Informer源码解析4——完整注意力机制解读
完整注意力机制
源码
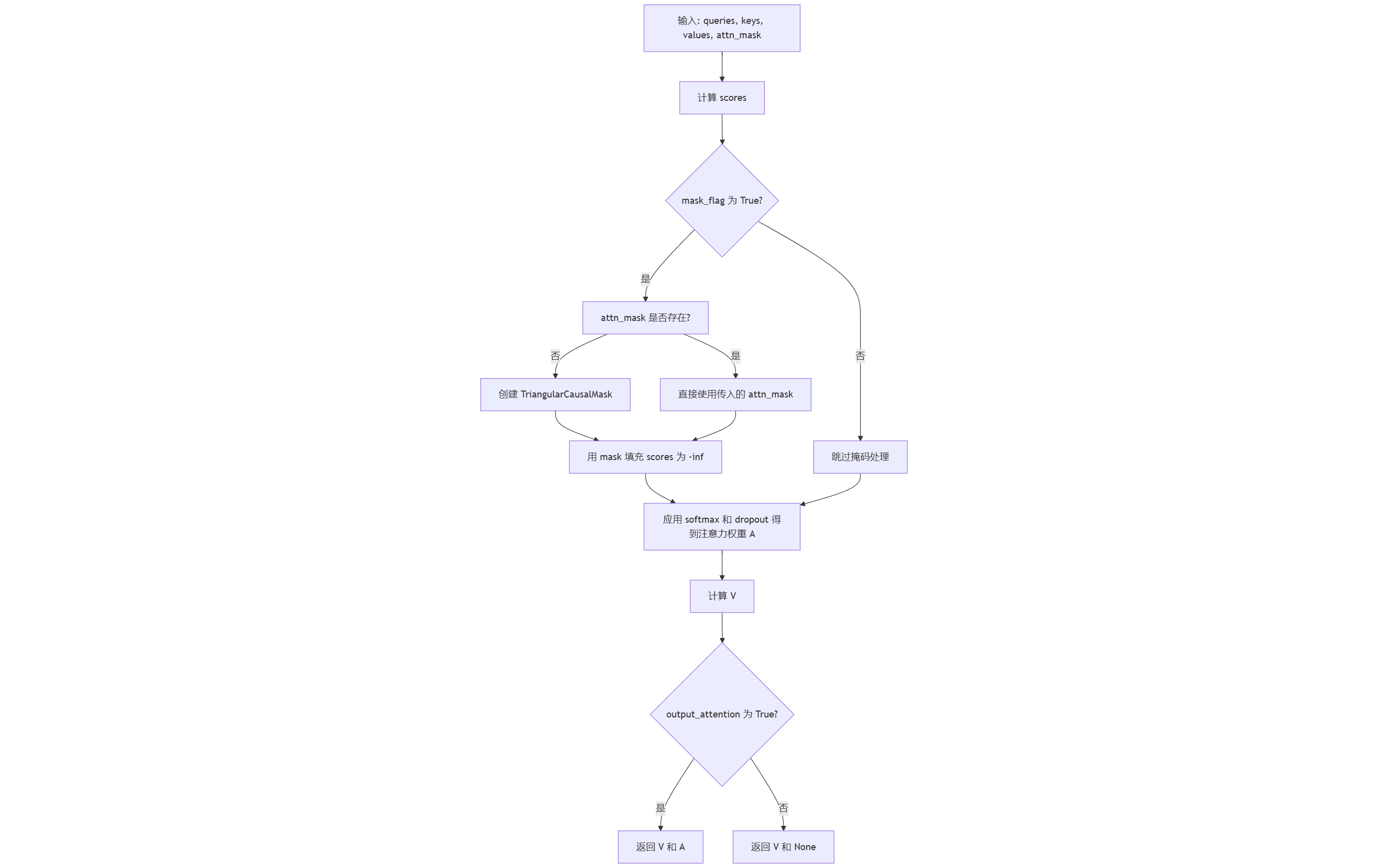
class FullAttention(nn.Module):def __init__(self, mask_flag=True, factor=5, scale=None, attention_dropout=0.1, output_attention=False):"""实现完整的注意力机制,支持因果掩码和注意力权重输出。Args:mask_flag (bool): 是否应用因果掩码(防止模型看到未来信息),默认为 True。factor (int): 未使用的参数(可能保留兼容性)。scale (float): 缩放因子,若未提供则默认为 1/sqrt(d_k)。attention_dropout (float): 注意力权重的 dropout 概率。output_attention (bool): 是否返回注意力权重矩阵。"""super(FullAttention, self).__init__()self.scale = scaleself.mask_flag = mask_flag # 是否启用因果掩码self.output_attention = output_attention # 是否返回注意力权重self.dropout = nn.Dropout(attention_dropout) # 注意力 Dropout 层def forward(self, queries, keys, values, attn_mask):"""前向传播计算注意力。Args:queries (Tensor): 查询张量,形状为 [Batch, Length, Heads, d_k]。keys (Tensor): 键张量,形状为 [Batch, Length, Heads, d_k]。values (Tensor): 值张量,形状为 [Batch, Length, Heads, d_v]。attn_mask (Tensor): 注意力掩码,形状为 [Batch, Length, Length]。Returns:Tuple[Tensor, Tensor]: 注意力加权后的值和注意力权重(可选)。"""# 获取输入张量的维度信息B, L, H, E = queries.shape # Batch, 查询序列长度, 注意力头数, d_k_, S, _, D = values.shape # Batch, 键值序列长度, 注意力头数, d_v# 缩放因子:默认为 1/sqrt(d_k)scale = self.scale or 1.0 / torch.sqrt(torch.tensor(E, device=queries.device))# 计算注意力分数矩阵:Q * K^Tscores = torch.einsum("blhe,bshe->bhls", queries, keys) # 输出形状 [B, H, L, S]print(scores.shape) # 调试输出# 因果掩码处理if self.mask_flag:if attn_mask is None:# 创建下三角因果掩码(解码器自注意力时使用)attn_mask = TriangularCausalMask(B, L, device=queries.device)# 将掩码位置的分数设为负无穷,softmax 后权重趋近于 0scores.masked_fill_(attn_mask.mask, -torch.inf)# 计算注意力权重:softmax + dropoutA = self.dropout(torch.softmax(scale * scores, dim=-1)) # 形状 [B, H, L, S]# 计算加权值:注意力权重 * ValuesV = torch.einsum("bhls,bshd->blhd", A, values) # 输出形状 [B, L, H, D]print(V.shape) # 调试输出(可删除)# 返回结果if self.output_attention:return (V.contiguous(), A) # 保证内存连续else:return (V.contiguous(), None)流程图
class FullAttention(nn.Module):def __init__(self, mask_flag=True, factor=5, scale=None, attention_dropout=0.1, output_attention=False):super(FullAttention, self).__init__()self.scale = scaleself.mask_flag = mask_flagself.output_attention = output_attentionself.dropout = nn.Dropout(attention_dropout)
