【AI】Ubuntu 22.04 4060Ti 16G vllm-api部署Qwen3-8B-FP8
下载模型
# 非常重要,否则容易不兼容报错
pip install modelscope -U
cd /data/ai/models
modelscope download --model Qwen/Qwen3-8B-FP8 --local_dir ./Qwen3-8B-FP8安装vllm
创建虚拟环境
mkdir vllm
cd vllm/
python -m venv venv
ource venv/bin/activate
安装vllm
# 安装vLLM框架及ModelScope
pip install modelscope vllm -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com# 安装FlashAttention优化模块
# 安装系统级构建工具
sudo apt-get install build-essential python3-dev
# 安装Python构建工具
pip install setuptools wheel ninja -i https://mirrors.aliyun.com/pypi/simple/# 更新Transformers库
pip install --upgrade transformers -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com
启动vllm openapi服务器
vllm serve /data/ai/models/Qwen3-8B-FP8 \
--served-model-name Qwen3-8B-FP8 \
--port 8000 \
--dtype auto \
--gpu-memory-utilization 0.8 \
--max-model-len 4096 \
--tensor-parallel-size 1
启动日志
(venv) yeqiang@yeqiang-Default-string:/data/ai/vllm$ vllm serve /data/ai/models/Qwen3-8B-FP8 --served-model-name Qwen3-8B-FP8 --port 8000 --dtype auto --gpu-memory-utilization 0.8 --max-model-len 4096 --tensor-parallel-size 1
INFO 05-06 20:48:11 [__init__.py:239] Automatically detected platform cuda.
INFO 05-06 20:48:14 [api_server.py:1043] vLLM API server version 0.8.5.post1
INFO 05-06 20:48:14 [api_server.py:1044] args: Namespace(subparser='serve', model_tag='/data/ai/models/Qwen3-8B-FP8', config='', host=None, port=8000, uvicorn_log_level='info', disable_uvicorn_access_log=False, allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, chat_template_content_format='auto', response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, enable_ssl_refresh=False, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_request_id_headers=False, enable_auto_tool_choice=False, tool_call_parser=None, tool_parser_plugin='', model='/data/ai/models/Qwen3-8B-FP8', task='auto', tokenizer=None, hf_config_path=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, allowed_local_media_path=None, load_format='auto', download_dir=None, model_loader_extra_config={}, use_tqdm_on_load=True, config_format=<ConfigFormat.AUTO: 'auto'>, dtype='auto', max_model_len=4096, guided_decoding_backend='auto', reasoning_parser=None, logits_processor_pattern=None, model_impl='auto', distributed_executor_backend=None, pipeline_parallel_size=1, tensor_parallel_size=1, data_parallel_size=1, enable_expert_parallel=False, max_parallel_loading_workers=None, ray_workers_use_nsight=False, disable_custom_all_reduce=False, block_size=None, gpu_memory_utilization=0.8, swap_space=4, kv_cache_dtype='auto', num_gpu_blocks_override=None, enable_prefix_caching=None, prefix_caching_hash_algo='builtin', cpu_offload_gb=0, calculate_kv_scales=False, disable_sliding_window=False, use_v2_block_manager=True, seed=None, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, hf_token=None, hf_overrides=None, enforce_eager=False, max_seq_len_to_capture=8192, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config={}, limit_mm_per_prompt={}, mm_processor_kwargs=None, disable_mm_preprocessor_cache=False, enable_lora=None, enable_lora_bias=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=None, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', speculative_config=None, ignore_patterns=[], served_model_name=['Qwen3-8B-FP8'], qlora_adapter_name_or_path=None, show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, max_num_batched_tokens=None, max_num_seqs=None, max_num_partial_prefills=1, max_long_partial_prefills=1, long_prefill_token_threshold=0, num_lookahead_slots=0, scheduler_delay_factor=0.0, preemption_mode=None, num_scheduler_steps=1, multi_step_stream_outputs=True, scheduling_policy='fcfs', enable_chunked_prefill=None, disable_chunked_mm_input=False, scheduler_cls='vllm.core.scheduler.Scheduler', override_neuron_config=None, override_pooler_config=None, compilation_config=None, kv_transfer_config=None, worker_cls='auto', worker_extension_cls='', generation_config='auto', override_generation_config=None, enable_sleep_mode=False, additional_config=None, enable_reasoning=False, disable_cascade_attn=False, disable_log_requests=False, max_log_len=None, disable_fastapi_docs=False, enable_prompt_tokens_details=False, enable_server_load_tracking=False, dispatch_function=<function ServeSubcommand.cmd at 0x7f2d48275000>)
INFO 05-06 20:48:18 [config.py:717] This model supports multiple tasks: {'generate', 'reward', 'embed', 'score', 'classify'}. Defaulting to 'generate'.
