图片转文字-Tesseract-OCR,完成文字转换。
Tesseract-OCR
在图像文字识别领域,Tesseract OCR 是一款广受欢迎的开源工具,通过结合 Java 语言可以实现强大的 OCR 功能。本文将围绕 Tesseract OCR 在 Java 中的应用,以及如何解决识别准确性问题展开讨论。
优点
开源免费:代码可自由获取、修改和分发,无需支付授权费用,降低了开发成本。
多语言支持:支持多种语言的文字识别,通过下载相应的语言包,就能够对不同语言的文本进行识别。
可定制性强:调整识别参数、训练自己的字库模型,以优化在特定场景下的识别效果,如识别特定字体、字号或具有特定格式的文档。
识别准确率较高:经过不断的优化和训练,对于常规的印刷体文字,在图像质量较好的情况下,能够达到较高的识别准确率。
缺点
对图像质量要求较高:如果图像存在模糊、倾斜、噪声干扰、低分辨率等问题,可能会显著影响识别准确率。
复杂布局和特殊字体处理能力有限:复杂排版布局的文档,以及一些罕见的手写字体或艺术字体,会出现文字分割错误或识别不准确的情况。
缺乏直观的图形界面:Tesseract 主要通过命令行或编程接口来使用,对于不熟悉命令行操作或编程的用户来说,使用门槛较高。
一、安装 Tesseract OCR 引擎
1.3、Windows
从 Tesseract Home · UB-Mannheim/tesseract Wiki · GitHub下载安装程序,按照提示完成安装。
1.2、Linux
使用包管理器进行安装,例如在 Ubuntu 上可以运行 sudo apt-get install tesseract-ocr。
1.3、macOS
可以使用 Homebrew 进行安装,运行 brew install tesseract。
在 macOS 系统中,通过brew install tesseract安装 Tesseract OCR 引擎后,其默认安装路径通常是/usr/local/Cellar/tesseract。
你可以通过以下命令来确认具体路径:
brew --prefix tesseract
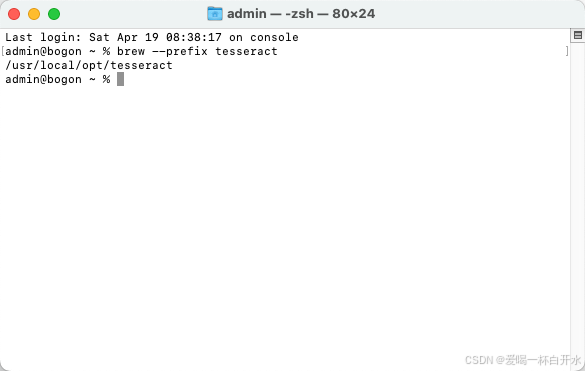
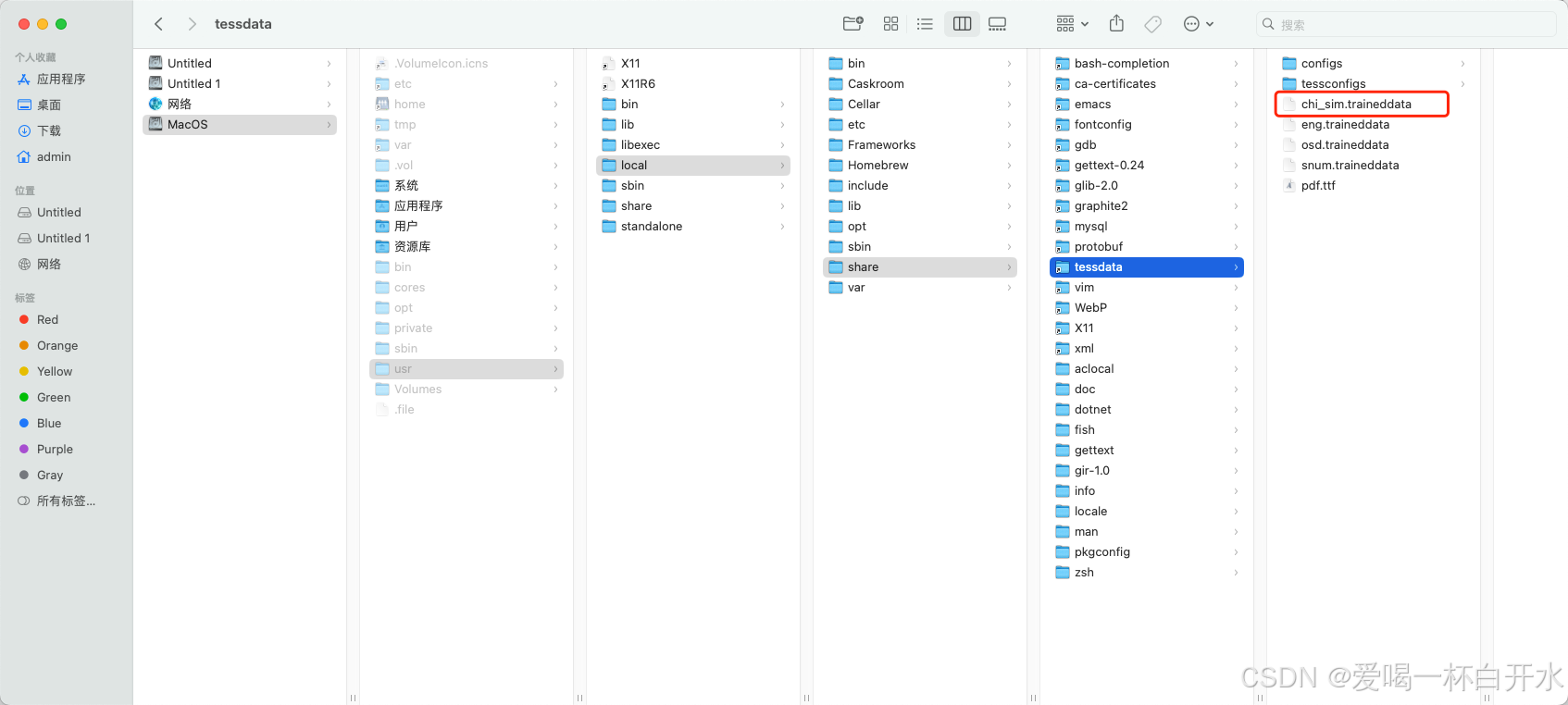
借助 Homebrew 安装 Tesseract 之后,tessdata目录通常位于/usr/local/share/tessdata。你可以使用以下命令来查看该目录是否存在,以及chi_sim.traineddata文件是否存在.
要是文件不存在,你需要手动下载 chi_sim.traineddata 文件。可以从 Tesseract OCR 的 GitHub 仓库下载GitHub - tesseract-ocr/tessdata: Trained models with fast variant of the "best" LSTM models + legacy models
,然后把下载好的文件放到 /usr/local/share/tessdata 目录。
二、添加 Tess4J 依赖
如果你使用 Maven 项目,可以在 pom.xml 文件中添加以下依赖:
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>5.11.0</version>
</dependency>三、编写 Java 代码
public class OCRExample {public static void main(String[] args) {// 创建 Tesseract 实例Tesseract tesseract = new Tesseract();try {// 设置 Tesseract 数据文件的路径,根据实际安装路径修改tesseract.setDatapath("C:\\Program Files\\Tesseract-OCR\\tessdata");// 设置识别语言,例如 "eng" 表示英文,"chi_sim" 表示简体中文tesseract.setLanguage("eng");// 要识别的图片文件路径,根据实际情况修改File imageFile = new File("path/to/your/image.jpg");// 进行 OCR 识别String result = tesseract.doOCR(imageFile);// 输出识别结果System.out.println(result);} catch (TesseractException e) {System.err.println("OCR 识别出错: " + e.getMessage());}}}- 完善优化
基于 Tesseract OCR 的 Java 工具类,我们可以方便地在项目中实现图像格式处理和文字识别功能。在实际应用中,根据具体需求对工具类进行优化和拓展,能够更好地满足不同场景下的 OCR 需求。
4.1、图片格式转化
处理图像文件,判断格式并转换 jpg/jpeg 为 png.
