干货分享|检索增强生成技术RAG:向量化与大模型的结合
本文我们将来学习一个与现在 AGI 时代合作紧密的技术 RAG, 这是每个 AIGC 方向开发不得不掌握的能力。
为什么需要使用RAG
该模块将介绍 RAG 的应用场景,以及与模型微调方案的差异
模型Agent需要额外的信息穿透
使用模型Agent时,对于一些不在基座模型训练数据中的信息,模型无法做出精准回答,即使回答了,也是错误的答复。当模型 Agent 用于外部或者一些通用场景时,这个问题可能还可以被忽略。但在内网场景,或者存在信息壁垒的场景使用时,这个问题会严重影响用户的体验,比如下列的一些场景:
·AI oncall:面向研发的一些内部AI oncall机器人,需要针对内网自研的基建进行专业答复。
·代码生成类的基建:需要对研发代码进行推荐和生成,缺乏一些内网库的使用无法更精准生成。
·直播审核辅助:面向直播审核员的辅助功能,需要知道内部制定的一些审核策略或背景。
面对这类问题,需要对模型 Agent 进行额外的信息穿透,信息穿透的大方向主要是两种方式:
1.准备一定体量的对应场景训练集,通过微调等训练方式调整基座模型的参数。
2.通过一些手段手动补全 Prompt 上下文,RAG就是一个常用的手段
微调的高成本和长期投入
对于这两种模型 Agent 信息扩展的方案而言,单论效果,对基底模型进行高质量微调的效果是更好的。因为还没介绍具体的方案,所以先使用类比来说明微调和RAG的过程:
·高质量微调:对基底模型的部分参数进行调整或者补充,已经深入理解了对应场景的知识点、正反面 case以及与其他知识图谱的关系,可以灵活使用,微调训练后,相关知识点作为基底模型的包含关系,是一个整体。
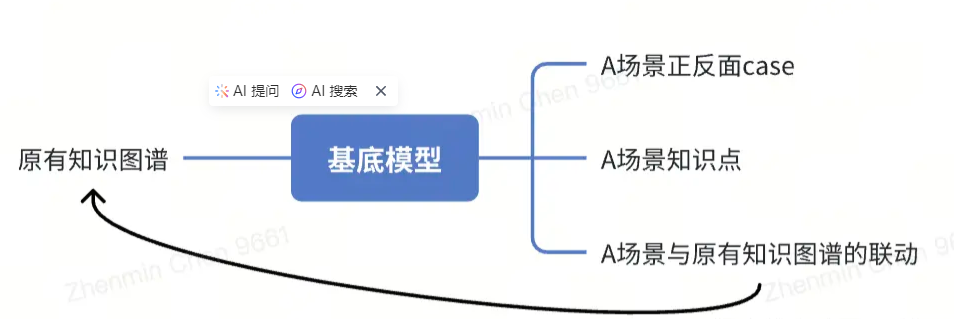
·RAG: 拿一本你从来没看过的书中的片段给你参考进行开卷考试,回答的质量决定于参考片段与问题本身的关联度,拿掉参考片段模型还是不会。

一个是熟练掌握,另一个是对着书开卷考,很明显前者(高质量微调)的效果是远比后者(RAG)好的,也没有对书本的依赖。单次微调的大致过程如下流程图。
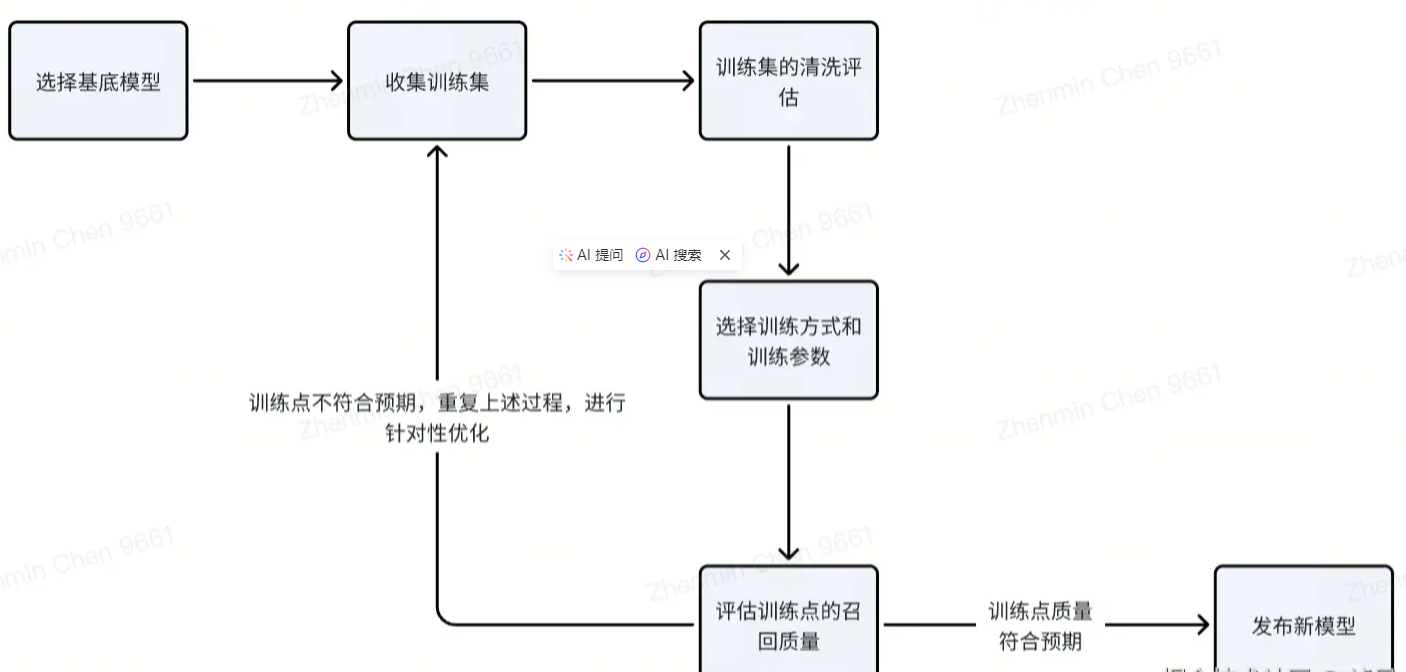
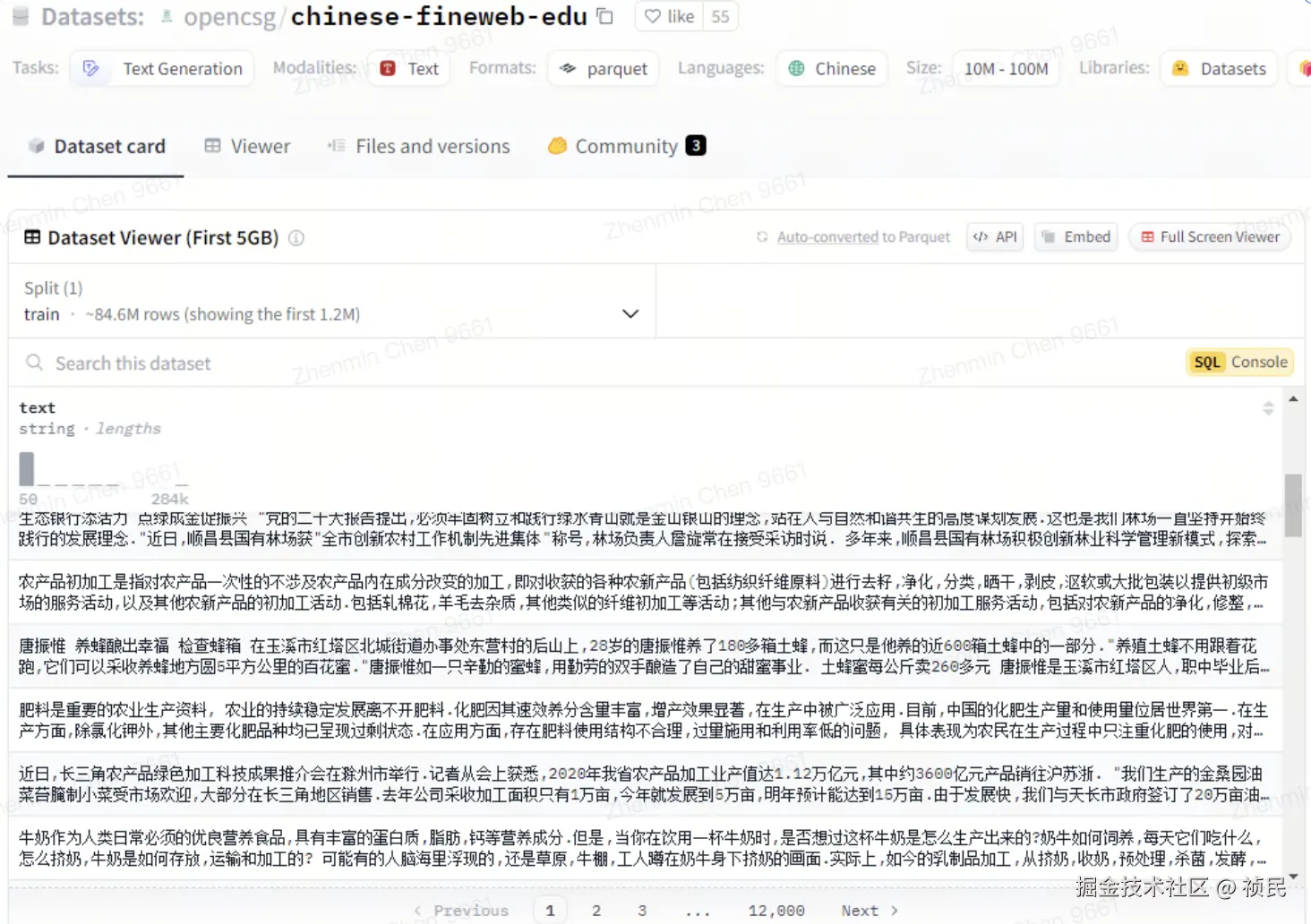
1.训练使用的数据集有体量和质量要求,收集和清洗需要大量人力时间成本,例如Hugging Face中的开源中文数据集opencsg/chinese-fineweb-edu数据量就有几十万条优质数据。
2.微调需要比较高的算力,有硬件成本的要求,在中国市场NVIDIA A100芯片的售价为22,500美元,对于某专一场景的模型训练,通常为了减少单次微调的时间会使用多卡训练,单次任务使用8 - 10张 A100也是很常见的,硬件跟不上单次微调时间会很长。
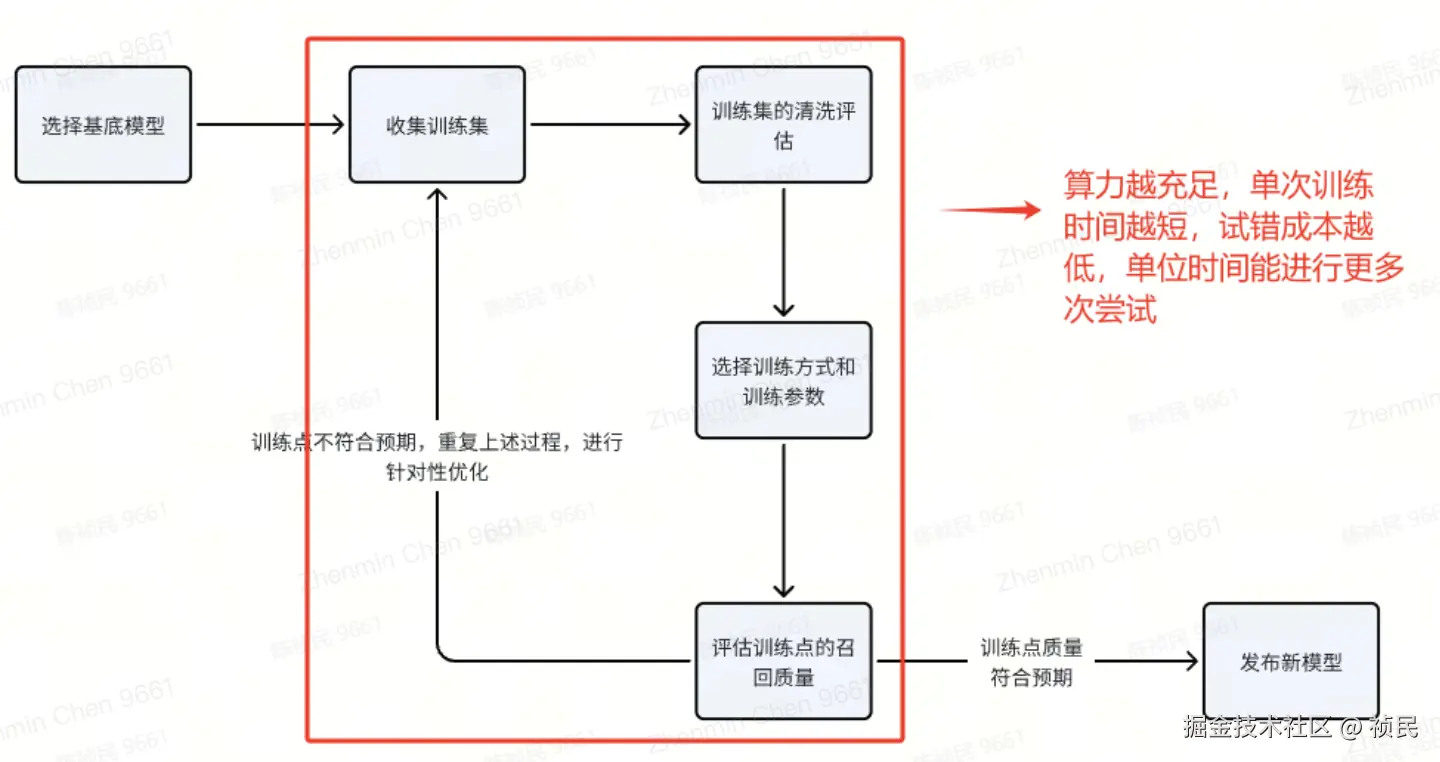
3.单次微调后还有评估过程,需要根据训练点的评估效果调整整个训练过程的训练集和训练参数等,是一个反复试错且长期的过程,很难通过1,2次微调就产生质的突破(除非你是天命人,实力运气都拉满)
更低成本的信息穿透方案RAG
世界上的任何原始数据都可以根据某项特点的程度而打上向量,向量值越高代表这个原始数据的对应特征越强烈,例如下图的二维向量坐标轴。

原始数据可以呈现为坐标轴的点位,点位间的距离越近就代表两者间的相似程度越高,例如上图中,单论年纪大小和是否趋近生活这两个点,“一个中年人在打电玩”与“工程师在开会”的相似程度,就高于“一个年迈的人在市场买菜”与“一群小孩子在吟诗作对”的相似程度。
这个原理同样在多维坐标系中也是成立的,理论上说,只要原始数据在指定特点的特征标记越精准,点位间的距离就能作为原始数据间相似程度的标准参考。不难理解,这样找寻原始数据的相似问题其实就转化为了下面两个步骤:
1.将原始数据进行指定特点的特征打标,也就是上图向量化的过程,向量化越精准,相似匹配的精度也会越高
2.根据多维坐标系的特点,使用指定算法(比如最常用的余弦相似度)计算距离,进而推算原始数据之间的相似程度,进行相似匹配。
这个为原始过程进行特征提取和打标的过程,也叫特征工程。不仅是大模型领域,在很多其他领域,比如直播的个性化推荐、风控策略等需要分析原始数据特点和相似性的场景中,都起到了重要的作用。
