【UEFN】用于可靠多模态情感分析的高效不确定性估计融合网络
abstract:
数字时代的快速发展极大地改变了社交媒体,导致情感表达更加多样化,公共话语日益复杂。因此,识别多模态数据中的关系变得越来越具有挑战性。目前大多数多模态情感分析(MSA)方法集中于将来自不同模态的数据合并到一个集成的特征表示中,以利用多模态数据的互补性来提高识别性能。然而,这些方法往往忽略了预测的可靠性。
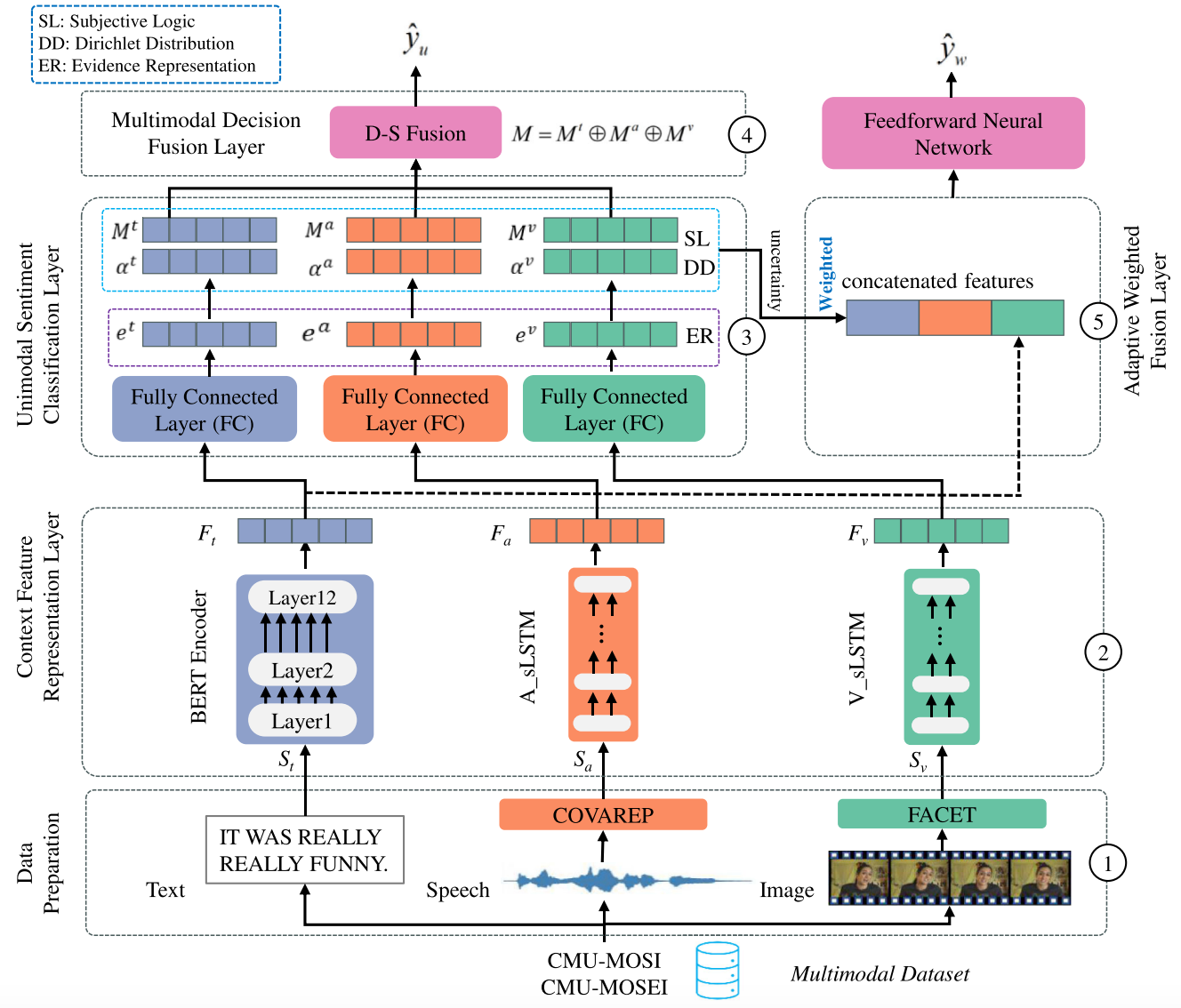
为了解决这个问题,我们提出了不确定性估计融合网络(UEFN),一个可靠的MSA方法的基础上不确定性估计。UEFN结合了Dirichlet分布和Dempster-Shafer证据理论(DSET)来预测文本,语音和图像模态的概率分布和不确定性,并在决策层融合预测。
具体来说,该方法首先表示文本,语音和图像模态的上下文特征分别。然后,它采用一个完全连接的神经网络将不同模态的特征转换为证据形式。随后,它通过狄利克雷分布参数化不同模态的证据,并估计每种模态的概率分布和不确定性。最后,我们使用DSET融合预测,获得情感分析结果和不确定性估计,称为多模态决策融合层(MDFL)。此外,基于主观逻辑理论产生的模态不确定性,我们计算特征权重,将其应用于相应的特征,连接加权特征,并将其送入前馈神经网络进行情感分类,形成自适应权重融合层(AWFL)。MDFL和AWFL都用于多任务训练。
实验比较表明,UEFN不仅取得了优异的性能,但也提供了不确定性估计沿着的预测,提高了结果的可靠性和可解释性。
introduction
数字时代的快速发展导致社交媒体平台(SMP)发生了重大变化,近年来产生了更广泛的情感表达和更复杂的公共话语[1]。SMP每天生成、存储和传播大量的社会信息。然而,这些信息往往缺乏有效的监督和管理,导致对社会和个人产生诸多负面影响[2]。因此,进行多模态情感分析(MSA)的社交媒体信息分析有非常重要的意义。然而,这一领域提出了相当大的挑战,如何准确地分析多模态数据源中潜在的情感偏见,并提供可靠的决策支持和分析结果,在此基础上,探索这些挑战的需要促使我们在这项研究中进行调查。
MSA可以通过整合来自多个来源的数据来捕捉人类情感的全面画面,从而实现更准确和细致入微的情感检测[3]。它与现实世界的场景更加紧密地联系在一起,特别是在社交媒体平台上,用户经常通过各种形式表达情感,包括文本,图像,语音和视频[4]。单峰情感分析通常依赖于单个数据源,这使得它容易受到单个模态内的不完整信息或噪声的影响,这可能导致降低了分类和识别精度。相比之下,MSA集成了不同模态的共同特征,并利用了跨模态信息的互补性。这种方法不仅提高了情感分类的准确性,而且更好地解决了社交媒体平台复杂多样的信息处理需求,实现了更有效的内容审核和增强的用户体验优化。
