音视频之H.265/HEVC编解码并处理
H.265/HEVC系列文章:
1、音视频之H.265/HEVC编码框架及编码视频格式
2、音视频之H.265码流分析及解析
3、音视频之H.265/HEVC预测编码
4、音视频之H.265/HEVC变换编码
5、音视频之H.265/HEVC量化
6、音视频之H.265/HEVC环路后处理
7、音视频之H.265/HEVC熵编码
8、音视频之H.265/HEVC网络适配层
9、音视频之H.265/HEVC编解码并处理
新一代视频压缩标准 H.265/HEVC 在很大程度上是为了满足人们对于高分辨率视频的需求,而对于高清乃至超高清视频,分辨率达到了4kx2k或8kx4k,无论是从编码还是从解码的角度,其计算复杂度都是极高的。而为了提高H.265/HEVC的网络适应能力,其压缩性能与H.264/AVC 相比显著提高,相同条件下的码率可以降低50%,获得性能提升的代价就是编解码复杂度的大大提高。
与H.264/AVC相比,H.265/HEVC的复杂度主要体现在以下几点:H.265/HEVC 的帧内预测模式增多,H.265/HEVC中包含角度预测、DC预测、平面预测等35 种预测模式,远远超过了H.264/AVC 的 17 种模式使得模式选择的复杂度大大增加:H.265/HEVC的区域划分方式更加多样化,提出了树形划分结构,划分的单元大小更加多种多样,出现了非对称划分,运动补偿更加复杂;H.265/HEVC中增加了变换单元的概念,最大变换单元的大小由H.264/AVC中的8x8增大到现在的32x32,运算量更是不可同日而语。H.265/HEVC 标准下的编解码器,其复杂度将可能超过以前编解码器数十倍。
H.265/HEVC 对处理器的计算能力以及实时编解码都提出了很大的挑战,如此高的运算复杂度不能仅仅依赖于处理器计算能力的提升,在实际情况下,高性能处理器的成本是非常高昂的。随着处理器多核架构的发展,在多核环境下并行处理可以成倍地增加编解码速度,成为一种有效的解决方式。
一、视频编解码并行处理技术:
1、并行处理基本概念:
并行处理一般是指许多指令得以同时进行的处理模式。并行处理通常是将处理的过程分解成小部分,之后采用多个运算单元以并发方式加以解决。本章只讨论使用多个处理器的并行处理技术,其通常分为两种:功能并行和数据并行。下面结合视频编解码原理对这两种并行方式做简要介绍。
功能并行:
功能并行是指将应用程序划分成相互独立的功能模块,每个模块间可以并行地执行。这种并行方式也被称为流水线型并行,是将各个独立的模块划分给不同的运算单元,各个模块之间通过流的方式来进行数据交换和通信,最终再将各个单元串接在一起。功能并行充分利用了时间上的并行性来获得加速的效果,比较适用于硬件实现。
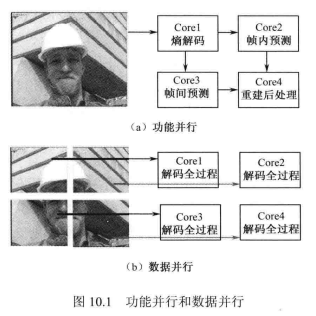
在视频编解码中,我们可以将编解码器划分为各个不同的模块,以解码为例,如图10.1(a)所示,各个模块映射到不同的运算单元,各自独立执行,完成不同的功能。由前面几章可以知道,H.265/HEVC的解码过程分为熵解码、反量化、反变换、帧内预测、帧间预测、去方块滤波和样点自适应补偿等。我们根据这些模块的相互联系和运作机制,可以对它们进行重新划分组合,从而实现功能并行。
功能并行的缺点也是很明显的。由于分配给不同运算单元的功能模块是不同的,因此很容易产生载荷失衡问题,有的运算单元的负载较轻,处理速度较快,而有的运算单元的负载较重,处理速度慢,总体上整个程序的运行效率就会降低。功能并行还需要在不同运算单元间进行数据通信,当数据量较大时,需要花费额外的资源来进行存储。另外,功能并行的扩展性较差,由于划分好的模块已经分配给不同的运算单元,在增加或减少运算单元时,需要对原有的模块进行重新划分和分配。
