Free Draft Model!Lookahead Decoding加速大语言模型解码新路径
Free Draft Model!Lookahead Decoding加速大语言模型解码新路径
大语言模型(LLMs)在当今AI领域大放异彩,但其自回归解码方式锁死了生成效率。本文将为你解读一种全新的解码算法——Lookahead Decoding,它无需Draft Model就能实现投机采样,加速LLM解码,在多项任务中实现显著提速,为大语言模型的应用带来新突破,快来一探究竟!
论文标题
Break the Sequential Dependency of LLM Inference Using LOOKAHEAD DECODING
来源
arXiv:2402.02057v1 [cs.LG] + http://arxiv.org/abs/2402.02057
博客
https://lmsys.org/blog/2023-11-21-lookahead-decoding/
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
在人工智能蓬勃发展的当下,大语言模型(LLMs)凭借其强大的语言理解和生成能力,逐渐成为推动自然语言处理领域进步的核心力量。如今,LLMs被广泛应用于搜索、聊天机器人、代码生成等众多场景 ,这使得低延迟生成高质量文本成为关键需求。然而,当前LLMs普遍采用的自回归解码方式却存在效率瓶颈。一方面,自回归解码每次只能生成一个token,就像逐字书写文章,整体生成时间与解码步骤数紧密相关,生成较长文本时耗时久。另一方面,这种解码方式对现代加速器(如GPU)的并行处理能力利用不足,就好比驾驶一辆高性能跑车却始终低速行驶,造成资源浪费。为了满足应用场景对低延迟的迫切需求,提升自回归解码效率成为该领域亟待攻克的核心难题。
