Ollama本地部署大模型指南

一、Ollama 是什么
Ollama 是一个用于在本地运行大型语言模型(LLM)的开源框架,它的出现为人工智能爱好者和开发者提供了一种全新的体验。在这个数据隐私和安全日益重要的时代,Ollama 允许用户在自己的设备上运行大型语言模型,而无需依赖外部服务器或云服务,极大地提高了数据处理的隐私性和安全性。
Ollama 将模型权重、配置和数据捆绑到一个名为 Modelfile 的包中,这一设计优化了模型的设置和配置细节,包括对 GPU 使用情况的精细调控,使得模型的部署和管理变得更加容易。它支持多种主流的大型语言模型,如 Llama 2、Code Llama、Mistral、Gemma 等,用户还能根据特定需求定制和创建自己的模型,满足个性化的应用场景。
从技术原理上讲,Ollama 通过一系列高效的算法和优化技术,实现了模型的快速加载和运行。它利用 Docker 容器技术,将模型及其依赖环境封装在一个独立的容器中,确保了模型运行的稳定性和可移植性。在模型推理过程中,Ollama 能够根据硬件资源的实际情况,智能地分配计算任务,充分发挥 CPU 和 GPU 的性能优势,从而实现高效的推理计算。
与其他类似工具相比,Ollama 具有明显的优势。例如,与一些依赖云服务的大语言模型应用相比,Ollama 无需担心网络延迟和数据隐私问题,用户可以在离线状态下随时使用模型。与一些复杂的本地模型部署方案相比,Ollama 的安装和使用更加简单,即使是没有深厚技术背景的用户也能轻松上手 。
Ollama官网:Ollama
二、Ollama 的优势
(一)便捷部署
Ollama 利用 Docker 容器技术,将模型及其依赖环境封装在一个独立的容器中,极大地简化了部署流程。在传统的模型部署过程中,开发者往往需要花费大量时间和精力去配置复杂的环境,包括安装各种依赖库、设置系统参数等 ,而 Ollama 通过将模型权重、配置和数据捆绑到一个名为 Modelfile 的包中,用户只需执行简单的命令,就能快速完成模型的部署和启动。
以在一台全新的 Linux 服务器上部署 Llama 2 模型为例,使用 Ollama,用户只需在终端中输入 “ollama pull llama2”,Ollama 便会自动从模型库中下载 Llama 2 模型及其相关依赖,并完成配置,整个过程可能只需要几分钟 。而如果采用传统的部署方式,可能需要先安装 Python 环境、配置 CUDA(如果使用 GPU 加速)、安装各种深度学习框架和依赖库,然后再手动下载和配置 Llama 2 模型,这个过程可能会遇到各种版本兼容性问题,耗时可能长达数小时甚至数天。
在优化配置方面,Ollama 会自动检测硬件资源,智能地分配计算任务,充分发挥 CPU 和 GPU 的性能优势。它还支持 GPU 加速,通过合理的配置,能够让模型在 GPU 上高效运行,大大提高推理速度。在处理大规模文本生成任务时,使用 GPU 加速的 Ollama 能够在短时间内生成高质量的文本,满足用户对实时性的需求。
