NoUniqueKey问题和Regular join介绍
问题背景
在flink任务中,遇到了 NoUniqueKey Join的情况,导致了数据膨胀,和下游结果与数据库数据不一致问题
那NoUniqueKey Join为什么会导致问题呢,下面是其中一种场景示例:
为什么会出现 NoUniqueKey :原因有很多,较为常见的是下方示例,我们通常指使用主键作为pk,而往往业务场景使用的是唯一建进行关联和查询,所以pk就丢了(疑问:flink自身不可以透传pk吗),进行关联时就变成了NoUniqueKey
怎么解决(以下方场景示例):
- 查询字段带有 pk 字段
- 提前基于关联字段做group
- 将pk字段改为 left_code
上诉3中时通用方案,尤其针对下面这个常见案列,具体原因还要具体分析
示例
CREATE TABLE left_table (`left_id` BIGINT COMMENT '自增主键',`left_code` STRING COMMENT '唯一建',`left_code` STRING COMMENT 'left_table唯一建',`left_created_at` TIMESTAMP ,`left_updated_at` TIMESTAMP ,PRIMARY KEY (`left_id`) NOT ENFORCED
) WITH (
);CREATE TABLE right_table (`right_id` INT ,`right_code` STRING COMMENT 'left_table唯一建',`left_code` STRING COMMENT 'left_table唯一建',`right_state` STRING COMMENT '状态',`right_created_at` TIMESTAMP COMMENT '创建时间',`right_updated_at` TIMESTAMP COMMENT '更新时间',right_proc_time as proctime(),PRIMARY KEY (`right_id`) NOT ENFORCED
) WITH (
);-- 定义输出表,省略
INSERT INTO print_table
SELECTleft.left_code,left.left_created_at,left.left_updated_at,right.right_code,right.right_created_at,right.right_updated_at
FROM left_table left
JOIN right_table right
ON left.left_code = right.right_code
;它的执行计划中JOIN是:
leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey]Regular join 简单介绍
关联逻辑
核心类org.apache.flink.table.runtime.operators.join.stream.StreamingJoinOperator
private void processElement(RowData input,JoinRecordStateView inputSideStateView,JoinRecordStateView otherSideStateView,boolean inputIsLeft)throws Exception {boolean inputIsOuter = inputIsLeft ? leftIsOuter : rightIsOuter;boolean otherIsOuter = inputIsLeft ? rightIsOuter : leftIsOuter;boolean isAccumulateMsg = RowDataUtil.isAccumulateMsg(input);RowKind inputRowKind = input.getRowKind();input.setRowKind(RowKind.INSERT); // erase RowKind for later state updatingAssociatedRecords associatedRecords =AssociatedRecords.of(input, inputIsLeft, otherSideStateView, joinCondition);if (isAccumulateMsg) { // record is accumulateif (inputIsOuter) { // input side is outerOuterJoinRecordStateView inputSideOuterStateView =(OuterJoinRecordStateView) inputSideStateView;if (associatedRecords.isEmpty()) { // there is no matched rows on the other side// send +I[record+null]outRow.setRowKind(RowKind.INSERT);outputNullPadding(input, inputIsLeft);// state.add(record, 0)inputSideOuterStateView.addRecord(input, 0);} else { // there are matched rows on the other sideif (otherIsOuter) { // other side is outerOuterJoinRecordStateView