二叉树与优先级队列
1.树
树是由n个数据构成的非线性结构,它是根朝上,叶朝下。
注意:树形结构之中,子树之间不能连接,不然就不构成树形结构
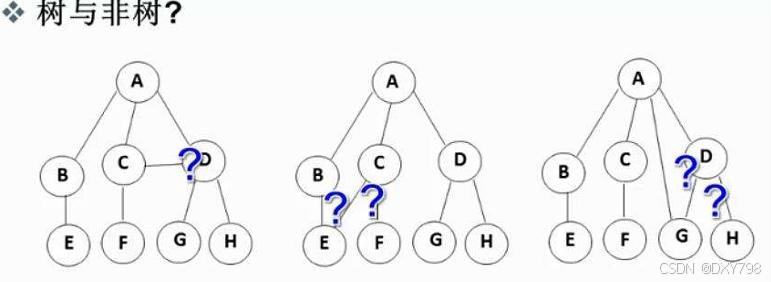
1.子树之间没有交集
2.除了根节点以外,每一个节点有且只有一个父亲节点
3.一个n个节点的树,有n-1条边
1.1树的一些概念
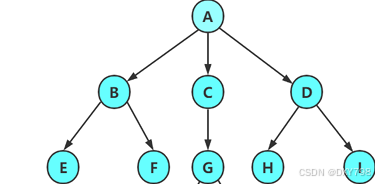
结点的度:一个结点含有子树的个数称为该结点的度; 如上图:A的度为6
树的度:一棵树中,所有结点度的最大值称为树的度; 如上图:树的度为6
叶子结点或终端结点:度为0的结点称为叶结点; 如上图:B、C、H、I...等节点为叶结点 双亲结点或父结点:若一个结点含有子结点,则这个结点称为其子结点的父结点; 如上图:A是B的父结点
孩子结点或子结点:一个结点含有的子树的根结点称为该结点的子结点; 如上图:B是A的孩子结点
根结点:一棵树中,没有双亲结点的结点;如上图:A
结点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推
树的高度或深度:树中结点的最大层次; 如上图:树的高度为4 树的以下概念只需了解,
非终端结点或分支结点:度不为0的结点; 如上图:D、E、F、G...等节点为分支结点
兄弟结点:具有相同父结点的结点互称为兄弟结点; 如上图:B、C是兄弟结点
堂兄弟结点:双亲在同一层的结点互为堂兄弟;如上图:H、I互为兄弟结点
结点的祖先:从根到该结点所经分支上的所有结点;如上图:A是所有结点的祖先
子孙:以某结点为根的子树中任一结点都称为该结点的子孙。如上图:所有结点都是A的子孙
森林:由m(m>=0)棵互不相交的树组成的集合称为森林
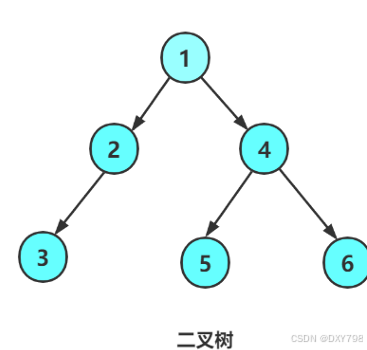
2.二叉树
2.1概念
一棵二叉树的节点是有限集合
对于任意的二叉树,都是由下列情况组合而成
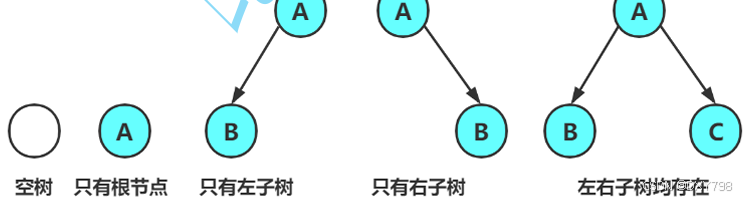
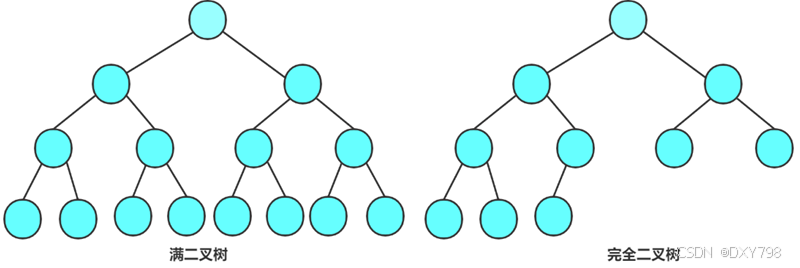
2.2两种特殊的二叉树
1.满二叉树:一棵二叉树树,每一层的节点数都到达了最大值,那么这就是满二叉树。也就是说如果一棵二叉树是k层,那么这棵树的节点树,且结点总数是-1,则它就是满二叉树。
2.完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n 个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从0至n-1的结点一一对应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。
2.3二叉树的性质
1. 若规定根结点的层数为1,则一棵非空二叉树的第i层上最多有(i>0)个结点
2. 若规定只有根结点的二叉树的深度为1,则深度为K的二叉树的最大结点数是-1(k>=0)
3. 对任何一棵二叉树, 如果其叶结点个数为 n0, 度为2的非叶结点个数为 n2,则有n0=n2+1
4. 具有n个结点的完全二叉树的深度k为上取整
5. 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的顺序对所有节点从0开始编号,则对于序号为i 的结点有:
若i>0,双亲序号:(i-1)/2;i=0,i为根结点编号,无双亲结点
若2i+1<n 左孩子序号:2i+1,否则没有左孩子
若2i+2<n 右孩子序号:2i+1,否则没有右孩子
2.4二叉树的存储
二叉树的存储结构分为:顺序存储和类似于链表的链式存储。
二叉树的链式存储是通过一个一个的节点引用起来的,常见的表示方式有二叉和三叉表示方式,具体如下
//孩子表示法
class Node {int val; //用于储存数据Node left; //表示左孩子,通常为以左子树为根节点的二叉树Node right; //表示右孩子,通常为右子树为根节点的二叉树
}
// 孩子双亲表示法