INFO 05-06 20:48:18 [config.py:2003] Chunked prefill is enabled with max_num_batched_tokens=2048.
WARNING 05-06 20:48:18 [fp8.py:63] Detected fp8 checkpoint. Please note that the format is experimental and subject to change.
INFO 05-06 20:48:20 [__init__.py:239] Automatically detected platform cuda.
INFO 05-06 20:48:22 [core.py:58] Initializing a V1 LLM engine (v0.8.5.post1) with config: model='/data/ai/models/Qwen3-8B-FP8', speculative_config=None, tokenizer='/data/ai/models/Qwen3-8B-FP8', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=4096, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=fp8, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='auto', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=Qwen3-8B-FP8, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"level":3,"custom_ops":["none"],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output"],"use_inductor":true,"compile_sizes":[],"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":512}
WARNING 05-06 20:48:22 [utils.py:2522] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x7fdf82584790>
INFO 05-06 20:48:22 [parallel_state.py:1004] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 05-06 20:48:22 [cuda.py:221] Using Flash Attention backend on V1 engine.
WARNING 05-06 20:48:22 [topk_topp_sampler.py:69] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
INFO 05-06 20:48:22 [gpu_model_runner.py:1329] Starting to load model /data/ai/models/Qwen3-8B-FP8...
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:00<00:00, 1.98it/s]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.75it/s]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [00:01<00:00, 1.78it/s]INFO 05-06 20:48:23 [loader.py:458] Loading weights took 1.18 seconds
WARNING 05-06 20:48:23 [kv_cache.py:128] Using Q scale 1.0 and prob scale 1.0 with fp8 attention. This may cause accuracy issues. Please make sure Q/prob scaling factors are available in the fp8 checkpoint.
INFO 05-06 20:48:23 [gpu_model_runner.py:1347] Model loading took 8.8011 GiB and 1.314728 seconds
INFO 05-06 20:48:30 [backends.py:420] Using cache directory: /home/yeqiang/.cache/vllm/torch_compile_cache/075128b044/rank_0_0 for vLLM's torch.compile
INFO 05-06 20:48:30 [backends.py:430] Dynamo bytecode transform time: 6.33 s
INFO 05-06 20:48:33 [backends.py:136] Cache the graph of shape None for later use
INFO 05-06 20:48:53 [backends.py:148] Compiling a graph for general shape takes 22.83 s
WARNING 05-06 20:48:54 [fp8_utils.py:431] Using default W8A8 Block FP8 kernel config. Performance might be sub-optimal! Config file not found at /data/ai/vllm/venv/lib/python3.10/site-packages/vllm/model_executor/layers/quantization/utils/configs/N=6144,K=4096,device_name=NVIDIA_GeForce_RTX_4060_Ti,dtype=fp8_w8a8,block_shape=[128,128].json
WARNING 05-06 20:48:56 [fp8_utils.py:431] Using default W8A8 Block FP8 kernel config. Performance might be sub-optimal! Config file not found at /data/ai/vllm/venv/lib/python3.10/site-packages/vllm/model_executor/layers/quantization/utils/configs/N=4096,K=4096,device_name=NVIDIA_GeForce_RTX_4060_Ti,dtype=fp8_w8a8,block_shape=[128,128].json
WARNING 05-06 20:48:56 [fp8_utils.py:431] Using default W8A8 Block FP8 kernel config. Performance might be sub-optimal! Config file not found at /data/ai/vllm/venv/lib/python3.10/site-packages/vllm/model_executor/layers/quantization/utils/configs/N=24576,K=4096,device_name=NVIDIA_GeForce_RTX_4060_Ti,dtype=fp8_w8a8,block_shape=[128,128].json
WARNING 05-06 20:48:56 [fp8_utils.py:431] Using default W8A8 Block FP8 kernel config. Performance might be sub-optimal! Config file not found at /data/ai/vllm/venv/lib/python3.10/site-packages/vllm/model_executor/layers/quantization/utils/configs/N=4096,K=12288,device_name=NVIDIA_GeForce_RTX_4060_Ti,dtype=fp8_w8a8,block_shape=[128,128].json
INFO 05-06 20:49:28 [monitor.py:33] torch.compile takes 29.15 s in total
INFO 05-06 20:49:29 [kv_cache_utils.py:634] GPU KV cache size: 11,184 tokens
INFO 05-06 20:49:29 [kv_cache_utils.py:637] Maximum concurrency for 4,096 tokens per request: 2.73x
INFO 05-06 20:49:54 [gpu_model_runner.py:1686] Graph capturing finished in 25 secs, took 2.61 GiB
INFO 05-06 20:49:54 [core.py:159] init engine (profile, create kv cache, warmup model) took 90.51 seconds
INFO 05-06 20:49:54 [core_client.py:439] Core engine process 0 ready.
