Diffusion Model与视频超分(2):解读字节开源视频增强模型SeedVR2
前言:在SeedVR之后,字节又开源了SeedVR2。相比于上一代的模型,在速度和性能上都有了非常大的提升,特别是单步的生成技术,极大降低了计算成本。本篇博客从论文和代码角度讲解《SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training》
目录
背景和动机
方法
扩散对抗后训练
自适应窗口注意力
渐进式蒸馏
训练细节
实验
实验设置
定量结果
定性结果
消融实验
背景和动机
之前方法主要存在的问题:
- 高计算成本:基于扩散模型的视频修复在视觉质量上表现出色,但推理阶段计算开销巨大,限制了其实用性。
- 扩展困难:现有一步图像修复蒸馏方法难以直接扩展到视频修复任务,尤其是在处理高分辨率、真实场景视频时面临较大挑战。
- 窗口注意力的不一致问题:在高分辨率视频修复中,使用固定窗口大小的注意力机制容易导致窗口不一致,影响修复质量。
方法
扩散对抗后训练
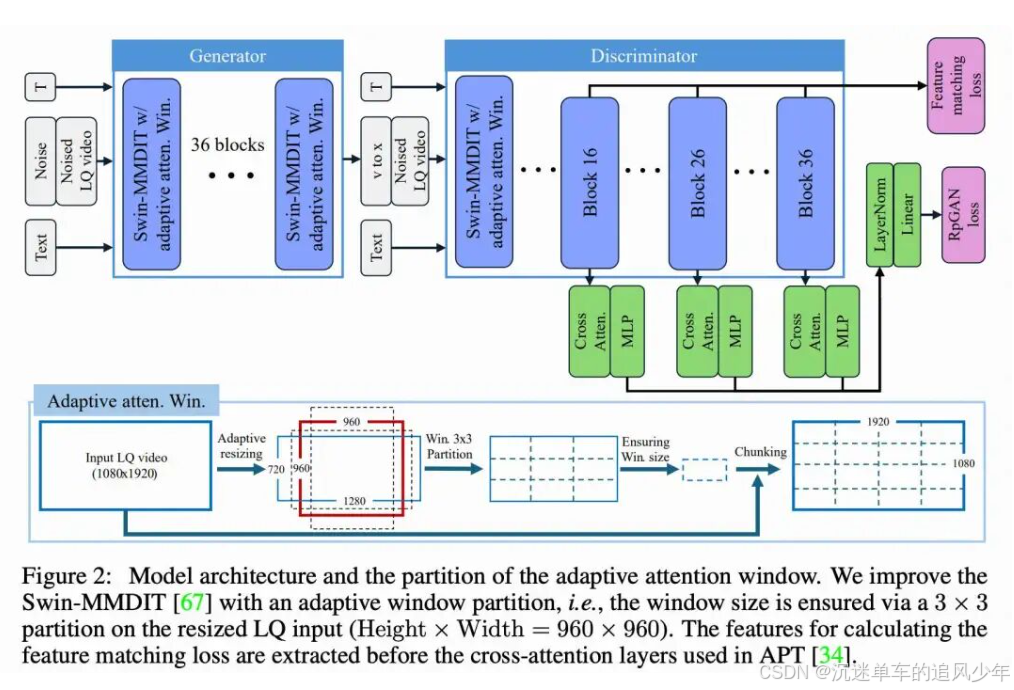
扩散对抗后训练(Diffusion Adversarial Post-Training, APT)是一种扩散加速方法,它将多步扩散模型转换为一步生成器。APT 主要包括两个训练阶段,即确定性蒸馏和对抗式后训练(APT)。在确定性蒸馏阶段,首先按照离散时间一致性蒸馏方法并使用均方误差损失训练一个蒸馏模型。教师模型使用恒定的无分类器引导(classifier-free guidance)系数 7.5 和预定义的负提示生成蒸馏监督信号。至于对抗训练,判别器首先由预训练的扩散网络初始化,然后引入仅包含交叉注意力的 Transformer 块来生成用于损失计算的 logits。