otherSideOuterStateView =(OuterJoinRecordStateView) otherSideStateView;for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) {RowData other = outerRecord.record;// if the matched num in the matched rows == 0if (outerRecord.numOfAssociations == 0) {// send -D[null+other]outRow.setRowKind(RowKind.DELETE);outputNullPadding(other, !inputIsLeft);} // ignore matched number > 0// otherState.update(other, old + 1)otherSideOuterStateView.updateNumOfAssociations(other, outerRecord.numOfAssociations + 1);}}// send +I[record+other]soutRow.setRowKind(RowKind.INSERT);for (RowData other : associatedRecords.getRecords()) {output(input, other, inputIsLeft);}// state.add(record, other.size)inputSideOuterStateView.addRecord(input, associatedRecords.size());}} else { // input side not outer// state.add(record)inputSideStateView.addRecord(input);if (!associatedRecords.isEmpty()) { // if there are matched rows on the other sideif (otherIsOuter) { // if other side is outerOuterJoinRecordStateView otherSideOuterStateView =(OuterJoinRecordStateView) otherSideStateView;for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) {if (outerRecord.numOfAssociations== 0) { // if the matched num in the matched rows == 0// send -D[null+other]outRow.setRowKind(RowKind.DELETE);outputNullPadding(outerRecord.record, !inputIsLeft);}// otherState.update(other, old + 1)otherSideOuterStateView.updateNumOfAssociations(outerRecord.record, outerRecord.numOfAssociations + 1);}// send +I[record+other]soutRow.setRowKind(RowKind.INSERT);} else {// send +I/+U[record+other]s (using input RowKind)outRow.setRowKind(inputRowKind);}for (RowData other : associatedRecords.getRecords()) {output(input, other, inputIsLeft);}}// skip when there is no matched rows on the other side}} else { // input record is retract// state.retract(record)inputSideStateView.retractRecord(input);if (associatedRecords.isEmpty()) { // there is no matched rows on the other sideif (inputIsOuter) { // input side is outer// send -D[record+null]outRow.setRowKind(RowKind.DELETE);outputNullPadding(input, inputIsLeft);}// nothing to do when input side is not outer} else { // there are matched rows on the other sideif (inputIsOuter) {// send -D[record+other]soutRow.setRowKind(RowKind.DELETE);} else {// send -D/-U[record+other]s (using input RowKind)outRow.setRowKind(inputRowKind);}for (RowData other : associatedRecords.getRecords()) {output(input, other, inputIsLeft);}// if other side is outerif (otherIsOuter) {OuterJoinRecordStateView otherSideOuterStateView =(OuterJoinRecordStateView) otherSideStateView;for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) {if (outerRecord.numOfAssociations == 1) {// send +I[null+other]outRow.setRowKind(RowKind.INSERT);outputNullPadding(outerRecord.record, !inputIsLeft);} // nothing else to do when number of associations > 1// otherState.update(other, old - 1)otherSideOuterStateView.updateNumOfAssociations(outerRecord.record, outerRecord.numOfAssociations - 1);}}}}}主要逻辑实际上就两步:
- 将数据存储于本侧的状态中
- 根据join key去另一侧的状态中获取数据并且match
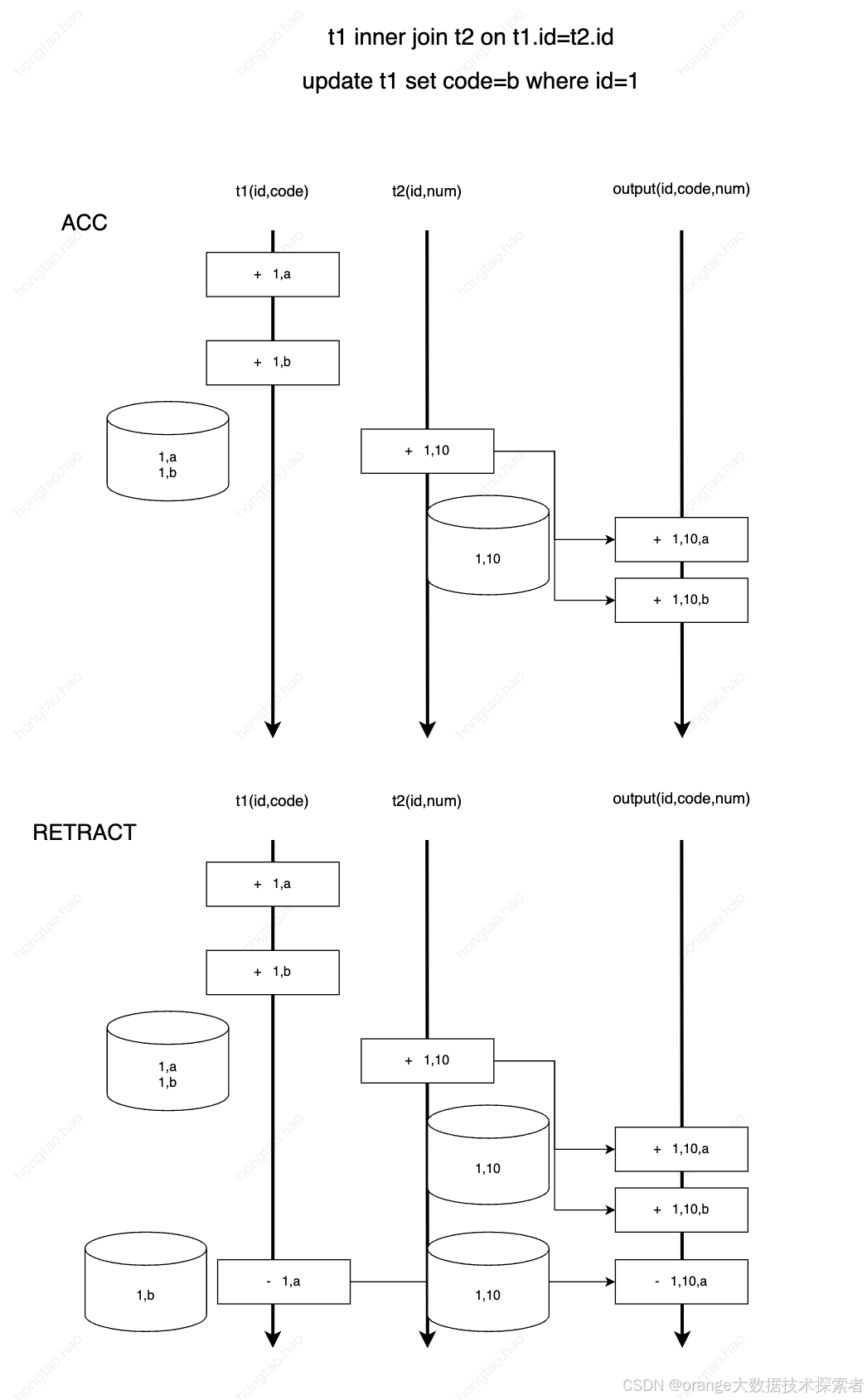
在flinksql对changelog的处理中将数据分为了Accumulate(insert/update_after)和Retract(delete/update_before)两类。
如果该消息类型为Accumulate,则处理逻辑的伪代码如下:
//record is ACC
if input side is outer //本侧是outer joinif no matched row on the other side //另一侧没有匹配记录send +[record + null]state.add(record, 0) // 0 表示另一侧没有关联的记录else // other.size > 0if other side is outerif (associated rows in matched rows == 0)//另一侧之前在本侧没有匹配的记录,所以需要撤回之前的 [null + other]send -[null + other]elseskipendifotherState.update(other, old + 1) //另一侧关联的记录 + 1endifsend +[record, other]s //另一侧有多少匹配的记录就发送多少条state.add(record, other.size) //更新状态endif
else //本侧不是 outer joinstate.add(record)if no matched row on the other side //另一侧没有匹配记录skip //无需输出else // other.size > 0if other size is outerif (associated rows in matched rows == 0) send -[null + other]elseskipendifotherState.update(other, old + 1) //另一侧关联的记录 + 1endifsend +[record + other]s //另一侧有多少匹配的记录就发送多少条endif
endif如果该消息为Retract,则处理逻辑的伪代码如下:
//record is RETRACT
state.retract(record)
if no matched rows on the other side //另一侧没有关联记录if input side is outersend -[record + null]endif
else //另一侧存在关联记录send -[record, other]s //要撤回已发送的关联记录if other side is outerif the matched num in the matched rows == 0, this should never happen!if the matched num in the matched rows == 1, send +[null + other]if the matched num in the matched rows > 1, skipotherState.update(other, old - 1) //另一侧关联的记录数 - 1endif
endifinner join的处理相对简单,重点在于当一侧流来数据去另一侧进行匹配的时候,会获取多少个匹配值,并且由于双流join为了保证join的准确性,需要将左右侧历史数据存放于状态中,因此除了给状态设置ttl,flink本身也对双流join的状态数据结构做了一些设计。
状态存储
根据 JoinInputSideSpec 中输入侧的特点(是否包含唯一键、关联键是否包含唯一键),Flink SQL 设计了几种不同的状态存储结构,即 JoinKeyContainsUniqueKey, InputSideHasUniqueKey 和 InputSideHasNoUniqueKey,分别如下:

public interface JoinRecordStateView {/*** Add a new record to the state view.*/void addRecord(BaseRow record) throws Exception;/*** Retract the record from the state view.*/void retractRecord(BaseRow record) throws Exception;/*** Gets all the records under the current context (i.e. join key).*/Iterable<BaseRow> getRecords() throws Exception;
}这些类都基于JoinRecordStateView进行函数实现:分别是往状态中添加一条记录,往状态中回撤一条记录,获取关联记录。
StreamingJoinOperator中的状态即使用MapState(键控状态),key就是当前关联记录的join key,在不同情况下不同的状态存储结构如下:

根据上面表格,可得出不同的join key和unique key的状态存储情况:
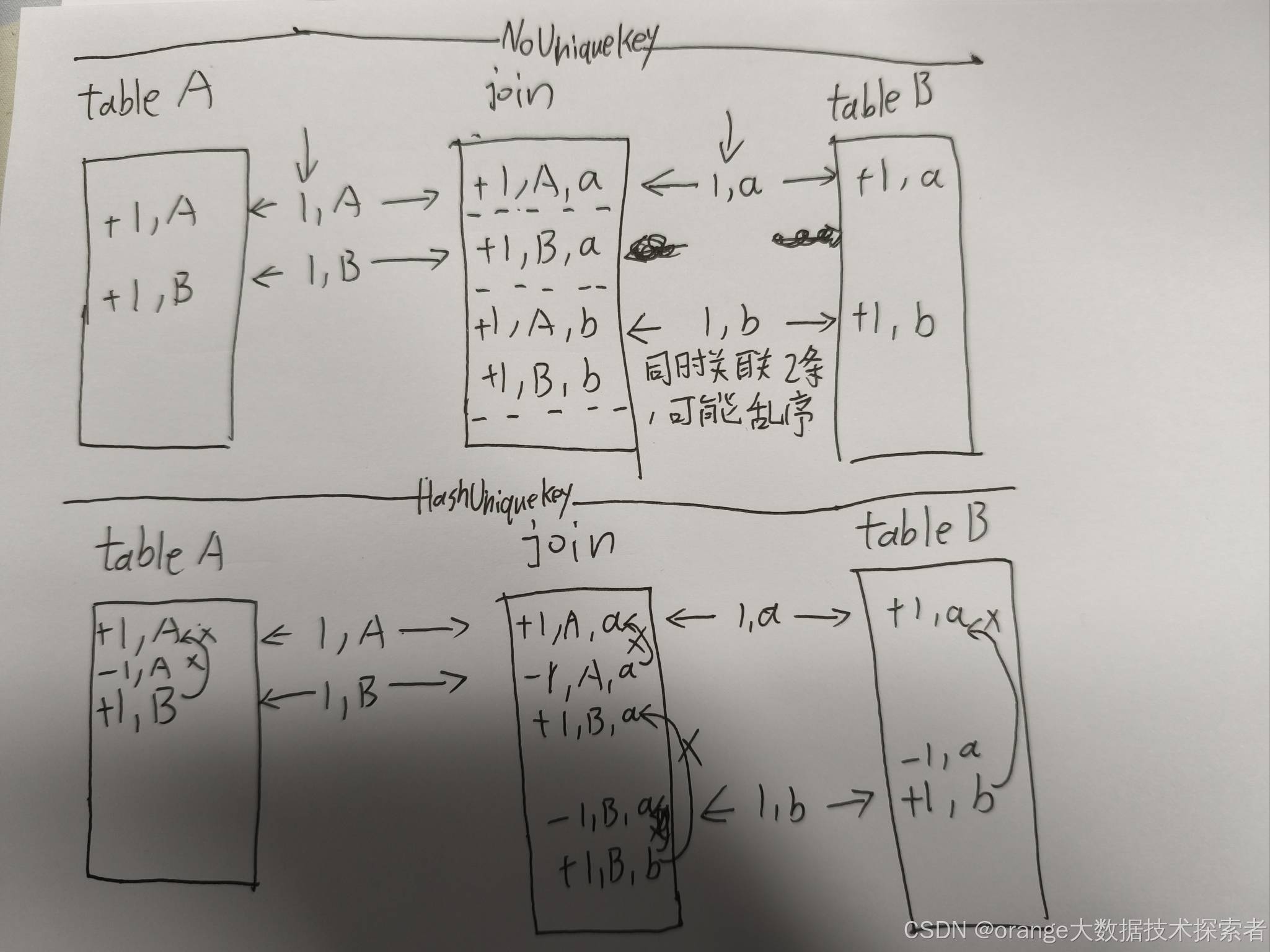
- 如果join key中包含unique key,那么一个join key只是对应一条记录
- 如果join key不包含unique key,那么一个join key 对应多条记录,但这些记录的unique key一定不同
- 如果输入没有unique key,那么只能使用ListState,当然,出于性能考虑flink仍然采用的MapState,只是key值即为记录本身
下图给一个inner join的例子,两侧的状态均为InputSideHasNoUniqueKey
unique key的获取与判断
FlinkSql的解析是在calcite的基础上做了二次开发,Unique key的获取和判断发生在planner的Optimize阶段,即将AST语法树(SqlNode)转化成关系代数式(RelNode)和行表达式(RexNode),然后从RelNode中判断是否有unique key。
核心类:org.apache.flink.table.planner.plan.metadata.FlinkRelMdUpsertKeys和org.apache.flink.table.planner.plan.metadata.FlinkRelMdUniqueKeys
private def getJoinUniqueKeys(joinInfo: JoinInfo,joinRelType: JoinRelType,left: RelNode,right: RelNode,mq: RelMetadataQuery,ignoreNulls: Boolean): JSet[ImmutableBitSet] = {val leftUniqueKeys = mq.getUniqueKeys(left, ignoreNulls)val rightUniqueKeys = mq.getUniqueKeys(right, ignoreNulls)getJoinUniqueKeys(joinRelType, left.getRowType, leftUniqueKeys, rightUniqueKeys,mq.areColumnsUnique(left, joinInfo.leftSet, ignoreNulls),mq.areColumnsUnique(right, joinInfo.rightSet, ignoreNulls))}def getJoinUniqueKeys(joinRelType: JoinRelType,leftType: RelDataType,leftUniqueKeys: JSet[ImmutableBitSet],rightUniqueKeys: JSet[ImmutableBitSet],isLeftUnique: JBoolean,isRightUnique: JBoolean): JSet[ImmutableBitSet] = {// first add the different combinations of concatenated unique keys// from the left and the right, adjusting the right hand side keys to// reflect the addition of the left hand side// NOTE zfong 12/18/06 - If the number of tables in a join is large,// the number of combinations of unique key sets will explode. If// that is undesirable, use RelMetadataQuery.areColumnsUnique() as// an alternative way of getting unique key information.val retSet = new JHashSet[ImmutableBitSet]val nFieldsOnLeft = leftType.getFieldCountval rightSet = if (rightUniqueKeys != null) {val res = new JHashSet[ImmutableBitSet]rightUniqueKeys.foreach { colMask =>val tmpMask = ImmutableBitSet.buildercolMask.foreach(bit => tmpMask.set(bit + nFieldsOnLeft))res.add(tmpMask.build())}if (leftUniqueKeys != null) {res.foreach { colMaskRight =>leftUniqueKeys.foreach(colMaskLeft => retSet.add(colMaskLeft.union(colMaskRight)))}}res} else {null}// determine if either or both the LHS and RHS are unique on the// equi-join columnsval leftUnique = isLeftUniqueval rightUnique = isRightUnique// if the right hand side is unique on its equijoin columns, then we can// add the unique keys from left if the left hand side is not null// generatingif (rightUnique != null&& rightUnique&& (leftUniqueKeys != null)&& !joinRelType.generatesNullsOnLeft) {retSet.addAll(leftUniqueKeys)}// same as above except left and right are reversedif (leftUnique != null&& leftUnique&& (rightSet != null)&& !joinRelType.generatesNullsOnRight) {retSet.addAll(rightSet)}retSet}private def getTableUniqueKeys(relOptTable: RelOptTable): JSet[ImmutableBitSet] = {relOptTable match {case sourceTable: TableSourceTable =>val catalogTable = sourceTable.catalogTablecatalogTable match {case act: CatalogTable =>val builder = ImmutableSet.builder[ImmutableBitSet]()val schema = act.getResolvedSchemaif (schema.getPrimaryKey.isPresent) {// use relOptTable's type which may be projected based on original schemaval columns = relOptTable.getRowType.getFieldNamesval primaryKeyColumns = schema.getPrimaryKey.get().getColumns// we check this because a portion of a composite primary key is not uniqueif (columns.containsAll(primaryKeyColumns)) {val columnIndices = primaryKeyColumns.map(c => columns.indexOf(c))builder.add(ImmutableBitSet.of(columnIndices: _*))}}val uniqueSet = sourceTable.uniqueKeysSet.orElse(null)if (uniqueSet != null) {builder.addAll(uniqueSet)}val result = builder.build()if (result.isEmpty) null else result}case table: FlinkPreparingTableBase => table.uniqueKeysSet.orElse(null)case _ => null}}def getProjectUniqueKeys(projects: JList[RexNode],typeFactory: RelDataTypeFactory,getInputUniqueKeys :() => util.Set[ImmutableBitSet],ignoreNulls: Boolean): JSet[ImmutableBitSet] = {// LogicalProject maps a set of rows to a different set;// Without knowledge of the mapping function(whether it// preserves uniqueness), it is only safe to derive uniqueness// info from the child of a project when the mapping is f(a) => a.