class Node {int val; // 数据域Node left; // 左孩子的引用,常常代表左孩子为根的整棵左子树Node right; // 右孩子的引用,常常代表右孩子为根的整棵右子树Node parent; // 当前节点的根节点
}2.2二叉树的基本操作
存储方式是孩子表示方法
BinaryTree类
import java.util.LinkedList;
import java.util.Queue;
import java.util.Stack;public class BinaryTree {public static class TreeNode {public int val;public TreeNode left;//储存左子树public TreeNode rigth;//储存右子树public TreeNode(int val) {this.val = val;}@Overridepublic String toString() {return "TreeNode{" +"val=" + val +'}';}}//创建一个二叉树public TreeNode createbinarytree() {TreeNode A = new TreeNode(1);TreeNode B = new TreeNode(2);TreeNode C = new TreeNode(3);TreeNode D = new TreeNode(4);TreeNode E = new TreeNode(5);TreeNode F = new TreeNode(6);TreeNode G = new TreeNode(7);TreeNode H = new TreeNode(8);//连接数的结构A.left = B;A.rigth = C;B.left = D;B.rigth = E;C.left = F;C.rigth = G;E.rigth = H;return A;}//先实现三种遍历方法// 前序遍历public void preOrder(TreeNode root) {//NLR:前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点--->根的左子树--->根的右子树。//递归的结束条件if (root == null) {return;}System.out.print(" " + root.val);preOrder(root.left);preOrder(root.rigth);//走到结尾这个循环结束}//不使用递归的的方法实现前序遍历public void preOrder1(TreeNode root){//借用栈来实现if(root==null){return ;}Stack<TreeNode> stack=new Stack<>();TreeNode cur=root;while(cur!=null||!stack.isEmpty()){while(cur!=null){stack.push(cur);System.out.print(cur.val+" ");cur=cur.left;}TreeNode top=stack.pop();cur=top.rigth;}}// 中序遍历public void inOrder(TreeNode root) {//LNR:中序遍历(Inorder Traversal)——根的左子树--->根节点--->根的右子树。if (root == null) {return;}inOrder(root.left);System.out.print(" " + root.val);inOrder(root.rigth);}//不使用递归的的方法实现中序遍历public void inOrder1(TreeNode root){//借用栈来实现iif(root==null){return ;}Stack<TreeNode> stack=new Stack<>();TreeNode cur=root;while(cur!=null||!stack.isEmpty()){while(cur!