/*** 处理图像文件,判断格式并转换 jpg/jpeg 为 png* @param inputFilePath 输入文件的路径* @return 处理后的文件路径,如果不支持的格式则返回 null*/public static Map<String ,Object> processImageFile(String inputFilePath) {Map<String, Object> resultMap = new HashMap<>();// 图片转化后的存储位置String outputDirectory = "/Users/admin/Downloads/WORK/JAVA/Upload/ocr";File inputFile = new File(inputFilePath);try {BufferedImage image = ImageIO.read(inputFile);String outputFileName = removeExtension(inputFile.getName()) + ".png";File outputFile = new File(outputDirectory, outputFileName);// 将图像写入为 PNG 格式ImageIO.write(image, "png", outputFile);resultMap.put("code", 0);resultMap.put("msg", "转化成功.");resultMap.put("url", outputFile.getAbsolutePath());} catch (IOException e) {resultMap.put("code", 400);resultMap.put("msg", "转换文件格式时出错.");}return resultMap;}4.2、文件格式处理
/*** 获取文件的扩展名* @param fileName 文件名* @return 文件扩展名*/public static String getFileExtension(String fileName) {int lastIndex = fileName.lastIndexOf('.');if (lastIndex == -1) {return "";}return fileName.substring(lastIndex + 1);}/*** 移除文件名的扩展名* @param fileName 文件名* @return 移除扩展名后的文件名*/private static String removeExtension(String fileName) {int lastIndex = fileName.lastIndexOf('.');if (lastIndex == -1) {return fileName;}return fileName.substring(0, lastIndex);}/*** 检查文件格式是否允许* @param fileExtension 文件扩展名* @return 如果允许则返回 true,否则返回 false*/public static boolean isAllowedFormat(String fileExtension) {return "jpg".equals(fileExtension) || "jpeg".equals(fileExtension) || "png".equals(fileExtension);}4.3、文字转换
public static String performOCR(String resultFilePath) {// ocr转换Tesseract tesseract = new Tesseract();try {// 设置 Tesseract 数据文件的路径,根据实际安装路径修改tesseract.setDatapath(tessDataUrl);// 设置识别语言,例如 "eng" 表示英文,"chi_sim" 表示简体中文tesseract.setLanguage("chi_sim+eng"); // 支持中英文混合识别// 要识别的图片文件路径,根据实际情况修改File imageFile = new File(resultFilePath);// 配置 Tesseract 以提高识别准确性tesseract.setPageSegMode(6); // 设置页面分割模式为单个统一文本块tesseract.setOcrEngineMode(1); // 使用 LSTM OCR 引擎// 进行 OCR 识别String result = tesseract.doOCR(imageFile);// 去除多余的空格和换行符result = result.replaceAll("\\s+", " ").trim();// 输出识别结果return AjaxResult.Return(0, result);} catch (TesseractException e) {return AjaxResult.Return(400, "OCR 识别出错: " + e.getMessage());}}4.4、结合业务使用