然而,MSA面临的挑战,如信号噪声和信号损失在输入阶段和次优的特征利用模态融合。早期的模型通常将语言,音频和视觉特征连接起来用于情感分析[5],但这些方法往往未能充分利用不同模态之间的相互关系。因此,Zeng等人[6]引入了一种基于特征的恢复动态交互网络,该网络在融合阶段动态地集成了文本,视觉和音频特征。
多年来,深度学习和深度强化学习[7,8]以指数速度发展,深度神经网络(DNN),递归神经网络(RNN),图形神经网络(GNN)和视觉变换器(ViT)等架构发挥着关键作用。这些技术使模型的开发能够从广泛的数据集中学习复杂的模式。基于变换器的模型[9-11]在捕获多模态数据的复杂性方面表现出显著的有效性,在自动特征提取方面表现出色,并有效地处理高维输入。尽管这些深度学习模型的性能令人印象深刻,但它们本质上缺乏量化预测中不确定性的能力,这使得决策变得困难,特别是当对模型输出的信心至关重要时。为了提高决策的可靠性,已经提出了几种基于深度学习的不确定性估计方法,包括贝叶斯神经网络(BNN)[13],集成方法[14],蒙特卡罗丢弃(MCD)[15]和选择性测试时间数据增强(TTA)[16]。不幸的是,这些方法仍然面临着重大挑战,例如推断后验分布时的高计算成本,确定性网络对训练数据的敏感性,以及单一模型的过度自信。此外,现有的MSA方法往往会产生不准确的预测噪声,模糊,或不完整的数据场景。
为了提高预测的可靠性,结合不确定性估计是必不可少的。在当前的MSA方法中,通常假设不同模态的值是统一的,或者为每个模态分配固定的权重[17]。这种方法假设,对于所有样本数据,每种模态的质量或重要性保持不变。然而,在实际情况中,不同模态的质量在样本之间可能会有很大差异。因此,模型必须相应地适应这些变化。一般来说,不仅要获得准确的分类结果,而且要评估这些预测的可靠性并了解其来源,这一点至关重要。这需要一个能够为总体预测结果和每个模态单独提供可靠的不确定性估计的模型,从而能够全面评估每个模态的质量。大多数现有的MSA方法通常依赖于DNN,需要大量的计算资源和大量的训练数据[18,19],导致在面对噪声或模糊输入时预测不可靠。MSA方法利用各种数据类型的互补优势来改进情感分析。特征级和决策级融合等技术结合了联合收割机的文本、听觉和视觉信息,从而提高了准确性和鲁棒性[20]。然而,这些技术没有考虑到来自不同模态的数据的不同质量,这可能导致在现实世界场景中的性能下降。这一差距强调了MSA中不确定性估计的必要性,MSA可以通过动态评估不同模态的质量来提供更可靠的预测。目前,大多数基于深度学习的分类任务在最终网络层使用Softmax函数来生成预测的概率分布,然后在模型训练期间使用交叉熵损失函数。然而,Moon等人[21]和货车阿默斯福特等人[22]进行的研究表明,在训练期间使用Softmax的最大输出作为预测结果可能会导致高估置信水平。即使预测不正确,置信水平仍然过高。因此,我们实现了一种基于Dempster-Shafer证据理论(DSET)的不确定性估计方法,以有效地估计预测结果的可靠性
