()
- .clear()
-
最大化窗口启动 driver = pw.chromium.launch(headless=False,args=["--start-maximized"]) page =driver.new_page(no_viewport=True)
- 设置窗口大小
-
site =page.viewport_size # page =driver.new_page(no_viewport=True) 用这个不能这样 print(site) # 设置框高 page.set_viewport_size({'width': 2000, 'height': 720})
-
- 浏览器操作和获取
-
page.go_forward() # 前进 page.go_back() # 后退 page.reload() # 刷新 print(page.url) # 这个没有括号哦 print(page.title())
-
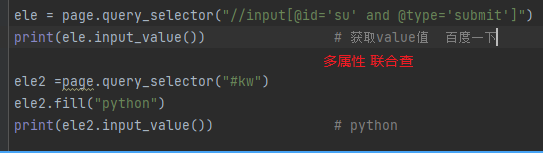
- print(ele.get_attribute('name')) # 获取属性值, 获取不到就是None
- .text_content() # 获取元素的文本
- .input_value() # 获取value属性
- 获取元素的坐标和尺寸大小

- 是否可见 是否选中 is_selected (例子如下) 是否可用 is_enabled
-
from playwright.sync_api import sync_playwright pw =sync_playwright().start() driver = pw.chromium.launch(headless=False) page =driver.new_page() ui_host= "http://121.43.36.83:8088" page.goto(f"{ui_host}/index.html#/")page.locator("#username").fill("sq2") page.query_selector("#password").fill("123") page.locator("#code").fill("999999") page.query_selector("#submitButton").click()# 先等待一下,不然直接刷新有问题 page.wait_for_url(f"{ui_host}/index.html#/home") # 刷新 page.reload()# 按钮-----单选 page.query_selector(".el-menu >.el-submenu:nth-child(1)").click() page.query_selector(".el-menu >.el-submenu:nth-child(1) ul li:nth-child(1)").click()eles = page.query_selector_all(".el-row .el-radio__label") for ele in eles:# print(ele.text_content(),"是否可见",ele.is_visible())print(ele.text_content(),"是否选中",ele.is_checked())input("回车结束") - 窗口fang 截图、元素截图。screenshot()

-
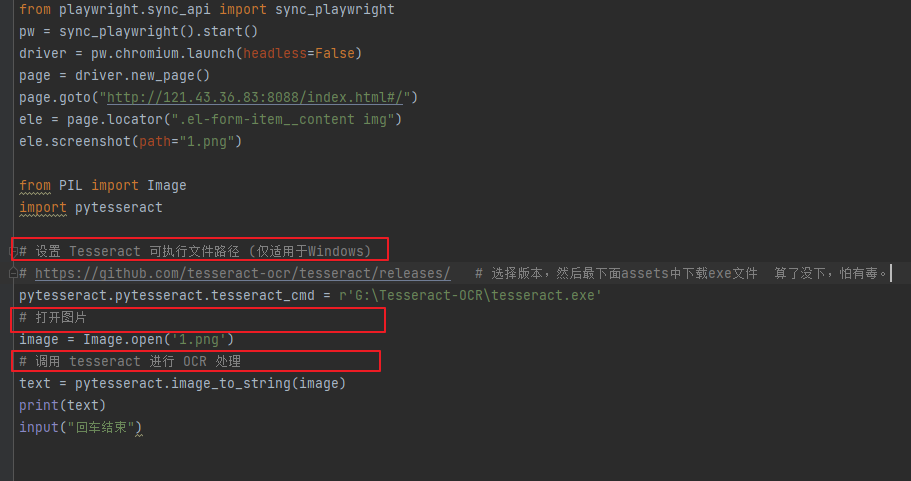
OCR识别方式1:没试过 - ocr识别方式2: 它返回的是 字节流,用dddocr,就可以识别解析
-
from playwright.sync_api import sync_playwright pw = sync_playwright().start() driver = pw.chromium.launch(headless=True) page = driver.new_page() page.goto("http://121.43.36.83:8088/index.html#/") ele = page.locator(".el-form-item__content img") ele_bytes = ele.screenshot(path="1.png") import ddddocr # pip install ddddocr ocr=ddddocr.DdddOcr(show_ad=False) text =ocr.classification(ele_bytes) print(text) - 也可以用rb读取本地的图片,得到字节流,然后用他来
-
with open("1.png", "rb") as f:pic_bytes = f.read() import ddddocr # pip install ddddocr ocr=ddddocr.DdddOcr(show_ad=False) text =ocr.classification(pic_bytes) print(text)
-
-
-
键盘操作

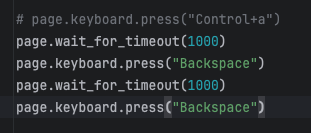
-
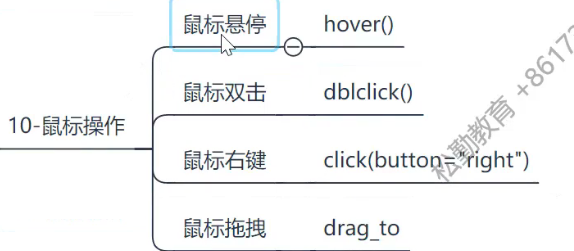
鼠标操作(--待验证)
- 是针对元素的, ele.hover()
- drag_to(ele1,ele2)
-
-
# 鼠标拖拽 page.goto(f"https://sahitest.com/demo/dragDropMooTools.htm") ele2 = page.locator('.item:nth-of-type(4)') page.locator('#dragger').drag_to(ele2)
-
弹窗处理
是监听,和selenium有所不同
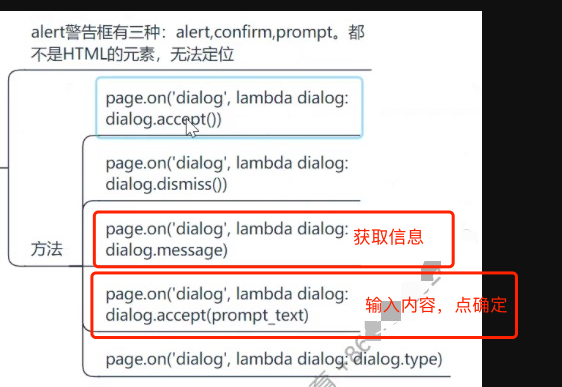
监听事件,监听到了,就会走lambda 的匿名函数。
from playwright.sync_api import sync_playwright
pw =sync_playwright().start()
driver = pw.chromium.launch(headless=False)
page =driver.new_page()
ui_host= "http://121.43.36.83:8088"