=null){stack.push(cur);cur=cur.left;}TreeNode top=stack.pop();System.out.print(top.val+" ");cur=top.rigth;}}// 后序遍历public void postOrder(TreeNode root) {//LRN:后序遍历(Postorder Traversal)——根的左子树--->根的右子树--->根节点。if (root == null) {return;}postOrder(root.left);postOrder(root.rigth);System.out.print(" " + root.val);}//使用不递归的方法使用后序遍历public void postOrder1(TreeNode root){//借用栈来实现if(root==null){return ;}Stack<TreeNode> stack=new Stack<>();TreeNode cur=root;TreeNode prve=null;while(cur!=null||!stack.isEmpty()){while(cur!=null){stack.push(cur);cur=cur.left;}TreeNode top=stack.peek();if(top==null||top.rigth==prve){System.out.println(top.val+" ");prve= stack.pop();}else{cur=top.rigth;}}}//获取数中节点个数public int nodesize;//第一种遍历式获取public void Nodesize1(TreeNode root) {//采用前序遍历if (root == null) {return;}//遇见节点将打印改成nodesize++nodesize++;Nodesize1(root.left);Nodesize1(root.rigth);}//第二种获取节点个数方法//左子树节点个数+右子树节点个数+根节点个数public int Nodesize2(TreeNode root) {if (root == null) {return 0;}return Nodesize2(root.left) + Nodesize2(root.rigth) + 1;}// 获取叶子节点的个数//依旧两种方法//第一遍种历二叉树public int getLeafNodeCount;public void getLeafNodeCount1(TreeNode root) {if (root == null) {return;}if (root.left == null && root.rigth == null) {getLeafNodeCount++;}getLeafNodeCount1(root.left);getLeafNodeCount1(root.rigth);}//第二种获取叶子节点个数//左子树叶子+右子树叶子节点个数public int getGetLeafNodeCount2(TreeNode root) {if (root == null) {return 0;}if (root.left == null && root.rigth == null) {return 1;}return getGetLeafNodeCount2(root.left) + getGetLeafNodeCount2(root.rigth);}// 获取第K层节点的个数public int getKLevelNodeCount(TreeNode root, int k) {//统计k层的节点个数,先找到第k-1层if (k == 1) {if (root == null) {return 0;} else {return 1;}}return getKLevelNodeCount(root.left, k - 1) + getKLevelNodeCount(root.rigth, k - 1);}// 获取二叉树的高度public int getHeight(TreeNode root) {//二叉树的高度等于左子树高度和右子树高度的最大值if(root==null) {return 0;}return getHeight(root.left)>getHeight(root.rigth)?getHeight(root.left)+1:getHeight(root.rigth)+1;}// 检测值为value的元素是否存在public TreeNode find(TreeNode root, int val){if(root.val==val){return root;}if(root.left!