上面的相似匹配过程就是检索,将检索的相似信息传递给模型进一步辅助生成的过程就是RAG。 通过这种信息穿透的方式,模型就能更低成本地扩展能力,回答因原本信息缺失无法精准答复的问题。
RAG 与 Agent 结合的 MVP 案例
该模块将基于开源模型实现一个使用 RAG 扩展 Agent 的最简 MVP 案例
扩展的知识库内容(虚构的故事):
在遥远的荷兰小镇,有一个名叫拉姆斯特拉的男孩,他自小就对法律充满了浓厚的兴趣。他的父亲是一位小镇上的法官,母亲则是一名教师,家庭的熏陶让他早早地懂得了正义与公平的价值。每当夜幕降临,拉姆斯特拉都会坐在窗前,手捧一本法律书籍,沉浸在知识的海洋中,梦想着有一天能成为像父亲那样受人尊敬的法律人士。
成年后,拉姆斯特拉考入了荷兰著名的莱顿大学法学系,那里汇聚了来自世界各地的法学精英。在这里,他不仅深化了自己的法律知识,还学会了多国语言,这为他日后成为国际法务专家打下了坚实的基础。大学期间,他还积极参与各种辩论赛和模拟法庭,这些经历极大地锻炼了他的逻辑思维能力和口才。
拉姆斯特拉先生的喜好十分广泛,他热爱阅读,尤其是历史类书籍,他认为了解历史是理解法律演变的关键。此外,他还是一名狂热的足球迷,闲暇时喜欢观看欧洲各大联赛,甚至偶尔会亲自上场踢几脚,这种团队合作的精神也深深影响了他在工作中的态度。
毕业后,拉姆斯特拉先生加入了雷姆法雷斯公司,负责处理复杂的跨国法律事务。他的工作节奏紧张而有序,每天清晨,他都会提前到办公室,先浏览最新的法律动态和行业资讯,然后开始处理手头的案件。他对每一个细节都要求严谨,力求在法律框架内为客户找到最优化的解决方案。尽管工作繁忙,但他总能保持冷静和耐心,这份专业精神赢得了同事和客户的高度赞誉。
拉姆斯特拉先生的人生理想是成为一名全球知名的法律专家,他希望通过自己的努力,推动国际法律体系的完善,为促进世界和平与发展贡献一份力量。他相信,法律不仅仅是规则的制定,更是社会公正与和谐的基石。在这个理想的引领下,拉姆斯特拉先生正以他的智慧和热情,一步步向着目标迈进。
基于Hugging face开源模型完成原始数据向量化
原始数据向量化通常使用模型完成,可以考虑使用 OpenAI 提供的 embeddings 端点,或者开源模型。对于开源模型,可以使用Hugging Face中提供的 Feature Extraction 类别,其中大部分开源模型都是可以对原始数据进行多维特征向量化的。
下面使用的是intfloat/multilingual-e5-large模型进行向量化,Feature Extraction模型通常也区分中英文训练集,会在名字中体现,名字中有multilingual字样的通常表示它兼容跨语言的特征提取任务,可以根据自己的需求选取。
我们来调用intfloat/multilingual-e5-large,通常这类开源模型的调用都是私有化部署到本地后使用,这个过程需要依赖比较多和机器学习相关的包,会使用 Anaconda 进行环境管理,大家可以自行查阅下安装,安装后进行下面的步骤:
1.使用 conda 创建一个独立的 python 环境:
conda create --name rag_test python=3.11
conda activate rag_test2. 安装以下依赖:
代码解读复制代码
pip3 install transformers torch numpy上述依赖的作用如下:
·transformers: Hugging Face提供的库,用于处理开源模型推理、预训练等一系列相关工作。
·torch: 深度学习的库,transformers库依赖于PyTorch(或TensorFlow)来加载和运行预训练模型。
·numpy:数值计算,可以将机器学习库中的特定数据结构转成 python 常规数据结构,例如 torch.Tensor 转 python 列表
3.创建 python 脚本,写一个简单的服务,里面使用 transformers 库加载 intfloat/multilingual-e5-large 模型进行推理将指定文本向量化:
printf("hello wofrom transformers import AutoTokenizer, AutoModel
# 加载预训练的分词器和模型
tokenizer = AutoTokenizer.from_pretrained("