研究问题
-
自回归解码每次仅生成一个令牌(token),整体生成时间与解码步骤数成正比,效率较低。
-
每个解码步骤对现代加速器(如GPU)的并行处理能力利用不足。
-
现有加速方法(如投机解码)常依赖难以获取且缺乏通用性的draft model,限制了投机解码的应用。
主要贡献
1. 设计新算法:提出Lookahead Decoding算法,这是一种无损、并行的解码算法,无需任何辅助模型就能加速LLM推理。
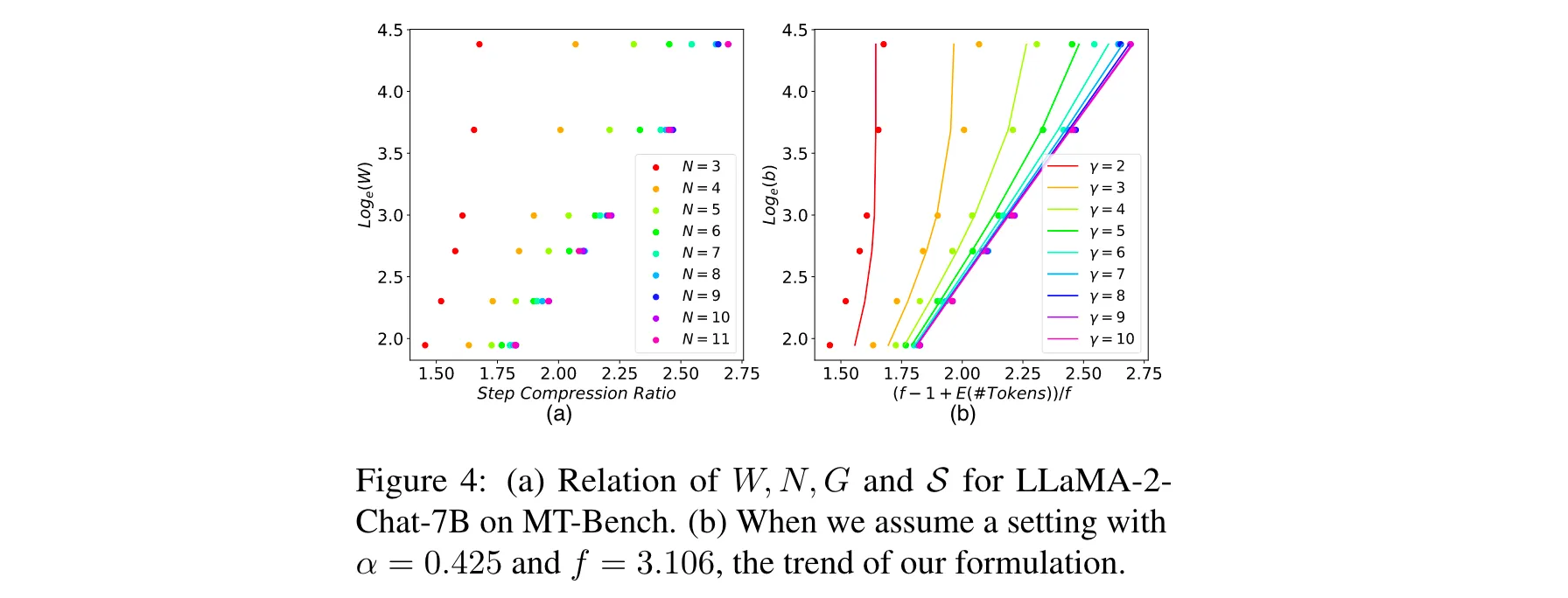
2. 揭示缩放规律:发现该算法能根据每步的log(FLOPs)线性减少解码步骤,在解码步骤数和每步FLOPs之间实现权衡,具有良好的扩展性。
3. 适配高效注意力机制:该算法能受益于最新的内存高效注意力机制(如FlashAttention),且易于在多个GPU上并行化,通过开发分布式CUDA实现提升性能。
4. 多场景验证有效性:在不同设置下对Lookahead Decoding进行评估,证明其在多种数据集和任务上均能有效加速解码过程。
方法论精要
Lookahead Decoding是一种创新的并行解码算法,旨在加速大语言模型(LLMs)的推理过程。它基于对自回归解码的深入理解,通过独特的设计和参数配置,有效提升了解码效率。详细解码过程可参考blog。