page.goto(f"{ui_host}/index.html#/")page.locator("#username").fill("sq2")
page.query_selector("#password").fill("123")
page.locator("#code").fill("999999")
page.query_selector("#submitButton").click()# 先等待一下,不然直接刷新有问题
page.wait_for_url(f"{ui_host}/index.html#/home")
# 刷新
page.reload()# 按钮-----弹窗
page.query_selector(".el-menu >.el-submenu:nth-child(5)").click()
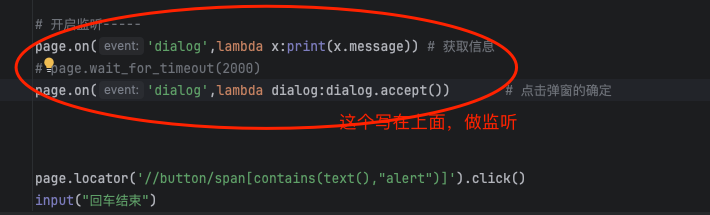
page.query_selector(".el-menu >.el-submenu:nth-child(5) ul li:nth-child(1)").click()# 开启监听-----
page.on('dialog',lambda x:print(x.message)) # 获取信息page.on('dialog',lambda dialog:dialog.accept('333333')) # 点击弹窗的确定page.locator('//button/span[contains(text(),"alert")]').click()
page.wait_for_timeout(2000)
page.locator('//button/span[contains(text(),"prompt")]').click()
input("回车结束")执行js语句
用page.evaluate(js)

from playwright.sync_api import sync_playwright
pw =sync_playwright().start()
driver = pw.chromium.launch(headless=False)
page =driver.new_page()
page.goto(f"https://www.baidu.com/")page.locator("#kw").fill("迪丽热巴")
page.set_viewport_size({'width': 720, 'height': 720})page.wait_for_timeout(2000)
js = 'window.scrollTo(0,400);' # 绝对的移动,往下400
page.evaluate(js)page.wait_for_timeout(2000)
js2 = 'window.scrollBy(300,0);' # 相对的移动,往右 300
page.evaluate(js2)input("回车结束")文件上传
input 标签的话,好操些。
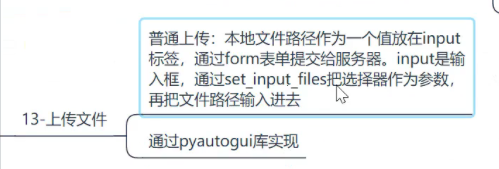
input标签(好处理):
其他的(需要借助pyautogui库)
from playwright.sync_api import sync_playwright
pw =sync_playwright().start()
driver = pw.chromium.launch(headless=False)
page =driver.new_page()
ui_host= "http://121.43.36.83:8088"
page.goto(f"{ui_host}/index.html#/")page.locator("#username").fill("sq2")
page.query_selector("#password").fill("123")
page.locator("#code").fill("999999")
page.query_selector("#submitButton").click()# 先等待一下,不然直接刷新有问题
page.wait_for_url(f"{ui_host}/index.html#/home")
# 刷新
page.reload()# page.locator("//span[text()='文件上传']")
page.query_selector(".el-menu >.el-submenu:nth-child(6)").click() # 同上# 单文件上传
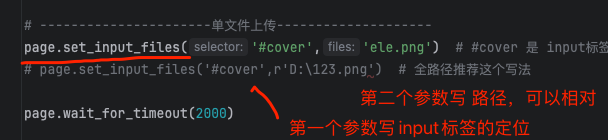
page.query_selector(".el-menu >.el-submenu:nth-child(6) ul li:nth-child(1)").click()# ----------------------单文件上传--------------------
page.set_input_files('#cover','ele.png') # #cover 是 input标签
# page.set_input_files('#cover',r'D:\123.png') # 全路径推荐这个写法page.wait_for_timeout(2000)# ----------------------单文件上传(非input)--------------------需要装pyautogui
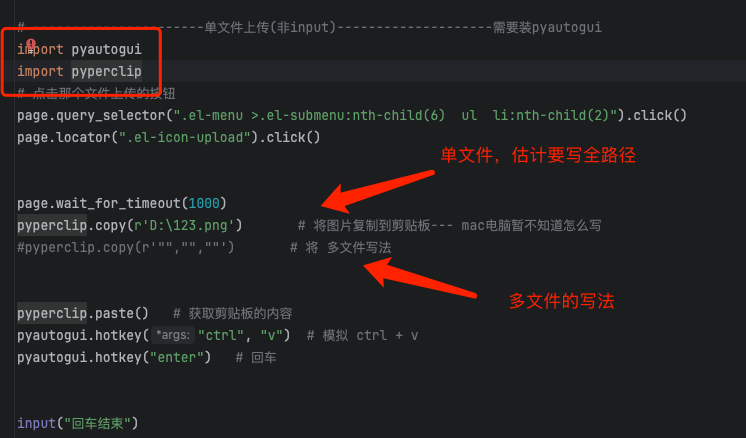
import pyautogui
import pyperclip
# 点击那个文件上传的按钮
page.query_selector(".el-menu >.el-submenu:nth-child(6) ul li:nth-child(2)").click()
page.locator(".el-icon-upload").click()page.wait_for_timeout(1000)
pyperclip.copy(r'D:\123.png') # 将图片复制到剪贴板--- mac电脑暂不知道怎么写
#pyperclip.copy(r'"","",""') # 将 多文件写法pyperclip.paste() # 获取剪贴板的内容
pyautogui.hotkey("ctrl", "v") # 模拟 ctrl + v