为了稳定对抗训练并避免高阶梯度计算,APT 提出了近似的 R1 损失来正则化判别器,最终的判别器损失是非饱和 GAN 损失与近似 R1 损失的组合。本文方法采用了与 APT 相似的网络架构,其中生成器和判别器都是扩散 Transformer,如下图 2 所示。
自适应窗口注意力
为了提升窗口注意力在处理任意尺寸高分辨率输入时的鲁棒性,提出了一种自适应窗口注意力机制,使得窗口大小可以根据输入分辨率动态调整,如上图 2 所示。
为了进一步提升高分辨率输入在测试阶段的鲁棒性,引入了一种分辨率一致的窗口划分策略。这种自适应划分策略增强了训练与测试配置之间的一致性,并显著缓解了高分辨率预测中的边界伪影,如下图 4 所示。

渐进式蒸馏
规模的对抗训练具有挑战性。得益于 VR 中的低质量条件,我们在从对抗训练开始时未观察到模式崩溃(mode collapse)现象。然而,在训练数千次迭代后仍可观察到不良伪影,表明训练不稳定性问题仍然存在。我们从以下两个方面提升训练稳定性,即蒸馏和损失函数。
渐进式蒸馏。直接将对抗训练应用于从初始多步模型获得一步模型,可能因初始模型与目标模型之间的巨大差距而削弱模型的恢复能力。采用渐进式蒸馏来缓解这一问题。具体而言,我们从使用 64 个采样步数的 SeedVR 初始化的教师模型开始,以步长为 2 渐进地将学生模型蒸馏为一步模型。每一次蒸馏过程大约进行 10K 次迭代,使用简单的均方误差损失。还在对抗训练中逐步增加训练数据的时间长度,从图像过渡到具有不同帧数的视频片段,从而实现对不同长度视频(包括图像)的鲁棒 VR 性能。得益于这种训练策略,进一步从原始的 7B 模型蒸馏出一个 3B 模型,在模型尺寸减半的情况下实现了相当的性能。