1. 核心算法设计:Lookahead Decoding基于雅可比解码(Jacobi decoding)进行改进。雅可比解码可将自回归解码转化为求解非线性系统的过程,但它存在生成令牌位置不准确的问题。Lookahead Decoding则利用雅可比解码一次生成多个令牌的能力,通过维护一个固定大小的2D窗口,在序列和时间两个维度上操作,从雅可比迭代轨迹中并行生成多个不相交的n-gram,这一过程称为前瞻分支(lookahead branch)。同时,引入n-gram pool来缓存生成的n-gram,后续通过验证分支(verification branch)对有前景的n - gram候选进行验证,确保符合LLM的输出分布,若验证通过,则将这些n - gram整合到生成序列中。
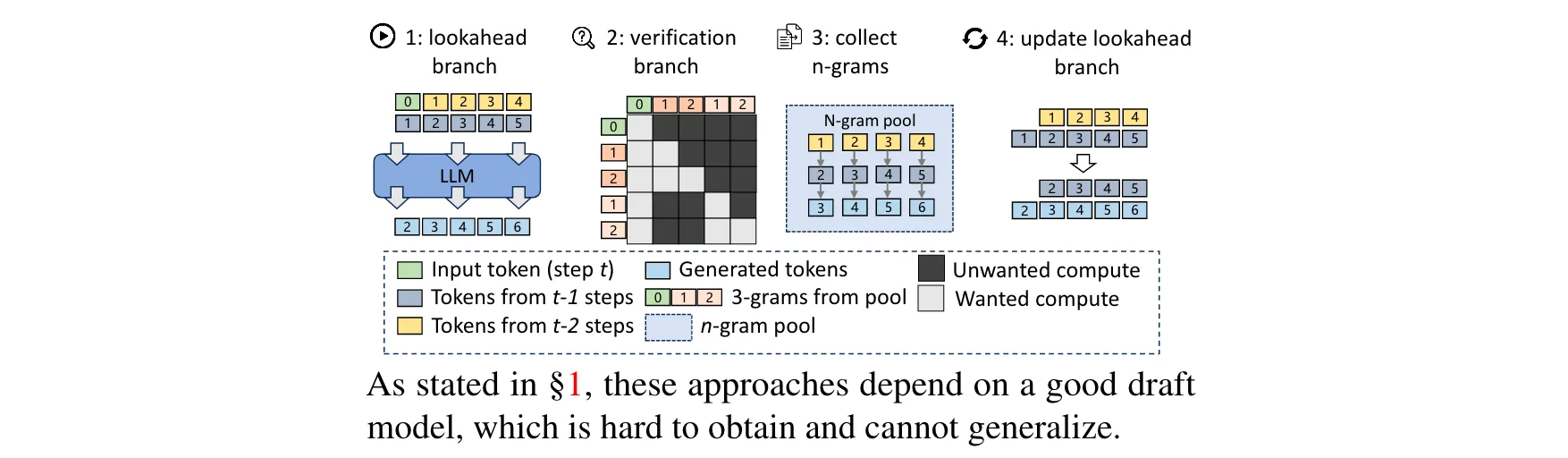
2. 关键参数设计
窗口大小W:决定并行解码时向前看的令牌位置数量,即每次在不同位置并行生成新令牌的数量。较大的W值可以增加并行度,但也可能引入更多无效计算,需要根据模型和任务进行调整。
回溯步数N:定义从过去雅可比轨迹中检索n-gram的回溯步数。N越大,模型能利用的历史信息越丰富,但计算复杂度也会相应增加。
最大候选数G:限制验证分支中并行运行的有前景候选数量,用于控制验证成本。通常设置G = W,以平衡生成和验证的资源消耗 。
3. 创新性技术组合
并行生成与验证:将并行生成n-gram和验证n - gram的过程相结合。在生成阶段,通过2D窗口利用过去n - 1步的历史令牌生成多个n-gram;验证阶段,从n-gram pool中查找以当前序列最后一个令牌开头的n-gram,并利用LLM进行并行验证。
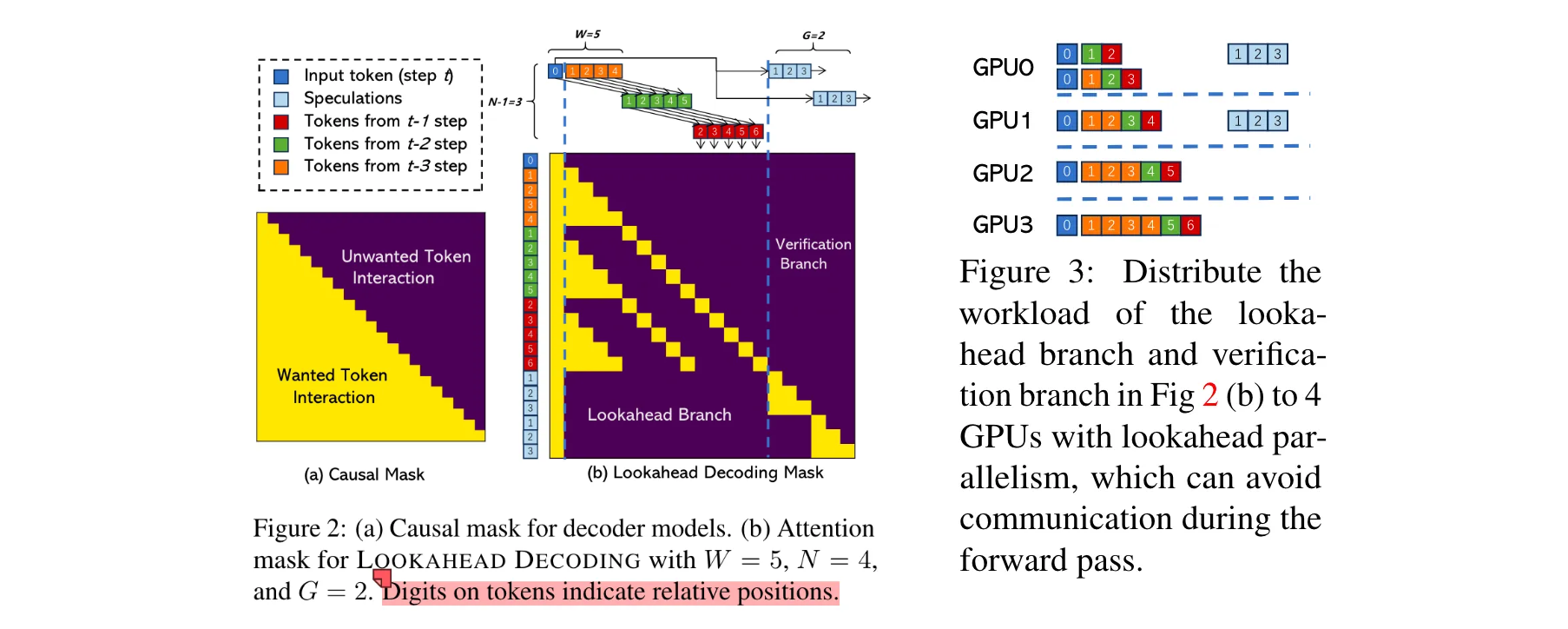