=null){TreeNode leftT=find(root.left,val);if(leftT!=null){return leftT;}}if(root.rigth!=null){TreeNode rigthT =find(root.rigth,val);if(rigthT!=null){return rigthT;}}return null;}//层序遍历public void levelOrder(TreeNode root){if(root==null){return;}//创建一个队列Queue<TreeNode> queue=new LinkedList<>();queue.offer(root);TreeNode cur=root;while(!queue.isEmpty()){//先将队列元素弹出cur=queue.poll();System.out.print(cur.val+" ");if(cur.left!=null){queue.offer(cur.left);}if(cur.rigth!=null){queue.offer(cur.rigth);}}System.out.println();}// 判断一棵树是不是完全二叉树public boolean isCompleteTree(TreeNode root){//完全二叉树从左到右依次填满Queue<TreeNode> queue=new LinkedList<>();TreeNode cur=root;queue.offer(cur);while(queue.peek()!=null){cur=queue.poll();queue.offer(cur.left);queue.offer(cur.rigth);}while(!queue.isEmpty()){if(queue.poll()!=null){return false;}}return true;}public static void main(String[] args) {}
}Test类
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;public class Test {public static void main(String[] args) {//调用创建二叉树BinaryTree binaryTree=new BinaryTree();//调用类中2的成员变量BinaryTree.TreeNode root=binaryTree.createbinarytree();//测试前序遍历打印binaryTree.preOrder(root);System.out.println();// //测试前序遍历打印1binaryTree.preOrder1(root);System.out.println();System.out.println("==============================");System.out.println();//测试中序遍历binaryTree.inOrder(root);System.out.println();//测试中序遍历的非递归方法binaryTree.inOrder1(root);System.out.println("===============================");System.out.println();//测试后序遍历binaryTree.postOrder(root);System.out.println();//测试后续遍历的非递归方法binaryTree.postOrder1(root);System.out.println("=========================");System.out.println();//打印节点个数binaryTree.Nodesize1(root);System.out.println("二叉树结点个数:"+binaryTree.nodesize);//测试第二种打印节点个数方法System.out.println("二叉树结点个数:"+binaryTree.Nodesize2(root));//测试第一种叶子节点个数binaryTree.getLeafNodeCount1(root);System.out.println("二叉树叶子节点个数:"+binaryTree.getLeafNodeCount);//测试第二种叶子节点个数System.out.println("二叉树叶子节点个数:"+binaryTree.getGetLeafNodeCount2(root));//测试统计第k层的节点个数System.out.println("第1层的节点个数为"+binaryTree.getKLevelNodeCount(root, 1));System.out.println("第2层的节点个数为"+binaryTree.getKLevelNodeCount(root, 2));System.out.println("第3层的节点个数为"+binaryTree.getKLevelNodeCount(root, 3));System.out.println("第4层的节点个数为"+binaryTree.getKLevelNodeCount(root, 4));//测试计算二叉树的高度System.out.println("二叉树的高度为:"+binaryTree.getHeight(root));//测试二叉树的是否存在的元素List<List<Integer>> llist=new ArrayList<List<Integer>>();List<Integer> list1=new ArrayList<>();llist.add(list1);Queue<Integer> queue=new LinkedList<>();queue.offer(1);System.out.println(queue.poll());System.out.println("元素1存在节点"+binaryTree.find(root, 1)+"中");System.out.println("元素4存在节点"+binaryTree.find(root, 4)+"中");System.out.println("元素8存在节点"+binaryTree.find(root, 8)+"中");System.out.println("元素7存在节点"+binaryTree.find(root, 7)+"中");//测试二叉树的层序遍历binaryTree.levelOrder(root);//判断二叉树是否是完全二叉树System.out.println("判断这棵树是否是完全二叉树 "+binaryTree.isCompleteTree(root));}
}
3.优先队列(PriorityQueue)
3.1堆的性质
堆逻辑上是一颗完全二叉树,物理上是存储在数组中
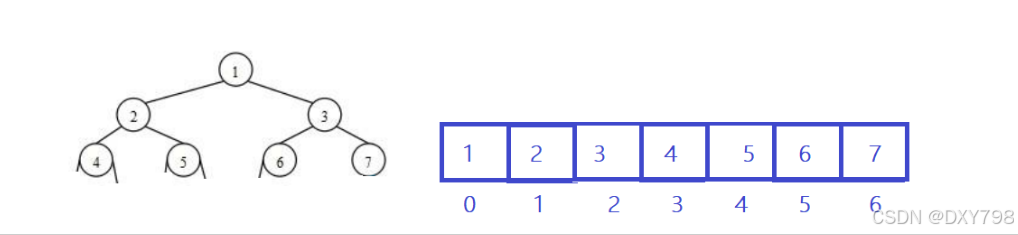
总结:一颗完全二叉树以层序遍历方式放入数组中存储,这种方式的主要用法就是堆的表示。
关于堆下标位置的计算
如果已知父亲(parent) 的下标,
则: 左孩子(left) 下标 = 2 * parent + 1;
右孩子(right) 下标 = 2 * parent + 2;
已知孩子(不区分左右)(child)下标,
则: 双亲(parent) 下标 = (child - 1) / 2;
3.2堆的分类
大堆:根节点大于左右两个子节点的完全二叉树 (父亲节点大于其子节点),叫做大堆,或者大根堆,或者最大堆 。
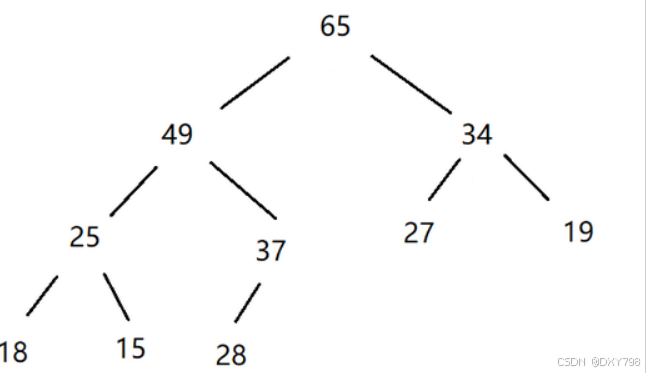