pyautogui.hotkey("enter") # 回车input("回车结束")iframe操作
遇到iframe标签时。 需要指定哪个frame,然后操作, (它相比与selenium,不需要切进去切出来)


方式1
可以用page.frame('name值')。或者 page.frame(url="")

方式2-- 通过frame的元素定位选到frame
![]()
窗口对象获取
相比selenium ,也是不用在切来切去。 每个窗口都可以得到一个对象

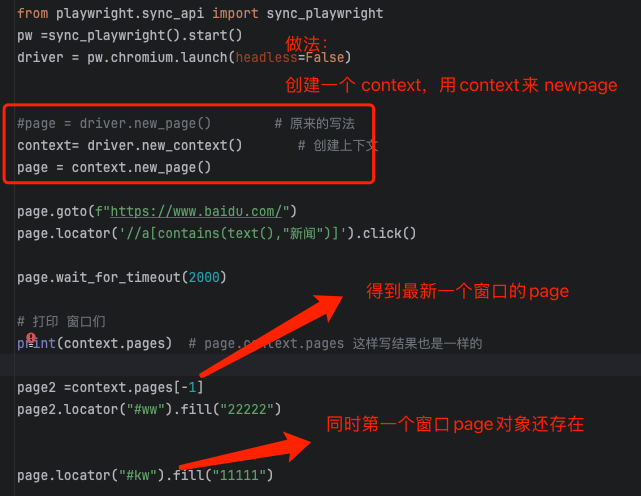
from playwright.sync_api import sync_playwright
pw =sync_playwright().start()
driver = pw.chromium.launch(headless=False)#page = driver.new_page() # 原来的写法
context= driver.new_context() # 创建上下文
page1 = context.new_page()page1.goto(f"https://www.baidu.com/")
page1.locator('//a[contains(text(),"新闻")]').click()page1.wait_for_timeout(2000)# 打印 窗口们
print(context.pages) # page.context.pages 这样写结果也是一样的page2 =context.pages[-1]
page2.locator("#ww").fill("22222")page1.locator("#kw").fill("11111")input("回车结束")某些元素的处理方式
1. 单选框,click一下就好了
复选框处理
选之前,可以先做一个是否选中的判断,不然再点两次点没了。
from playwright.sync_api import sync_playwright
pw =sync_playwright().start()
driver = pw.chromium.launch(headless=False)
page =driver.new_page()
ui_host= "http://121.43.36.83:8088"
page.goto(f"{ui_host}/index.html#/")page.locator("#username").fill("sq2")
page.query_selector("#password").fill("123")
page.locator("#code").fill("999999")
page.query_selector("#submitButton").click()# 先等待一下,不然直接刷新有问题
page.wait_for_url(f"{ui_host}/index.html#/home")
# 刷新
page.reload()# 按钮-----复选框
page.query_selector(".el-menu >.el-submenu:nth-child(1)").click()
page.query_selector(".el-menu >.el-submenu:nth-child(1) ul li:nth-child(2)").click()eles = page.query_selector_all("//input[@value='11']/..") # xpath 定位, 唱歌 和水果
for ele in eles:# print(ele)checked = ele.is_checked()# print(checked)if checked:print("选了")else:print("没有选")ele.click()input("回车结束")下拉框处理
如果是select 和option标签的。

from playwright.sync_api import sync_playwright
pw =sync_playwright().start()
driver = pw.chromium.launch(headless=False)
page =driver.new_page()
ui_host= "http://121.43.36.83:8088"
page.goto(f"{ui_host}/index.html#/")page.locator("#username").fill("sq2")
page.query_selector("#password").fill("123")
page.locator("#code").fill("999999")
page.query_selector("#submitButton").click()# 先等待一下,不然直接刷新有问题
page.wait_for_url(f"{ui_host}/index.html#/home")
# 刷新
page.reload()# 按钮-----复选框
page.query_selector(".el-menu >.el-submenu:nth-child(1)").click()
page.query_selector(".el-menu >.el-submenu:nth-child(1) ul li:nth-child(3)").click()# select 标签
page.wait_for_timeout(1000)
ele = page.locator('select#categoryId')
ele.select_option(index=2) # 根据索引选
page.wait_for_timeout(1000)
ele.select_option(value="1") # 根据value值
page.wait_for_timeout(1000)
ele.select_option(label="家居家装") # 中间的文本信息# 如果支持多选,就写成。label=('',''), 这种写法,或者结合三种方式都可以的
ele.select_option(label=("家居家装","xxx"), index=(1,3), value="xxxxx") # 中间的文本信息input("回车结束")额外知识
1 操作方法,可以直接定位,设置超时(不认知默认是30s)等