与FlashAttention集成:FlashAttention可加速LLMs的训练和推理,但它强制使用因果掩码,不适合Lookahead Decoding的注意力模式。为此,论文将Lookahead Decoding的注意力模式硬编码到FlashAttention中,实现了两者的有效结合,相比基于原生PyTorch的简单实现,能带来约20%的端到端加速。
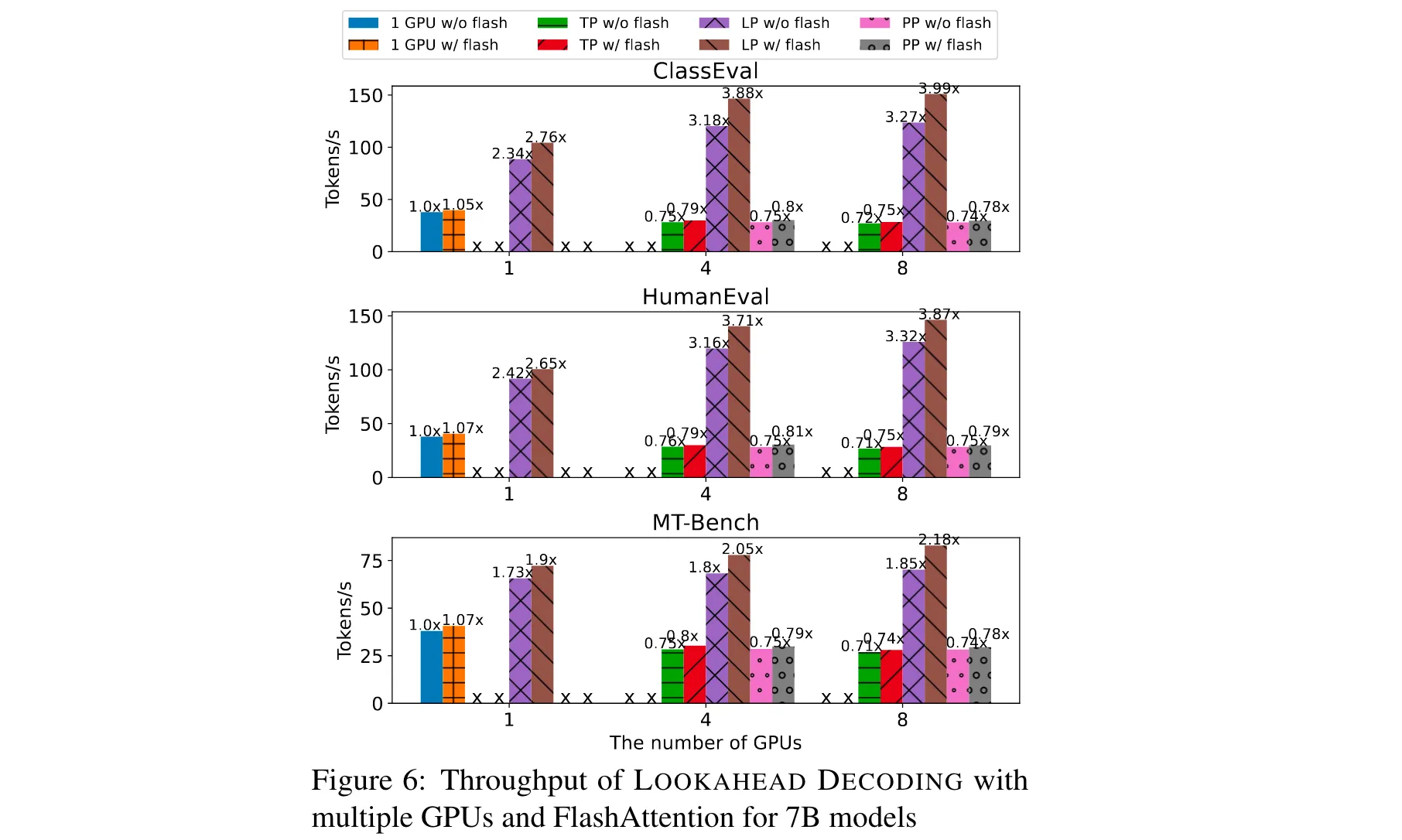
Lookahead并行性(Lookahead Parallelism):该算法易于在多个GPU上并行化,对于前瞻分支,由于其计算由多个不相交分支组成,可将这些分支分配到不同GPU上,避免推理计算中的通信开销;对于验证分支,将多个n - gram候选分配到不同设备进行独立验证。这种并行方式(LP)与传统的模型并行方法不同,它为每个GPU维护完整的模型副本,虽然需要更多内存,但能在每个解码步骤中实现近乎零通信,更适合推理任务。
4. 实验验证方式:为验证Lookahead Decoding的有效性,论文使用了多种版本的LLaMA - 2和CodeLlama模型,在不同GPU设置下进行实验。数据集涵盖了MT - Bench、GSM8K、HumanEval、MBPP、ClassEval等多种类型,用于测试不同任务下的性能。基线设置包括HuggingFace的贪心搜索实现,以及引入FlashAttention作为更强的基线。在分布式设置中,将Lookahead Parallelism(LP)与张量并行(TP)和流水线并行(PP)进行对比,通过测量单批次推理的吞吐量评估性能。
实验洞察
论文通过一系列实验对Lookahead Decoding算法进行了全面评估,涵盖了不同模型、数据集和任务,以探究其性能优势、效率突破以及核心模块的有效性。