小堆:根节点小于左右两个子节点的完全二叉树叫 小堆(父亲节点小于其子节点),或者小根堆,或者最小堆。
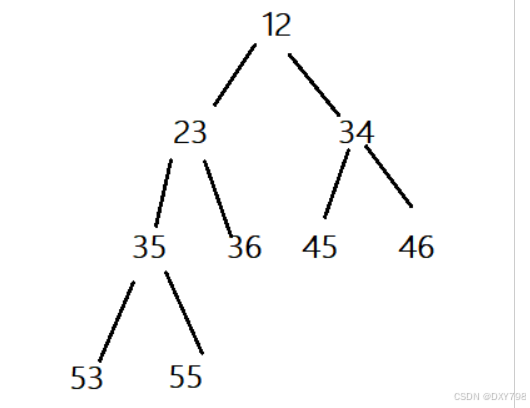
3.3堆的底层代码实现
创建小根堆
创建大根堆
向上调整
现在有一个堆,我们需要在堆的末尾插入数据,再对其进行调整,使其仍然保持堆的结构,这就是向上调整。
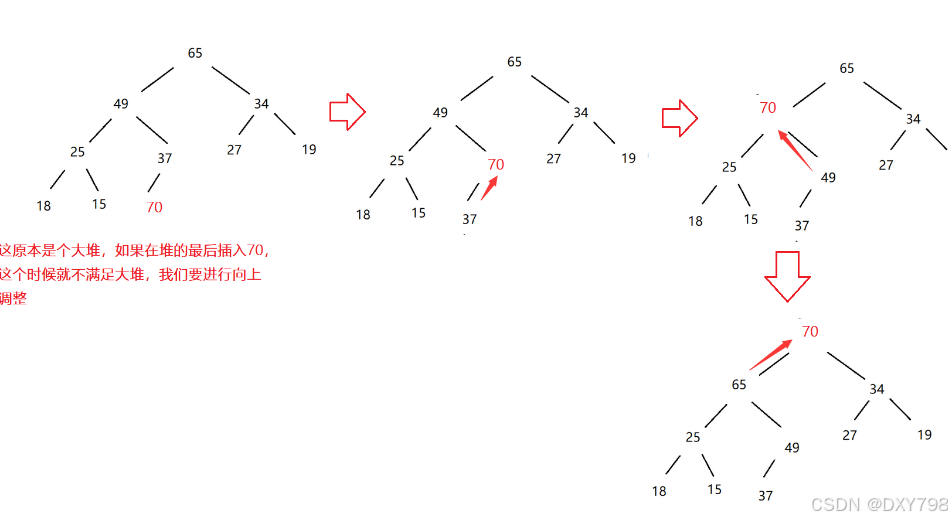
以大堆为例:
向下调整
堆的删除和添加
PriorityQueue类
import java.lang.reflect.Array;
import java.util.Arrays;public class PriorityQueue {public int[] elem;public int usedsize;public PriorityQueue() {this.elem=new int[10];}public void initelem(int [] array){for(int i=0;i<array.length;i++){this.elem[i]=array[i];usedsize++;}}public void elempeek(){for(int i=0;i<this.usedsize;i++){System.out.print(elem[i]+" ");}}//创建小根堆public void Smallrootpiles(){//小根堆的节点数要大于子树//第一步先确定有多少个树,利用最后一个节点来找到父亲节点for(int parent=(usedsize-1-1)/2;parent>=0;parent--){//也是一样采用向下调整的方法siftDown2(parent,usedsize);}}public void siftDown2(int parent,int usedsize){//parent:代表调整子树的起始位置//usedsize:判断子树是否还需要调整//1.根据父亲节点,找到左子树孩子节点int child=parent*2+1;//2.找到孩子之间的最小值while(child<usedsize){if(child+1<usedsize&&elem[child]>elem[child+1]){child++;}if(elem[child]<elem[parent]){int num=elem[parent];elem[parent]=elem[child];elem[child]=num;parent=child;child=child*2+1;}else{break;}}}//创建大根堆public void createhead(){//大根堆的节点数要大于子树//第一步先确定有多少个树,利用最后一个节点来找到父亲节点for(int parent=(usedsize-1-1)/2;parent>=0;parent--){//采用向下调整siftDown1(parent,usedsize);}}//parent:代表调整子树的起始位置//usedsize:判断子树是否还需要调整public void siftDown1(int parent,int usedsize){//根据父亲节点找到左子树节点int child=parent*2+1;while(child<usedsize){if(child+1<usedsize&&elem[child]<elem[child+1]){child++;}if(elem[child]>elem[parent]){int num=elem[parent];elem[parent]=elem[child];elem[child]=num;
// elem[child]=elem[child]^elem[parent];
// elem[parent]=elem[child]^elem[parent];