传参讲解:
mask_flag:控制是否应用因果掩码(防止解码器查看未来信息)scale:缩放因子,默认使用1/sqrt(d_k)attention_dropout:注意力权重的随机失活概率output_attention:是否返回注意力矩阵(可用于可视化或分析)
注意力分数计算
# 获取输入张量的维度信息B, L, H, E = queries.shape # Batch, 查询序列长度, 注意力头数, d_k_, S, _, D = values.shape # Batch, 键值序列长度, 注意力头数, d_v首先看一下Q,K,V三个张量的形状。
queries (Tensor): 查询张量,形状为 [Batch, Length, Heads, d_k]。
keys (Tensor): 键张量,形状为 [Batch, Length, Heads, d_k]。
values (Tensor): 值张量,形状为 [Batch, Length, Heads, d_v]。
可以看到,三个张量的前三个值代表的含义是相同的,分别是批次数量,序列长度,注意力头数。只有最后一个值含义不同,对于q和k来说,d_k代表的是查询/键的维度,d_v代表的是值的维度。
注意力分数计算的核心步骤是下面这句,对下面这句代码需要做详细解释。
scores = torch.einsum("blhe,bshe->bhls", queries, keys)
爱因斯坦求和约定(Einsum)
爱因斯坦求和约定(Einstein Summation Convention)是张量运算中的一种简洁记法,通过下标标记维度间的运算关系
假设输入张量结构如下:
queries: [B, L, H, E] # [Batch, Query长度, 头数, d_k]
keys: [B, S, H, E] # [Batch, Key长度, 头数, d_k]
期望得到注意力分数矩阵:
scores: [B, H, L, S] # [Batch, 头数, Query长度, Key长度]
计算公式为:
![]()
可以看到,方法里的传参 blhe,bshe是指传入张量的各个维度,bhls是指输出张量的各个维度。
爱因斯坦求和约定也可以等效为基础的矩阵乘法:首先做维度调整,再做乘积。
# 原始维度调整
queries_ = queries.permute(0, 2, 1, 3) # [B, H, L, E]
keys_ = keys.permute(0, 2, 3, 1) # [B, H, E, S]# 矩阵乘法
scores = torch.matmul(queries_, keys_) # [B, H, L, S]
相比于基础的矩阵乘法,爱因斯坦求和约定在执行效率上有明显提升。能够避免繁琐的permute/transpose操作 。
| 方法 | 代码复杂度 | 可读性 | 内存占用 | 执行效率 |
|---|---|---|---|---|
| Einsum | 低 | 高 | 优化 | 较高 |
| 传统矩阵乘法 | 高 | 低 | 中间转置 | 稍低 |
因果掩码处理
if self.mask_flag:if attn_mask is None:attn_mask = TriangularCausalMask(B, L, device=queries.device)scores.masked_fill_(attn_mask.mask, -torch.inf)

注意力权重与值计算
scale = self.scale or 1.0 / torch.sqrt(torch.tensor(E))
A = self.dropout(torch.softmax(scale * scores, dim=-1))
- 缩放:防止点积结果过大导致梯度消失
- Softmax:沿最后一个维度(Key序列方向)归一化
- Dropout:随机丢弃部分注意力连接,增强泛化能力
经过上面的处理可以获取注意力矩阵A。A的形状是 [B, H, L, S],和score的形状相同。
V = torch.einsum("bhls,bshd->blhd", A, values)
输入维度:
A: [B, H, L, S] # [Batch, 头数, q序列长度, k序列长度]
value: [B, S, H, D] # [Batch, value序列长度, 头数, d_v]
输出维度:
V: [B, L, H, D] # [Batch, q序列长度, 头数, d_v]该运算实现了注意力机制中值加权聚合的核心步骤,将注意力权重作用于值向量。