package com.cn.springboot.controller;import com.cn.springboot.utils.AjaxResult;
import com.cn.springboot.utils.OCRUtil;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;import javax.servlet.http.HttpServletRequest;
import java.io.File;
import java.util.Map;@RestController
@RequestMapping(value={"/ocr"},method = {RequestMethod.POST,RequestMethod.GET})
public class OcrController {@RequestMapping("/ocrUpload")public String ocrUpload(@RequestParam("ocrFile") MultipartFile ocrFile, HttpServletRequest request) {try {// 检查文件是否为空if (ocrFile.isEmpty()) {return AjaxResult.Return(400, "上传的文件为空.");}// 获取上传文件的原始文件名String originalFileName = ocrFile.getOriginalFilename();if (originalFileName == null) {return AjaxResult.Return(400, "无法获取上传文件的原始文件名.");}// 获取上传文件的扩展名String fileExtension = OCRUtil.getFileExtension(originalFileName);if (!OCRUtil.isAllowedFormat(fileExtension)) {return "不支持的文件格式,仅允许上传 jpg、jpeg、png 文件";}// 创建临时文件File tempFile = File.createTempFile("upload_", null);ocrFile.transferTo(tempFile);// 获取临时文件的绝对路径String inputFilePath = tempFile.getAbsolutePath();// 图片判定或转换并输出结果Map<String, Object> map = OCRUtil.processImageFile(inputFilePath);if (!map.get("code").toString().equals("0")) {// 删除临时文件tempFile.delete();return AjaxResult.Return(400, map.get("msg").toString());}tempFile.delete();// 进行 OCR 识别return OCRUtil.performOCR(map.get("url").toString());} catch (Exception ex) {ex.printStackTrace();return AjaxResult.Return(400,"请求异常:"+ex.getMessage());}}}
4.5、设置语言包
TESS_DATA_URL=/usr/local/share/tessdata五、常见问题
5.1、Error: LSTM requested, but not present!! Loading tesseract.
在使用过程中,我们还遇到了 Error: LSTM requested, but not present!! Loading tesseract. 错误。该错误是由于请求使用 LSTM 引擎,但系统中未安装或配置该引擎导致的。解决方法包括检查并更新 Tesseract 版本(确保使用支持 LSTM 的版本,如 4.0 及以上),检查并下载 LSTM 数据文件并正确配置路径,以及检查代码中对 Tesseract 引擎模式的配置是否正确。
5.2、Not a JPEG file: starts with 0x89 0x50
这个错误信息表明程序在处理文件时预期该文件是 JPEG 格式,但实际检测到的文件头并非 JPEG 格式的文件头,而是 PNG 格式的文件头。
六、总结
通过对 Tesseract OCR 在 Java 中的应用及识别准确性优化的实践,我们发现 OCR 识别准确性受到多种因素的影响,包括图像预处理、Tesseract 配置等。在实际应用中,需要根据具体情况不断调整和优化,以达到更好的识别效果。同时,对于遇到的错误要及时排查和解决,确保 OCR 功能的正常运行。
通过以上内容便可轻轻松松完成图片转文字.是不是超级简单.有任何问题欢迎留言哦!!!
重点!重点!重点!
遇到问题不用怕不如来我的知识库找找看,也许有意想不到的收获!!!
易网时代-易库资源-易库教程:.NET开发、Java开发、PHP开发、SqlServer技术、MySQL技术-开发资料大全-易网时代-易库资源-易库教程 (escdns.com)