为了融合多模态信息和估计不确定性,本文提出了不确定性估计融合网络(UEFN),一个有效的多模态框架,旨在通过纳入不确定性估计来增强情感分析。具体来说,我们的模型将来自不同模态的数据作为证据,并整合预测结果,而不是融合不同模态的特征。这一方法可以进行稳定可靠的不确定性估计,从而提高分类的可靠性。此外,我们集成了Dirichlet分布与DSET。狄利克雷分布模拟预测的概率分布,而DSET融合来自多模态数据的预测。对于每种形式(文本,语音和视频),我们进行独立的情感分析和不确定性估计,然后通过决策级融合策略来联合收割机组合最终的预测结果。该方法在融合过程中最大限度地减少了模型之间的干扰,同时充分利用了不同模态之间的互补信息。此外,基于主观逻辑理论(SLT)产生的模态不确定性,计算特征权重,将其应用于相应的特征,并将加权特征连接起来,将其输入前馈神经网络(FNN)进行情感分类,形成自适应权重融合层(AWFL)。然后,MDFL和AWFL都用于多任务训练。总体而言,提出的UEFN增强了MSA的可靠性以及稳健性以及可解释性,提供了显著的进步。
实验结果表明,UEFN具有上级分类精度,并能有效地评估预测结果的不确定性。我们的模型表现出强大的性能改进先进的模型,突出UEFN的有效性,提供可靠的和可解释的MSA。
(1)提出了一种有效的MSA不确定性估计融合网络(UEFN)。UEFN将不确定性估计集成到情感预测过程中,利用Dirichlet分布(DD)对预测结果的概率分布进行建模。通过结合主观逻辑理论(SLT),该网络使得能够跨个体模态(包括文本、语音和图像数据)进行有效的情感分析和不确定性估计。
(2)我们开发了一个层次化的多模态表示框架,该框架充分利用了来自社交媒体平台(SMP)多模态数据源的跨文本、语音和图像模态的互补特征。在决策层,我们应用Dempster-Shafer证据理论(DSET)来联合收割机来自每个模态的预测,从而产生总体预测。该方法提高了MSA任务结果的可靠性和可解释性。
(3)在主观逻辑理论(SLT)产生模态不确定性的基础上,计算特征权重,将其应用于相应的特征,并将加权后的特征连接起来,然后将其输入前馈神经网络(FNN)进行情感分类。多模态决策融合层和自适应权值融合层均用于多任务训练。
(4)在CMU-MOSI和CMU-MOSEI两个基准开放数据集上验证了UEFN的分类性能和可靠性。实验结果表明,UEFN具有优于现有模型的最优性能。
理论扫盲
Q:作者的创新是在模型模块还是理论部分?