(二)丰富模型支持
Ollama 支持多种主流的大型语言模型,为用户提供了丰富的选择。在 Ollama 的模型库中,常见的模型包括 Llama 2、Code Llama、Mistral、Gemma 等 。这些模型在不同的自然语言处理任务中表现出色,具有各自的特点和优势。
Llama 2 是 Meta 开发的新一代开源大型语言模型,在语言理解和生成方面具有强大的能力,能够处理多种复杂的任务,如文本生成、问答系统、机器翻译等;Code Llama 则专注于代码生成领域,能够根据用户的描述自动生成高质量的代码,支持多种编程语言,为开发者提供了极大的便利;Mistral 以其高效的推理速度和出色的性能在自然语言处理任务中脱颖而出,尤其在处理长文本时表现出色;Gemma 则在多语言处理和知识问答方面具有独特的优势,能够理解和回答多种语言的问题。
用户可以根据自己的具体需求和应用场景,在 Ollama 中轻松选择和切换不同的模型。在进行文本创作时,用户可以选择 Llama 2 模型,利用其强大的语言生成能力,快速生成富有创意的文章;而在进行代码开发时,Code Llama 模型则能提供更精准的代码生成建议。如果用户对模型的性能和速度有更高的要求,Mistral 模型可能是更好的选择;如果需要处理多语言任务,Gemma 模型则能发挥其优势。这种丰富的模型支持,使得 Ollama 能够满足不同用户群体和多样化的应用需求。
Ollama官网上搜索模型:
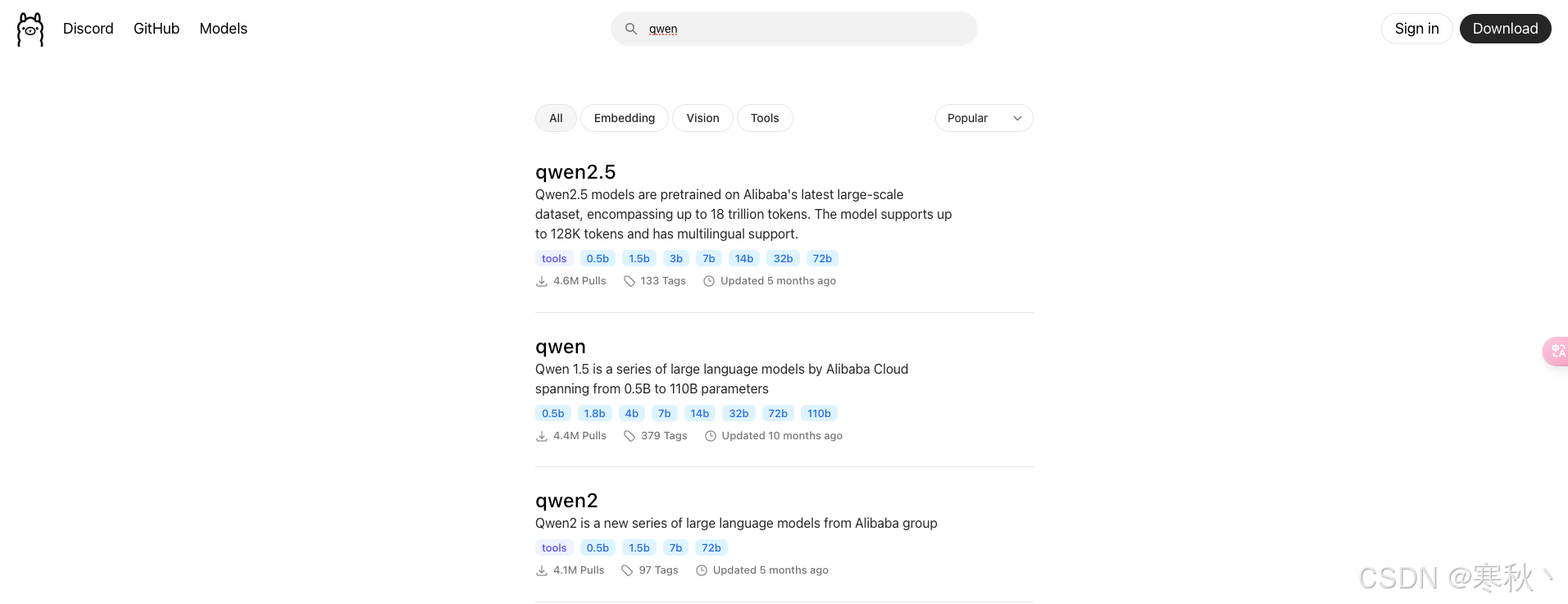
(三)跨平台特性
Ollama 具有出色的跨平台特性,支持多种操作系统,包括 macOS、Windows 和 Linux,以及 Docker 环境。这使得不同平台的用户都能轻松使用 Ollama 来运行大型语言模型。
对于 macOS 用户,Ollama 提供了专门的安装包,用户可以通过官方网站下载并进行简单的安装操作,即可在 Mac 设备上快速部署和运行模型。在 MacBook Pro 上安装 Ollama 后,用户可以利用设备的 M1 或 M2 芯片的强大性能,运行各种大型语言模型,进行文本处理、编程辅助等任务。
Windows 用户也能方便地使用 Ollama。通过下载 Windows 版本的安装包,用户可以在 Windows 10 及以上版本的系统中顺利安装和使用 Ollama。在 Windows 系统中,Ollama 的操作界面和命令行工具与其他操作系统保持一致,用户可以快速上手。
Linux 用户则可以通过多种方式安装 Ollama,如使用官方提供的安装脚本,或者通过 Docker 容器进行安装。在 Ubuntu、Fedora 等常见的 Linux 发行版中,Ollama 都能稳定运行,为 Linux 用户提供了便捷的模型运行环境。
