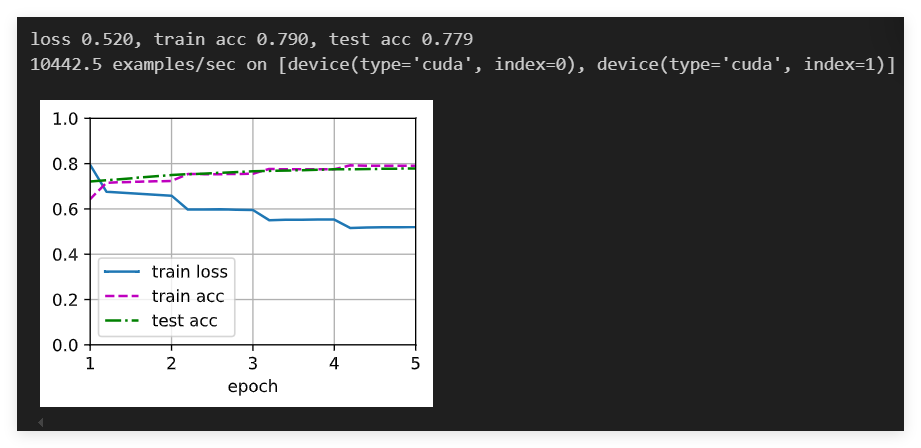
BERT 微调
BERT微调
微调 BERT
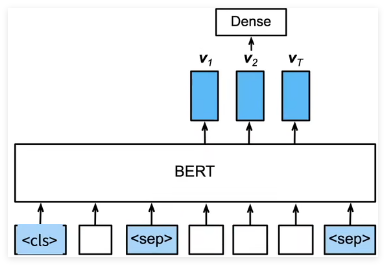
BERT 对每一个词元( token )返回抽取了上下文信息的特征向量
不同的任务使用不同的特征
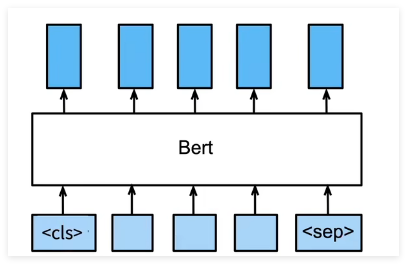
句子分类
将 < cls > 对应的向量输入到全连接层分类
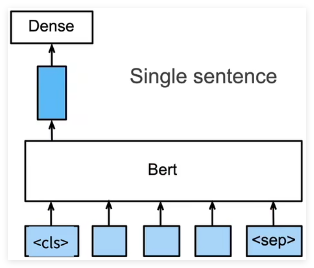
命名实体识别
识别一个词元是不是命名实体,例如人名、机构、位置
将非特殊词元放进全连接层分类
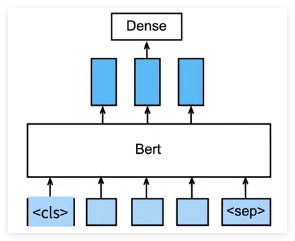
问题问答
给定一个问题,和描述文字,找出一个片段作为回答
对片段中的每个词元预测它是不是回答的开头或结束
总结
即使下游任务各有不同,使用 BERT 微调时均只需要增加输出层
但根据任务的不同,输入的表示,和使用的 BERT 特征也会不一样
自然语言推理数据集
[斯坦福自然语言推断语料库(Stanford Natural Language Inference,SNLI)]是由500000多个带标签的英语句子对组成的集合 :cite:Bowman.Angeli.Potts.ea.2015。
import os
import re
import torch
from torch import nn
from d2l import torch as d2ld2l.DATA_HUB['SNLI'] = ('https://nlp.stanford.edu/projects/snli/snli_1.0.zip','9fcde07509c7e87ec61c640c1b2753d9041758e4')data_dir = d2l.download_extract('SNLI')
Reading the Dataset
def read_snli(data_dir, is_train):"""将SNLI数据集解析为前提、假设和标签"""def extract_text(s):# 删除我们不会使用的信息s = re.sub('\\(', '', s)s = re.sub('\\)', '', s)# 用一个空格替换两个或多个连续的空格s = re.sub('\\s{2,}', ' ', s)return s.strip()label_set = {'entailment': 0, 'contradiction': 1, 'neutral': 2}file_name = os.path.join(data_dir, 'snli_1.0_train.txt'if is_train else 'snli_1.0_test.txt')with open(file_name, 'r') as f:rows = [row.split('\t') for row in f.readlines()[1:]]premises = [extract_text(row[1]) for row in rows if row[0] in label_set]hypotheses = [extract_text(row[2]) for row in rows if row[0] \in label_set]labels = [label_set[row[0]] for row in rows if row[0] in label_set]return premises, hypotheses, labels
Print the first 3 pairs
train_data = read_snli(data_dir, is_train=True)
for x0, x1, y in zip(train_data[0][:3], train_data[1][:3], train_data[2][:3]):print('前提:', x0)print('假设:', x1)print('标签:', y)

Labels " entailment " , " contradiction " , and " neutral " are balanced
test_data = read_snli(data_dir, is_train=False)
for data in [train_data, test_data]:print([[row for row in data[2]].count(i) for i in range(3)])# [183416, 183187, 182764]
# [3368, 3237, 3219]
Defining a Class for Loading the Dataset
class SNLIDataset(torch.utils.data.Dataset):"""用于加载SNLI数据集的自定义数据集"""def __init__(self, dataset, num_steps, vocab=None):self.num_steps = num_stepsall_premise_tokens = d2l.tokenize(dataset[0])all_hypothesis_tokens = d2l.tokenize(dataset[1])if vocab is None:self.vocab = d2l.Vocab(all_premise_tokens + \all_hypothesis_tokens, min_freq=5, reserved_tokens=['<pad>'])else:self.vocab = vocabself.premises = self._pad(all_premise_tokens)self.hypotheses = self._pad(all_hypothesis_tokens)self.labels = torch.tensor(dataset[2])print('read ' + str(len(self.premises)) + ' examples')def _pad(self, lines):return torch.tensor([d2l.truncate_pad(self.vocab[line], self.num_steps, self.vocab['<pad>'])for line in lines])def __getitem__(self, idx):return (self.premises[idx], self.hypotheses[idx]), self.labels[idx]def __len__(self):return len(self.premises)