A:都有,创新的模块主要是UEFN网络,对于不确定性的估计的意思就是说模型自己对“这句话是消极还是积极”的结论的把握有多大,具体而言,作者设计了层次化多模态表示框架,在底层分别提取文本、语音和图像的特征,在高层,通过“自适应权重融合层”动态调整不同模态的重要性,例如,如果图像模糊,则降低图像权重,更多依赖文本和语音;此外,作者还设计了多任务训练机制,同时训练模型完成情感分类和不确定性估计两个任务。
此外,作者还引入了新的数学理论:
Dirichlet分布(DD)-> 传统方法是直接输出情感概率,如积极70%,消极30%,但无法表达模型对这一结果的信心。本文用Dirichlet分布建模“概率的分布”,例如“模型对70%积极这一结果的信心是80%”。传统方法类似于直接报答案,本文在报答案之外附加信心值
主观逻辑理论(SLT)-> 将不同模态的预测结果转化为“信任度”和“不确定性”指标(例如,文本的信任度为0.8,不确定性为0.1;图像的信任度为0.6,不确定性为0.3)。帮助模型动态判断哪些模态更可靠(例如,图像质量差时,其不确定性指标会升高,权重自动降低)。
Dempster-Shafer证据理论(DSET):传统融合方法是简单的加权平均,例如文本权重0.4、语音0.3、图像0.3,本文选择用DSET将不同模态的预测视为“证据”,通过数学规则合并证据
related work
基于张量的融合方法
不确定性估计概述
类型 数据不确定性 模型不确定性 来源 数据本身的噪声或模糊性(如模糊图像) 模型训练不足、数据分布差异(如训练数据与测试数据不匹配) 别名 任意不确定性 认知不确定性 是否可减少 不可消除(数据固有属性) 可通过优化模型或增加数据缓解 例子 图像模糊导致识别困难 训练数据不足,模型未见过某些场景
不确定性估计的常用方法
方法
原理 优缺点 蒙特卡罗 Dropout 在推理时多次随机“关闭”神经元,通过多次预测结果的方差衡量不确定性。 ✅ 简单易用;
❌ 需多次计算,耗时较长。贝叶斯神经网络 将模型参数视为概率分布,通过采样估计不确定性。 ✅ 理论严谨;
❌ 计算复杂,难以大规模应用。Bootstrapping 训练多个模型(通过数据重采样),用预测差异衡量不确定性。 ✅ 稳定性高;
❌ 资源消耗大,训练多个模型成本高。高斯混合模型 (GMM) 假设预测服从混合高斯分布,直接拟合数据分布以分离两种不确定性(Choi等人方法)。 ✅ 计算高效,一次推理即可;
✅ 可区分数据与模型不确定性;
✅ 适合深度学习。
不确定性估计建立在确定性预测的基础上,确定性预测是根据一个实体的确定特征做出判断的。不确定性评估衡量这些预测的可靠性。例如,在面部识别中,为了验证两张图像是否描绘了同一个人,系统提取特征并通过预定义的指标测量相似性。如果相似性超过阈值(例如,95%),图像被认为是相同的-确定性预测。然而,在实践中,当图像质量不同(例如,模糊)时,确定性预测可能不可靠。在这里,信心分数补充相似分数来衡量预测的可信度。例如,95%的相似度和10%的置信度表明需要谨慎。
这突出表明,由于固有的“不确定性”,仅仅依赖于确定性预测的机器学习可能会产生不可靠的结果。因此,集成诸如信心分数或不确定程度之类的度量对于明智的决策是至关重要的。
预测模型通常有两种不确定性:数据不确定性和模型不确定性[24]。数据不确定性,通常被称为任意不确定性,源于数据中固有的噪声和误差,并且与样本量无关。模型不确定性或认知不确定性源于模型学习不足或训练数据与测试数据不匹配,从而导致模型参数的不确定性。这种不确定性可以通过改进模型和优化训练过程来减轻。