intfloat/multilingual-e5-large
")
model = AutoModel.from_pretrained("
intfloat/multilingual-e5-large
")
texts = ["
这是一个测试文本。
", "
This is a test text.
"]
# 使用分词器对输入文本进行编码
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="
pt
")
# 取降维后的重要特征信息
embeddings = model(**inputs).pooler_output
print(embeddings.detach().numpy())终端执行效果如下,可以看到原始数据已经向量化了。

使用向量数据库Chroma评估文本相似程度
在对文本进行向量提取后,通过计算向量间的距离就可以评估文本间的相似程度,这个过程常常会使用向量数据库完成文本向量的存储和相似匹配。与常规数据库不同,向量数据库是一种专门设计用于存储和查询高维向量的数据管理系统,社区中有非常多的成熟向量数据库选择,例如Chroma,Qdrant,Faiss等,下面我们以 Chroma 举例如何完成相似性匹配。
Chroma 是一个开源的向量数据库,设计用于高效管理和查询向量数据。它支持Python和JavaScript语言,并且易于与现有的LLM(Large Language Model)框架集成,如LangChain和LlamaIndex。当然这里选择它来示范的核心原因是轻量化并且上手简单,很适合与LLM应用结合,使用pip完成安装即可:
pip3 install chromadb最基础示例
Chroma有内置的默认向量化模型(huggingface.co/sentence-tr… )和相似算法(Squared l2),所以即使不配置也可以快速对一系列文本进行相似评估,比如下面的示例:
# 使用内置的onnx_mini_lm_l6_v2
from chromadb.utils.embedding_functions.onnx_mini_lm_l6_v2 import ONNXMiniLM_L6_V2
# CPU 推理
ef = ONNXMiniLM_L6_V2(preferred_providers=["CPUExecutionProvider"])
import chromadb
# 非持久化实例
chroma_client = chromadb.Client()
# 存储集合
collection = chroma_client.create_collection(name="my_collection", embedding_function=ef)
collection.add(documents=["This is a document about apple","This is a document about oranges", "Something will happen tomorrow"
],ids=["id1", "id2", "id3"])
# 相似匹配
results = collection.query(query_texts=["This is a query document about oranges"],n_results=1)
print(results)上面示例效果如下,可以看到chroma完成了相似文本的评估匹配:

不过上述的示例是非持久化存储,每次使用都需要重新初始化,添加过的向量也不会存储,如果需要换成本地服务存储可以参考以下示例:
# 使用内置的onnx_mini_lm_l6_v2
from chromadb.utils.embedding_functions.onnx_mini_lm_l6_v2 import ONNXMiniLM_L6_V2
# CPU 推理
ef = ONNXMiniLM_L6_V2(preferred_providers=["CPUExecutionProvider"])
import chromadb
# 持久化存储
chroma_client = chromadb.PersistentClient(path="./chroma_data")
try:collection = chroma_client.get_collection(name="my_collection", embedding_function=ef)
