Elasticsearch知识汇总之ElasticSearch与OpenSearch比较
四 ElasticSearch与OpenSearch比较
OpenSearch项目分为 OpenSearch(源自 Elasticsearch 7.10.2)与 OpenSearch Dashboards(源自 Kibana 7.10.2)两部分。此外,OpenSearch 项目也将成为之前发布的 Elasticsearch 发行版(即 Open Distro for Elasticsearch )的“新家”,在这里为广大用户提供企业级的安全、警报、机器学习、SQL、索引状态管理等多项功能。
OpenSearch 项目中的所有软件都是遵循 Apache 2.0许可证(ALv2)所发布。
OpenSearch和ElasticSearch的产品线比较,对比我们可以参考如下:
OpenSearch提供了很多开源ES中不可用的功能
| Features | Description |
| Advanced Security | Offers encryption, authentication, authorization, and auditing features. They include integrations with Active Directory, LDAP, SAML, Kerberos, JSON web tokens, and more. OpenSearch also provides fine-grained, role-based access control to indices, documents, and fields. |
| SQL Query Syntax | Provides the familiar SQL query syntax. Use aggregations, group by, and where clauses to investigate your data. Read data as JSON documents or CSV tables so you have the flexibility to use the format that works best for you. |
| Reporting | Schedule, export, and share reports from dashboards, saved searches, alerts, and visualizations. |
| Anomaly Detection | Use machine learning anomaly detection based on the Random Cut Forest (RCF) algorithm to automatically detect anomalies as your data is ingested. Combine with alerting to monitor data in near real time and send alert notifications automatically. |
| Index Management | Define custom policies to automate routine index management tasks, such as rollover and delete, apply them to indices and index patterns, and transforms. |
| Performance Analyzer and RCA Framework | Query numerous cluster performance metrics and aggregations. Use PerfTop, the command line interface (CLI) to quickly display and analyze those metrics. Use the root cause analysis (RCA) framework to investigate performance and reliability issues in clusters. |
| Asynchronous Search | Run complex queries without worrying about the query timing out with Asynchronous Search queries running in the background. Track query progress and retrieve partial results as they become available. |
| Trace Analytics | Ingest and visualize OpenTelemetry data for distributed applications. Visualize the flow of events between these applications to identify performance problems. |
| Alerting | Automatically monitor data and send alert notifications to stakeholders. With an intuitive interface and a powerful API, easily set up, manage, and monitor alerts. Craft highly specific alert conditions using OpenSearch’s full query language and scripting capabilities. |
| k-NN search | Using machine learning, run the nearest neighbor search algorithm on billions of documents across thousands of dimensions with the same ease as running any regular OpenSearch query. Use aggregations and filter clauses to further refine similarity search operations. k-NN similarity search powers use cases such as product recommendations, fraud detection, image and video search, related document search, and more. |
| Piped Processing Language | Provides a familiar query syntax with a comprehensive set of commands delimited by pipes (\ |
| Dashboard Notebooks | Combine dashboards, visualizations, text, and more to provide context and detailed explanations when analyzing data. |
ElasticSearch和OpenSearch组件的对比

从图上可以看出,原来的Elasticsearch实例,就是OpenSearch实例。而Kibana在OpenSearch体系里面叫做OpenSearch Dashboards。原来为ES开发的插件OpenDistro完全变成了OpenSearch的插件,来实现我们刚才说的那些功能,且完全免费。
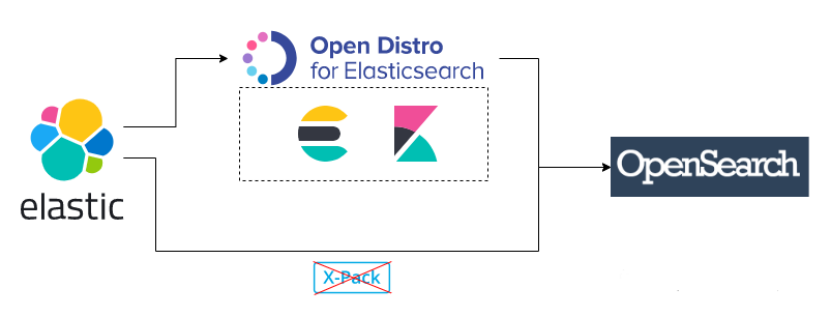
以X-Pack为例,在OpenSearch中叫做OpenSearch-security,以plugin的形式随着二进制包一起被下载。
容量估算,容量估算的公式基本和ES的估算方式一样,且各个功能节点的预估也和ES一样
认证集成和ES的x-pack一样,常见的认证方式都可以支持。
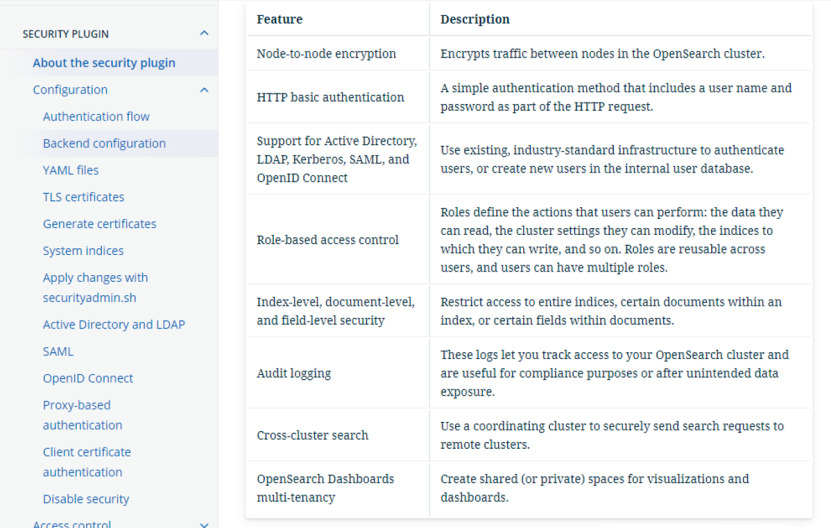
OpenSearch多种中英文分词器、行业分词器,均来自阿里NLP的技术成果,效果明显好于开源分词器。内置已成熟的多种高级算法功能,用户在控制台通过简单的交互即可使用,无需额外自主研发,搜索效果即可一键提升。人工干预功能即干预即生效。
Elasticsearch开源产品更加灵活,对于有开发能力的客户来说,使用Elasticsearch可以自研更适合自身业务的插件和算法使用,并且迭代节奏完全可以自行把控。数据接入方式基本没有局限。所以不管业务数据存放在哪里都可以较方便的接入Elasticsearch。品牌软实力,全世界闻名的开源搜索引擎。没有数据敏感性的困扰。
OpenSearch:数据接入方式相比Elasticsearch来说较局限,目前仅支持云上的rds、odps或用户通过API/SDK的方式推送。基本上所有的算法功能都是黑盒的,用户无法根据业务自己迭代opensearch的算法功能,灵活性不够;服务部署目前暂时较少
Elasticsearch如果对搜索效果有较高要求,Elasticsearch的开发难度相对较高,比如OpenSearch默认支持两轮排序,用户在控制台上填写每轮排序表达式即可,但是Elasticsearch的两轮排序的实现对于索引配置的合理性有要求。自定义分词文件每次上传都需要重启服务,方便性较弱。需要复杂繁琐的运维。