1. 操作上可以添加超时方法,fill上、text_content 等操作方法里添加 timeout

![]()
全局设置:page.set_default_timeout(10000),
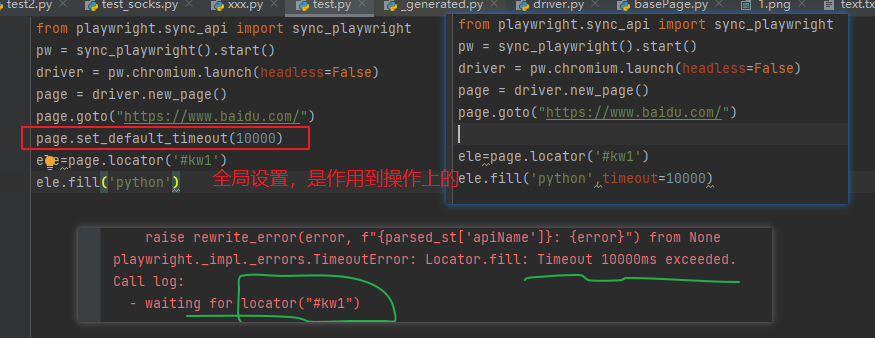
2 、操作上可以直接加 元素定位。
。fill()。也可以直接用的, page.fill('元素定位', text,timeout=1000)
2. 等待
- 感觉有点像sleep
![]()
- 等到某个url出现
![]()
1. 等到某个元素出现(类似显示等待+)

3. 容易消失的元素找定位技巧
表示,5秒后,冻屏
setTimeout(function() {debugger
},5000)
框架实现(demo)
框架思路和selenium一样:
【ui自动化】框架搭建v2.0_ui自动化框架如何实现-CSDN博客
【PO框架总结】ui自动化selenium,清新脱俗代码,框架升级讲解_ui自动化po博客园-CSDN博客
1 .新建common 包,新建 driver_page.py
里面获取page对象(selenium是获取driver)
并且,代码最后创建一个 page对象,后续都用这一个对象,实现单例的效果。只有一个浏览器页面存在
from playwright.sync_api import sync_playwright
# from configs.config import Configdef get_page(browser_type="chrome"):pw = sync_playwright().start()if browser_type == 'chrome':driver = pw.chromium.launch(headless=False, args=["--start-maximized"]) # 获取一个浏览器对象# 设置全屏# page = driver.new_page(no_viewport=True)# 多窗口时的上下文context = driver.new_context()# page = context.new_page(no_viewport=True) #使用context.new_page,不能加这个参数page = context.new_page() # 新建一个页面page.set_viewport_size({'width': 1920, 'height': 1080})# input("---调试用---")return pageelif browser_type == 'firefox': # 有点慢driver = pw.firefox.launch(headless=False) # 获取一个浏览器对象page = driver.new_page(viewport={'width': 1920, 'height': 1080}) # 新建一个页面,(firefox全屏时有点点问题)# input("---调试用---")return pageyourpage = get_page()2. 新建的common 包下,新建 basePage.py 页面基类
它作为所有页面类的基础类
- 获取到唯一page对象,或者selenium里面的driver。这个就可以操作浏览器,也可以二次封装一些基础方法。
- 统一管理一个 元素yaml文件。页面类继承basePage.py后获取文件中各自的元素定位
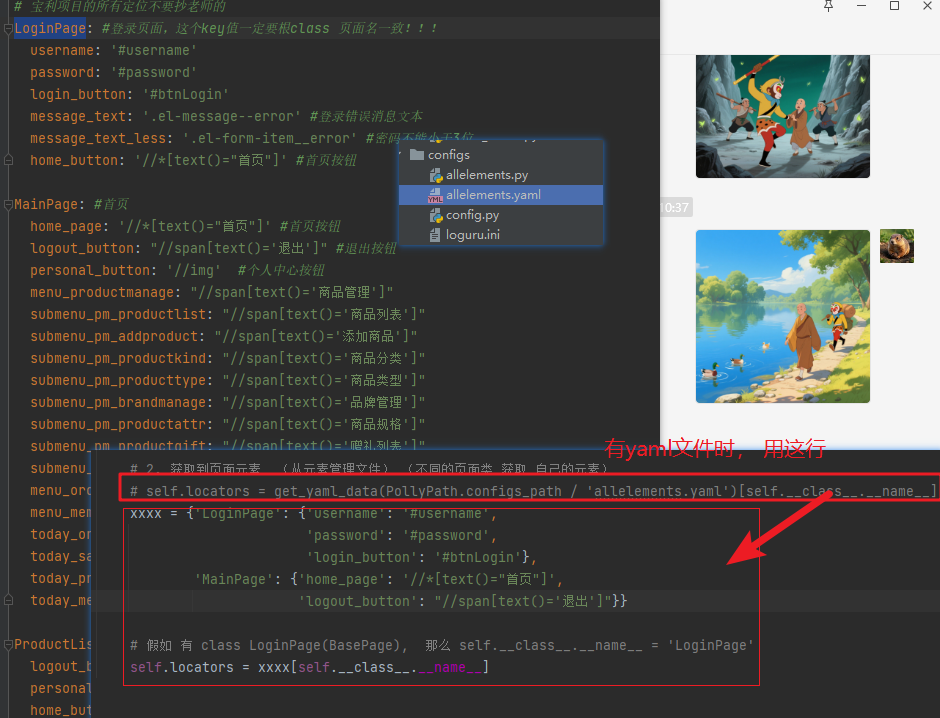
from common.dirver_page import yourpageclass BasePage(object):def __init__(self):# 1. 获取到那个唯一的页面对象,拿来操作浏览器self.page = yourpage# 2. 获取到页面元素 (从元素管理文件) (不同的页面类 获取 自己的元素)# self.locators = get_yaml_data(PollyPath.configs_path / 'allelements.yaml')[self.__class__.__name__]xxxx = {'LoginPage': {'百度首页输入框': '#kw','百度搜索按钮': '#su','login_button': '#btnLogin'},'MainPage': {'home_page': '//*[text()="首页"]','logout_button': "//span[text()='退出']"}}# 假如 有 class LoginPage(BasePage), 那么 self.__class__.__name__ = 'LoginPage'self.locators = xxxx[self.__class__.__name__]# 有了这个方法后,就可以实现,让 self.locators 这个字典, 本来是self.locators['username'] 获取到 '#username', 可以直接用self['username'] 获取。def __getitem__(self, item):return self.locators[item]def get_page(self):return self.pageif __name__ == '__main__':class LoginPage(BasePage):passlp1= LoginPage()print(lp1.locators['百度首页输入框']) # 输出:#kwprint(lp1['百度首页输入框']) # 输出:#kwpage = lp1.get_page()page.goto("https://www.baidu.com/")page.fill(lp1['百度首页输入框'],'admin') # 是哪个元素,可以做到见名知意input("---卡住--")统一管理的元素yaml文件(后面再提供完整代码)
结构要和上面的xxxx一样。这个是一个大字典,一个页面一个key
每个key的值,又是一个字典,里面每一项是一个元素,名称 : 元素定位
元素定位直接写 CSS的定位,或xpath的定位即可
需注意 LoginPage 的命名 要和接下来的pages包中 定义 LoginPage类名称一致
3. 新建pages包,新建LoginPage.py 表示登录页
要继承basePage.