损失改进。受 R3GAN启发,我们首先将 APT 中使用的非饱和 GAN 损失替换为 RpGAN 损失,以避免潜在的模式丢失问题。进一步引入近似的 R2 正则化,以惩罚判别器 在伪造数据上的梯度范数,同时支持现代深度学习软件栈:
训练细节
实现细节。 在 72 张 NVIDIA H100-80G GPU 上使用 sequence parallel 和 data parallel,每个 batch 约包含 100 帧 720p 视频帧来训练 SeedVR2。每个训练阶段大约耗时一天。首先从头训练一个 7B 的 SeedVR 模型,遵循本文中的新注意力设计。然后,从 7B SeedVR 模型初始化模型参数,并遵循前文中讨论的训练策略来训练本文 SeedVR2 模型。对于对抗训练,主要遵循 APT [34] 中的训练设置。参照 UAV合成了约 1000 万张图像对和 500 万段视频对用于训练。
实验
实验设置
按照先前工作 [97],评估合成基准,包括 SPMCS、UDM10、REDS30和 YouHQ40,采用与训练中相同的降质设置。测试分辨率为 720p,放大因子为 4。此外,还在常用的真实世界数据集(VideoLQ)和自采集的 AIGC 数据集(AIGC28)上评估性能,AIGC28 包含 28 个具有不同分辨率和场景的 AI 生成视频。使用一系列指标来评估帧级和整体视频质量。对于合成配对数据集,采用全参考指标,包括 PSNR、SSIM、LPIPS和 DISTS。对于真实世界和 AI 生成内容(AIGC)的测试数据,由于缺乏真值,完全依赖无参考指标,即 NIQE、CLIP-IQA、MUSIQ 和 DOVER。为确保测试效率,最大输出分辨率限制为 1080p,时长保持不变。
定量结果
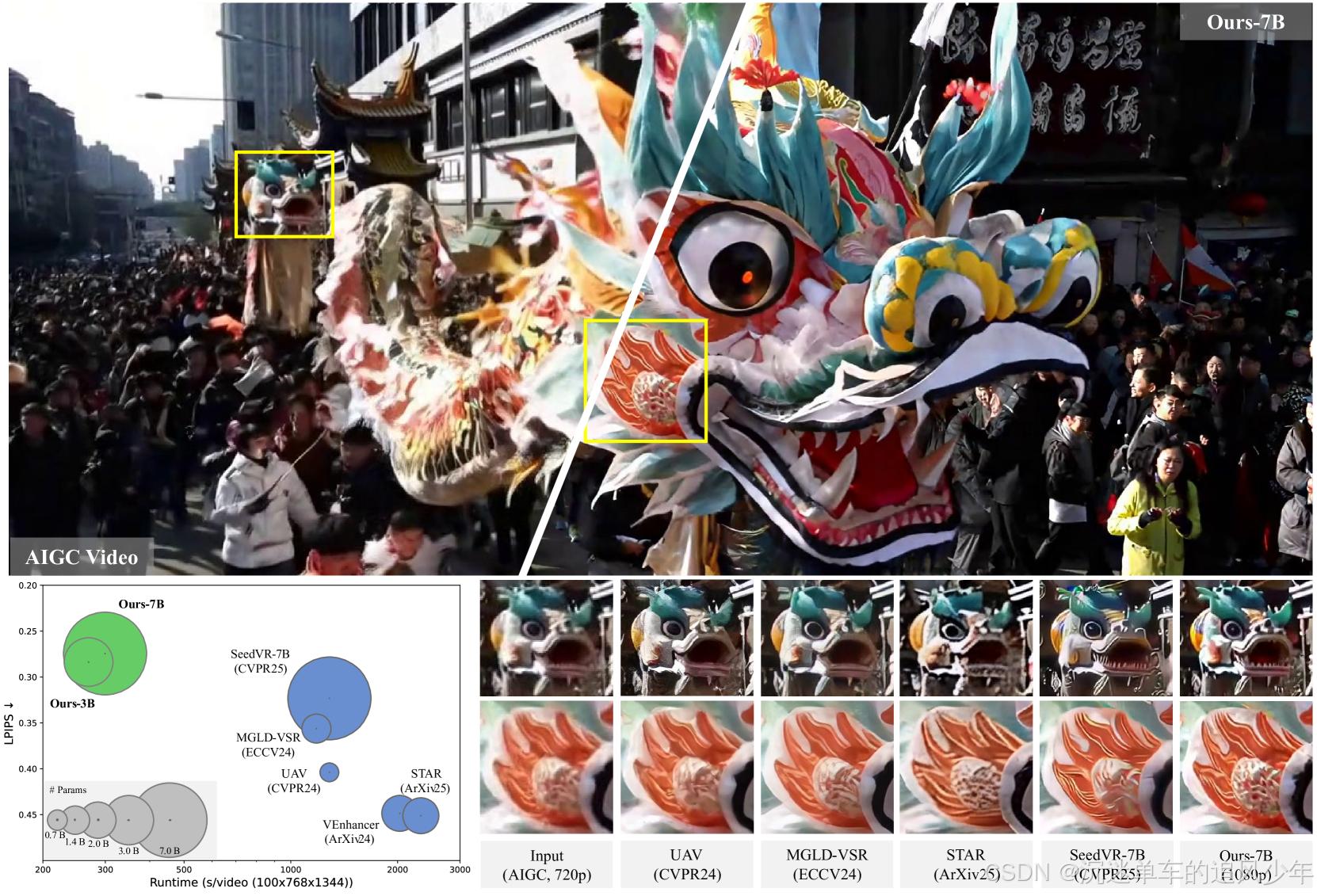