此外,Ollama 还支持在 Docker 环境中运行。通过 Docker,用户可以将 Ollama 及其相关模型打包成一个独立的容器,方便在不同的服务器环境中部署和迁移。这种跨平台特性,使得 Ollama 能够适应各种不同的使用场景,无论是个人开发者在本地设备上进行开发和测试,还是企业在生产环境中部署模型,Ollama 都能提供一致的体验和高效的服务。
(四)隐私与安全保障
在数据隐私和安全备受关注的今天,Ollama 在本地运行模型的特点为用户提供了更高的数据隐私和安全性保障。与依赖云服务的大语言模型应用不同,Ollama 将模型运行在用户自己的设备上,数据的处理和存储都在本地进行,避免了数据传输过程中的风险。
在一些对数据隐私要求极高的场景中,如医疗、金融等领域,企业和机构往往需要处理大量敏感信息。使用 Ollama,这些机构可以将模型部署在内部服务器上,确保患者的医疗记录、客户的金融数据等敏感信息不会被传输到外部服务器,从而有效保护数据的隐私和安全。
在本地运行模型还能减少因网络问题导致的服务中断风险,提高模型运行的稳定性和可靠性。即使在没有网络连接的情况下,用户依然可以使用 Ollama 运行模型,进行各种自然语言处理任务。这种对数据隐私和安全的重视,使得 Ollama 在众多大语言模型工具中脱颖而出,成为对隐私敏感用户的首选。
三、Ollama 安装步骤
(一)Mac 安装
直接下载安装包:访问 Ollama 官方网站(Download Ollama on macOS ),在下载页面找到适用于 Mac 的安装包(通常为.dmg格式)。下载完成后,双击安装包,按照安装向导的提示进行操作,将 Ollama 应用程序拖动到 “应用程序” 文件夹中即可完成安装。
使用 Homebrew 安装:如果 Mac 上已经安装了 Homebrew 包管理器,可以通过以下命令进行安装:
brew install ollama安装过程中,Homebrew 会自动下载并安装 Ollama 及其依赖项。
安装完成后,可以在终端中输入以下命令查看 Ollama 的版本:
ollama -v
如果看到输出的版本信息,则说明安装成功。要启动 Ollama 服务,可以在终端中输入:
ollama serve启动后,Ollama 将在本地监听默认端口11434,等待接收请求。
(二)Windows 安装
从 Ollama 官网(Download Ollama on macOS )下载适用于 Windows 的安装程序(通常为.exe文件)。
下载完成后,双击安装程序,按照安装向导的提示进行操作。在安装过程中,可以选择安装路径等选项,保持默认设置并点击 “下一步” 即可。
安装完成后,打开命令提示符(CMD)或 PowerShell,输入以下命令验证安装是否成功:
ollama --version如果显示 Ollama 的版本信息,则说明安装成功。同样,要启动 Ollama 服务,在命令提示符或 PowerShell 中输入:
ollama serve(三)Linux 安装
在 Linux 系统上安装 Ollama,可以使用官方提供的一键安装脚本。打开终端,执行以下命令:
curl -fsSL https://ollama.com/install.sh | sh该脚本会自动下载并安装 Ollama 及其依赖项。安装完成后,通过以下命令启动 Ollama 服务:
ollama serve还可以将 Ollama 添加为系统服务,实现开机自启动。首先,创建一个服务文件,例如在/etc/systemd/system/ollama.service中:
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=/usr/local/bin/ollama serve
User=user1
Group=group1
Restart=always
RestartSec=3[Install]
WantedBy=default.target将User和Group替换为实际的用户名和用户组。然后,执行以下命令使服务生效并开机自启:
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollama使用以下命令可以查看 Ollama 服务的状态:
sudo systemctl status ollama如果看到 “Active: active (running)”,则说明 Ollama 服务正在运行。
(四)Ollama可配置环境变量:
OLLAMA_DEBUG: 显示额外的调试信息(例如:OLLAMA_DEBUG=1)。
OLLAMA_HOST: Ollama 服务器的 IP 地址(默认值:127.0.0.1:11434)。
OLLAMA_KEEP_ALIVE: 模型在内存中保持加载的时长(默认值:“5m”)。
OLLAMA_MAX_LOADED_MODELS: 每个 GPU 上最大加载模型数量。
OLLAMA_MAX_QUEUE: 请求队列的最大长度。
OLLAMA_MODELS: 模型目录的路径。
OLLAMA_NUM_PARALLEL: 最大并行请求数。
OLLAMA_NOPRUNE: 启动时不修剪模型 blob。
OLLAMA_ORIGINS: 允许的源列表,使用逗号分隔。
OLLAMA_SCHED_SPREAD: 始终跨所有 GPU 调度模型。
OLLAMA_TMPDIR: 临时文件的位置。
OLLAMA_FLASH_ATTENTION: 启用 Flash Attention。
OLLAMA_LLM_LIBRARY: 设置 LLM 库以绕过自动检测。示例:
- 显卡资源使用不均衡:设置环境变量OLLAMA_SCHED_SPREAD为1