// elem[child]=elem[child]^elem[child];parent=child;child=child*2+1;}else{break;}}}//向堆中增加元素public void push(int val) {//先进行判满处理if (isFull()) {//进行扩容elem = Arrays.copyOf(elem, elem.length * 2);}elem[usedsize] = val;usedsize++;siftUp(usedsize - 1);}//向上调整public void siftUp(int child) {//孩子节点找到父亲节点int parent=(child-1)/2;//向上调整while(parent>=0){if(elem[child]>elem[parent]){int num=elem[parent];elem[parent]=elem[child];elem[child]=num;child=parent;parent=(parent-1)/2;}else{break;}}}public boolean isFull(){if(usedsize==this.elem.length){return true;}return false;}//删除堆的元素public int poll(){if(isEmpty()){return -1;}int val=elem[0];//交换0位置和最后一个节点位置elem[0]=elem[usedsize-1];elem[usedsize-1]=val;//对0节点位置进行向下调整siftDown1(0,usedsize-1);usedsize--;return val;}//判段是否为空public boolean isEmpty(){if (usedsize==0){return true;}return false;}//对节点进行排从小到大排序(再节点本身上排序)public void headsort(){//先对数据进行建大堆this.createhead();int end=usedsize-1;while(end>0){int num=elem[0];elem[0]=elem[end];elem[end]=num;siftDown1(0,end);end--;}}public static void main(String[] args) {}
}
Test类
public class Test {public static void main(String[] args) {//对队进行初始化PriorityQueue priorityQueue=new PriorityQueue();int[] array={ 27,15,19,18,28,34,65,49,25,37 };priorityQueue.initelem(array);//测试建立小根堆priorityQueue.Smallrootpiles();priorityQueue.elempeek();System.out.println();//测试大根堆的实现priorityQueue.createhead();priorityQueue.elempeek();//测试插入一个元素priorityQueue.push(80);System.out.println();priorityQueue.elempeek();//测试删除一个元素priorityQueue.poll();System.out.println();priorityQueue.elempeek();System.out.println();//测试堆排序priorityQueue.headsort();priorityQueue.elempeek();//}
}
3.4堆的问题
3.4.1topk问题
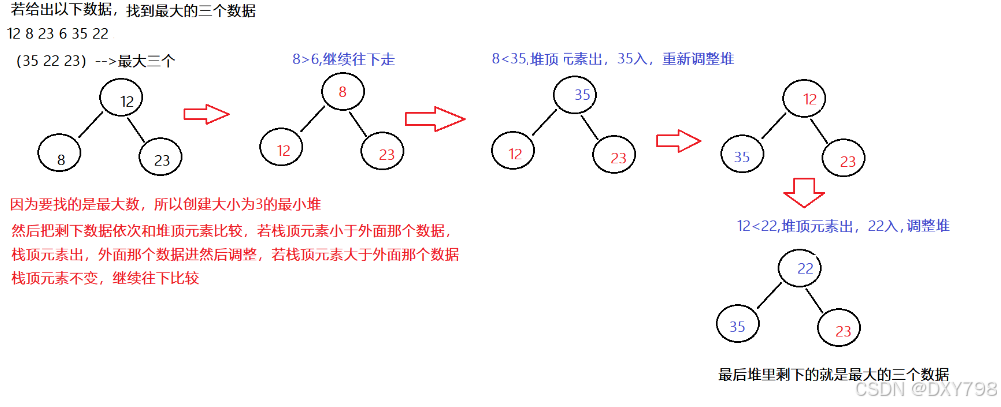
给你6个数据,求前3个最大数据。这时候我们用堆怎么做的?
解题思路:
1、如果求前K个最大的元素,要建一个小根堆。
2、如果求前K个最小的元素,要建一个大根堆。
3、第K大的元素。建一个小堆,堆顶元素就是第K大的元素。
4、第K小的元素。建一个大堆,堆顶元素就是第K大的元素。
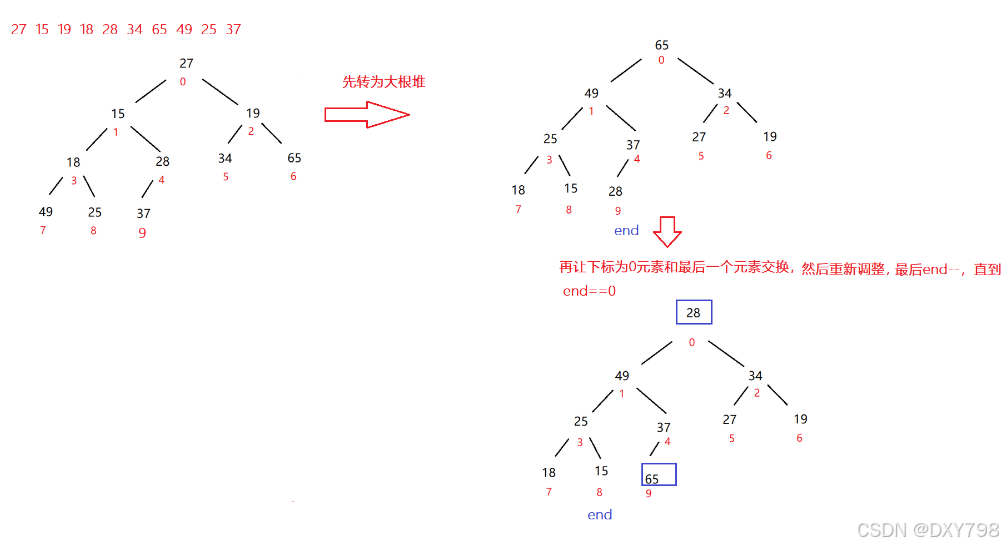
3.4.2数组的排序
再者说如果要对一个数组进行从小到大排序,要借助大根堆还是小根堆呢?