Putting All Things Together
def load_data_snli(batch_size, num_steps=50):"""下载SNLI数据集并返回数据迭代器和词表"""num_workers = d2l.get_dataloader_workers()data_dir = d2l.download_extract('SNLI')train_data = read_snli(data_dir, True)test_data = read_snli(data_dir, False)train_set = SNLIDataset(train_data, num_steps)test_set = SNLIDataset(test_data, num_steps, train_set.vocab)train_iter = torch.utils.data.DataLoader(train_set, batch_size,shuffle=True,num_workers=num_workers)test_iter = torch.utils.data.DataLoader(test_set, batch_size,shuffle=False,num_workers=num_workers)return train_iter, test_iter, train_set.vocab
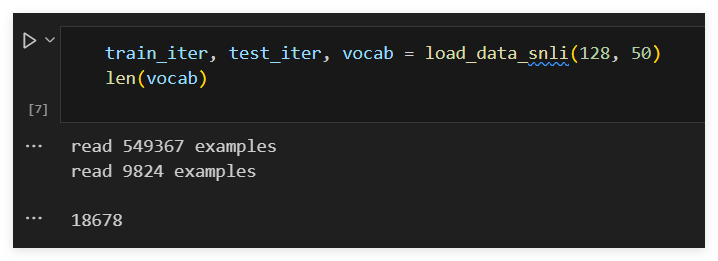
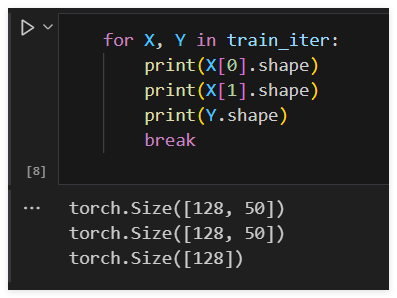
BERT微调代码
import json
import multiprocessing
import os
import torch
from torch import nn
from d2l import torch as d2l
Loading Pretrained BERT
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.torch.zip','225d66f04cae318b841a13d32af3acc165f253ac')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.torch.zip','c72329e68a732bef0452e4b96a1c341c8910f81f')
Load pretrained BERT parameters
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,num_heads, num_layers, dropout, max_len, devices):data_dir = d2l.download_extract(pretrained_model)# 定义空词表以加载预定义词表vocab = d2l.Vocab()vocab.idx_to_token = json.load(open(os.path.join(data_dir,'vocab.json')))vocab.token_to_idx = {token: idx for idx, token in enumerate(vocab.idx_to_token)}bert = d2l.BERTModel(len(vocab), num_hiddens, norm_shape=[256],ffn_num_input=256, ffn_num_hiddens=ffn_num_hiddens,num_heads=4, num_layers=2, dropout=0.2,max_len=max_len, key_size=256, query_size=256,value_size=256, hid_in_features=256,mlm_in_features=256, nsp_in_features=256)# 加载预训练BERT参数bert.load_state_dict(torch.load(os.path.join(data_dir,'pretrained.params')))return bert, vocabdevices = d2l.try_all_gpus()
bert, vocab = load_pretrained_model('bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,num_layers=2, dropout=0.1, max_len=512, devices=devices)
The Dataset for Fine-Tuning BERT