except:collection = chroma_client.create_collection(name="my_collection", embedding_function=ef, metadata={"hnsw:space": "cosine"})
collection.add(documents=["This is a document about apple","This is a document about oranges", "Something will happen tomorrow"
],ids=["id1", "id2", "id3"])
# 相似匹配
results = collection.query(query_texts=["This is a query document about oranges"],n_results=1)
print(results)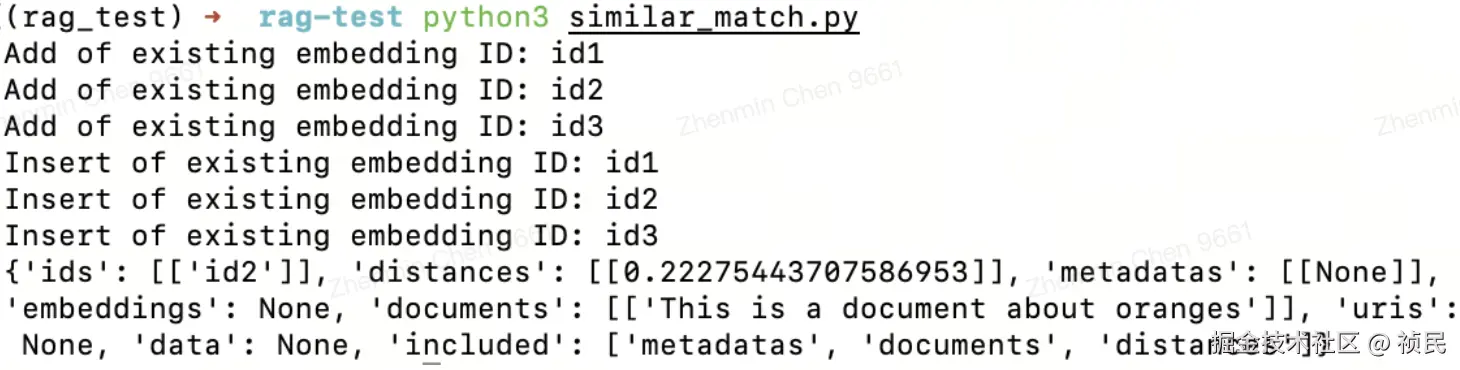
Chroma提供的内置向量距离算法
更多相似匹配算法参考Distance Metrics in Vector Search | Weaviate
Chroma提供了以下内置向量距离算法,默认使用Squared L2:
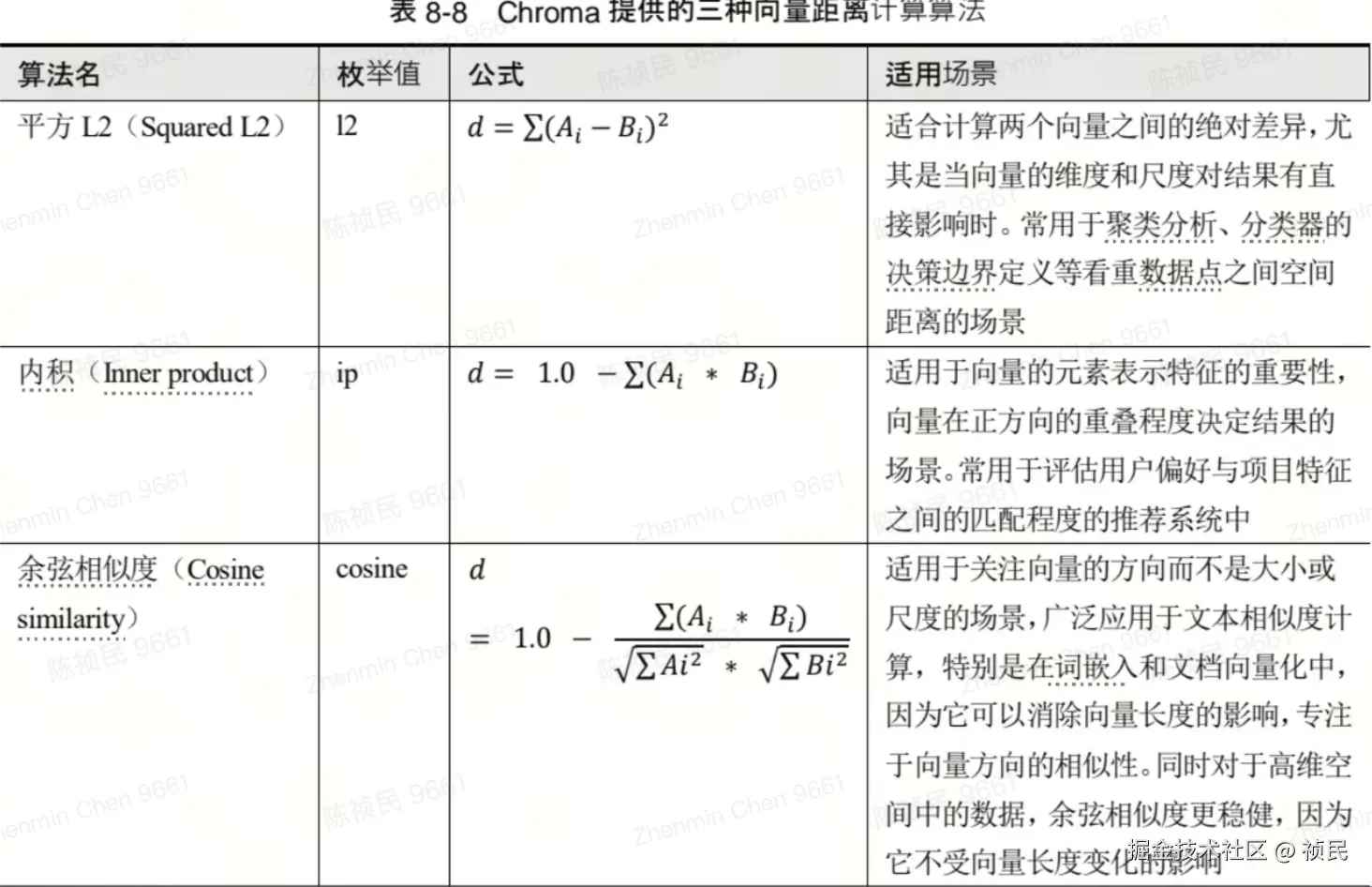
对于文本相似度的场景,平方 L2 和余弦相似度都能满足需求,内积则不适合用于这个场景,更多地广泛用于推荐算法或者其他特征工程中。
而平方 L2 和余弦相似度中,余弦相似度在高维度的场景下会有更优的效果,相比平方 L2 算法直接的物理距离,余弦相似度更关注向量的方向,也就是向量在某个特征上的程度,而不受向量长度变化的影响,所以对于文本相似度的场景,虽然平方 L2 也可以满足基本场景的需求,但更推荐使用余弦相似度的计算方式来获取更好的相似度匹配。
指定向量距离算法只需要加一个参数即可,例如:
collection = chroma_client.get_collection(# ...other paramsmetadata={"hnsw:space": "cosine"}
)自定义向量模型
Chromadb 除使用内置模型外,也支持使用开源模型,下面来示范如何使用Hugging Face开源模型完成文本向量化的过程:
import chromadb
from transformers import AutoTokenizer, AutoModel
from chromadb import Documents, EmbeddingFunction
from typing import List
# chromadb 接收的自定义 embeddings function,需要实现 EmbeddingFunction 类
class TestEmbeddingFunction(EmbeddingFunction):def __init__(self, model_name: str):self.tokenizer
= AutoTokenizer.from_pretrained(model_name)self.model = AutoModel.from_pretrained(model_name)
def __call__(self, texts: Documents) -> List[List[float]]:inputs = self.tokenizer(texts, padding=True, truncation=True, return_tensors="pt")embeddings = self.model(**inputs).pooler_outputreturn embeddings.detach().numpy().tolist()
# 持久化存储
chroma_client = chromadb.PersistentClient(path="./chroma_data")
try:collection = chroma_client.get_collection(name="my_collection", embedding_function=TestEmbeddingFunction("intfloat/multilingual-e5-large"))