数据并行:
数据并行是将数据信息划分为相互独立的部分,每一部分交给不同的运算单元来执行,从而实现并行处理。这种方式下,不同运算单元上执行的程序是相同的,而且处理的是相互独立的数据信息,因此不需要进行运算单元间的通信,如图10.1(b)所示。
H.265/HEVC 中提供了适于进行数据并行处理的结构单元,如片和Tile,在不同的片和Tile中,数据信息是相互独立的,这样有利于将其分配给不同的运算单元来处理。对于比片和Tile小的划分单元,H.265/HEVC支持波前并行处理(Wavefront Parallel Processing,WPP),这是对于相互具有依赖关系的图像单元进行数据并行处理的方法。针对这种情况,需要通过适当的核间通信来消除数据单元之间的依赖关系,从而使得具有依赖关系的数据单元可以在不同的运算单元中进行处理。
对于数据并行,当数据块数目多于运算单元数目时,各个运算单元均处于持续运行状态,比较容易达到负载均衡。另外,数据并行具有非常好的扩展性,易于软件实现,当数据单元数目增多时,可以很容易地增加运算单元的数目来提升并行速率。
2、H.265/HEVC编解码并行处理方式:
考虑到 H.265/HEVC 标准的特点,在解码过程中,解码在Slice、Tile 以及 CTB行的起始处都有可能进行概率模型初始化,而对于不同的图像,初始化的位置都不相同。由于熵解码的依赖关系与后续解码模块的依赖关系不一致,如果在并行过程中不加以区分,会给整个并行解码带来很多麻烦,解码效率大大降低。因此H.265/HEVC的解码过程可以分成两个串行的功能模块,即熵解码和并行解码两部分,熵解码部分主要进行熵解码,而并行解码部分主要进行预测、反变换、反量化和去方块滤波等。两个功能模块组成串行的一级流水线,而分别在两个模块内部,针对不同的子数据块进行数据并行。这样一来,H.265/HEVC并行解码模型混合了功能并行和数据并行两种方式。H.265/HEVC解码器混合并行模型如图 10.2所示。
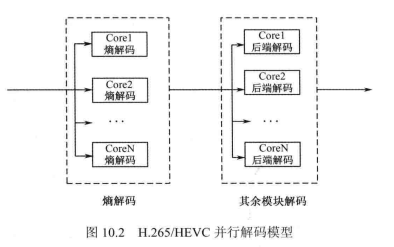
解码器中功能模块间的并行与通用的功能并行相似,而数据并行需要根据视频编码的特点考虑编码单元间的数据依赖关系。这里主要介绍H.265/HEVC 编解码器的数据并行技术,包括基于 Tile 的并行和波前并行两种方式。在进行基于 Tile 的并行时,由于Tile 的相互独立性,不需要考虑它们之间的相互依赖关系,而在进行波前并行处理时,数据间的相互依赖关系就显得尤为重要了。
3、 H.265/HEVC 编码单元数据依赖关系
针对并行处理的编码单元,必须消除数据间依赖关系的影响。如波前并行处理过程中所用到的数据块并不是相互独立的,它们之间存在相互参考的关系,在并行解码过程中,解码当前块所需要参考的数据仍未解码,那么当前块的解码也就无法展开,因此,波前并行处理必须在满足各个数据单元(CTB)之间依赖关系的前提下进行。
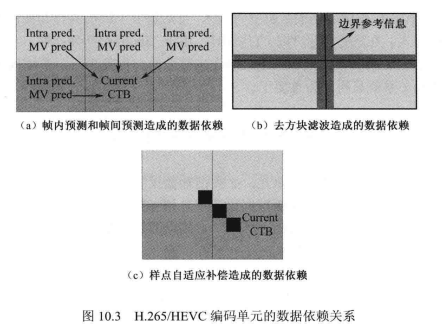
H.265/HEVC 编码单元的数据依赖关系主要由帧内预测、帧间预测、去方块滤波以及样点自适应补偿产生,其具体依赖关系如下。
- 帧内预测:当前CTB有可能会依赖左方、左上方、上方、右上方的 CTB 的像素信息和模式信息。
