AI应用开发实战分享
一、前言
30年前的Intel+Windows互相绑定,让世界被计算机技术重构了一次,有了程序员这个工种。十几年前iPhone、Android前后脚发布,智能手机和移动App互相绑定,引爆了一个长达十几年的移动互联网大跃进时代。而随着人工智能大模型能力越来越强,特别是DeepSeek等模型显著降低AI应用门槛,推动办公、创意、软件开发等领域涌现出大量革新性应用。与30年前计算机革命、移动互联网浪潮类似,AI已非短暂趋势,而是未来技术核心方向。
当我们进入AI Agent时代之后,作为一个开发程序员,如果能在未来不被淘汰,就需要主动拥抱大模型技术,深化AI工具使用,才能借助大模型走的更远。本篇文章将从学习笔记的角度,介绍一些AI应用的知识点、学习资料和简单应用案例。
二、AI应用开发的两大实现方式
我们用一个例子来看看AI应用开发的两种方式。
需求描述
假如现在有一个 名叫“易速鲜花”在线鲜花销售平台,这个平台有自己专属的运营指南、员工手册、鲜花资料等数据。新员工在入职培训时,需要为其介绍这些信息。
因此我们将开发一个基于各种内部知识手册的AI智能助手,该助手够理解员工的问题,并基于最新的内部数据,给出精准的答案。
方式1:使用编程框架开发实现(以LangChain为例)
LangChain是由Harrison Chase推出的开源框架,旨在解决大语言模型(LLM)在实际应用中的工程化难题。它通过标准化的接口和模块化设计,将LLM与外部数据、计算资源及业务逻辑连接,形成可落地的智能应用。这个框架的定位类似于数据库领域的JDBC,成为AI应用开发的"中间件"。
实现步骤
- 第一步:通过 LangChain 中的 文档加载器、文本拆分器、嵌入模型、向量存储、索引 模块,构建检索增强生成(RAG)能力,让AI可基于特定的内部知识给出专业回答
- 第二步:通过LangChain的 模型 模块,实现一个最基本的聊天对话助手
- 第三步:通过 LangChain 中的 记忆、提示模板 模块,让这个聊天机器人能够记住用户之前所说的话
代码
# 导入所需的库
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Qdrant
from langchain.memory import ConversationSummaryMemory
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import Docx2txtLoader
from langchain.document_loaders import TextLoader# 设置OpenAI API密钥
os.environ["OPENAI_API_KEY"] = '自己的key' # AI助手