在人工智能(AI)领域,特别是在深度学习领域,不确定性估计是一个非常有趣的问题。许多应用需要伴随不确定性估计的模型预测,以评估预测的可信度和促进决策。在仅基于点估计的决策可能导致不良结果的情况下,这一点尤为重要。因此,研究人员正在积极开发方法来有效地估计预测中的不确定性。代表性的方法有蒙特卡罗dropout[15]、贝叶斯神经网络[25]、bootstrapping[26]和高斯混合模型[12]。这些方法采用不同的技术来捕捉数据或模型中固有的不确定性,为预测可靠性和辅助决策过程提供有价值的见解。Choi等人率先使用高斯混合模型(gmm)来估计深度学习任务[27]中的预测不确定性。该方法利用神经网络的拟合能力来学习GMM参数并相应地处理不确定性。GMM提供了一种有效而优雅的方法来估计预测不确定性。不像MC-Dropout,这需要重复预测,或引导模型产生多个预测,GMM显着减少了计算开销。此外,GMM可以分别评估数据中的任意不确定性和模型中的认知不确定性,使其成为不确定性估计的主要方法。
狄利克雷分布Dirichlet distribution
狄利克雷分布
Beta分布的高维扩展,用于建模多个概率值的联合分布,
Beta分布(二维特例):
,其中
描述的是单一事件,如硬币正面概率的不确定性。
Dirichlet分布(k维推广):
,描述k个互斥事件的概率分布,如文档属于k个主题的概率
在MSA中的应用:
- 建模不确定性,将情感分类结果视为概率分布,而非单一预测值
- 引入先验知识,通过参数a加入领域知识,如“社交媒体文本中消极情感更常见”
基于Dirichlet的情感分析模型
- Zadeh等人:用Dirichlet分布改进跨模态交互建模,解决文本、语音、图像模态间的动态权重分配问题。
- Zhang和Ma:结合LDA(主题模型)与深度学习,从文本中提取隐含主题(如“灾难”主题对应更高负面情绪概率),提升突发场景的情感识别鲁棒性。
- Ruz等人:通过Dirichlet先验处理数据不平衡(如消极样本稀少),增强模型对少数类情感的捕捉能力。
解决挑战:
- 数据稀疏,如某些情感类别样本不足 -> Dirichlet先验补偿缺失信息
- 多模态冲突,如文本积极但语音消极 -> 动态调整模态权重,高不确定性模态降权
Dempster-Shafer证据理论
以下是针对四张图片理论部分的逐层解析,结合多模态情感分析(MSA)背景,说明各理论的作用与关联:
一、狄利克雷分布(Dirichlet Distribution)
1. 核心概念
- 本质:Beta分布的高维扩展,用于建模多个概率值的联合分布(如文档中不同主题的占比)。
- 关键公式:
- Beta分布(二维特例):Beta(p∣α,β)=B(α,β)pα−1(1−p)β−1其中 B(α,β)=Γ(α+β)Γ(α)Γ(β),描述单一事件(如硬币正面概率)的不确定性。
- Dirichlet分布(k维推广):Dir(π∣α)=B(α)1i=1∏kπiαi−1描述k个互斥事件的概率分布(如文档属于k个主题的概率)。
2. 在MSA中的应用
- 作用:
- 建模不确定性:将情感分类结果(如积极、中性、消极)视为概率分布,而非单一预测值。
- 引入先验知识:通过参数 α 加入领域知识(如“社交媒体文本中消极情感更常见”)。
- 实例:
- 若模型预测某文本的“积极:0.6, 中性:0.3, 消极:0.1”,Dirichlet分布可量化这一预测的置信度(如模型对此结果的把握是80%还是30%)。
二、基于Dirichlet的情感分析模型
1. 研究案例
- Zadeh等人:用Dirichlet分布改进跨模态交互建模,解决文本、语音、图像模态间的动态权重分配问题。