from common.basePage import BasePageclass LoginPage(BasePage):# 假装百度是登录页面# 访问页面def open_login_page(self):self.page.goto("https://www.baidu.com")def login(self,msg):self.page.fill(self["百度首页输入框"], msg)self.page.click(self["百度搜索按钮"])self.page.wait_for_timeout(2000)self.page.screenshot(path="./screenshot/baidu.png")if __name__ == '__main__':lp1 = LoginPage()# 步骤1:打开页面lp1.open_login_page()# 步骤2:登录lp1.login("selenium")
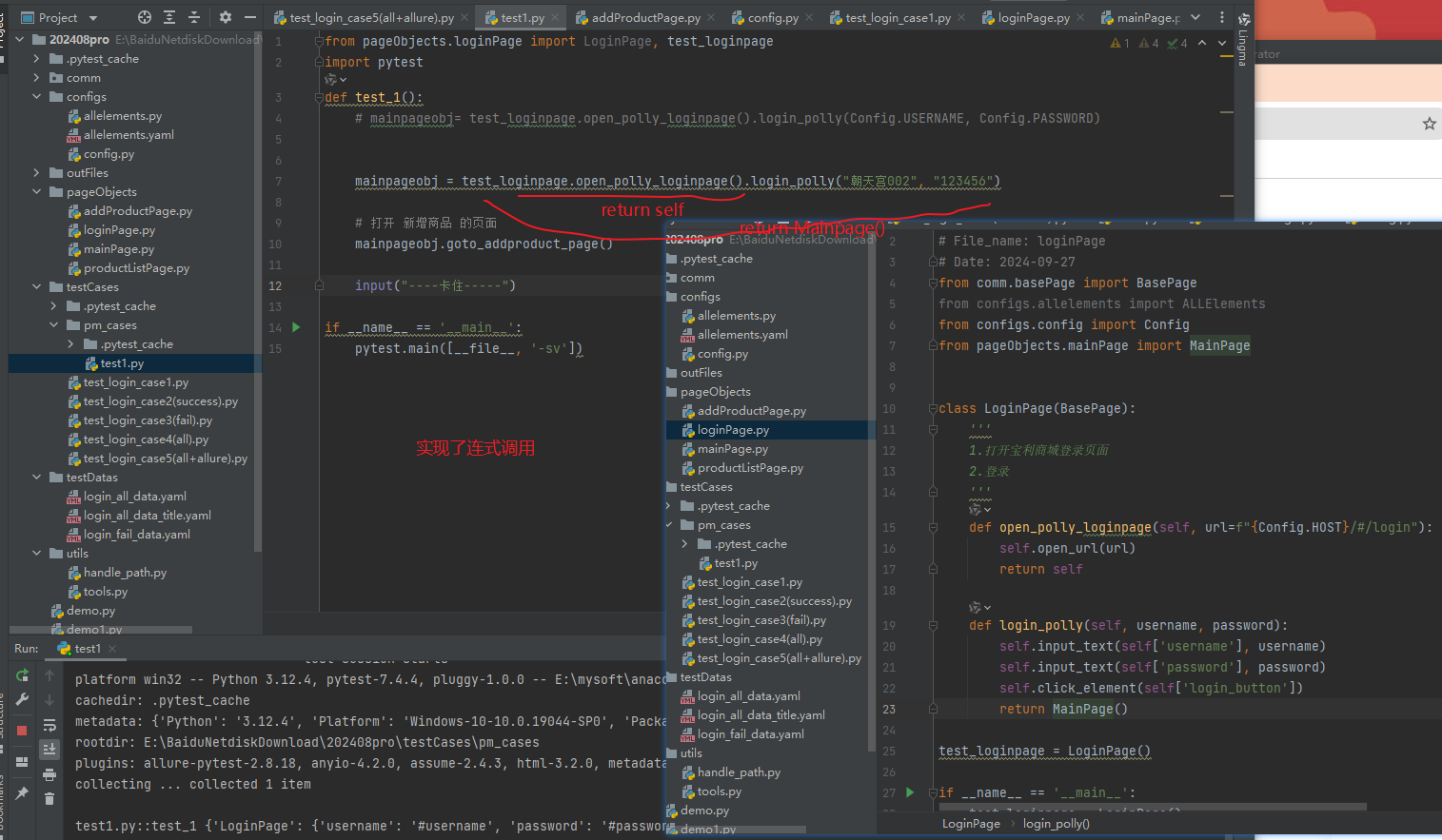
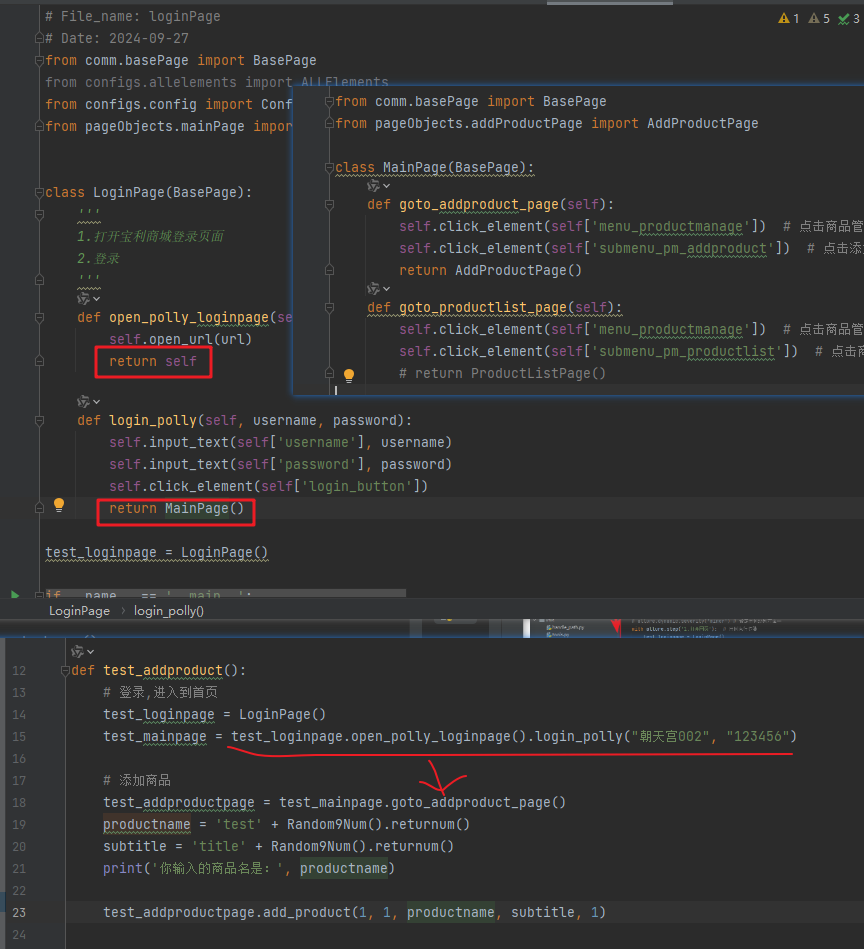
4.页面与页面之间的连接
比如登录页面类中的登录方法中,返回了 首页对象
首页类中,实现了,打开添加商品页面的方法。