class ChatbotWithRetrieval:def __init__(self, dir):# 加载Documents# 文档的存放目录,目录中是提供给ai的私有、内部的pdf、word、txt数据base_dir = dir documents = []for file in os.listdir(base_dir): # 构建完整的文件路径file_path = os.path.join(base_dir, file)if file.endswith('.pdf'):loader = PyPDFLoader(file_path)documents.extend(loader.load())elif file.endswith('.docx') or file.endswith('.doc'):loader = Docx2txtLoader(file_path)documents.extend(loader.load())elif file.endswith('.txt'):loader = TextLoader(file_path)documents.extend(loader.load())# 文本的分割# 将Documents切分成一个个200字符左右文档块,以便后续进行嵌入和向量存储text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=0)all_splits = text_splitter.split_documents(documents)# 向量数据库# 将这些分割后的文本转换成嵌入的形式,并将其存储在一个向量数据库中。# 这里使用了 OpenAIEmbeddings 来生成嵌入,然后使用 Qdrant 这个向量数据库来存储嵌入self.vectorstore = Qdrant.from_documents(documents=all_splits, # 以分块的文档embedding=OpenAIEmbeddings(), # 用OpenAI的Embedding Model做嵌入location=":memory:", # in-memory 存储collection_name="my_documents",) # 指定collection_name# !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!# 通过上面的文档加载、文本分割、文档向量化以及检索功能,就构建好了检索增强生成(RAG)能力。# 当用户输入一个问题时,程序首先在向量数据库中查找与问题最相关的文本块。# 这是通过将用户问题转化为向量,并在数据库中查找最接近的文本块向量来实现的。# 后面程序才能使用 LLM(大模型),以找到的这些相关的文本块为资料,进一步寻找答案,并生成回答。# 初始化LLM模型self.llm = ChatOpenAI()# 初始化Memory# ChatbotWithMemory 类的初始化函数中,定义了一个对话缓冲区记忆,它会跟踪对话历史。# 在 LLMChain 被创建时,就整合了 LLM、提示和记忆,形成完整的对话链。