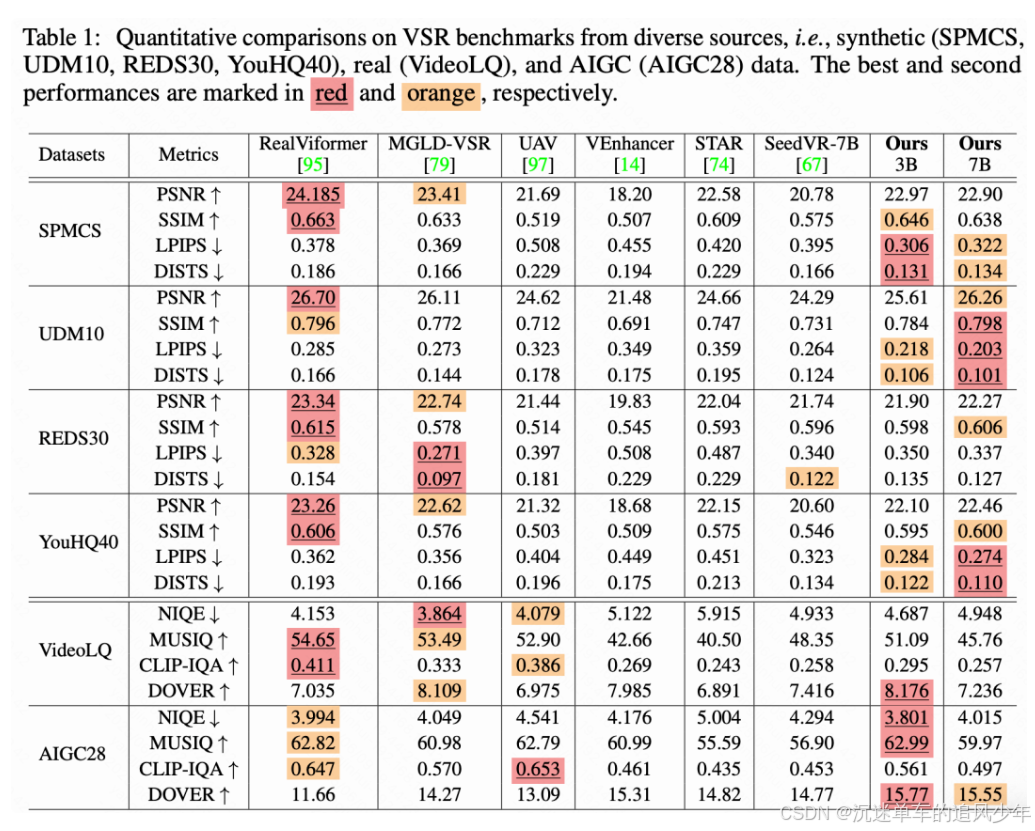
定量比较。 我们将本文方法与所有最新的真实世界视频修复方法进行了比较。对于基于扩散的方法,如[14, 67, 74, 79, 97],采用了 50 步采样,并使用小波颜色修正后处理,其余设置保持官方默认。如下表 1 所示,本文方法在合成基准 SPMCS、UDM10 和 YouHQ40 上,在感知指标如 LPIPS 和 DISTS 上表现出优越性能。需要注意的是,RealViformer和 MGLD-VSR在训练数据中包含了 REDS,因此在相应的测试集上表现较好。对于真实世界基准,本文方法在 VideoLQ 上与其他基于扩散的方法表现相当,并在 AIGC28 上获得了最高的 NIQE、MUSIQ 和 DOVER 分数,展示了我们方法的有效性。
定性结果
定性比较。 如多个先前研究[2, 12, 84, 86] 所观察到的,现有的图像和视频质量评估指标并不能完全与人类感知对齐。例如,MUSIQ 和 CLIP-IQA等无参考指标倾向于偏好锐利的结果,但可能忽略细节质量。我们注意到,在高分辨率(如 1080p)下,这种现象更加明显。如下图 3 所示,尽管本文方法在 VideoLQ 上的指标性能并不占优,但我们方法生成的结果与 SeedVR相当,并在很大程度上优于其他基线方法。

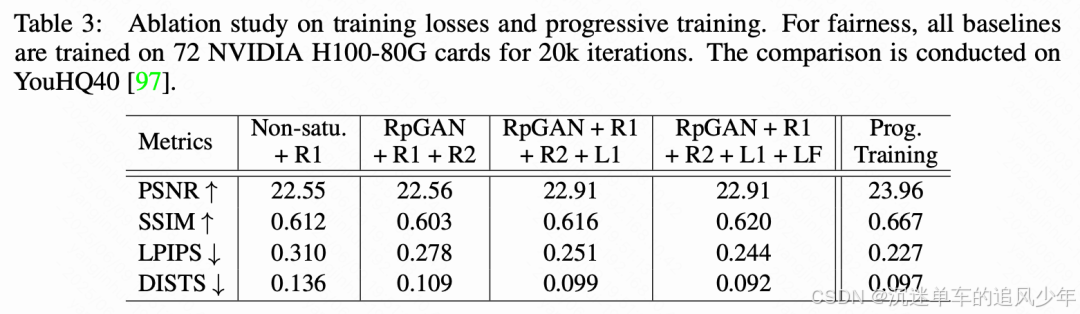
消融实验
自适应窗口注意力的效果。 首先验证所提出的自适应窗口注意力的有效性。我们分别使用预定义大小的窗口注意力和所提出的自适应窗口注意力训练模型。两个模型在相同训练设置下训练 20k 次迭代。如上图 4 所示,在生成高分辨率(例如 1080p)结果时,使用预定义大小窗口注意力会出现窗口边界不一致的问题。