except:collection = chroma_client.create_collection(name="my_collection", embedding_function=TestEmbeddingFunction("intfloat/multilingual-e5-large"), metadata={"hnsw:space": "cosine"})
collection.add(documents=["This is a document about apple","This is a document about oranges", "Something will happen tomorrow"
],ids=["id1", "id2", "id3"])
# 相似匹配
results = collection.query(query_texts=["This is a query document about oranges"],n_results=1)
print(results)效果如下:

值得一提的是,chromadb的 collections只能存储相同维度的向量,比如模型A embeddings 的向量维度是 x ,模型B embeddings 的向量维度是 y,如果存储到一个collections中会报错,因为不同维度数和向量维度的向量间是无法通过计算距离的方式评估相似性的。
所以修改向量模型后,可能因为前后解析的向量维度不同而无法直接向原 collections 中存储,需要考虑删除原 collections 重新创建,或者创建一个新的 collections。
原始数据的分片存储
现在我们已经了解了RAG的原始数据相似匹配过程,通过对原始数据的向量化后,再进行向量间的相似评估,最后匹配出与匹配文本最相似的内容。
但通常来说,用户的初始文本数据往往是大篇的文档,而原始数据需要尽可能是长度类似且连续完整的短句,这就涉及到一个切割初始文本数据为原始数据的过程。
一些常见的分割文档方式,都不适合用于RAG的原始数据分割,比如:
·以标点符号隔断:使用例如“。”,“?”等结束标点隔断语句,一方面要处理的情况可能比较多,文档未必按照标准的方式使用了标点,另一方面每个分片之间的长度无法控制,导致可能出现分片间长度差距过大的问题。
·以长度隔断:相比标准符号隔断效果更好,不过虽然这样分片间的长度差距可控,但很容易切断原有语句,导致某些分片意思不完整,或者毫无价值。
那么如何切割初始文档可以得到比较好的原始数据呢?
RAG 的分割常常采用块大小和块重叠的方式,这是一种和长度隔断类似的分割方式,在它的基础上一定程度上解决了文档原意被截断导致分片无价值的问题,而且重叠块的信息冗余有助于模型更好地理解文档内容。整体的分隔方式如下图。
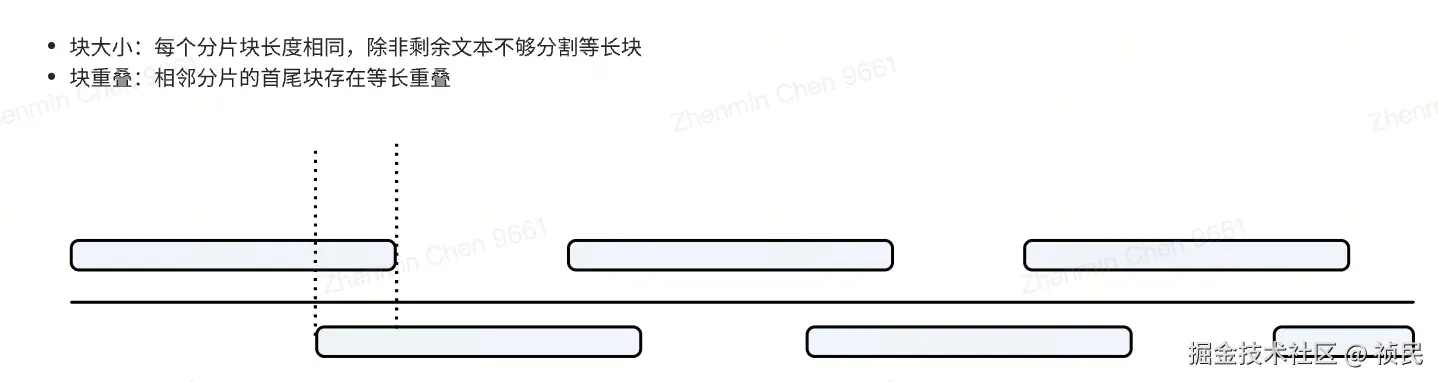
通过这种方式可以为单句补充更多的上下文信息,进而保证在非相邻单句之间结合使用的时候能理解大部分语义,具体块大小和块重叠的长度可以根据实际的业务场景定制。如果对文档质量比较自信,可以设置尽可能短的重叠块长度,反之设置越长。
def split_text_with_overlap(text, block_size, overlap_size):if block_size <
=
0
oroverlap_size <
0
oroverlap_size >= block_size:raise ValueError('Invalid blockSize or overlapSize')result = []start = 0while start + block_size <= len(text):result.append(text[start:start + block_size])start += block_size - overlap_sizeif start < len(text):result.append(text[start:])return result向量化与大模型的结合
下面把上面的片段逻辑封装成一个 server方便调用,
pip install flask
from typing import List
from flask import Flask, request, jsonify