class SNLIBERTDataset(torch.utils.data.Dataset):def __init__(self, dataset, max_len, vocab=None):all_premise_hypothesis_tokens = [[p_tokens, h_tokens] for p_tokens, h_tokens in zip(*[d2l.tokenize([s.lower() for s in sentences])for sentences in dataset[:2]])]self.labels = torch.tensor(dataset[2])self.vocab = vocabself.max_len = max_len(self.all_token_ids, self.all_segments,self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens)print('read ' + str(len(self.all_token_ids)) + ' examples')def _preprocess(self, all_premise_hypothesis_tokens):pool = multiprocessing.Pool(4) # 使用4个进程out = pool.map(self._mp_worker, all_premise_hypothesis_tokens)all_token_ids = [token_ids for token_ids, segments, valid_len in out]all_segments = [segments for token_ids, segments, valid_len in out]valid_lens = [valid_len for token_ids, segments, valid_len in out]return (torch.tensor(all_token_ids, dtype=torch.long),torch.tensor(all_segments, dtype=torch.long),torch.tensor(valid_lens))def _mp_worker(self, premise_hypothesis_tokens):p_tokens, h_tokens = premise_hypothesis_tokensself._truncate_pair_of_tokens(p_tokens, h_tokens)tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens)token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \* (self.max_len - len(tokens))segments = segments + [0] * (self.max_len - len(segments))valid_len = len(tokens)return token_ids, segments, valid_lendef _truncate_pair_of_tokens(self, p_tokens, h_tokens):# 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置while len(p_tokens) + len(h_tokens) > self.max_len - 3:if len(p_tokens) > len(h_tokens):p_tokens.pop()else:h_tokens.pop()def __getitem__(self, idx):return (self.all_token_ids[idx], self.all_segments[idx],self.valid_lens[idx]), self.labels[idx]def __len__(self):return len(self.all_token_ids)
Generate training and testing examples
# 如果出现显存不足错误,请减少“batch_size”。在原始的BERT模型中,max_len=512
batch_size, max_len, num_workers = 512, 128, d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size, shuffle=True,num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(test_set, batch_size,num_workers=num_workers)# read 549367 examples
# read 9824 examples
This MLP transforms the BERT representation of the special “< cls >” token into three outputs of natural language inference
class BERTClassifier(nn.Module):def __init__(self, bert):super(BERTClassifier, self).__init__()self.encoder = bert.encoderself.hidden = bert.hiddenself.output = nn.Linear(256, 3)def forward(self, inputs):tokens_X, segments_X, valid_lens_x = inputsencoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)return self.output(self.hidden(encoded_X[:, 0, :]))net = BERTClassifier(bert)
The training
lr, num_epochs = 1e-4, 5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)