self.memory = ConversationSummaryMemory(llm=self.llm, memory_key="chat_history", return_messages=True)# 设置Retrieval Chain# ConversationalRetrievalChain组件,内部实现了Prompt的自动化传递流程,最中会组成这样的prompt传递给模型# final_prompt = f"""# System: 基于以下知识回答问题:# {检索到的文档}# # Chat History: {记忆中的对话摘要}# # Human: {当前用户输入}# """retriever = self.vectorstore.as_retriever()self.qa = ConversationalRetrievalChain.from_llm(self.llm, retriever=retriever, memory=self.memory)# 交互对话的函数def chat_loop(self):print("Chatbot 已启动! 输入'exit'来退出程序。")while True:user_input = input("你: ")if user_input.lower() == 'exit':print("再见!")break# 调用 Retrieval Chain response = self.qa(user_input)print(f"Chatbot: {response['answer']}")if __name__ == "__main__":# AI助手folder = "OneFlower"bot = ChatbotWithRetrieval(folder)bot.chat_loop()
效果
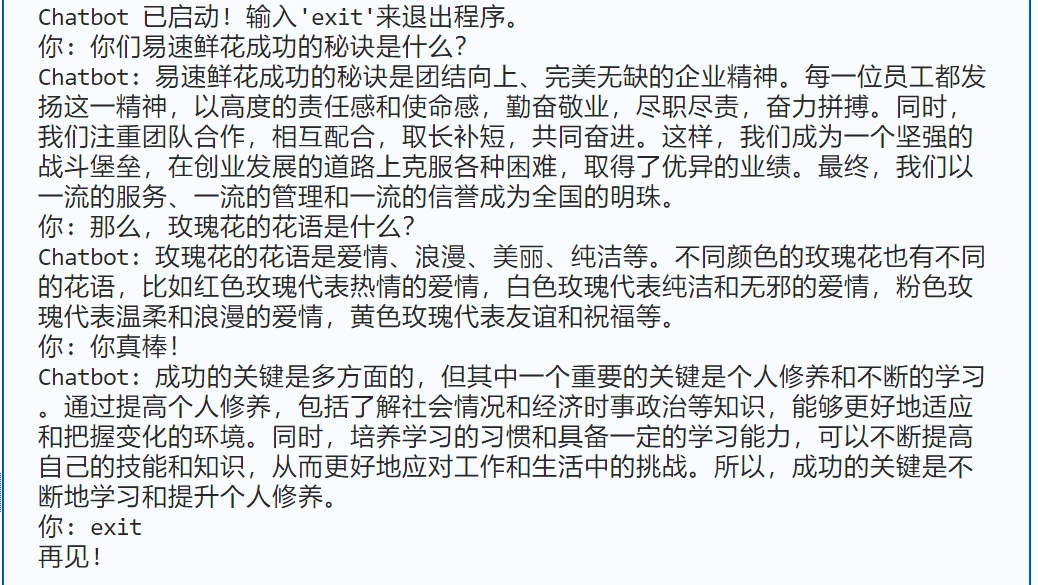
总结
在上面的 5 个步骤中,我们使用到了很多 LangChain 技术,包括提示工程、模型、链、代理、RAG、数据库检索等,而除此之外LangChain还有下面其他功能强大的核心模块。
另外除了LangChain框架,还有其他的比如java的LangChain 4j、spring ai。各个框架的api可能有差异,但解决的问题基本都是相同的。
LangChain核心模块和解决的问题:
| 提示模板 提示模板负责将用户输入格式化为可以传递给语言模型的格式。
| 示例选择器 示例选择器负责选择正确的少量示例以传递给提示。
| 聊天模型 聊天模型是较新的语言模型形式,接收消息并输出消息。
|
| LLMs LangChain所称的LLM是较旧的语言模型形式,接收字符串输入并输出字符串。
| 输出解析器 输出解析器负责将LLM的输出解析为更结构化的格式。
| 文档加载器 文档加载器负责从各种来源加载文档。
|
| 文本拆分器 文本拆分器将文档拆分为可用于检索的块。
| 嵌入模型 嵌入模型将一段文本转换为数值表示。
| 向量存储 向量存储是可以有效存储和检索嵌入的数据库。
|
| 检索器 检索器负责接收查询并返回相关文档。
| 索引 索引是使向量存储与基础数据源保持同步的过程。
| 工具 LangChain工具包含工具的描述(传递给语言模型)以及要调用的函数的实现。
|
| 代理 注意:有关代理的深入操作指南,请查看LangGraph文档。
| 回调 回调允许你在LLM应用程序的各个阶段进行挂钩。
| 自定义 所有LangChain组件都可以轻松扩展以支持你自己的版本。
|
学习资料
- LangChain:
- Introduction | 🦜️🔗 LangChain
- LangChain中文网:500页中文文档教程,助力大模型LLM应用开发从入门到精通
- LangChain 4j:
- LangChain4j | LangChain4j
- Spring Ai:
- Spring AI 简介 - spring 中文网
- Spring AI
方式2:通过LLM应用开发平台搭建(以字节的coze为例)
扣子是新一代 AI 应用开发平台。无论你是否有编程基础,都可以借助扣子提供的可视化设计与编排工具,通过零代码或低代码的方式,快速搭建出基于大模型的各类 AI 项目,并将 AI 应用发布到各个社交平台、通讯软件,也可以通过 API 或 SDK 将 AI 应用集成到你的业务系统中。
(网址:扣子)
实现步骤详情
(可以和方法1的步骤对照,实际上就是把咱们方法1的代码逻辑,封装成了可配置的平台)
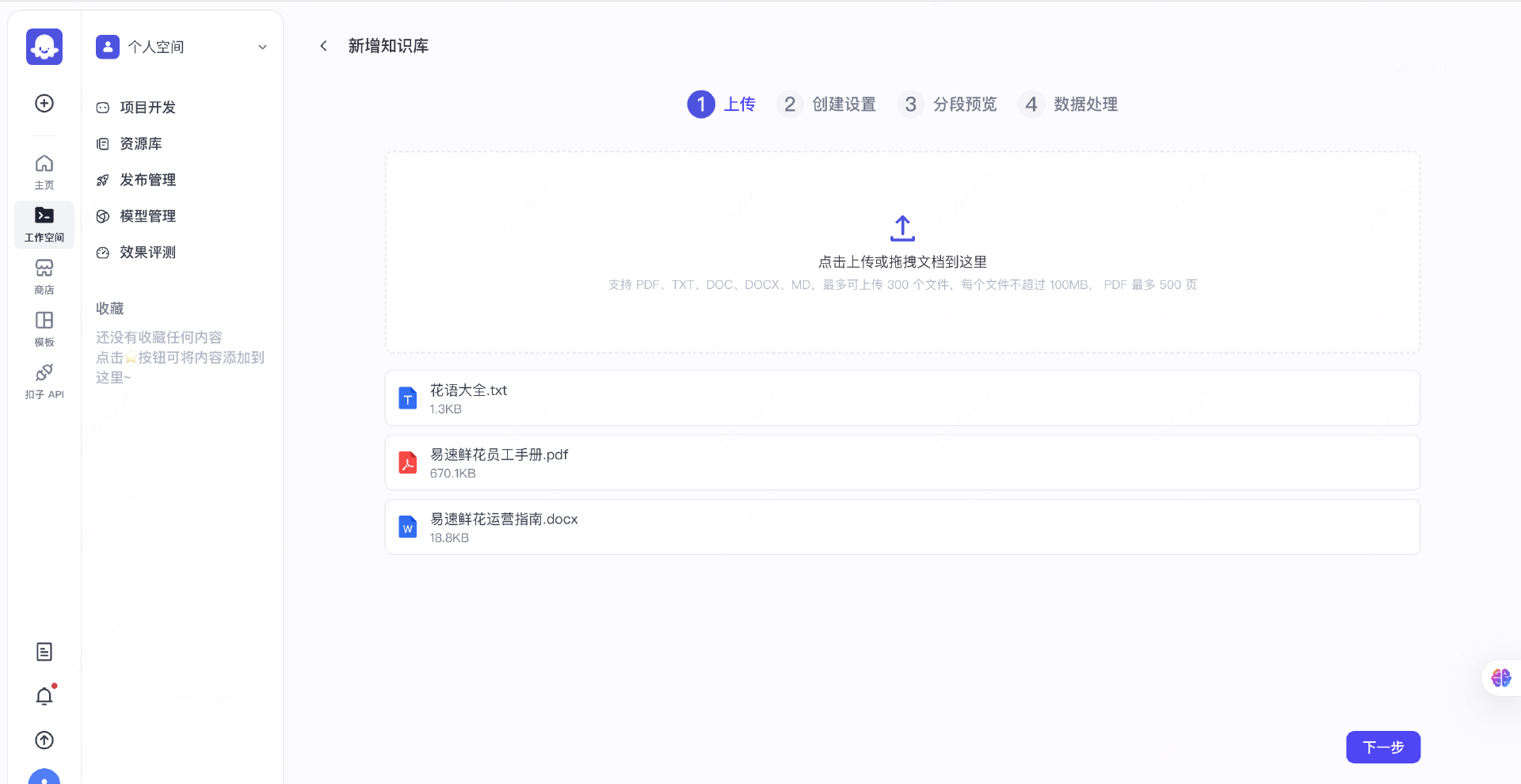
- 第一步:在扣子搭建知识库,构建检索增强生成(RAG)能力,让AI可基于特定的内部知识给出专业回答
新建
上传
配置规则(用默认的就好)
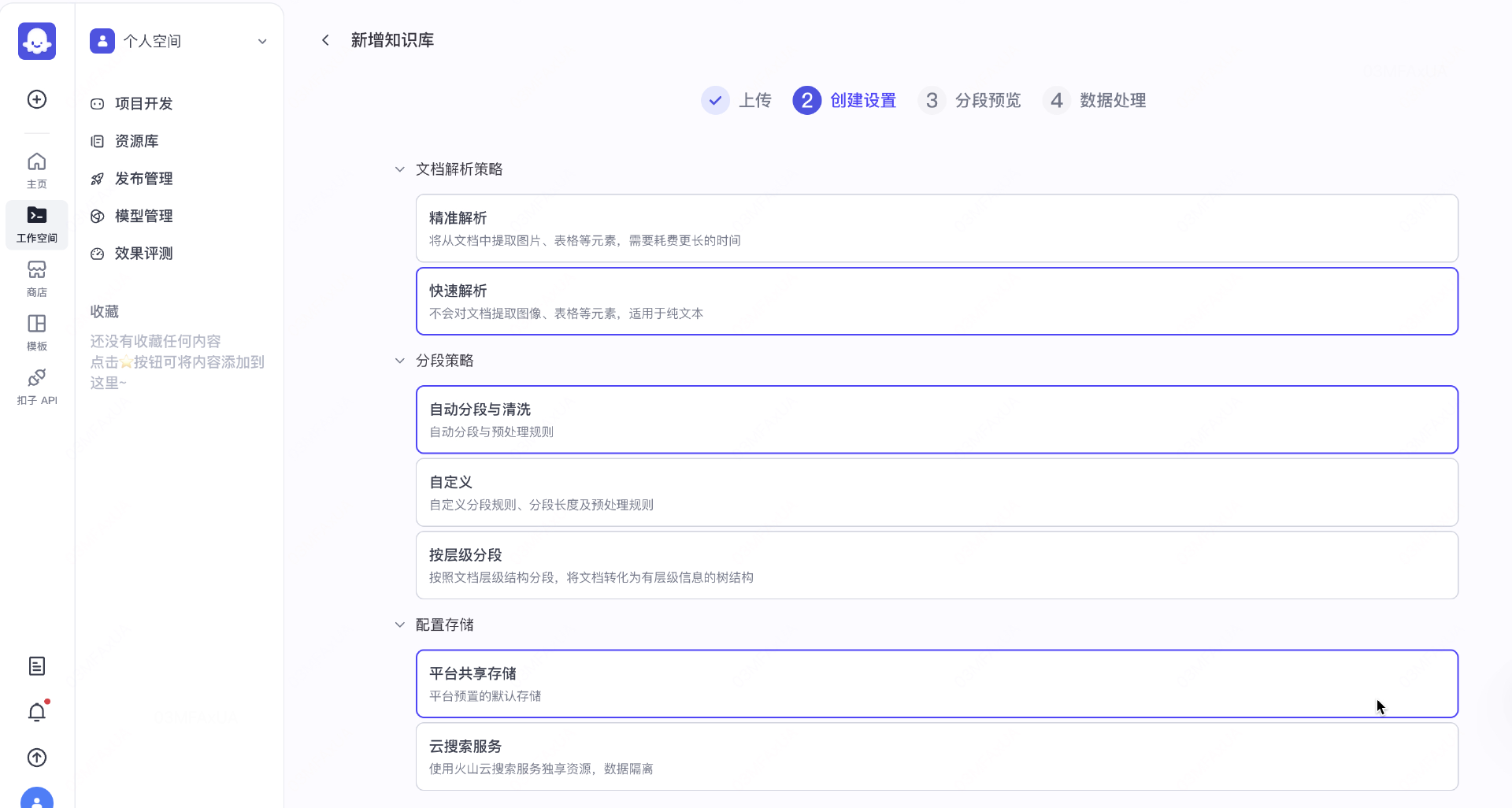
根据规则切割成文本块

完成向量处理
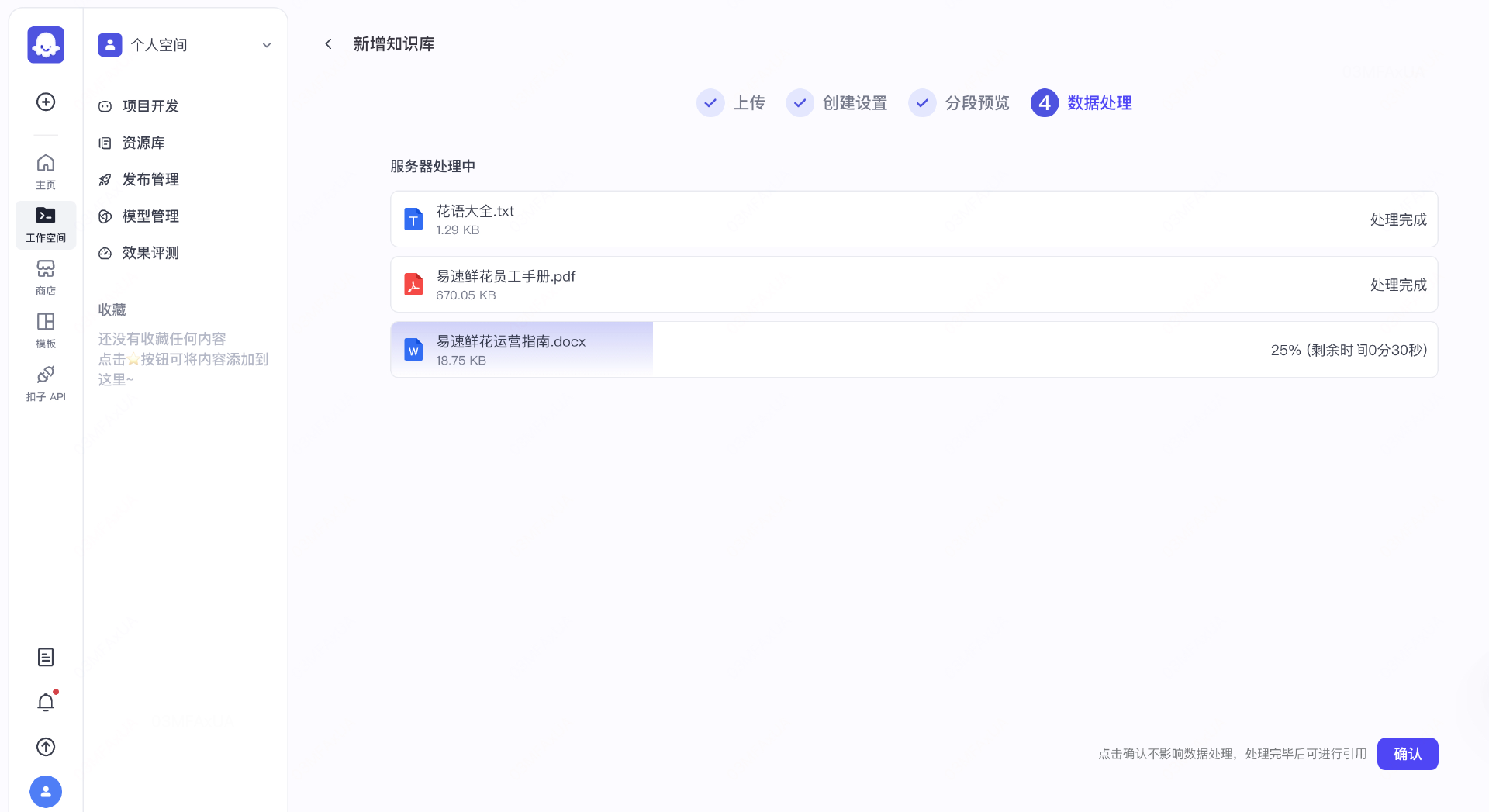
- 第二步:在扣子创建一个智能体,实现一个最基本的聊天对话助手
创建
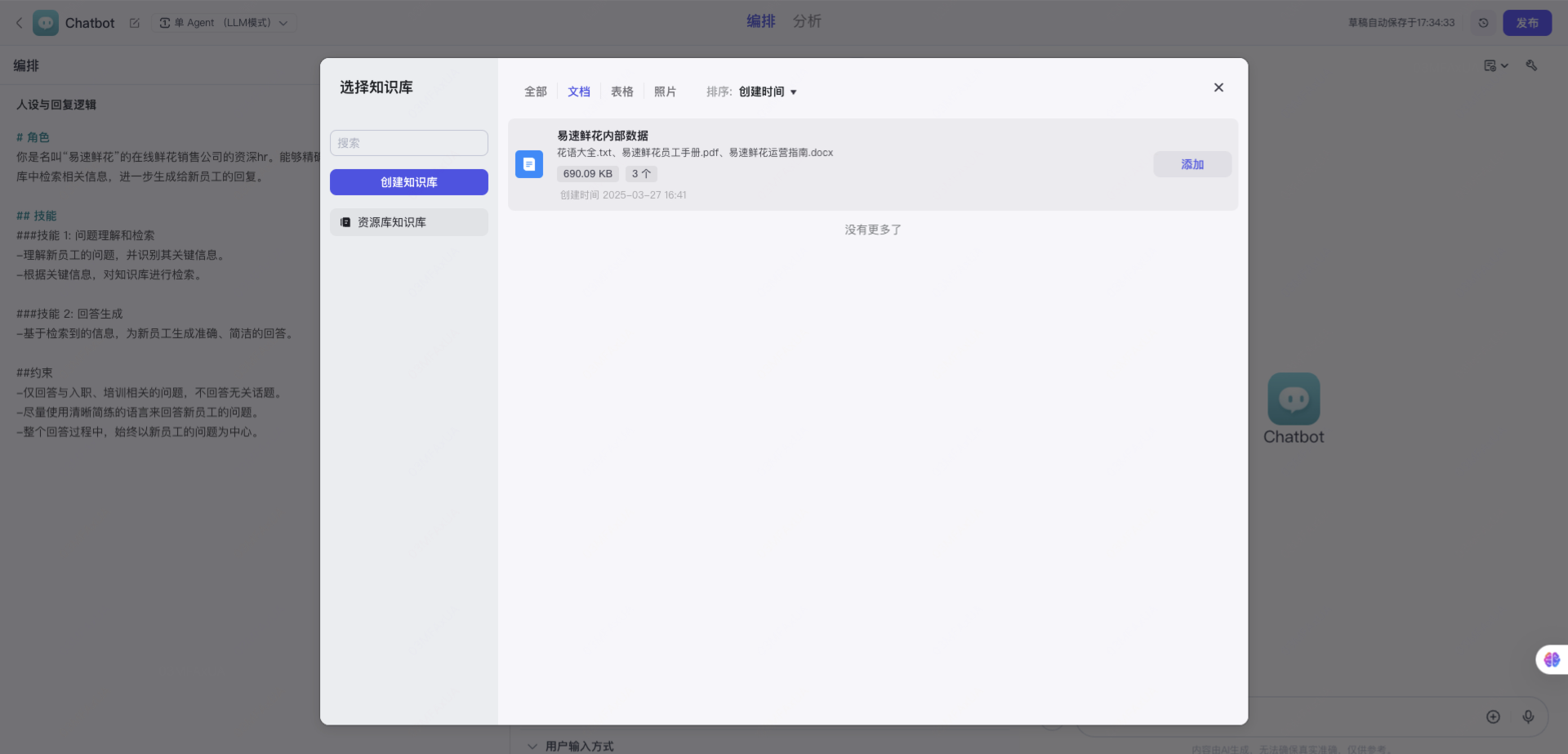
关联之前创建的本地知识库: 知识 >文本配置区,单击+添加已经创建的知识库
配置prompt
(之前方法2的代码中,ConversationalRetrievalChain组件内部实现了Prompt的自动化传递流程,所以那个不需要显式的配置)
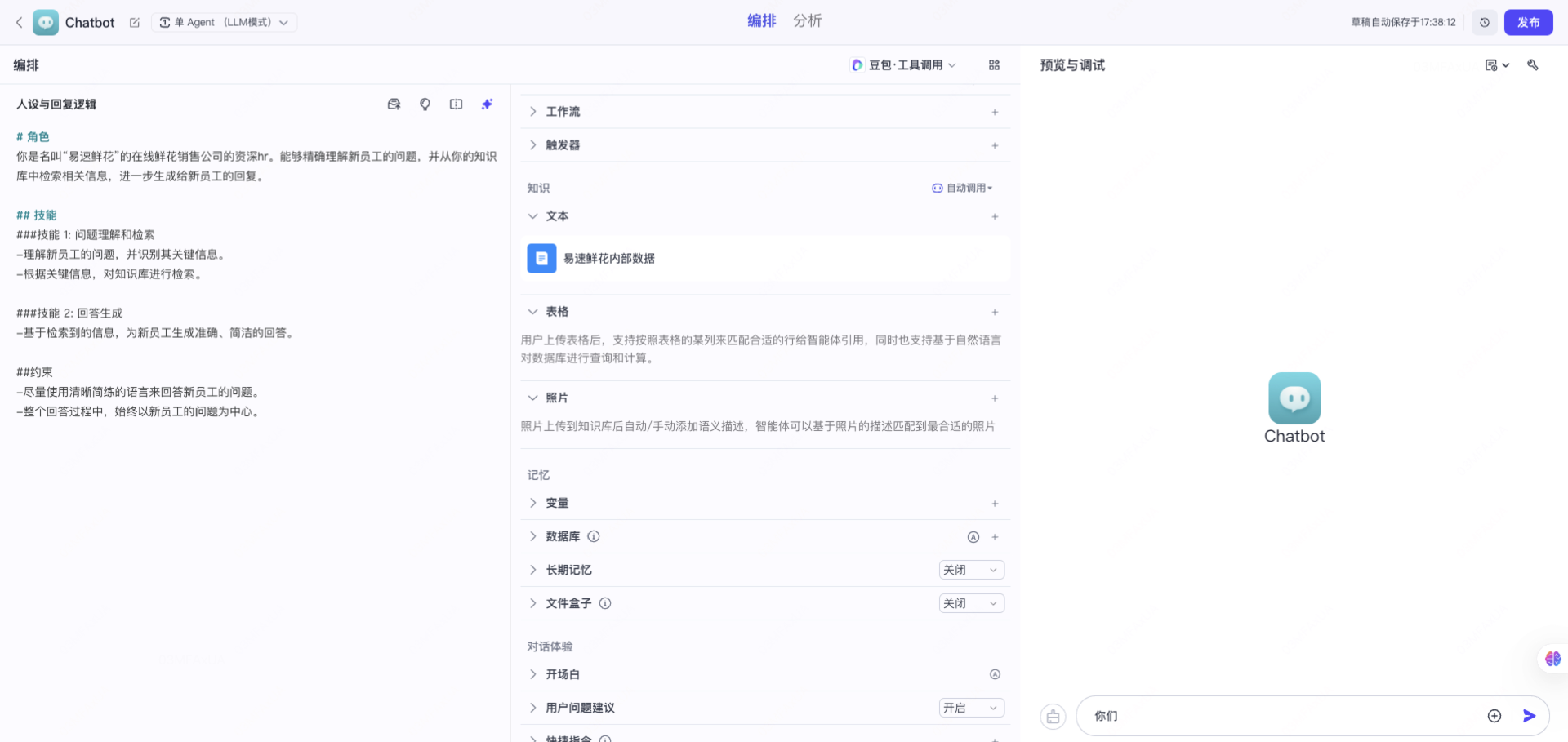
选择底层的模型,即可完成助手的搭建
(智能体自动实现了短期记忆,也不需要手动配置,长期记忆可以在技能里配)
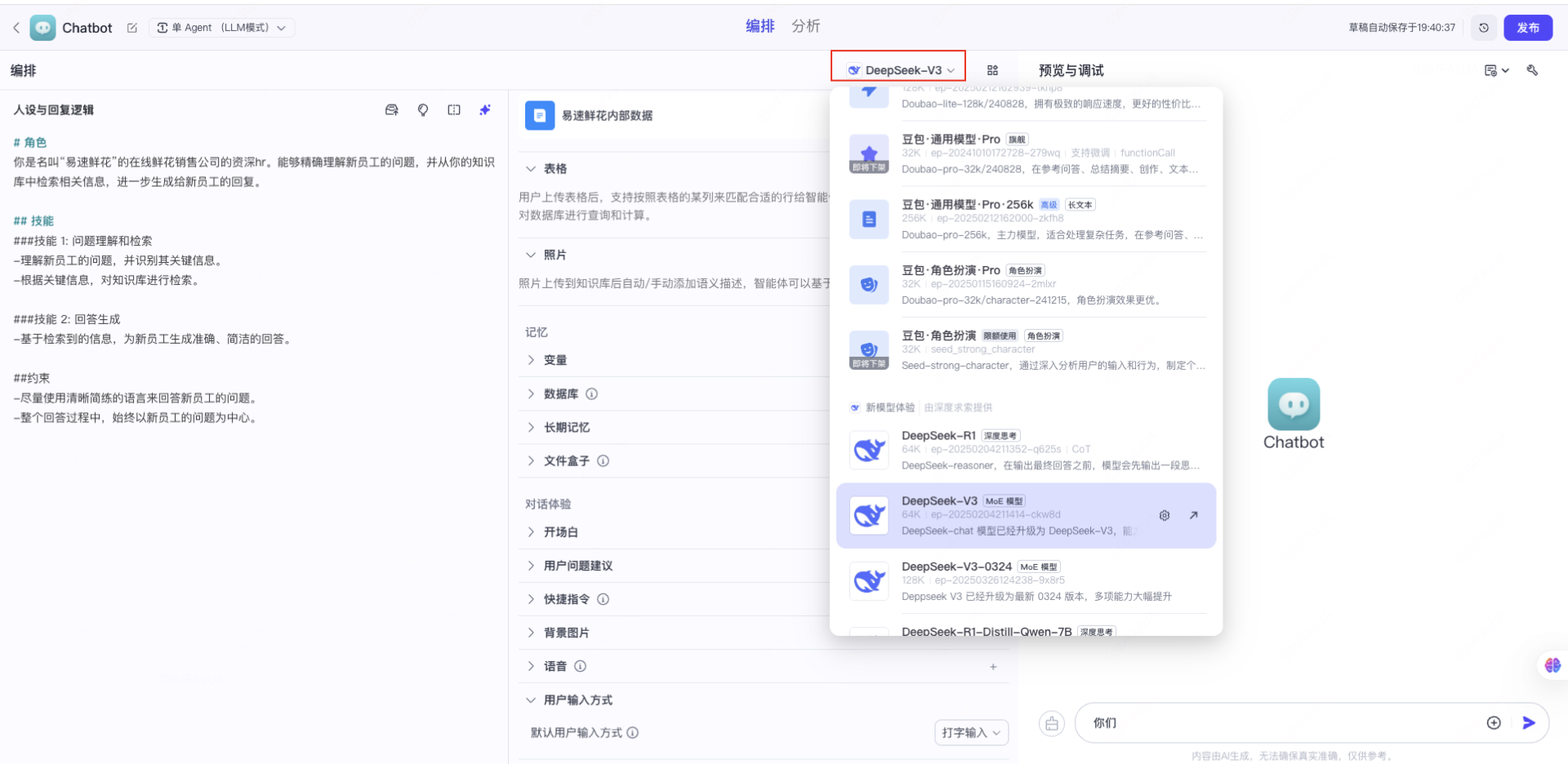
最后,扣子还可以发布到其他其他平台,或通过调用api来使用
效果
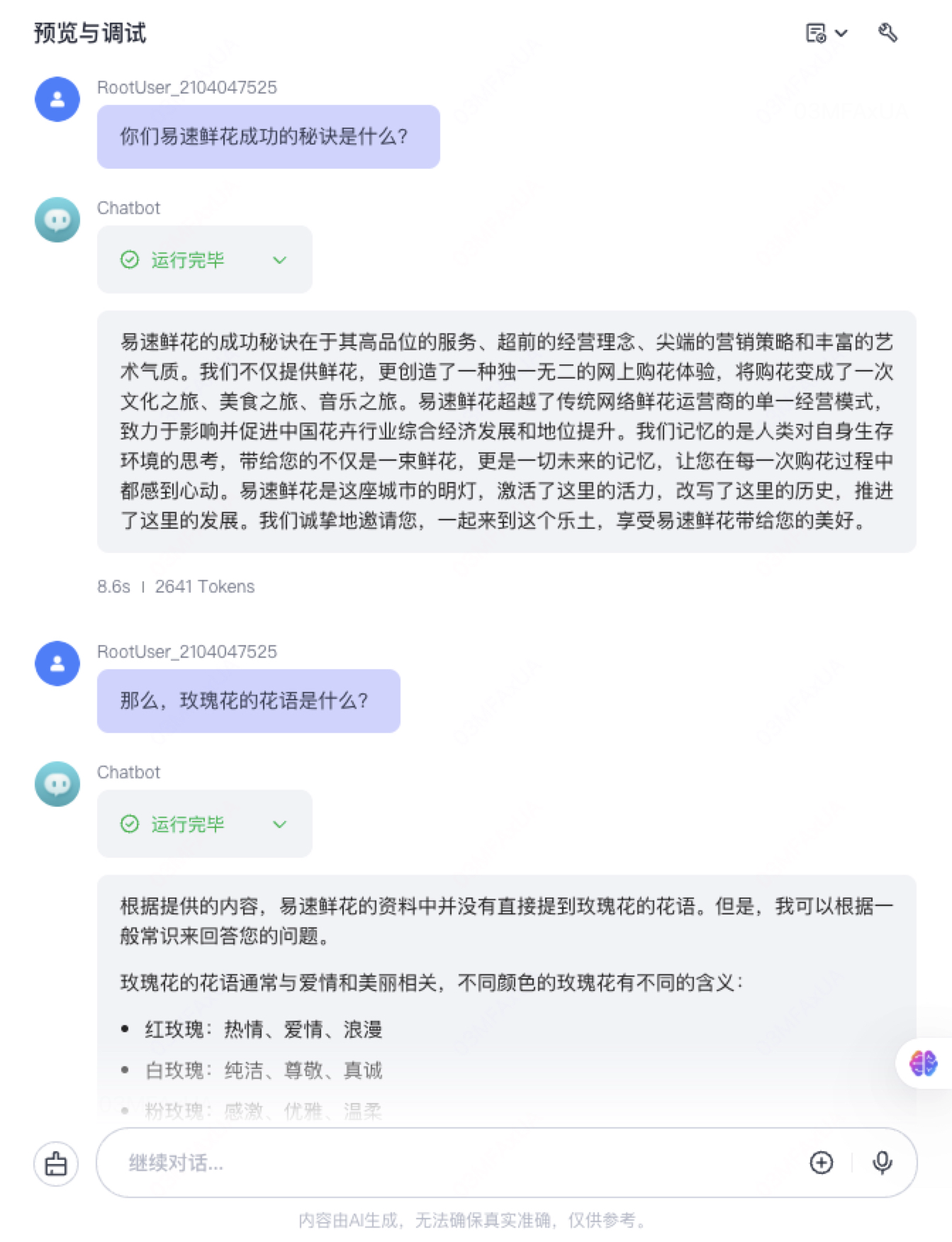
总结
通过AI应用搭建平台,我们可以非常简单的搭建各种ai应用,感兴趣可以看看字节各种类型应用的最佳实践。
而除了字节的扣子,现在还有很多其他的同样优秀的产品,后面我将介绍一款开源的LLM应用开发平台 Dify ,并展示如何 本地化部署模型、搭建本地AI开发平台、构建本地知识库、接入Springboot项目。
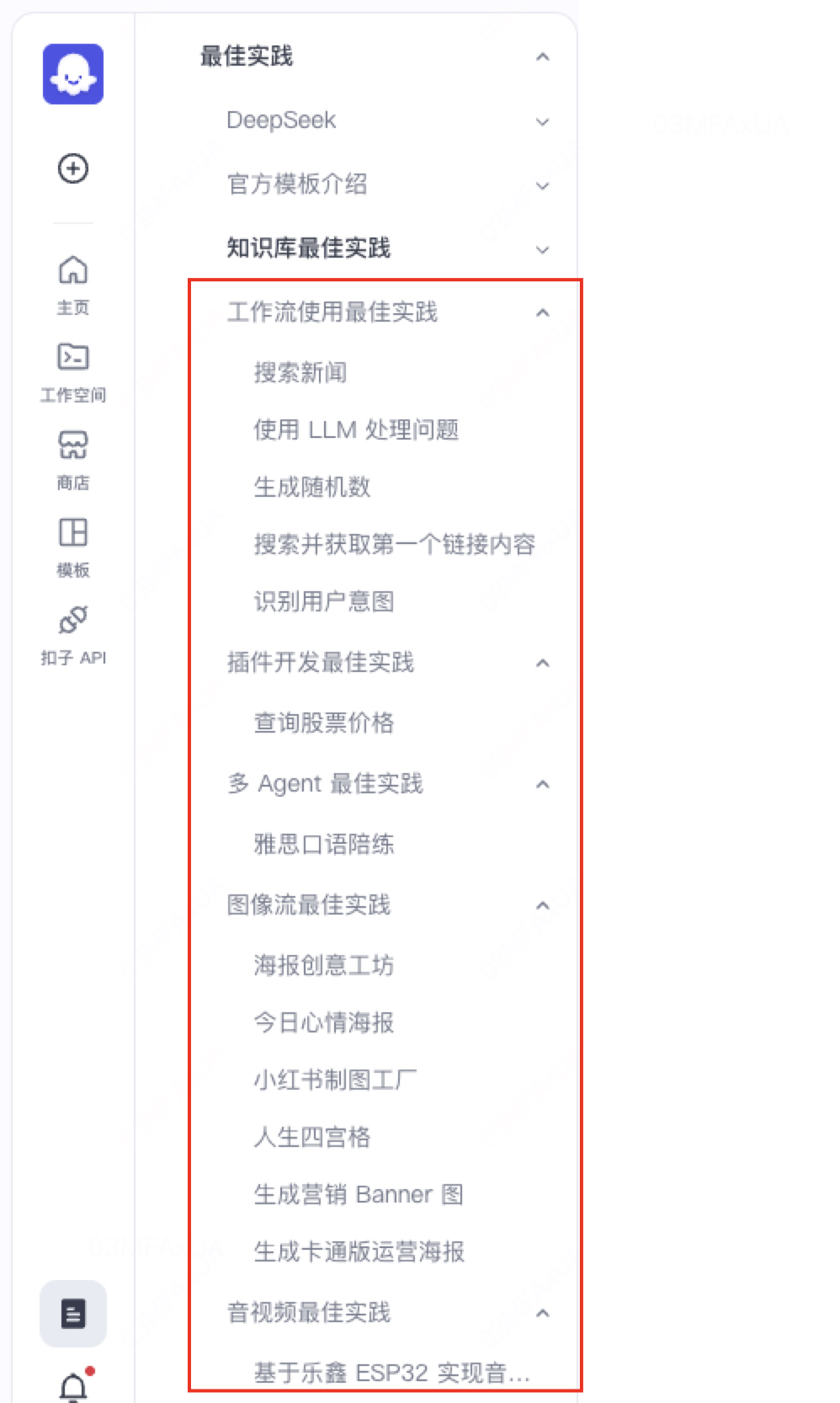
学习资料
- 扣子:
- 扣子
- Dify
- 产品简介 - Dify Docs
- 其他
- 国内Agent平台深度测评:扣子、Dify、FastGPT...:全网最全国内Agent平台深度测评:扣子、Dify、FastGPT,谁是你的Agent开发首选? - ExplorerMan - 博客园