- 帧间预测:当前CTB块的运动矢量有可能会需要由左方、左上方、上方、右上方的CTB预测得到。如图10.3(a)所示,对于帧内预测和帧间预测部分,要进行并行处理,需要在解码当前CTB块时保证左方、左上方、上方、右上方的 CTB 块已经解码完成。而对于去方块滤波需要保证左方和上方的块已经解码完成。
- 去方块滤波:对当前CTB块进行边界滤波的过程中需要参考左方CTB块的左侧四列像素、上方CTB块的底部四行像素对边界进行分析。如图10.3(b)所示,在对图中垂直边界滤波时,需要保证左方的块已经解码完成,而在对图中水平边界滤波时,需要保证边界上方的块已经解码完成。
- 样点自适应补偿(SAO):SAO 的边缘补偿有0°、45°、90°、135°四种情况,因此对当前CTB块进行补偿时,其周围的8个块都有可能被参考,依赖关系较为复杂。如图10.3(c)所示,以135° SAO为例,对当前CTB左上角的像素进行样点自适应补偿时,需要参考左上方CTB右下角的像素值。
二、H.265/HEVC标准中并行处理新技术:
H.265/HEVC标准中增加了很多新的特性和句法结构用以实现并行处理,如 Tile、依赖片、波前并行处理等,使得并行处理成为H.265/HEVC的重要特征。
1、Tile:
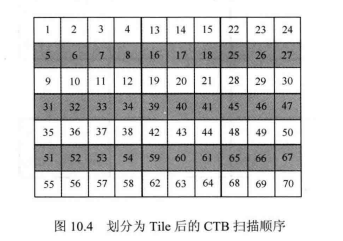
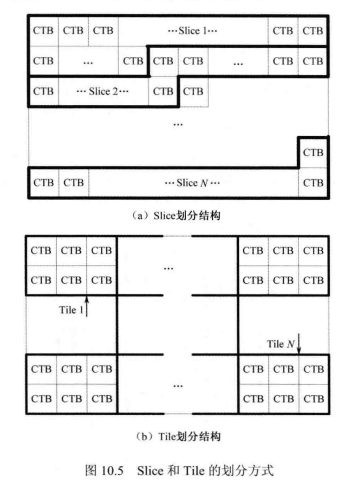
Tile 是 H.265/HEVC 中新增加的数据单元,它将原图像划分为一个个独立的矩形区域,各个矩形区域独立进行编码,不会进行相互参考。Tile的引入主要是为了进行并行处理,而非同步和纠错。Tile改变了原本图像中CTB的扫描顺序,Tile中的CTB是根据光栅扫描顺序进行扫描的,而这些 Tile 也是根据光栅扫描顺序扫描的。如图10.4所示,第一个 Tile中的12个CTB是按照光栅扫描顺序扫描的,而第二个Tile也按照光栅扫描顺序排列在第一个 Tile 后面。
类似于 Slice,不同的 Tile 之间是相互独立的,但与 Slice 相比,Tile具有更好的编码效率。因为从划分方式上来看,Tile所包含的像素与Slice包含的像素相比具有更高的相关性。如图10.5(a)所示,Slice一般横向跨度较大,而且并不一定是规则的,同一个Slice 中的块之间的空间距离可能会很大,相关性较低。如图10.5(b)所示,Tile的划分比Slice要规则,块与块之间的空间跨度一般不会很大,相关性较强。从空间结构上来看,一个Slice可能会包含多个Tile,一个Tile也可能会包含多个Slice,但绝对不会出现一个 Slice 跨越 Tile 边界的情况,同样也不会出现一个Tile跨越 Slice 边界的情况。当多个Tile位于同一个Slice 当中时它们可以共用同一个 Slice 头,从而可以节省码率。
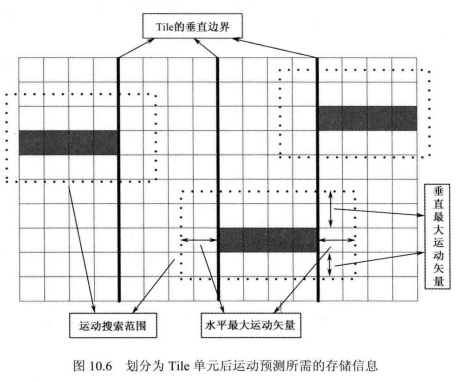
Tile 的引入减少了由于运动预测所需要的缓冲数量。通常来说,在对当前CTB进行帧间预测时,需要为运动补偿存储相应的参考信息。这些数据会一直存在于解码器缓存中,直到需要参考它的区域解码完成。如图10.6所示,在引入Tile之前,由于光栅扫描的原因,解码器按顺序解码,当前CTB所需要的参考块之前的CTB块都需要依次进行存储,所需要存储的像素点数为PicWx(2xSRy+CTBH-1)+2xSRx。其中PicW为图像宽度,CTBH为CTB的高度,SRx为最大水平运动失量,SRy为最大垂直运动矢量。而在引入Tile 之后,由于Tile改变了原有的光栅扫描顺序,很多原本需要依次存储的CTB现在不需要存储了,现在运动估计所需要存储的像素点数大约为(TileW+2xSRx)x(2xSRy+CTBH)其中 TileW为 Tile单元的宽度。大多数情况下,(TileW+2xSRx)要小于PicW,尤其是对于高清视频序列。