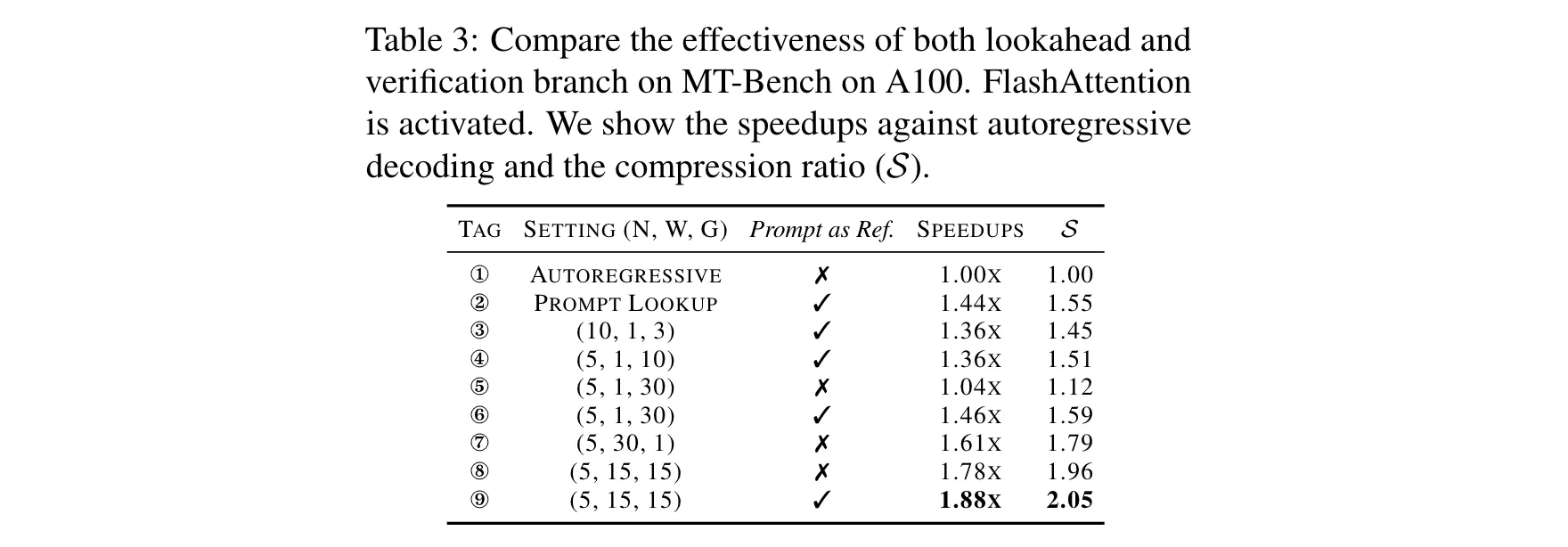
1. 性能优势:在多项实验中,Lookahead Decoding展现出显著的性能提升。在MT - Bench数据集上,相较于HuggingFace的贪心搜索实现,它实现了1.5x - 2.3x的加速 。在代码完成任务中,该算法表现更为出色,加速比可达2.3x。这得益于代码完成任务中重复令牌出现频率较高,使得模型预测相对容易,Lookahead Decoding能更好地发挥其优势。同时,研究发现较小的模型在使用该算法时加速比更高。这是因为Lookahead Decoding通过每步的FLOPs与解码步骤压缩比进行权衡,较大模型由于本身所需FLOPs较多,在相同GPU设置下更容易达到GPU的FLOPs上限,从而压缩解码步骤的能力相对较弱。
2. 效率突破:通过 Lookahead Decoding 算法,能够利用计算资源减少解码步骤,实现推理速度的优化。例如,在多个 GPU 上进行并行计算时,可进一步降低推理延迟。同时,与 FlashAttention 集成后,相比基于原生 PyTorch 的简单实现,能带来约 20% 的端到端加速。

3. 消融研究:研究发现,平衡的前瞻分支和验证分支设置(如 ( W = 15 , N = 5 , G = 15 ) (W = 15, N = 5, G = 15) (W=15,N=5,G=15)能获得较好的加速效果。仅使用最小前瞻分支( W = 1 W = 1 W=1 )时,即使调整 N 和 G 设置,在 MT - Bench 上的加速效果仍不如平衡分支设置。此外,使用提示(prompt)作为参考可以进一步提升 Lookahead Decoding 的性能,已经集成入代码实现中。