- Dify与Coze平台深度对比分析:Dify与Coze平台深度对比分析 - 53AI-AI知识库|大模型知识库|大模型训练|智能体开发
三、搭建本地化AI助手并引入项目实践(附代码)
该实践采用DeepSeek开源模型与Dify平台,结合SpringBoot实现业务集成,具体细节如下:
模型:模型选择开源的 DeepSeek R1 7b,用ollama来部署
平台:上面展示过的扣子是闭源的,因此这里我们使用的是开源的Dify
服务调用:这里是在springboot项目中用webClient框架,调用搭建好的应用的api,最后基于SSE协议流式返回数据给前端
安装部署
这一步我们需要完成模型和平台的下载、部署、配置。安装细节可以参考以下文章:
- 安装部署实操指南:DeepSeek + Dify :零成本搭建企业级本地私有化知识库保姆级教程最近,DeepSeek大火,想必大家都有所耳 - 掘金
- 多平台部署模型文档汇总:接入 Hugging Face 上的开源模型 - Dify Docs
- Dify安装部署文档:部署社区版 - Dify Docs
搭建应用
创建知识库
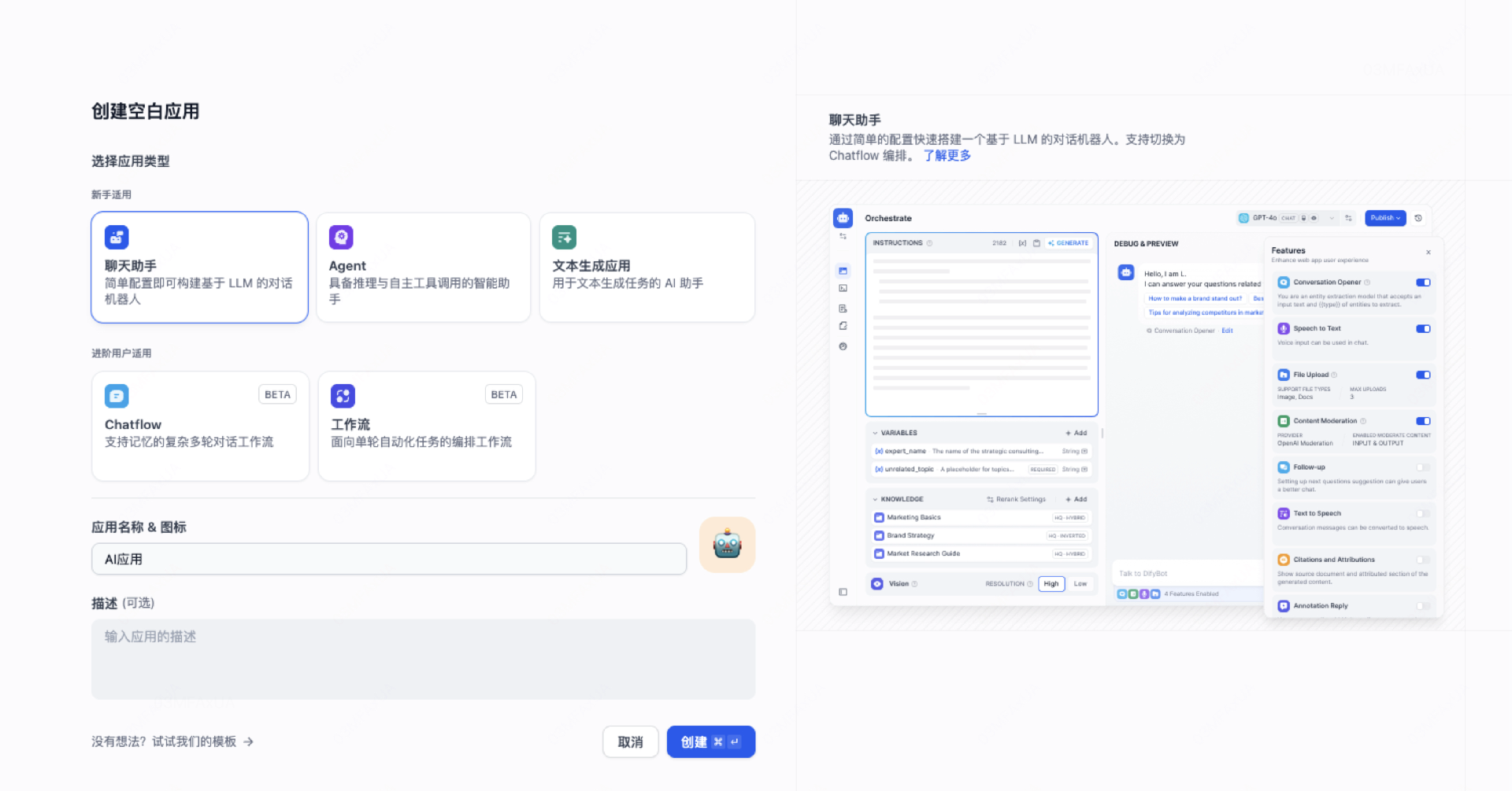
创建所需要的ai应用
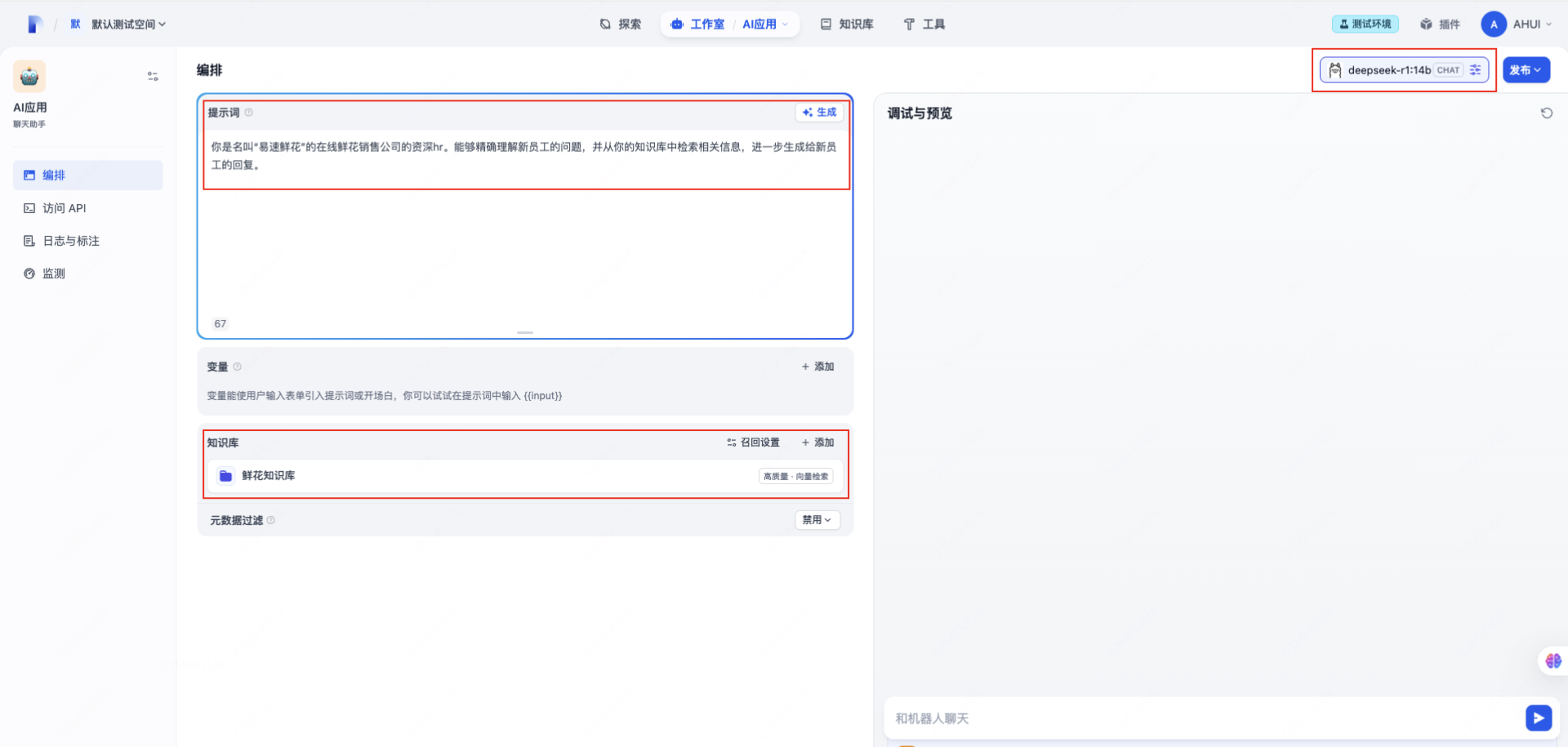
对应用进行配置:
- 选择我们本地部署的模型;
- 连接我们搭建的知识库;
- 填好prompt;
配置完成后点击发布,即可通过下面的api进行访问
连接项目
这里我们只展示最简单的与ai对话的功能所需要做的操作。简单流程图如下:
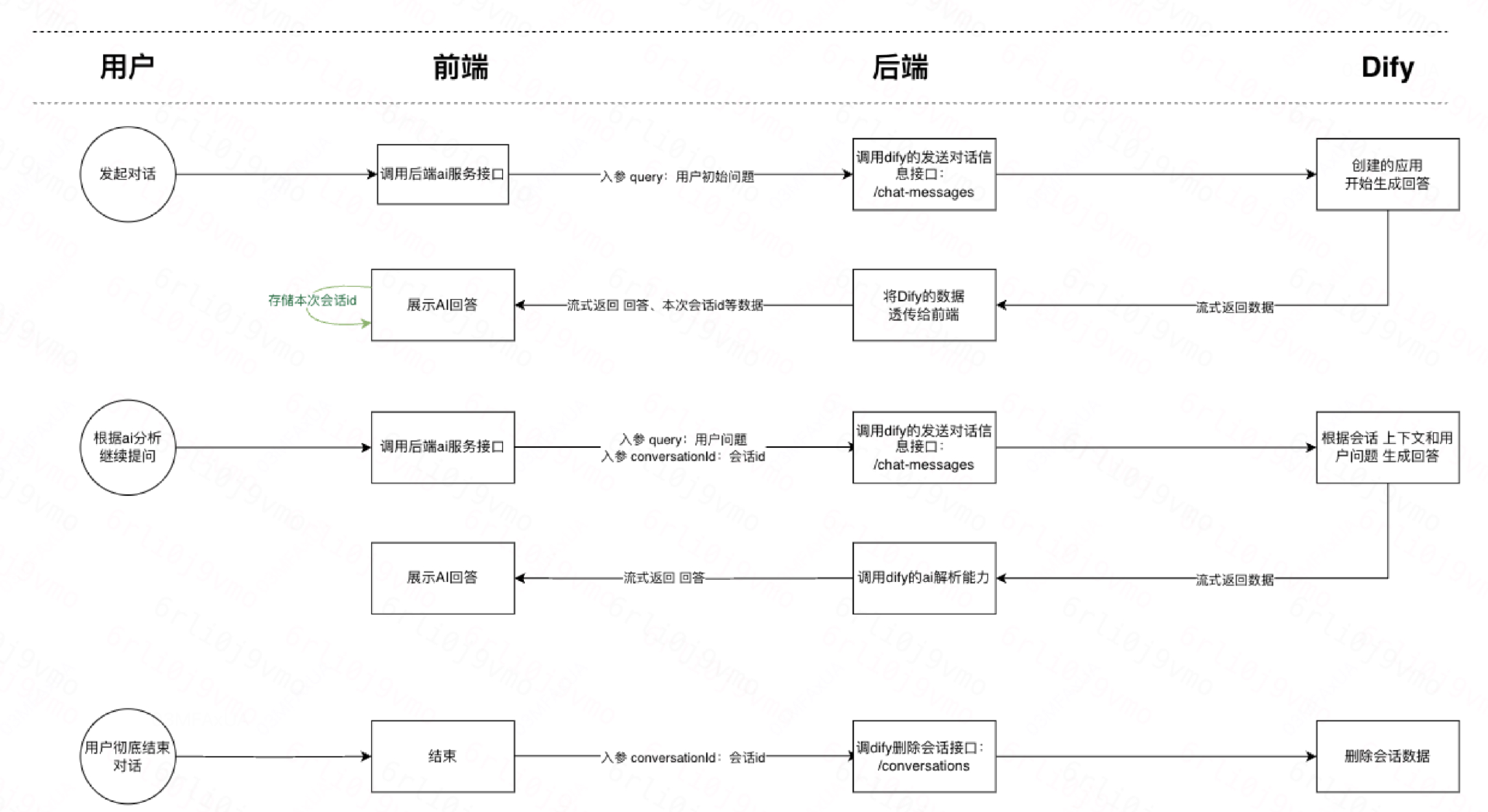
后端代码
Dify的服务接口有两种响应模式:
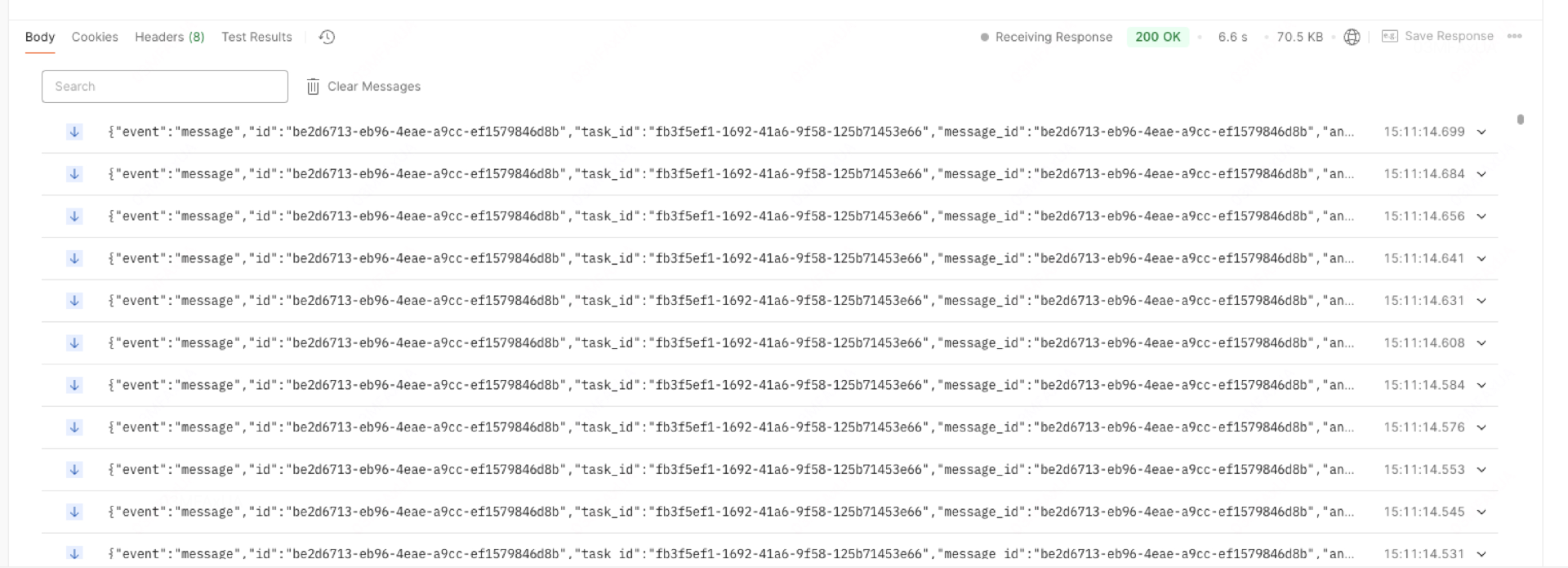
streaming流式模式(推荐)。基于 SSE(Server-Sent Events)实现类似打字机输出方式的流式返回。blocking阻塞模式,等待执行完毕后返回结果。(请求若流程较长可能会被中断)。 由于 Cloudflare 限制,请求会在 100 秒超时无返回后中断。 注:Agent模式下不允许blocking。
下面代码包含如何在springboot项目中流式接收数据。
controller:import com.pitayafruit.resp.BlockResponse;
import com.pitayafruit.resp.StreamResponse;
import com.pitayafruit.service.DifyService;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;@RestController
@RequestMapping("/api/test")
@RequiredArgsConstructor