Tile的引入不是没有代价的。类似于Slice,率失真性能会随着Tile数目的增加而降低。因为Tile单元的划分使得 Tile 边界附近信息的相关性被破坏了,而且CABAC编码也会在Tile边界处进行概率型的更新,这些都降低了 H.265/HEVC 的编码效率。
2、波前并行处理:
Slice 和 Tile 都有利于H.265/HEVC 并行的实现,但是这两种数据结构都破坏了图像原有的在Slice和Tile边界上的相关性,造成了一定的性能下降。H.265/HEVC引入了波前并行处理算法,它允许多行CTB可以同时进行处理,但是后一行的处理要比前一行滞后两个CTB,这样可以在不破坏正常相关性的前提下进行并行解码,保证了原始性能。
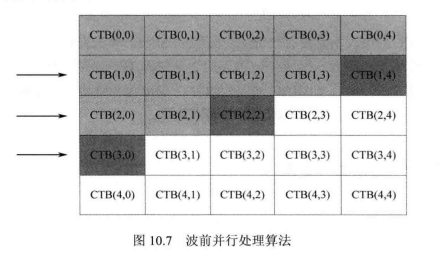
在正常的解码顺序下,每一幅图像或者Slice的CTB是按照光栅扫描顺序从左到右,从上到下进行的。在波前并行处理中,需要将不同的CTB 行放入不同的运算单元进行处理,因此需要对不同核中CTB的编码顺序进行协调。如图10.7所示,根据 H.265/HEVC的数据依赖关系可知,在 CTB(1,3)解码完成后,CTB(2,2)所需的依赖信息都已经解码完成,同理,在 CTB(2,1)解码完成后,CTB(3,0)所需的解码信息也都已经解码完成。因此 CTB(1,4)、CTB(2,2)和CTB(3,0)3个CTB块可以分别交给3个不同的运算单元同时进行解码。以上就是波前并行处理的主要方法,在该方法中,原本的光栅扫描顺序没有改变,CTB的相互依赖关系也得以保留,只是由于并行处理,不同行的CTB的解码顺序有所改变。
同时H.265/HEVC中还加入了entropy_coding_sync_enabled_flag这语法元素,当其值为1时,CABAC编码会在每一行的开头处进行概率模型的更新,这样一来,CABAC熵解码也可以使用波前并行算法进行实现。但是当其值为0时,CABAC熵编码只能在Slice和Tile的边界处进行更新,由于不同 CTB行的前后依赖关系,此时的CABAC解码不能采用波前并行处理。
3、依赖片:
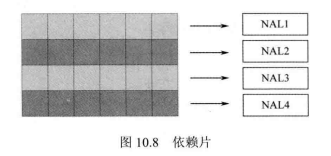
H.265/HEVC中增加了依赖片这一数据单元,它将一个完整的Slice划分为不同的区域,分别封装到不同的独立NAL单元当中,而这些区域有可能是相互关联的。依赖片的引入同样有利于并行处理的实现,尤其是在解码端。片通常是相互独立的数据单元,而依赖片则允许是相互参考的。在划分的时候,可以将一段用于波前并行处理的CTB行数据或一个 Tile 打包到一个单独的NAL单元当中,这样一个单元被称为一个依赖片。如图10.8所示,若采用波前并行处理算法,图中的4行CTB都可以分别交给不同的运算单元进行处理,就可以将它们分别封装到4个不同的NAL单元当中。由于依赖片会参考其他片,如图中的NAL2,其中的数据会参考NAL1中的数据,它们具有一定的依赖性,所以要解码当前依赖片必须等待其参考的片先进行解码,但不用全部解码完,只需要参考片完成部分解码,当前依赖片的解码便可以开始,这与波前并行处理算法是很相似的。