- 加速计算:设置环境变量OLLAMA_FLASH_ATTENTION为1(FlashAttention 是一种优化的注意力机制,用于加速深度学习模型中常见的自注意力计算,尤其是在Transformer架构中。它通过改进内存访问模式和计算策略,显著提高了计算效率和内存使用率。)
- 并发请求数量:OLLAMA_NUM_PARALLEL,默认一般是4或者1。但是会相应的增加上下文,比如一个请求2048 Tokens。如果是4个并行,那么就会消耗4*2048的上下文窗口。
四、Ollama 常用操作
(一)模型管理
模型下载:使用ollama pull命令可以从模型仓库中下载所需的模型。例如,要下载流行的 qwen2.5 模型,可以在终端中输入:
ollama pull qwen2.5这将自动从 Ollama 的模型库中下载qwen2.5 模型及其相关依赖文件。如果想下载特定版本或变体的模型,只需在模型名称后加上版本号或变体标识,如下载 qwen2.5模型的 3B 版本:
ollama pull qwen2.5:3b-
模型运行:通过ollama run命令来运行已下载的模型,并进入交互界面与模型进行对话。运行 qwen2.5 模型的命令如下:
ollama run qwen2.5:3b执行上述命令后,终端会进入交互模式,此时你以输入问题或指令与模型进行交互。例如,输入 “请介绍一下人工智能的发展历程”,模型会根据其训练数据生成相应的回答。在交互过程中,可以随时输入新的问题,模型会持续响应,直到退出交互界面 。
模型列表查看:若要查看本地已下载的模型列表,使用ollama list命令,它会列出所有已下载到本地的模型及其相关信息,包括模型名称、版本、大小等。在终端中输入该命令后,会得到类似以下的输出:
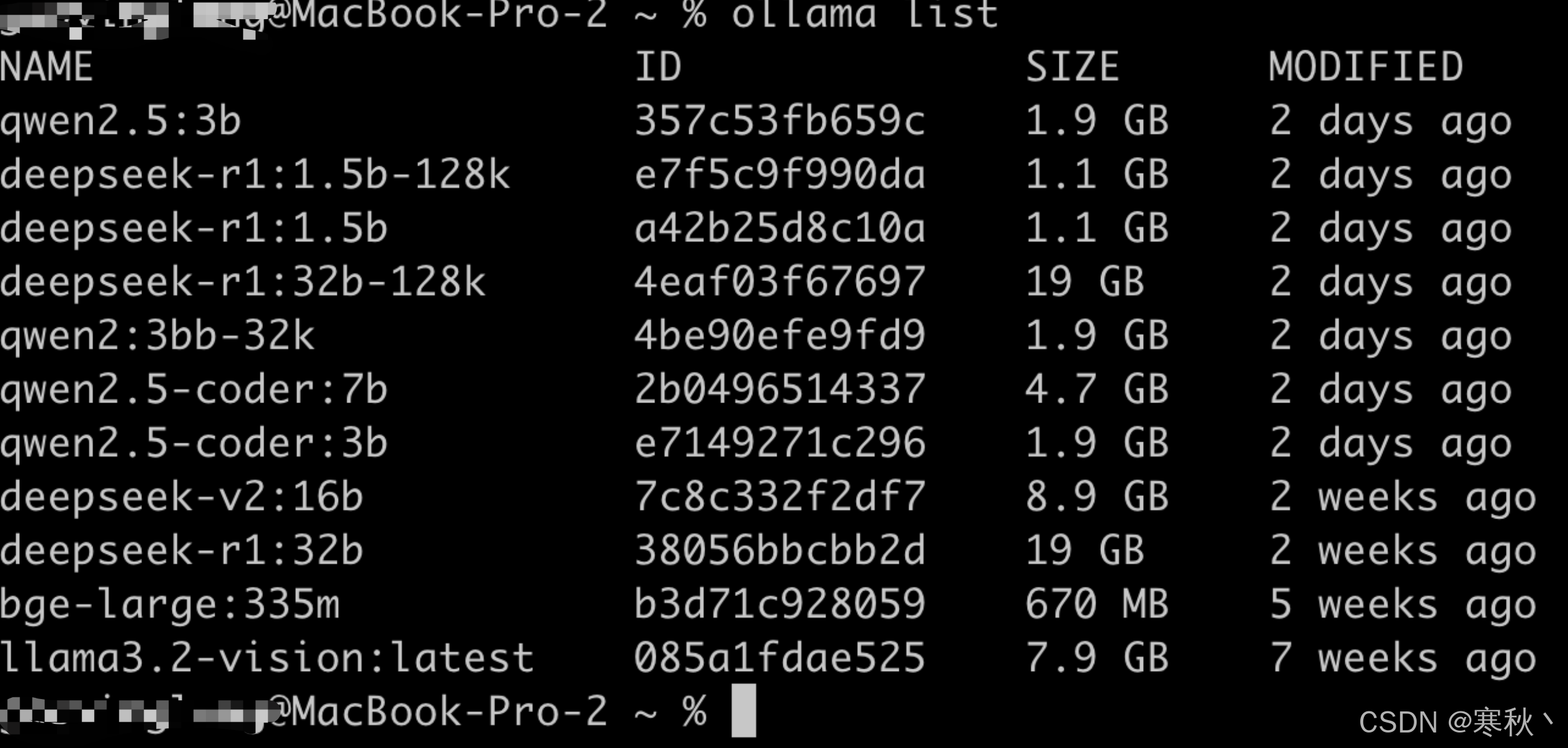
通过这个列表,可以清晰地了解本地已安装的模型情况,方便进行模型管理和选择使用。
模型删除:当不再需要某个已下载的模型时,可以使用ollama rm命令将其从本地删除,以释放磁盘空间。删除 qwen2.5 3b 模型的命令如下:
ollama rm qwen2.5:3b注意,删除模型后,相关的模型文件和数据将被永久删除,请谨慎操作。
(二)API 调用
文本生成 API:Ollama 提供了/api/generate接口用于文本生成。以下是使用curl命令调用该接口的示例:
curl http://localhost:11434/api/generate -d '{"model": "qwen2.5:3b","prompt": "请写一首关于春天的诗","stream": false,"options": {"temperature": 0.7,"max_tokens": 200}
}'在这个示例中:
- "model": "qwen2.5:3b"指定使用 qwen2.5:3b 模型进行文本生成。
- "prompt": "请写一首关于春天的诗"是输入的提示词,模型会根据这个提示生成相应的文本。
- "stream": false表示不启用流式响应,即模型生成完所有内容后一次性返回结果;若设置为true,则模型会边生成边返回,适用于实时生成文本的场景。
- "options"部分用于设置模型的参数:
对话模式 API:使用/api/chat接口可以实现对话功能,模型会记住上下文,支持多轮对话。以下是调用该接口的curl命令示例:
curl http://localhost:11434/api/chat -d '{"model": "qwen2.5:3b","messages": [{"role": "user", "content": "天空为什么是蓝色的"},{"role": "assistant", "content": "这是因为瑞利散射,太阳光中的蓝光更容易被散射,所以我们看到的天空是蓝色的。"},{"role": "user", "content": "那大海为什么也是蓝色的呢"}],"stream": false,"options": {"temperature": 0.8}
}'在这个示例中:
- "model": "qwen2.5:3b"指定使用 qwen2.5:3b 模型进行对话。
- "messages"是一个数组,包含了对话的历史消息。每个消息是一个对象,包含"role"(角色,取值为"user"或"assistant")和"content"(消息内容)。通过传递对话历史,模型可以根据上下文生成更合理的回复。
- "stream": false含义与文本生成 API 中的相同,控制响应是否为流式。
- "options"部分同样用于设置模型参数,这里设置了"temperature": 0.8,以调整生成回复的随机性 。
(三)自定义模型
创建 Modelfile:Modelfile 是 Ollama 用于定义模型参数和配置的文件。要创建自定义模型,首先需要编写 Modelfile。假设我们基于已有模型qwen2.5:3b创建一个自定义模型,设置系统提示和温度参数,Modelfile 的内容可以如下:
FROM qwen2.5:3b
SYSTEM "你是一个专业的知识问答助手,回答问题要简洁明了。"
PARAMETER temperature 0.6在这个 Modelfile 中:
- FROM qwen2.5:3b指定基础模型为 qwen2.5:3b,即基于 qwen2.5:3b 来创建自定义模型。
- SYSTEM "你是一个专业的知识问答助手,回答问题要简洁明了。"设置了系统提示,模型在生成回答时会遵循这个提示,以特定的角色和风格进行回复。
- PARAMETER temperature 0.6设置了模型的温度参数为 0.6,控制生成文本的随机性。