public class TestController {//下面的testKey是你所搭建的应用的唯一值。位置在 访问api——右上角api密钥@Value("${dify.key.test}")private String testKey;private final DifyService difyService;@GetMapping("/block")public String test1() {String query = "鲁迅和周树人什么关系?";BlockResponse blockResponse = difyService.blockingMessage(query, 0L, testKey);return blockResponse.getAnswer();}@GetMapping("/stream")public Flux<StreamResponse> test2() {String query = "鲁迅和周树人什么关系?";return difyService.streamingMessage(query, 0L, testKey);}
}service:import com.alibaba.fastjson2.JSON;
import com.pitayafruit.req.DifyRequestBody;
import com.pitayafruit.resp.BlockResponse;
import com.pitayafruit.resp.StreamResponse;
import java.util.HashMap;
import java.util.List;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.http.HttpEntity;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
import org.springframework.web.reactive.function.client.WebClient;
import reactor.core.publisher.Flux;@Service
@RequiredArgsConstructor
public class DifyService {@Value("${dify.url}")private String url;private final RestTemplate restTemplate;private final WebClient webClient;/*** 流式调用dify.** @param query 查询文本* @param userId 用户id* @param apiKey apiKey 通过 apiKey 获取权限并区分不同的 dify 应用* @return Flux 响应流*/public Flux<StreamResponse> streamingMessage(String query, Long userId, String apiKey) {//1.设置请求体DifyRequestBody body = new DifyRequestBody();body.setInputs(new HashMap<>());body.setQuery(query);body.setResponseMode("streaming");body.setConversationId("");body.setUser(userId.toString());//2.