在并行结构上来看,这样做对于并行速率并没有什么改变,可能还会因为NAL单元数的增多使得编码效率下降。但是从网络传输方面考虑依赖片降低了NAL单元的大小,利用依赖片进行并行处理可以有效减少解码时延。
三、 H.265/HEVC编解码并行策略:
视频序列是由一个或多个图像组GOP组成的,GOP通常被用来进行视频同步,它们是相互独立的,没有任何相关性。每个GOP包含多幅图像,图像根据其特点又可以分为I图像、P图像和B图像。从图像级向下划分又可以分为Slice 和Tile,Slice 和 Tile 作为两种划分单元可以将一幅图像划分为一个个相互独立的图像单元,而Slice和Tile都是由多个CTB组成的。最后,每个CTB又包含了多个像素。从H.265/HEVC的数据结构来看,在每一个层级上都可以进行并行处理,每一个层级上的并行都有其各自的优缺点和并行策略。接下来我们将对这些不同层级上的并行策略进行讨论和分析。
1、GOP级并行:
在H.265/HEVC中GOP级的并行是可行的。我们可以将一个视频序列中的不同GOP交给不同的运算单元来并行处理。如图10.9所示,线程T1、T2和T3分别对GOP1、GOP2和GOP3 进行并行处理,T0 负责统筹控制。当某个线程完成对其当前GOP的处理后发送请求至T0,T0会根据各线程的完成情况为其分配下一个GOP,这样的并行过程持续到整个视频序列的结束。
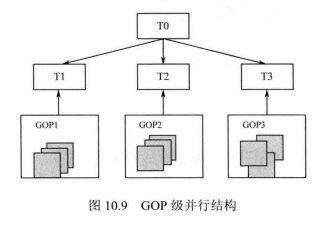
GOP的数据量是庞大的,因此GOP级的并行要求每个运算单元都有较多的存储资源。如果这些运算单元使用的是公共缓存,那么GOP级的并行将会变得十分低效,因为大量数据的频繁读入与读取是非常耗费时间和资源的。另外,GOP级并行较之其他并行方式,其解码时延是较高的,因此这种并行方式更适用于编码端。
2、图像级并行:
在图像级数据结构中,由于运动预测的存在,不同的图像之间会有时域上的依赖性,但这种依赖性并非是不可避免的。一个视频序列中通常包含I、P、B 3种数据图像,如图10.10所示,由于I图像和P图像都有可能会用作参考,后续图像要进行解码必须等待它们的解码完成,因此通常对这些图像不做并行考虑。
对于B图像,图中将B图像分成了3个等级、
和
;,其中
会用作
和
的参考图像,而
会作为
的参考图像,但是同级的B图像之间不会相互参考,高级的B图像也不会作为低级B图像的参考图像,更不会作为I图像和P图像的参考图像,这就意味着同级的B图像之间是相互独立的。这就为图像级的并行处理提供了可能,我们可以将同级的B图像分别交给不同的运算单元来进行处理,当然前提是更低级的B图像已经解码完成,当前级别B图像解码的先决条件已经满足。
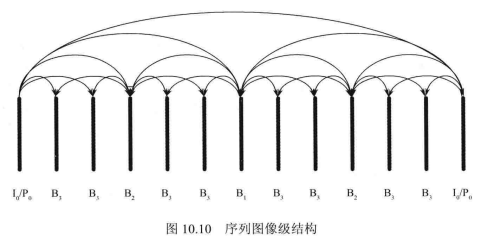
这样的实现方式十分受限于B图像的数量,当P图像之间的B图像数目较少时,可以并行的线程数目也就很少,影响了并行的效率。另外,由于B图像也会被用做参考,不同级别的B图像之间不能进行并行解码,并行只能在同级 B图像之间进行,这在更大程度上限制了并行的效率。
3、Slice级并行:
虽然 Slice 通常被用来实现数据同步、差错控制和随机接入等功能,但是由于Slice的相互独立性,Slice级的并行处理是可行的。而且在H.265/HEVC中,CABAC编码在每个Slice的结尾都会对上下文模型进行更新,这就允许不同的 Slice 的熵编码部分并行进行。除了编码部分,不同的 Slice 数据也可以被送给不同的运算单元进行处理而不用考虑它们的相关性。如图10.11所示,图像中存在3个相互独立的Slice,分别送给3个运算单元来进行并行处理。