WARNING 05-06 20:49:54 [config.py:1239] Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
INFO 05-06 20:49:54 [serving_chat.py:118] Using default chat sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
INFO 05-06 20:49:54 [serving_completion.py:61] Using default completion sampling params from model: {'temperature': 0.6, 'top_k': 20, 'top_p': 0.95}
INFO 05-06 20:49:54 [api_server.py:1090] Starting vLLM API server on http://0.0.0.0:8000
INFO 05-06 20:49:54 [launcher.py:28] Available routes are:
INFO 05-06 20:49:54 [launcher.py:36] Route: /openapi.json, Methods: GET, HEAD
INFO 05-06 20:49:54 [launcher.py:36] Route: /docs, Methods: GET, HEAD
INFO 05-06 20:49:54 [launcher.py:36] Route: /docs/oauth2-redirect, Methods: GET, HEAD
INFO 05-06 20:49:54 [launcher.py:36] Route: /redoc, Methods: GET, HEAD
INFO 05-06 20:49:54 [launcher.py:36] Route: /health, Methods: GET
INFO 05-06 20:49:54 [launcher.py:36] Route: /load, Methods: GET
INFO 05-06 20:49:54 [launcher.py:36] Route: /ping, Methods: GET, POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /tokenize, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /detokenize, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/models, Methods: GET
INFO 05-06 20:49:54 [launcher.py:36] Route: /version, Methods: GET
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/chat/completions, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/completions, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/embeddings, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /pooling, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /score, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/score, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/audio/transcriptions, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /rerank, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v1/rerank, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /v2/rerank, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /invocations, Methods: POST
INFO 05-06 20:49:54 [launcher.py:36] Route: /metrics, Methods: GET
INFO: Started server process [201874]
INFO: Waiting for application startup.
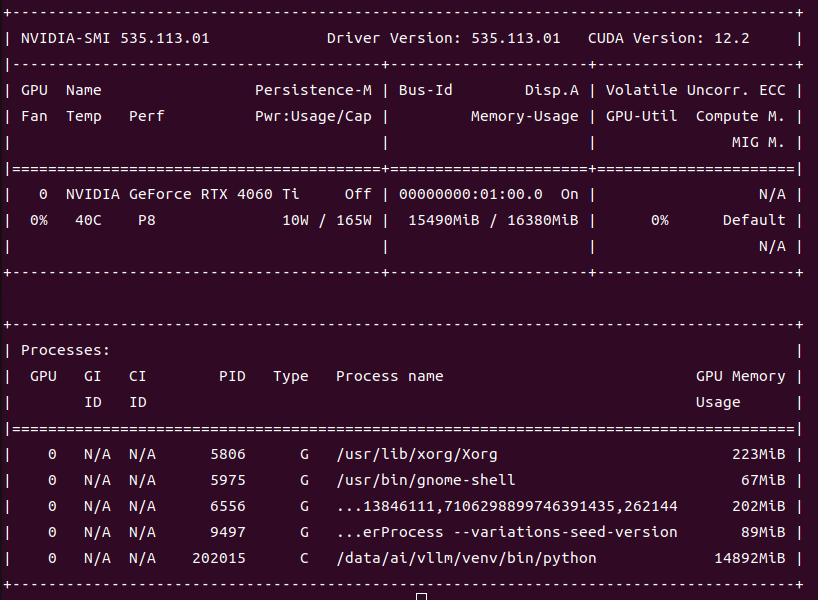
INFO: Application startup complete.验证基本服务状态
yeqiang@yeqiang-Default-string:/data/ai/vllm$ curl http://localhost:8000/v1/models
{"object":"list","data":[{"id":"Qwen3-8B-FP8","object":"model","created":1746535967,"owned_by":"vllm","root":"/data/ai/models/Qwen3-8B-FP8","parent":null,"max_model_len":4096,"permission":[{"id":"modelperm-9c2faa75985d4efabc3ddf63942c3f04","object":"model_permission","created":1746535967,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}GPU状态