构建并运行自定义模型:编写好 Modelfile 后,使用ollama create命令来构建自定义模型,假设自定义模型命名为my_qwen2.5:
ollama create my_qwen2.5 -f Modelfile其中,my_qwen2.5是自定义模型的名称,-f Modelfile指定使用名为Modelfile的文件来创建模型。构建完成后,就可以使用ollama run命令来运行自定义模型:
ollama run my_qwen2.5运行后,即可进入交互界面,与自定义的模型进行对话。由于在 Modelfile 中设置了系统提示和温度参数,模型在回答问题时会表现出与基础模型不同的行为,更符合我们定义的角色和风格。
自定义模型示例(增加上下文窗口):
假设从Ollama上拉取了大模型,其默认的窗口大小只有2048。可以通过如下方法,提高上下文窗口。
ollama show --modelfile qwen2.5:3b > Modelfile生成的Modelfile如下:
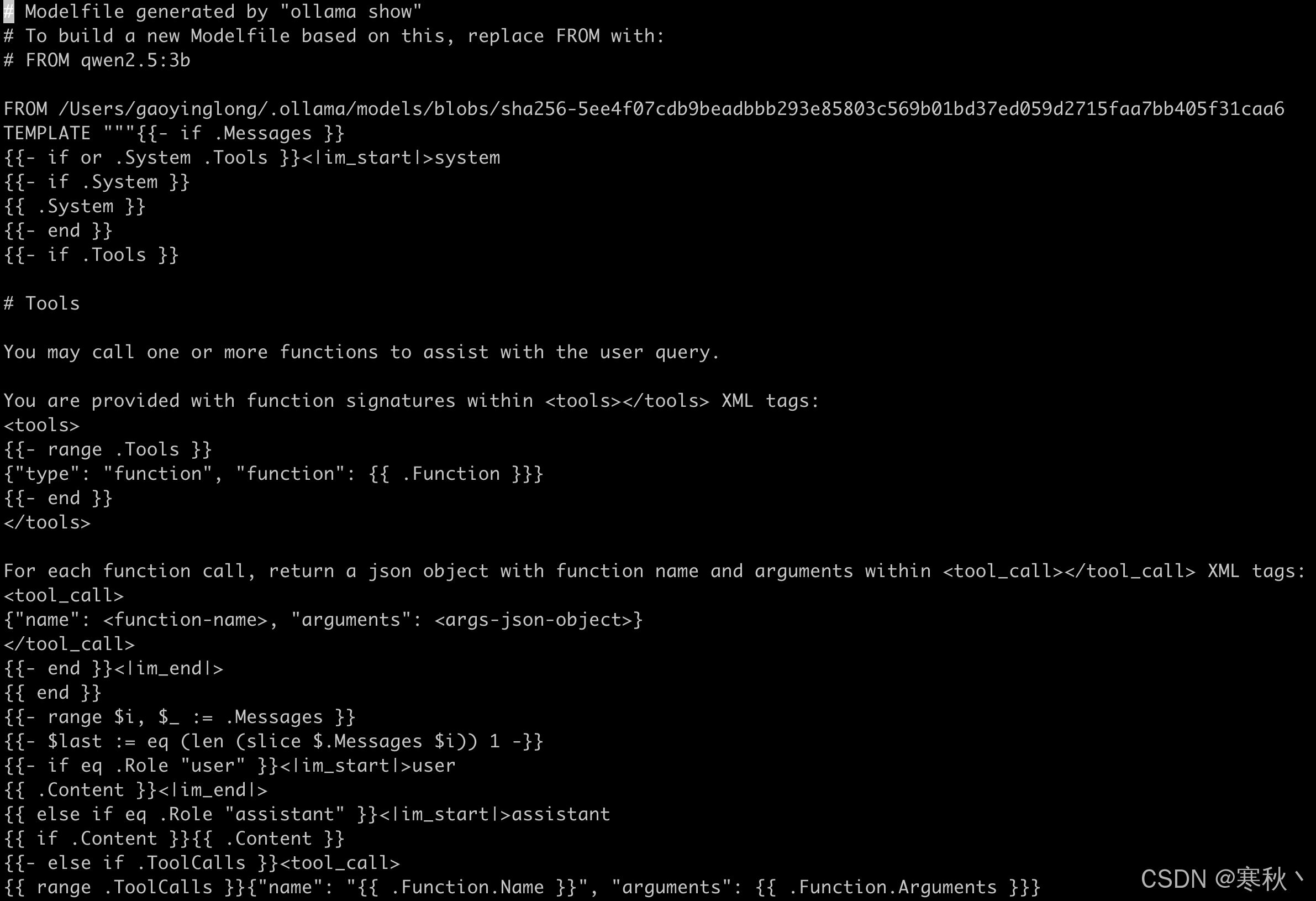
然后在PARAMETER处增加如下配置,32768就是上下文窗口大小。
注意增加上下文窗口可能增加显存的使用,谨慎增加。
PARAMETER num_ctx 32768然后创建新模型即可。
ollama create qwen2:3b-32k -f Modelfile接下来,就可以使用运行具有更高上下文的模型了。
ollama run qwen2:3b-32k五、Ollama 使用注意事项
(一)硬件要求
运行 Ollama 中的不同模型对硬件资源有一定要求,特别是内存和显存。对于一些较小规模的模型,如 7B 参数的模型,至少需要 8GB 的内存或显存才能较为流畅地运行 。在这个配置下,模型能够在处理简单的文本生成任务时,如短文本摘要、简单对话回复等,保持相对稳定的性能表现。当内存或显存不足时,模型的运行速度会明显下降,甚至可能出现运行中断的情况。
而对于 13B 参数的模型,建议配备 16GB 的内存或显存。这类模型在处理稍微复杂一些的任务,如长文本创作、复杂问题解答时,需要更多的内存来存储模型参数和中间计算结果。如果硬件配置达不到要求,模型在推理过程中可能会频繁进行内存交换,导致运行效率大幅降低。
对于更大规模的 34B 参数模型,至少需要 32GB 的内存或显存。这类大型模型通常用于处理非常复杂的自然语言处理任务,如专业领域的深度文本分析、多轮复杂对话等。足够的内存和显存能够确保模型在处理这些复杂任务时,有足够的资源来进行高效的计算和数据存储。