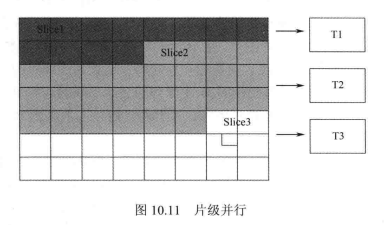
Slice 级并行的缺点是比较明显的。第一,由于每幅图像的 Slice 数目是由编码器决定的,在解码端,并行的数量是难以确定的;第二,虽然Slice是完全独立的,但在进行去方块滤波时,有可能会跨越Slice的边界,这降低了并行的扩展性;第三,由于Slice的内容可能会相差较大,这会引起并行过程中的负载失衡问题;第四,也是最重要的,当Slice数目较多时,Slice级并行可能会造成码率成倍增加,这在很多实际的码流环境下是不允许的。
4、Tile级并行:
Tile 将图像划分为一个个独立的矩形CTB组。Tile 的数量以及它们的位置和大小通常会随图像的变化而变化。对于熵解码和预测,不同的Tile 数据是相互独立的,而且CABAC熵解码也会在每个Tile 的结尾进行上下文模型的更新,这些都有利于实现Tile 级并行。但是去方块滤波和样点自适应补偿仍然有可能会跨Tile边界进行,需要额外的处理来消除这种操作所造成的 Tile 间的依赖性。
Tile 改变了原有的CTB的扫描顺序,CTB的光栅扫描顺序会受到Tile边界的约束,这样的数据结构不利于在单核上实现 H.265/HEVC 的编/解码过程,但有利于多核并行处理的实现。
由于 Tile 间的独立性,Tile 级通常将整个 Tile 分配给一个运算单元,因此不需要 CTB级的核间通信,但是如果去方块滤波跨越 Tile 边界进行,就需要进行核间通信来消除Tile间的依赖性。如图10.12所示,假设图中有左右两个 Tile,将这两个 Tile 分别交给两个不同的运算单元进行并行处理。由于去方块滤波跨越Tile边界进行,那么在滤除中间那条垂直的边界时会出现右边 Tile 参考左边Tile的情况。这时我们需要进行核间通信,来协调两个运算单元的解码进程。比如,当右边Tile 解码到第 21个CTB时需要查看左边Tile的第8个CTB是否解码完成,只有当第8个CTB解码完成后,第21个CTB才能继续进行解码。通常情况下这种核间通信是有必要的,因为如果不跨越Tile 边界进行去方块滤波,就有可能会造成视觉上的块效应。
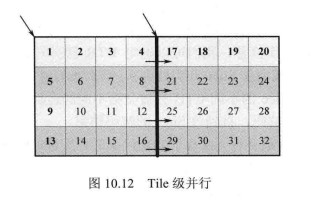
Tile 级并行同样具有一些 Slice 级并行的缺点。由于 Tile 单元内容的差异性,负载失衡的问题仍然有可能会发生。而且,当并行处理的Tile数目较多时,码率飙升问题仍然是不可避免的。
5、CTB级并行:
H.265/HEVC中采用了波前并行处理(WPP)算法来进行CTB级的并行。另外,对于CABAC熵解码,当entropy_coding_sync_enabled_flag为1时,CABAC上下文模型会在每一行的结尾处进行更新,这使得编码和熵解码的 CTB 级并行成为可能。当进行波前并行处理时,多行CTB被分别送到不同的运算单元中进行处理,但是由于相邻CTB之间的依赖性,这些运算单元不能同时开始运行。除解码第一行CTB的线程外,每一个线程都要比上一个线程落后两个CTB进行解码,这也就意味着所有的运算单元不可能同时结束。这会造成并行效率的降低,尤其是当运算单元数较多时更为明显。
尽管在线程数较多时,CTB级并行的效率有所降低,但CTB级并行处理相对于其他并行方式还是有很多优点的。首先,CTB级并行有较好的扩展性。随着图像分辨率的增加,CTB级并行的线程数也可以很方便地增加。其次,相对于其他层级的并行方式,CTB级并行可以更好地实现负载均衡。由于分配给各个运算单元的数据信息量是较少的,因此各运算单元的运算时间不会有太大差异,因此很容易实现负载均衡。