我们推测,这种缺陷表明模型在处理重叠窗口时能力有限,这与窗口大小设置不当相对于训练分辨率有关。具体来说,在下采样因子为 8 的压缩隐空间变量上应用 的窗口,使得模型在训练中很少遇到窗口重叠的情况,尤其是在 720p 的训练对上。此外,我们发现使用 RoPE embeddings的扩散 Transformer 在各种分辨率下表现更稳健,前提是在多种尺寸数据上进行训练。转而使用大多为固定窗口大小的窗口注意力 [67] 可能会削弱在其他窗口大小(如上图 4 中边界附近的可变大小窗口)上的泛化能力。我们展示了所提出的自适应窗口注意力可以通过消除上述不良情况显著提升模型鲁棒性。
损失函数与渐进式蒸馏的效果。 由于其不稳定性,训练大规模 GAN 具有挑战性。我们验证了方法中使用的各种损失的重要性。我们在相同设置下,用不同的损失组合训练每个基线模型 20k 次迭代。如表 3 所示,与 APT中使用的 vanilla 损失(即非饱和 GAN 损失+ )相比,使用 RpGAN、 和 损失训练的模型在感知指标如 LPIPS 和 DISTS 上表现出显著提升。我们还观察到训练过程更加稳定,避免了长时间训练后在 APT 设置下出现的模式崩溃现象。此外,引入 L1 损失和所提出的特征匹配损失都提升了指标表现,表明这些损失在修复任务中的重要性。在实际操作中,注意到较大的 L1 损失和特征匹配损失权重提高了保真度,但相比于为 GAN 损失分配更大权重,可能会导致结果略微过于平滑。这一观察与感知-失真理论一致。因此,在最终模型中,将 L1 损失和特征匹配损失的权重降低为 0.1,以获得更好的视觉质量,如前文所述。最后,如下表 3 所示,采用渐进式蒸馏对于维持强大的修复能力是必要的,这是可以预期的,因为蒸馏有效地缩小了初始模型与一步对抗训练模型之间的差距。