from transformers import AutoTokenizer, AutoModel
from chromadb import Documents, EmbeddingFunction
from text_splitter import split_text_with_overlap
import chromadb
app = Flask(__name__)
class TestEmbeddingFunction(EmbeddingFunction):def __init__(self, model_name: str):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModel.from_pretrained(model_name)
def __call__(self, texts: Documents) -> List[List[float]]:inputs = self.tokenizer(texts, padding=True, truncation=True, return_tensors="pt")embeddings = self.model(**inputs).pooler_outputreturn embeddings.detach().numpy().tolist()chroma_client = chromadb.PersistentClient(path="./chroma_data")
# 存储向量化文本
@app.route('/store_text_embeddings', methods=['POST'])
def store_text_embeddings():text = request.json.get('text')block_size = int(request.json.get('block_size', 10))overlap_size = int(request.json.get('overlap_size', 5))collection_name = request.json.get('collection_name', 'default_collection')
if not text:return jsonify({"error": "No text provided"}), 400texts = split_text_with_overlap(text, block_size, overlap_size)
try:collection = chroma_client.get_collection(name=collection_name, embedding_function=TestEmbeddingFunction("intfloat/multilingual-e5-large"))except:collection = chroma_client.create_collection(name=collection_name, embedding_function=TestEmbeddingFunction("intfloat/multilingual-e5-large"), metadata={"hnsw:space": "cosine"})ids = [str(i) for i in range(len(texts))]collection.add(ids=ids,documents=texts,metadatas=[{"text": text} for text in texts] )return jsonify({"status": "success", "message": f"{len(texts)} texts stored successfully."})
# 查询相似文本
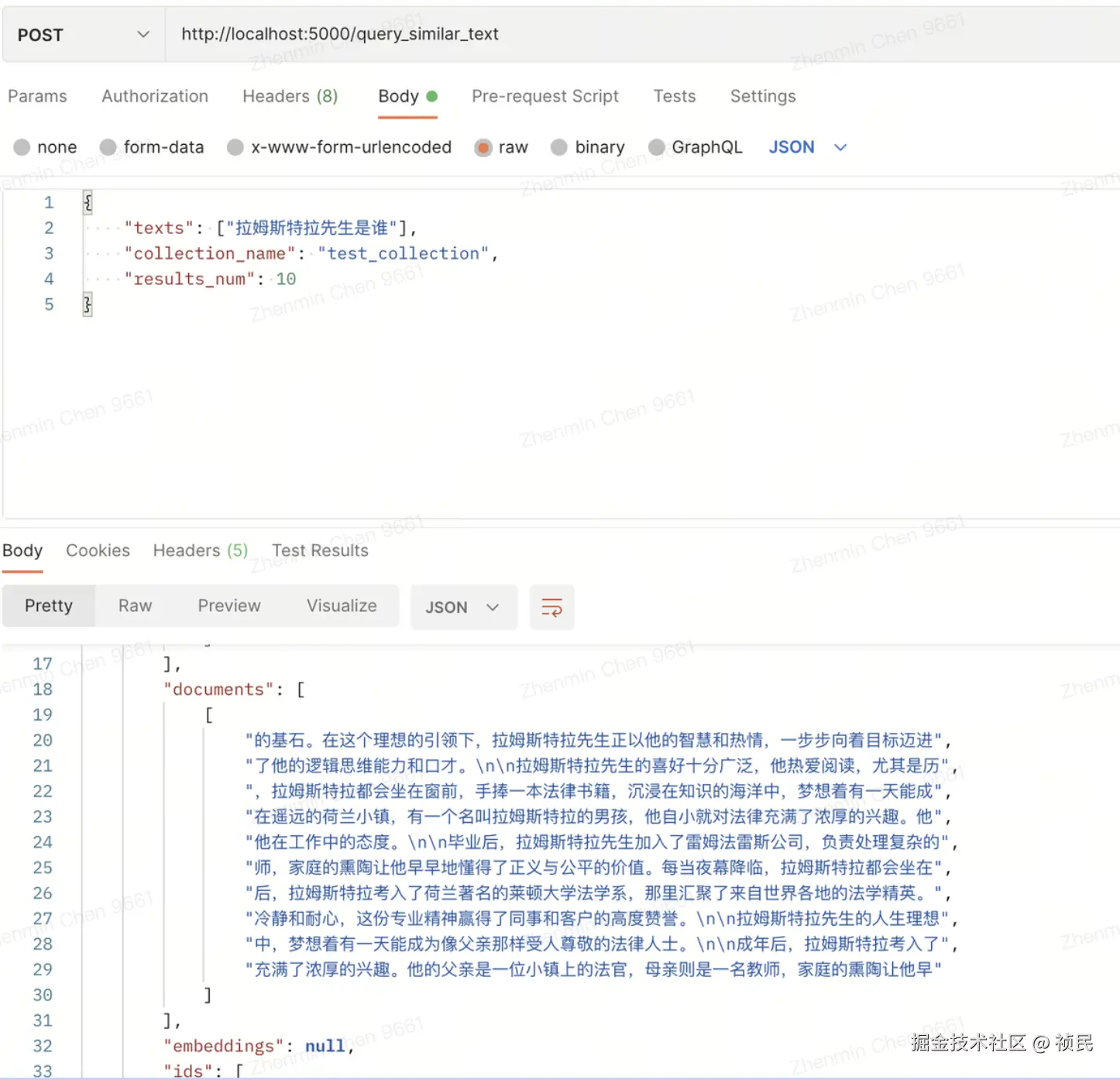
@app.route('/query_similar_text', methods=['POST'])