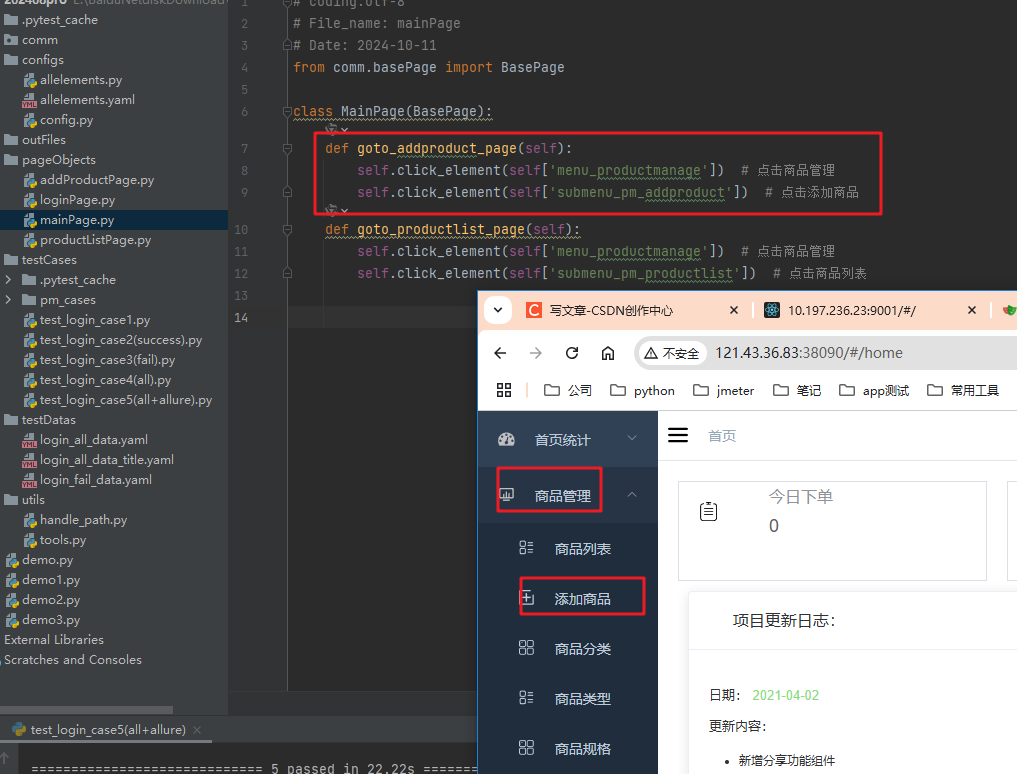
同样的,首页的方法中,跳增加商品页,也有return
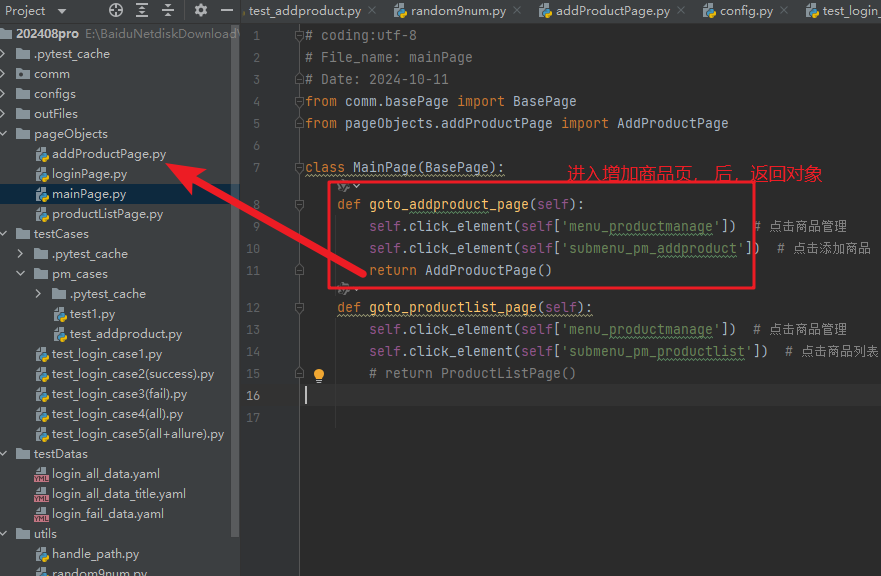
4. 新建testCases包,里面用pytest(略)
写用例,获取到pages包中的页面类对象,调页面类的方法。(略)
结合allure (略)
框架实现(案例-保利商城)
登录用例(元素定位写在login_data.yaml 里面的,单独搞的)
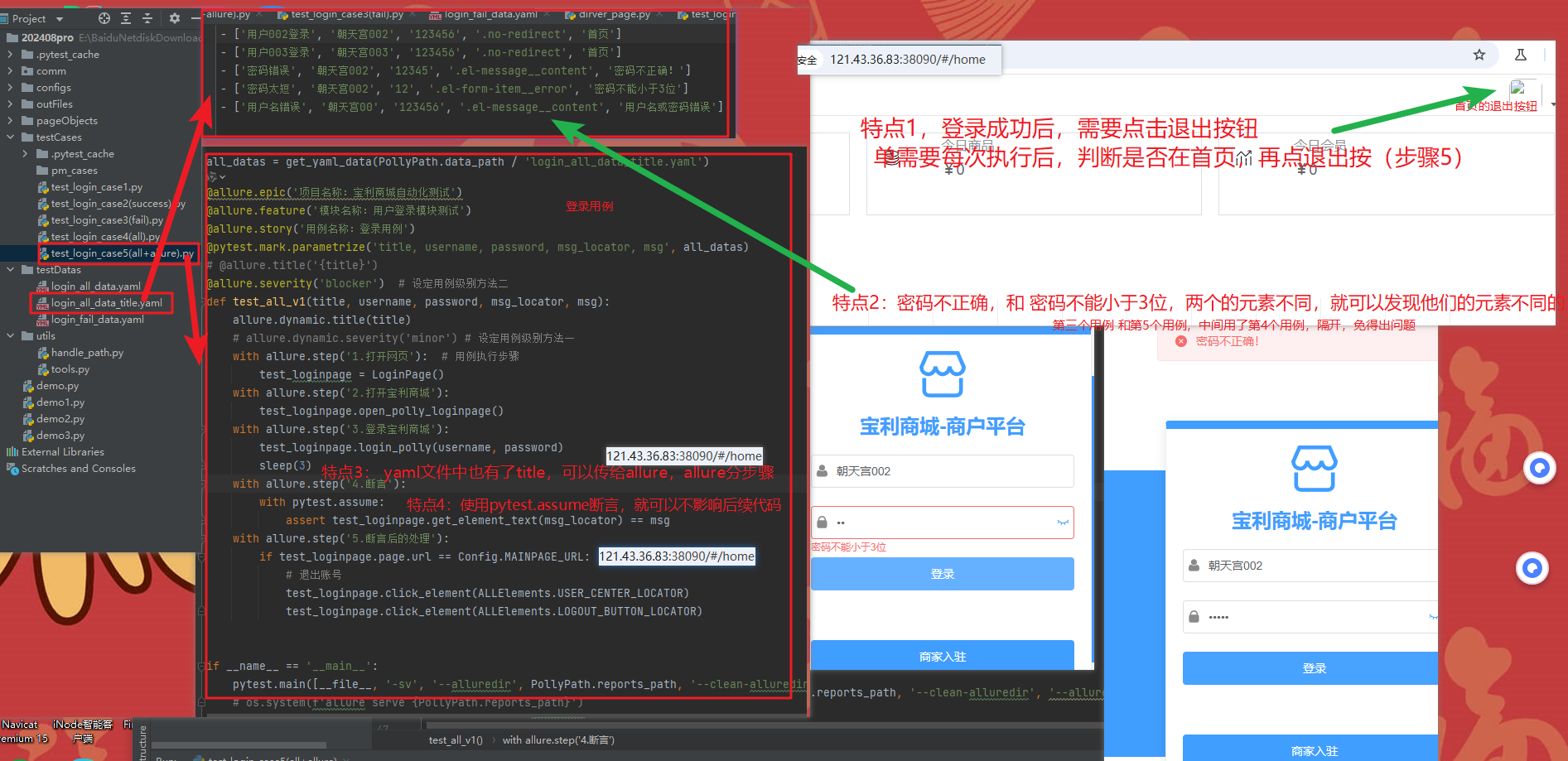