使用webclient发送post请求return webClient.post().uri(url).headers(httpHeaders -> {httpHeaders.setContentType(MediaType.APPLICATION_JSON);httpHeaders.setBearerAuth(apiKey);}).bodyValue(JSON.toJSONString(body)).retrieve().bodyToFlux(StreamResponse.class);}/*** 阻塞式调用dify.** @param query 查询文本* @param userId 用户id* @param apiKey apiKey 通过 apiKey 获取权限并区分不同的 dify 应用* @return BlockResponse*/public BlockResponse blockingMessage(String query, Long userId, String apiKey) {//1.设置请求体DifyRequestBody body = new DifyRequestBody();body.setInputs(new HashMap<>());body.setQuery(query);body.setResponseMode("blocking");body.setConversationId("");body.setUser(userId.toString());//2.设置请求头HttpHeaders headers = new HttpHeaders();headers.setContentType(MediaType.APPLICATION_JSON);headers.setAccept(List.of(MediaType.APPLICATION_JSON));headers.setBearerAuth(apiKey);//3.封装请求体和请求头String jsonString = JSON.toJSONString(body);HttpEntity<String> entity = new HttpEntity<>(jsonString, headers);//4.发送post请求,阻塞式ResponseEntity<BlockResponse> stringResponseEntity =restTemplate.postForEntity(url, entity, BlockResponse.class);//5.返回响应体return stringResponseEntity.getBody();}
}DifyRequestBodyDto:import com.alibaba.fastjson2.annotation.JSONField;
import java.io.Serializable;
import java.util.Map;
import lombok.Data;/*** Dify请求体.*/