def query_similar_text():texts = request.json['texts']results_num = request.json.get('results_num', 1)collection_name = request.json.get('collection_name', 'default_collection')try:collection = chroma_client.get_collection(name=collection_name, embedding_function=TestEmbeddingFunction("intfloat/multilingual-e5-large"))except:return jsonify({"error": f"No collection named {collection_name}"}), 400 results = collection.query(query_texts=texts,n_results=results_num)return jsonify({"status": "success", "data": results})
if __name__ == '__main__':app.run()
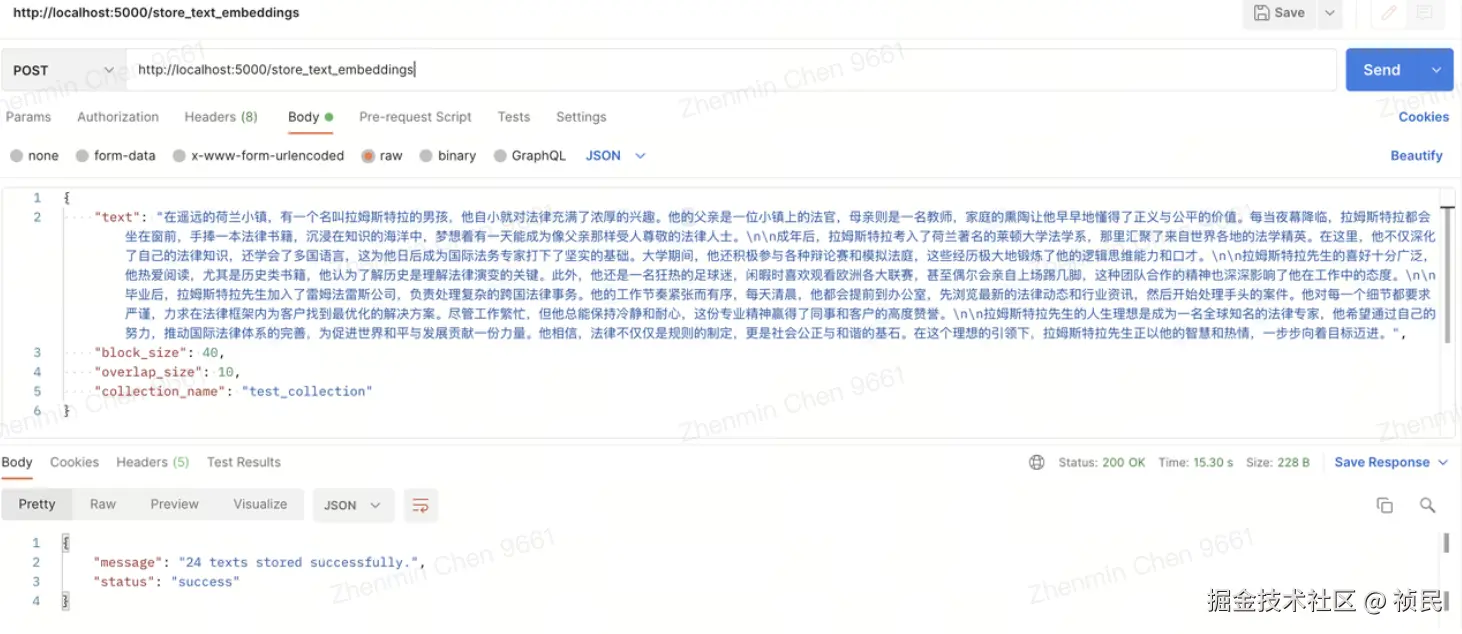
服务的效果如下:
为了能有更直观的交互体验,下面用 node 写一个简单的终端交互:
const axios = require('axios');
const readline = require('readline-sync');
const OpenAI = require('openai');
const openai = new OpenAI({apiKey: "sk-EZLRpBUv40D4P3xpCB11PjwwAXYjKRuS6ttMOER6L1nasKgx", baseURL: "https://api.chatanywhere.tech",
});
// 请求获取collections列表
async function getCollections() {try {const response = await axios.get('http://127.0.0.1:5000/get_collections');return response.data.collections;} catch (error) {console.error('Failed to fetch collections:', error.message);return [];}
}
// 显示collections列表并让用户选择
function chooseCollection(collections) {console.log('Available Collections:');collections.forEach((collection, index) => {console.log(`${index + 1}. ${collection}`);});// 添加一个选项,允许用户选择“无”const noChoiceOption = collections.length + 1;console.log(`${noChoiceOption}. No Collection (Proceed without selecting)`);const choice = readline.question('Choose a collection by entering its number or choose "No Collection": ');const selectedChoice = parseInt(choice, 10);if (isNaN(selectedChoice) || selectedChoice < 1 || selectedChoice > noChoiceOption) {console.error('Invalid choice. Please select a valid option.');process.exit(1);}if (selectedChoice === noChoiceOption) {return null; // 用户选择了“无”,返回null}return collections[selectedChoice - 1];
}
// 用户询问问题并发送请求
