探索表访问方法功能:顺序扫描分析
引言
在之前的文章中,我们讨论了 PostgreSQL 表访问方法 API 的基础知识以及堆元组(heap tuple)与元组表槽(Tuple Table Slot,简称 TTS)之间的区别。
本文将深入探讨 PostgreSQL 核心如何通过特定的 API 调用实现顺序扫描。
涉及的 API
为了实现顺序扫描,以下表访问方法 API 回调将会被调用:
- relation_size()
- slot_callbacks()
- scan_begin()
- scan_getnextslot()
- scan_end()
默认情况下,PostgreSQL 使用堆访问方法(heap access method),它通过以下方式实现上述 API:
- table_block_relation_size()
- heapam_slot_callbacks()
- heap_beginscan()
- heap_getnextslot()
- heap_endscan()
这些函数位于 src/backend/access/heap/heapam_handler.c 中。
基本工作流程
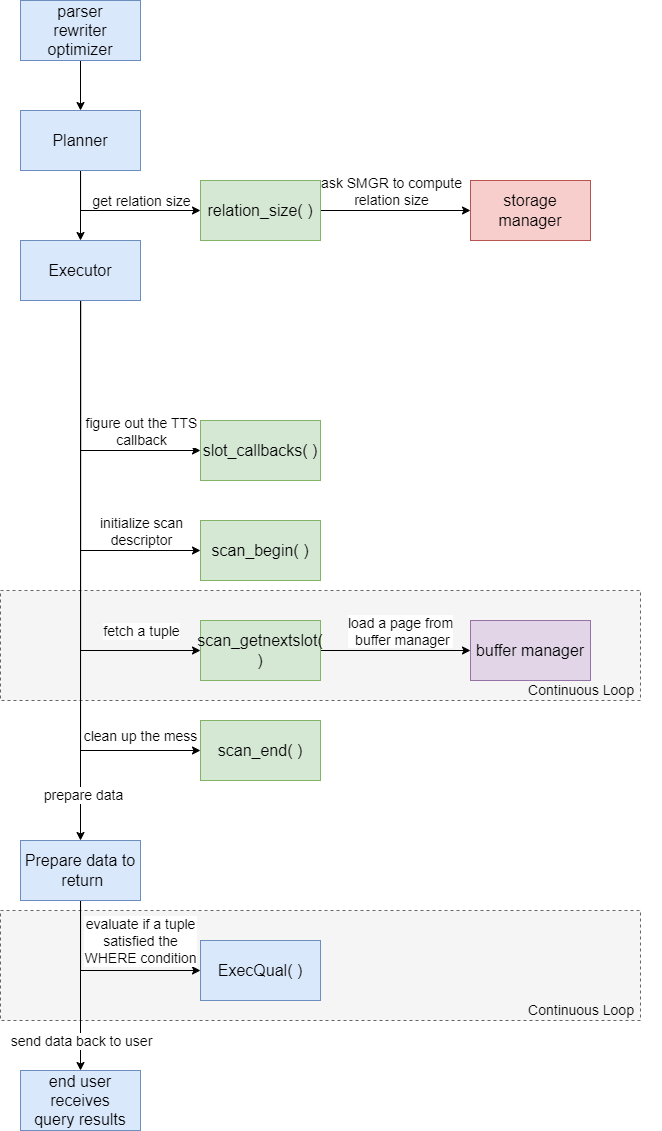
API 函数调用详解
table_block_relation_size(Relation rel, ForkNumber forkNumber)
这是查询规划阶段首先被调用的函数,旨在实际检查给定的 Relation rel 和 ForkNumber forkNumber 的大小。该函数将返回表的总块数(默认块大小为 8KB),以便调用方可以基于表的大小规划最佳查询策略。
什么是关系(relation)?
在大多数情况下,关系表示表(table)、索引(index)或视图(view)。在我们的案例中,它表示一个表,包含关于该表的重要信息,如数据库对象标识符(OID)、表空间、属性数量、其他标志等。
什么是分叉号(fork number)?
一个关系由多个分叉(fork)组成:
- MAIN_FORKNUM (0:存储用户数据)
- FSM_FORKNUM (1:存储空闲空间映射数据)
- VISIBILITY_FORKNUM (2:存储可见性数据)
- INIT_FORKNUM (3:用于重置 WAL 日志表)
heapam_slot_callbacks()
此函数被调用以返回适当的 TTS 操作,使执行器能够将堆元组转换为元组表槽(TTS)。对于堆访问方法,它使用考虑缓冲区管理的 TTS 回调:
const TupleTableSlotOps TTSOpsBufferHeapTuple = {.base_slot_size = sizeof(BufferHeapTupleTableSlot),.init = tts_buffer_heap_init,.release = tts_buffer_heap_release,.clear = tts_buffer_heap_clear,.getsomeattrs = tts_buffer_heap_getsomeattrs,.getsysattr = tts_buffer_heap_getsysattr,.materialize = tts_buffer_heap_materialize,.copyslot = tts_buffer_heap_copyslot,.get_heap_tuple = tts_buffer_heap_get_heap_tuple,/* 缓冲区堆元组表槽不能"拥有"最小元组 */.get_minimal_tuple = NULL,.copy_heap_tuple = tts_buffer_heap_copy_heap_tuple,.copy_minimal_tuple = tts_buffer_heap_copy_minimal_tuple
};
scan_begin() 和 scan_end()
在实际顺序扫描前后调用。scan_begin 负责初始化 HeapScanDesc 结构,该结构描述当前扫描状态,包括:当前块编号、待扫描块总数、扫描模式、快照等信息。其定义位于 src/include/backend/access/heapam.h。
而 scan_end() 则负责清理在 scan_begin() 中分配的 HeapScanDesc。
scan_getnextslot()
顺序扫描的核心。此函数负责从存储引擎检索元组。在 PostgreSQL 中,它会向缓冲区管理器(buffer manager)模块请求元组,该模块既可以从内存缓冲区读取元组,也可以从物理存储读取。
这正是通过此 API 创建自定义数据库存储引擎的可能性所在——可以完全从内存读写元组,形成内存数据库。
如果仍有数据需要扫描,此函数需要返回 true 以便执行器再次调用。当所有数据扫描完毕时,返回 false 表示扫描结束。

总结
这是 PostgreSQL 中顺序扫描的基本工作流程,它利用了表访问方法的 API。