- Zhang和Ma:结合LDA(主题模型)与深度学习,从文本中提取隐含主题(如“灾难”主题对应更高负面情绪概率),提升突发场景的情感识别鲁棒性。
- Ruz等人:通过Dirichlet先验处理数据不平衡(如消极样本稀少),增强模型对少数类情感的捕捉能力。
2. 优势总结
- 解决挑战:
- 数据稀疏(如某些情感类别样本不足)→ Dirichlet先验补偿缺失信息。
- 多模态冲突(如文本积极但语音消极)→ 动态调整模态权重(高不确定性模态降权)。
三、Dempster-Shafer证据理论(DSET)
1. 核心概念
- 基本元素:
- 识别框架(Θ):所有可能假设的集合(如情感类别{积极, 中性, 消极})。
- 基本概率赋值(BPA):对每个子集的置信度分配(如“积极或中性”置信度0.7)。
- 组合规则:合并多源证据(如文本、语音、图像预测),处理冲突与不确定性。
2. 在MSA中的应用
- 案例:
- Wang和Qin:用DSET融合文本与语音特征,冲突时自动降低低质量模态权重(如噪声语音)。
- Xie等人(TMSON):引入序数关系(如“积极>中性>消极”的强度顺序),DSET处理模态贡献差异。
- 优势:
- 允许“不知道”(不确定区间)的存在,避免强行决策导致错误。
四、主观逻辑理论(SLT)
1. 核心概念
- 意见空间:将证据转化为三元组(相信 b、不相信 d、不确定 u),满足 b+d+u=1。
- 公式:
其中 r 为支持证据数,s 为反对证据数(如100次检测中90次支持“积极”,则 b=0.89,d=0.09,u=0.02)。
- Beta分布映射:用 Beta(θ ∣ r+1,s+1) 表示意见的可信度密度。
2. 在MSA中的应用
- 案例:
- Esposito等人:在社交网络中评估用户可信度,SLT聚合多源评价(如评论、点赞、举报),输出“该用户可信度为0.8,不确定度为0.1”。
- 优势:
- 显式量化不确定性,支持动态信任更新(如新证据出现时调整 r 和 s)。
五、理论关联与MSA中的协同作用
- Dirichlet分布 → 建模单模态预测的不确定性(如文本情感概率分布)。
- DSET → 融合多模态证据,解决冲突与权重分配(如文本与图像不一致时决策)。
- SLT → 将融合结果转化为可解释的信任度量(如“最终情感为积极,置信度85%,不确定性5%”)。
实例流程:
- 输入:用户发布的图文视频(多模态数据)。
- 单模态处理:
- 文本 → Dirichlet输出“积极:0.7, 不确定度0.2”。
- 图像 → Dirichlet输出“消极:0.6, 不确定度0.3”。
- DSET融合:根据不确定度加权,组合后得到“积极:0.65, 冲突度0.1”。
- SLT解释:最终意见为“相信积极(0.65),不确定(0.1)”,建议人工复核。
狄利克雷分布是beta分布在高维情况下的一种扩展,通常用于多项分布的参数建模。它是多项式分布的共轭先验分布,在贝叶斯统计和机器学习中有着广泛的应用。β分布是定义在区间[0,1]内的连续概率分布,由两个参数α和β表示。这两个变量以随机变量的指数形式出现,控制着分布的变化,通俗地理解为概率的概率分布。其概率密度函数如(2)所示:
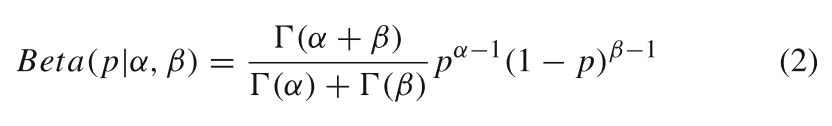
狄利克雷分布的参数是一个k维向量α∈[α1,…, αK],其概率密度函数和期望如(3)所示。
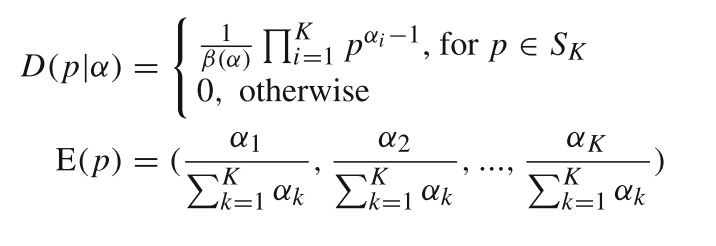
近年来,Dirichlet分布已成为自然语言处理(NLP)和机器学习任务的重要工具,因为它能够建模不确定性和纳入先验知识。