GPU 在 Ollama 运行模型时起着至关重要的加速作用。Ollama 支持利用 GPU 进行加速,特别是 NVIDIA GPU。在配备 NVIDIA GPU 的设备上,通过合理配置,模型的运行速度和性能能够得到显著提升。在处理大规模文本生成任务时,使用 GPU 加速的 Ollama 可以将生成时间缩短数倍,大大提高了处理效率。在进行多轮对话时,GPU 加速能够使模型更快地响应用户的输入,提供更流畅的交互体验。因此,在条件允许的情况下,建议使用带有 NVIDIA GPU 的设备来运行 Ollama,以充分发挥模型的性能。
(二)网络问题
在使用 Ollama 下载模型时,有时可能会遇到下载速度慢的问题,这可能是由于网络环境不佳或下载源的限制导致的。为了解决这个问题,用户可以尝试配置镜像源来加速下载。在 Ollama 中,可以通过修改配置文件或设置环境变量的方式来指定镜像源。在 Linux 系统中,可以在 Ollama 的配置文件中添加以下内容:
export OLLAMA_MIRROR=https://new-mirror-url将https://new-mirror-url替换为实际的镜像源地址。一些常用的镜像源包括国内的一些技术社区或云服务提供商提供的镜像,这些镜像通常具有更快的下载速度和更稳定的连接。
(三)存储路径
Ollama 下载的模型默认存储在操作系统的特定目录中,具体路径取决于操作系统。在 Linux 和 macOS 系统中,默认路径为~/.ollama/models,其中~表示用户主目录。在 Windows 系统中,默认路径为C:\Users\\.ollama\models ,是当前 Windows 系统的登录用户名。这些默认路径下会存储所有通过 Ollama 下载的模型文件和相关数据。
如果希望将模型存储在其他位置,例如因为 C 盘空间有限,想将模型存储到 D 盘,可以通过设置环境变量来修改存储路径。在 Linux 和 macOS 系统中,可以通过编辑~/.bashrc或~/.zshrc文件(根据使用的 shell 而定),添加以下内容:
export OLLAMA_MODELS="/custom/path/to/models"将/custom/path/to/models替换为用户希望存储模型的实际路径。修改完成后,执行source ~/.bashrc或source ~/.zshrc使设置生效。
在 Windows 系统中,可以通过以下步骤设置环境变量:右键点击 “此电脑”,选择 “属性”;在弹出的窗口中,点击左侧的 “高级系统设置”;在 “系统属性” 窗口的 “高级” 选项卡中,点击 “环境变量”;在 “环境变量” 窗口中,在 “系统变量” 或 “用户变量” 部分新建一个名为OLLAMA_MODELS的环境变量,变量值为希望存储模型的路径,如D:\OllamaModels;点击 “确定” 保存设置。设置完成后,重启 Ollama 服务,新的存储路径就会生效。在修改存储路径时,要确保目标路径具有足够的存储空间,并且用户对该路径具有读写权限,以保证模型能够正常下载和存储。