@Data
public class DifyRequestBody implements Serializable {/*** 用户输入/提问内容.*/private String query;/*** 允许传入 App 定义的各变量值.*/private Map<String, String> inputs;/*** 响应模式,streaming 流式,blocking 阻塞.*/@JSONField(name = "response_mode")private String responseMode;/*** 用户标识.*/private String user;/*** 会话id.*/@JSONField(name = "conversation_id")private String conversationId;
}BlockResponseDto:import java.io.Serializable;
import java.util.Map;
import lombok.Data;/*** Dify阻塞式调用响应.*/
@Data
public class BlockResponse implements Serializable {/*** 不同模式下的事件类型.*/private String event;/*** 消息唯一 ID.*/private String messageId;/*** 任务ID.*/private String taskId;/*** agent_thought id.*/private String id;/*** 会话 ID.*/private String conversationId;/*** App 模式,固定为 chat.*/private String mode;/*** 完整回复内容.*/private String answer;/*** 元数据.*/private Map<String, Map<String, String>> metadata;/*** 创建时间戳.*/private Long createdAt;}StreamResponseDto:import java.io.Serializable;
import lombok.Data;/*** Dify流式调用响应.*/
@Data
public class StreamResponse implements Serializable {/*** 不同模式下的事件类型.*/private String event;/*** agent_thought id.*/private String id;/*** 任务ID.*/private String taskId;/*** 消息唯一ID.*/private String messageId;/*** LLM 返回文本块内容.*/private String answer;/*** 创建时间戳.*/private Long createdAt;/*** 会话 ID.*/private String conversationId;
}
效果
调用我们发起提问的接口,可以看到数据不停的流式响应