页面类中,跳转到另一个页面方法返回另一个页面的对象,可以实现方法的链式调用
如下是登录页,到首页, 还有一个是首页中两个方法也有返回(也在下图)
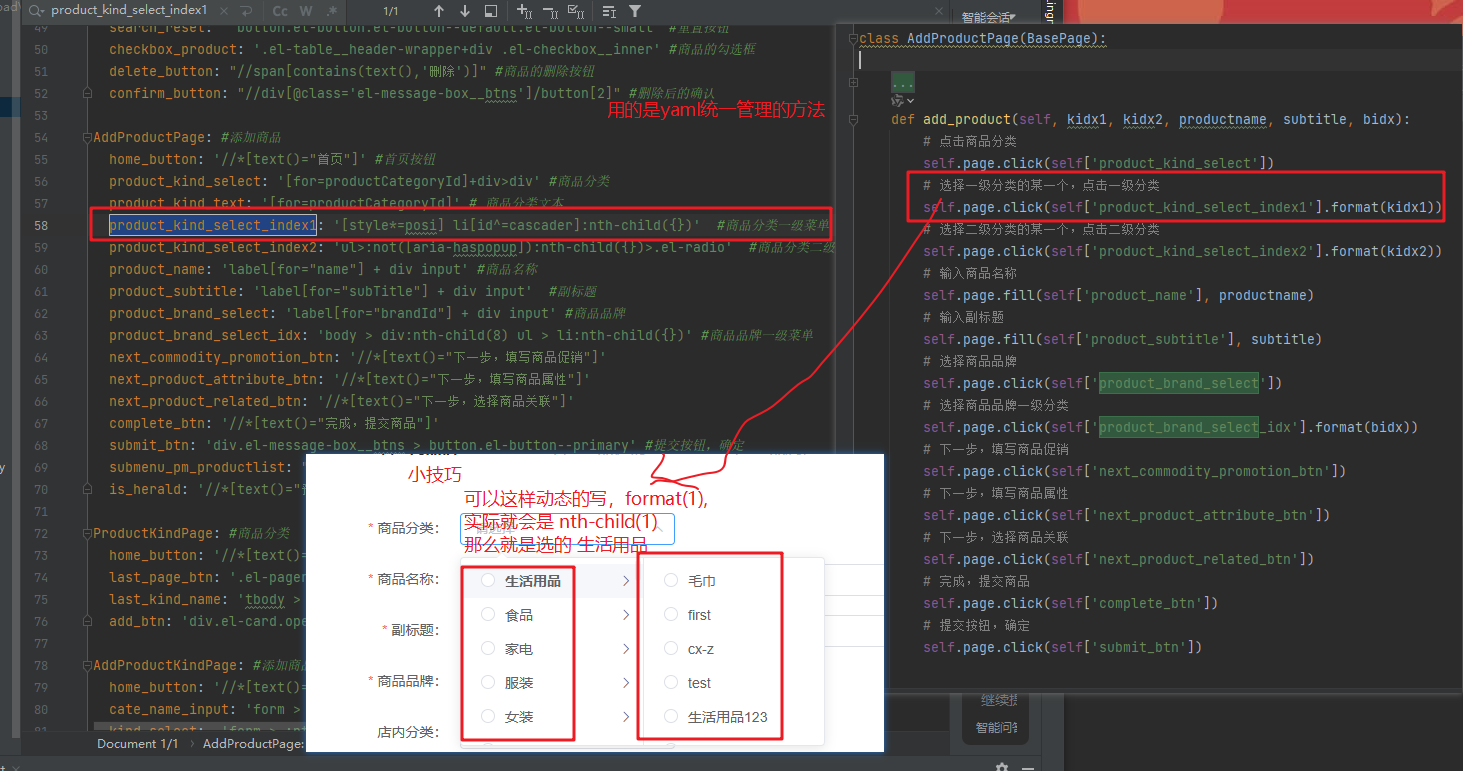
是用的统一管理元素的方式。 然后下拉选项的元素设置有个小技巧,如下。
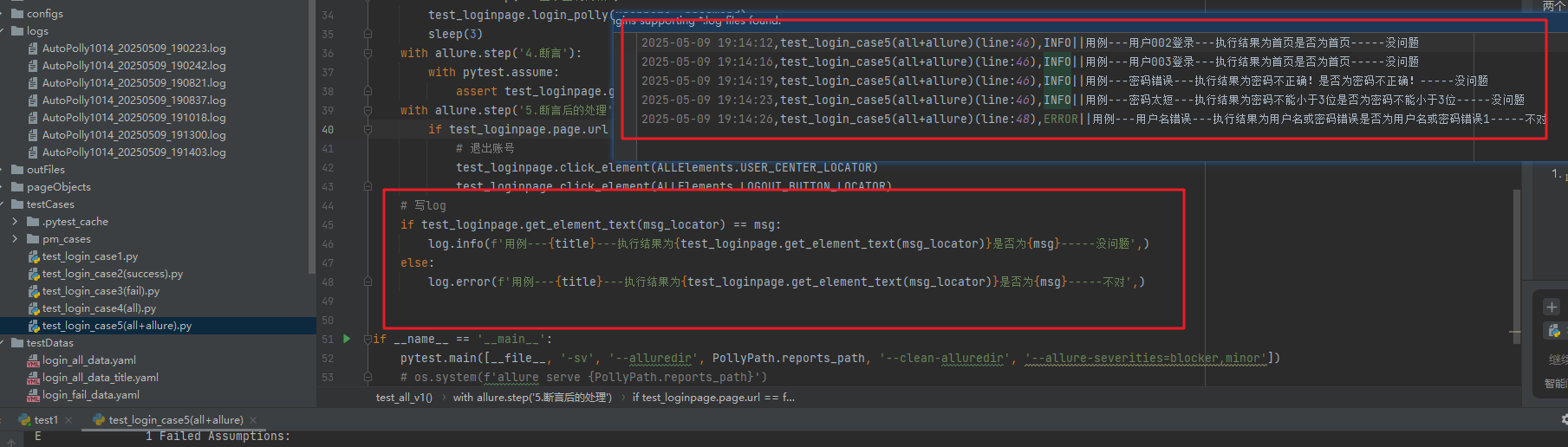
最后,项目搞了个日志。每次运行后,有日志文件
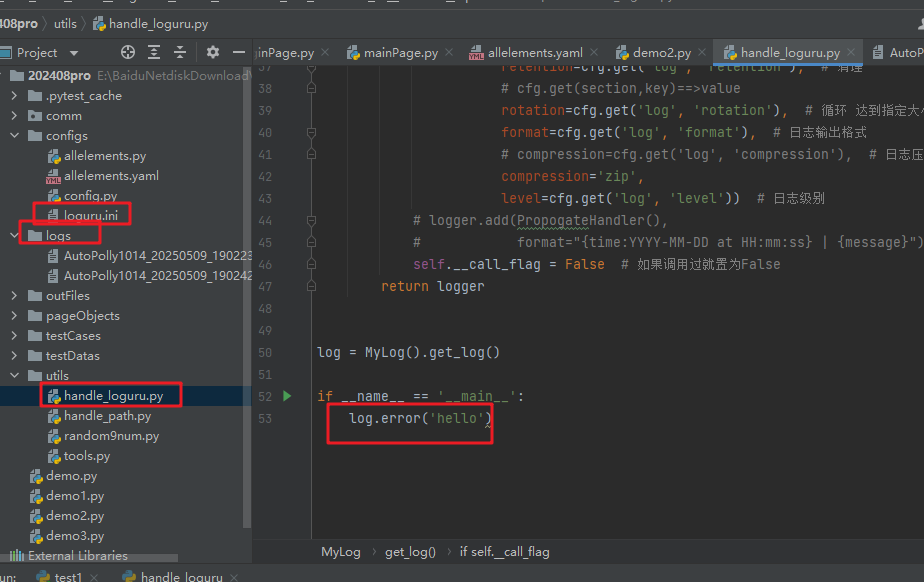
就可以实现,再关键地方记录日志,好追溯问题
最后代码,再gitee.需要联系,