async function askQuestion(collectionName) {const question = readline.question('Enter your question (or type "q" to quit): ');if (question.toLowerCase() === 'q') {console.log('Exiting the program.');process.exit(0);}if (collectionName !== null) {try {const response = await axios.post('http://127.0.0.1:5000/query_similar_text', {texts: [question],collection_name: collectionName, results_num: 5});const similarText = response.data.data.documents[0].join(',');const completion = await openai.chat.completions.create({model: "gpt-3.5-turbo", messages: [{ role: "user", content: `这个问题有如下前置信息:${similarText}` }, {role: "user", content: question}]});console.log(`Response: ${JSON.stringify(completion.choices[0].message.content)}`);} catch (error) {console.error('Failed to query similar text:', error.message);}} else {const completion = await openai.chat.completions.create({model: "gpt-3.5-turbo", messages: [{role: "user", content: question}]});console.log(`Response: ${JSON.stringify(completion.choices[0].message.content)}`);}
}
(async () => {const collections = await getCollections();if (collections.length === 0) {console.error('No collections available.');process.exit(1);}let selectedCollection = chooseCollection(collections);if (selectedCollection === null) {console.log('No Collection Selected.');} else {console.log(`Selected Collection: ${selectedCollection}`);}console.log('Type "q" to quit.');// 主循环,用户可以一直提问while (true) {await askQuestion(selectedCollection);}
})();小结
本文介绍了检索增强生成技术 RAG 的背景和 MVP 实现,RAG 的关键在于能够针对指定的业务场景对原始数据进行有效高质量的向量化,在拿到原始数据的向量后,就可以通过余弦相似度等计算方式来计算向量间的距离并评估相似度。
检索出多个与问题相似的分片后,就可以提供给大模型作为上下文信息的补充,使得模型能够对信息隔离的领域做出更有效答复。
值得一提的是,原始数据的向量化本质是对它的多维特征打标的过程,不同的模型特征标识的标准和维度都可能是不同的,所以在一些特定场景应用其他方向的 embeddings 模型效果不一定很好。
作者:祯民
链接:https://juejin.cn/post/7464756728685936694
本文摘自《生成式AI应用开发:基于OpenAI API实现》,获出版社和作者授权发布。
生成式AI应用开发:基于OpenAI API实现——jd![]() https://item.jd.com/14398865.html
https://item.jd.com/14398865.html