Zadeh等人([23])引入了一种集成了Dirichlet分布的TFN,以提高跨模态交互的表示和情感检测的准确性。
Zhang和Ma[28]提出了一种基于albert的textcnn - hat混合模型,该模型通过潜在狄利克雷分配(latent Dirichlet allocation, LDA)增强了主题知识,通过结合上下文语义关系来改进MSA,从而在突发性灾难场景中获得更好的性能。
Ruz等人采用了Dirichlet先验的贝叶斯方法来提高不平衡数据集上的情感分类性能,展示了对少数类情感表达的改进处理。
Najar和Bouguila[30]提出了一种平滑Dirichlet多项式(SDM)分布及其混合模型来改进情绪识别任务,在社交媒体平台(SMPs)上的抑郁检测和疼痛估计等领域取得了优异的表现。
基于dirichlet的模型有助于更稳健和细致的情感分析,解决诸如数据稀疏、不平衡和多模态信息融合等挑战。多模态情感分类中的dirichlet分布可以用来建模和推断每个模态下的类别分布,从而帮助我们理解不同模态之间的相关性,从而准确地对情感进行分类。
证据理论和主观逻辑理论
Dempster-shafer证据理论
Dempster-Shafer证据理论[31]最初由Dempster教授提出,后来由他的学生Shafer发展,用于不确定性建模。该理论将贝叶斯理论扩展到主观概率,主要由识别框架、基本概率赋值(BPA)、信念函数、似然函数、置信区间和Dempster组合规则组成。
多模态情感分析旨在通过整合文本、音频和视觉信号等多种数据模态来理解和解释人类情感。传统方法通常依赖于概率框架或机器学习技术,这些方法在处理多模态数据中固有的不确定性和冲突信息方面面临挑战。Dempster-Shafer (D-S)理论提供了一个强大的数学框架,可以将不同来源的证据结合起来,同时管理不确定性和冲突,使其成为应对这些挑战的有力工具。
Wang和Qin b[32]提出了一种应用D-S理论融合文本和音频特征的情感分析方法。与传统的融合技术相比,该方法有效地解决了不同模式之间的不确定性和冲突,从而提高了情感预测的准确性。Xie等人介绍了一个可信的多模态情绪序数网络(TMSON),该网络利用D-S理论来管理噪声、语义歧义和不同的情态贡献,以改进情绪分析,考虑情绪类别内的序数关系。Tong等人[34]提出了一种证据深度学习分类器,该分类器将D-S理论与卷积神经网络相结合,通过将高维特征聚合成质量函数并进行集值分类来提高分类精度和谨慎决策
主观逻辑理论
Jsang[35]提出的主观逻辑理论是对Dempster-Shafer理论的扩展,将证据空间和意见空间的概念结合起来描述证据并量化信任水平。它建立了证据空间和意见空间之间的映射关系来表示信任的形成过程。在主观逻辑理论(SLT)中,基本单位是“意见”,它由“相信”、“不相信”、“不确定”和“基本比率”组成。基于服从Beta分布的二项事件,Jsang提出了一个由其正事件数r和负事件数s表示的概率确定性密度函数,可表示为:
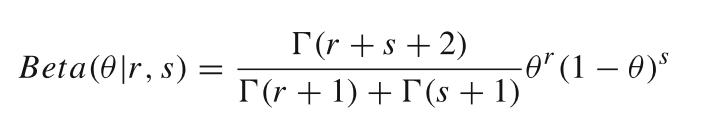
式中,![]() 为Gamma函数。
为Gamma函数。
意见空间(W)由相信(b)、不相信(d)和不确定(u)组成,可以表示为W = {b, d, u}。
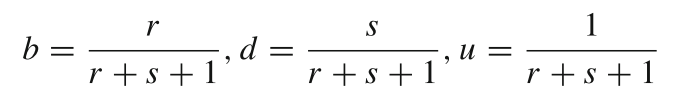
Esposito等人提出了一种综合的方法,使用SLT来解决在线社交网络中评估用户可信度的挑战,提供了一套更大的标准和鲁棒的聚合方法,以有效地处理计算分数中的不确定性和模糊性,从而提高了信任估计的准确性和精度。
未完,待整理