然而CTB级的并行也存在一些缺点。首先是解码的上下文模型更新问题。在进行熵解码之前,CTB单元是无法区分的,因此必须先进行熵解码,再进行之后的图像处理。但是CABAC解码的概率模型需要参考从上一个更新点以后所有的码流信息,而我们无法保证在每一行CTB的开头都有一个更新点。这样波前并行处理算法就无法在CABAC熵解码部分实现,我们只能分别进行熵解码和并行处理。根据CABAC上下文模型的更新位置,我们可以确定CTB级并行的起始位置。如果CABAC上下文模型在Slice开头处更新,那么我们就可以将该Slice送入并行过程。该Slice的不同CTB行被交给不同的运算单元,利用波前并行处理算法进行解码,直到该Slice的解码结束。
其次是CTB级并行无法保证输出码率的稳定性。根据波前并行处理算法,在并行处理开始时,满足依赖关系可以进行解码的CTB数目是较少的,码率较低。随着解码的进行,越来越多的运算单元启动,码率开始增大,直到达到最大值。在解码达到尾声时,解码运算单元又会逐个终止,这样码率又会逐渐减少到零。这样一来,CTB级并行处理就无法达到恒定的码率,而且还会造成并行效率的下降。
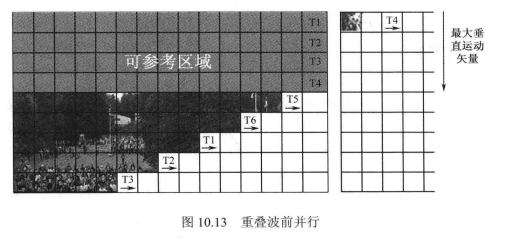
针对上述问题,人们提出了一种叫作重叠波前并行的方法,来减少并行过程中由于线程数增加和减少所带来的并行效率的下降。在最初的波前并行算法当中,如果一个运算单元处理完一行CTB之后,在当前图像中没有剩余的 CTB行可以交给它进行处理,如图10.13中的线程T4,那么在整幅图像解码完成之前,该运算单元会一直处于等待状态。之后,对于下一幅图像,波前并行算法会重新开始。而在重叠波前并行算法中,在图像的运动矢量足够小的情况下,一个运算单元处理完一行CTB之后,如果当前图像中没有剩余的CTB行可以交给它进行处理,该运算单元可以直接开始对下一幅图像的处理而不用等待整幅图像解码的完成。如图10.13所示,共有6个运算单元来对当前图像进行波前并行处理,当线程T4完成对分配给它的CTB行的解码后,会发现在当前图像中已没有满足条件可以分配给它,于是线程 T4直接转入下幅图像进行解码。但是该算法的前提是运动矢量要足够小,对于前一幅图像,前4行CTB是解码完成了的,因此它们可以作为后幅图像的参考,后幅图像的最大运动矢量不能超出这4行CTB的范围,否则可能会导致后幅图像解码时缺少参考信息。重叠波前并行处理不能完全使得并行解码时的线程数恒定,但它可以较为有效地解决由于线程数增加和减少所带来的并行效率下降问题。
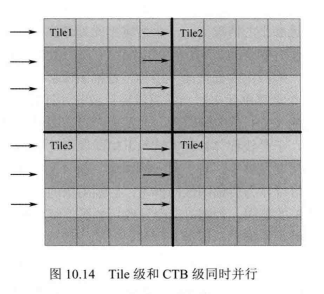
从数据结构上来看,CTB 级并行和Tile 级并行是可以同时实现的,如图10.14所示,可以将一幅图像划分为4个Tile,每个 Tile 交给一组运算单元来处理,而每组运算单元按照CTB级并行的方式可以并行处理3行CTB,这在理论上来说比单纯进行CTB级并行或Tile级并行效率要高。但是同时实现将会造成线程数大幅增加,复杂度和码率都会急剧上升。过多的运算单元之间进行通信将会占用较多的资源,而且,就每个运算单元来看,其所分到的数据信息量将会很少,负载均衡难以实现,利用率降低。因此H.265/HEVC中没有提出CTB级和Tile 级同时并行的方案。
参考资料:
《新一代高效视频编码 H.265/HEVC 原理、标准与实现》——万帅 杨付正 编著