---->大根堆
3.5PriorityQueue
使用注意:
1. 使用时必须导入PriorityQueue所在的包,即:
import java.util.PriorityQueue; 2. PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出 ClassCastException异常
3. 不能插入null对象,否则会抛出NullPointerException
4. 没有容量限制,可以插入任意多个元素,其内部可以自动扩容
5. 插入和删除元素的时间复杂度为
6. PriorityQueue底层使用了堆数据结构
7. PriorityQueue默认情况下是小堆---即每次获取到的元素都是最小的元素
1.优先级队列的构造

static void TestPriorityQueue(){// 1.创建一个空的优先级队列,底层默认容量是11PriorityQueue<Integer> q1 = new PriorityQueue<>();// 2.创建一个空的优先级队列,底层的容量为initialCapacityPriorityQueue<Integer> q2 = new PriorityQueue<>(100);ArrayList<Integer> list = new ArrayList<>();list.add(4);list.add(3);list.add(2);list.add(1);// 用ArrayList对象来构造一个优先级队列的对象// q3中已经包含了三个元素PriorityQueue<Integer> q3 = new PriorityQueue<>(list);System.out.println(q3.size());System.out.println(q3.peek());}//注意:默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器// 用户自己定义的比较器:直接实现Comparator接口,然后重写该接口中的compare方法即可
class IntCmp implements Comparator<Integer>{@Overridepublic int compare(Integer o1, Integer o2) {return o2-o1;}}public class TestPriorityQueue {public static void main(String[] args) {PriorityQueue<Integer> p = new PriorityQueue<>(new IntCmp());p.offer(4);p.offer(3);p.offer(2);p.offer(1);p.offer(5)自定义排序规则
1.该改变升序降序

2.根据HashMap的value值对HashMap的键值对排序
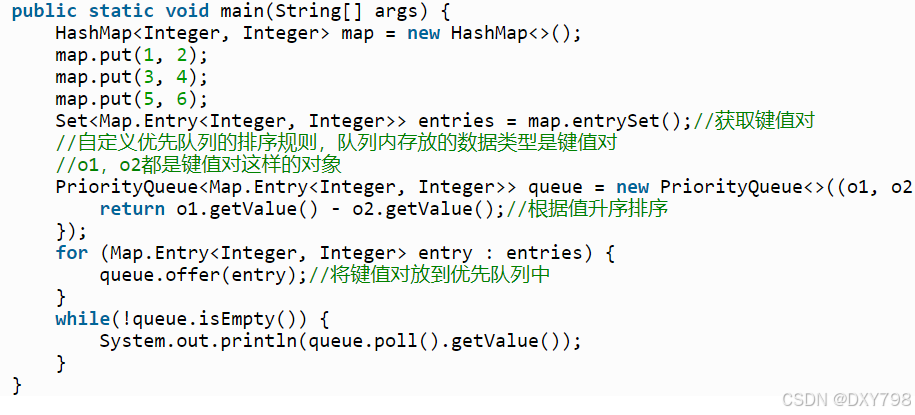
方法摘要
System.out.println(p.peek());}}static void TestPriorityQueue2(){int[] arr = {4,1,9,2,8,0,7,3,6,5};// 一般在创建优先级队列对象时,如果知道元素个数,建议就直接将底层容量给好// 否则在插入时需要不多的扩容// 扩容机制:开辟更大的空间,拷贝元素,这样效率会比较低PriorityQueue<Integer> q = new PriorityQueue<>(arr.length);for (int e: arr) {q.offer(e);}System.out.println(q.size()); // 打印优先级队列中有效元素个数System.out.println(q.peek()); // 获取优先级最高的元素// 从优先级队列中删除两个元素之和,再次获取优先级最高的元素q.poll();q.poll();System.out.println(q.size()); // 打印优先级队列中有效元素个数System.out.println(q.peek()); // 获取优先级最高的元素q.offer(0);System.out.println(q.peek()); // 获取优先级最高的元素// 将优先级队列中的有效元素删除掉,检测其是否为空q.clear();if(q.isEmpty()){System.out.println("优先级队列已经为空!!!")}else{System.out.println("优先级队列不为空");}}