//// Further more, the unique bitset coming from the child needsval projUniqueKeySet = new JHashSet[ImmutableBitSet]()val mapInToOutPos = new JHashMap[Int, JArrayList[Int]]()def appendMapInToOutPos(inIndex: Int, outIndex: Int): Unit = {if (mapInToOutPos.contains(inIndex)) {mapInToOutPos(inIndex).add(outIndex)} else {val arrayBuffer = new JArrayList[Int]()arrayBuffer.add(outIndex)mapInToOutPos.put(inIndex, arrayBuffer)}}// Build an input to output position map.projects.zipWithIndex.foreach {case (projExpr, i) =>projExpr match {case ref: RexInputRef => appendMapInToOutPos(ref.getIndex, i)case a: RexCall if ignoreNulls && a.getOperator.equals(SqlStdOperatorTable.CAST) =>val castOperand = a.getOperands.get(0)castOperand match {case castRef: RexInputRef =>val castType = typeFactory.createTypeWithNullability(projExpr.getType, true)val origType = typeFactory.createTypeWithNullability(castOperand.getType, true)if (castType == origType) {appendMapInToOutPos(castRef.getIndex, i)}case _ => // ignore}//rename or castcase a: RexCall if (a.getKind.equals(SqlKind.AS) || isFidelityCast(a)) &&a.getOperands.get(0).isInstanceOf[RexInputRef] =>appendMapInToOutPos(a.getOperands.get(0).asInstanceOf[RexInputRef].getIndex, i)case _ => // ignore}}if (mapInToOutPos.isEmpty) {// if there's no RexInputRef in the projected expressions// return empty set.return projUniqueKeySet}val childUniqueKeySet = getInputUniqueKeys()if (childUniqueKeySet != null) {// Now add to the projUniqueKeySet the child keys that are fully// projected.childUniqueKeySet.foreach { colMask =>val filerInToOutPos = mapInToOutPos.filter { inToOut =>colMask.asList().contains(inToOut._1)}val keys = filerInToOutPos.keysif (colMask.forall(keys.contains(_))) {val total = filerInToOutPos.map(_._2.size).productfor (i <- 0 to total) {val tmpMask = ImmutableBitSet.builder()filerInToOutPos.foreach { inToOut =>val outs = inToOut._2tmpMask.set(outs.get(i % outs.size))}projUniqueKeySet.add(tmpMask.build())}}}}projUniqueKeySet}def getUniqueKeysOnAggregate(grouping: Array[Int]): util.Set[ImmutableBitSet] = {// group by keys form a unique keyImmutableSet.of(ImmutableBitSet.of(grouping.indices: _*))}由于sql场景很多因此文档里只列举几个场景:
- join的uniqueKey需要判断两侧的uniquekey情况并进行组合判断
- scan的uniqueKey由scan的列是否全部包含该table定义中primary key来决定
- 投影的uniqueKey由投影的列是否全部包含输入子Node的unique key来决定
- 聚合的uniqueKey即是group by的unique key
比如上诉案例,两张表uniquekey均为为id,然后对scan后结果做投影,此时投影列不包含子Node unique key,唯一键丢失。
基于上面两个投影做join,因此本次join操作的左侧为no unique key,右侧则有unique key,又由于本次为inner join所以join后的投影也没有unique key
大致可以归纳为以下几个步骤或方法(不仅仅是FlinkSql,所有sql逻辑都这样):
- 静态信息:部分rel节点可以从表的元数据中获取unique key信息,例如table scan(Flink中TableSourceScan)
- 推导:根据输入的uniquekey信息来推导新的unique key,例如投影
- 聚合和分组:在进行聚合操作时,分组的key会形成一个新的unique key
- join:根据join类型和join条件来推导结果的unique key