爬虫学习笔记(五)---数据解析之re
数据提取
前面的爬虫笔记学习的都是如何爬取整个页面的内容,服务器渲染中,数据是直接放在源代码html里面的,大多数情况下整个页面的内容真正需要的只是一小部分,那把这一小部分提取出来的过程就叫做数据提取
数据解析方式
re解析(运行速度最快)
RE:regular expression正则表达式,写一段话对字符串进行匹配的语法规则
因为爬取到的页面本质上就是一个超长的字符串,所以正则表达式很适合用于爬取字符串的数据提取
元字符
| 元字符 | 含义(下面都是匹配一个字符串) |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意空白字符(空格、换行、回车) |
| \d | 匹配数字 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串开始 |
| $ | 匹配字符串结尾 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a|b | 匹配字符a或字符b |
| () | 匹配括号内的表达式,也表示一个组 |
| [. . .] | 匹配字符组中的字符 |
| [^. . .] | 匹配除了字符组中字符的所有字符 |
量词
| 量词 | 含义 |
| * | 重复0次或更多次 |
| "+" | 重复1次或更多次 |
| ? | 重复0次或1次 |
| {n} | 重复1次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
贪婪匹配和惰性匹配
| .* | 贪婪匹配(尽可能多次) |
| .*? | 惰性匹配(爬虫使用最多,尽可能少的匹配,回溯) |
python中的re模块
代码练习:
import re
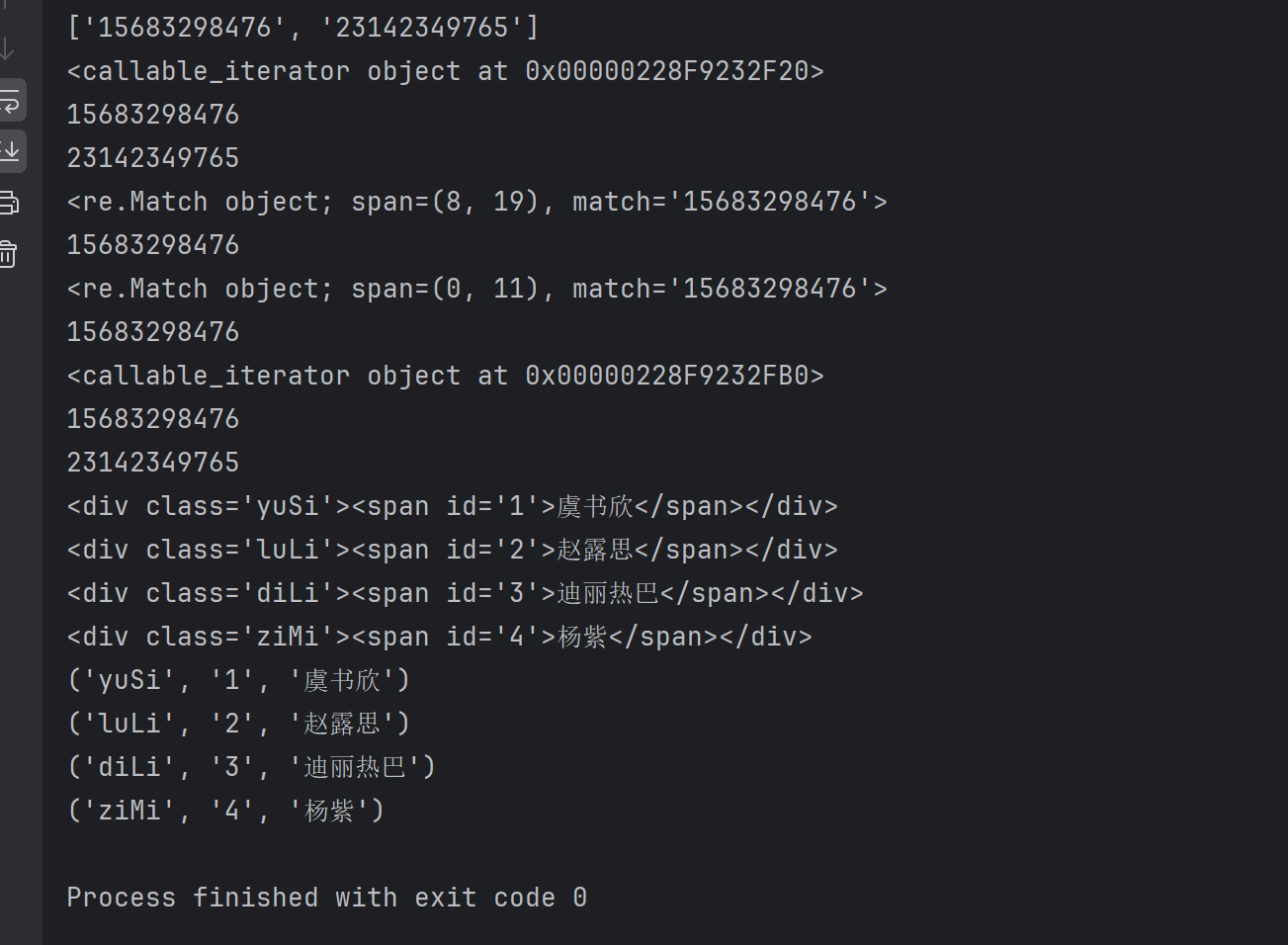
#1-findall匹配所有符合正则的内容
lst = re.findall(r"\d+","我的电话号码是:15683298476,你的电话号码是:23142349765")#r(正则)声明字符串为原始字符串
print(lst)
#2-finditer:返回的是迭代器,迭代器的效率比列表高
it = re.finditer(r"\d+","我的电话号码是:15683298476,你的电话号码是:23142349765")#r声明字符串为原始字符串
print(it)#返回的是迭代器,从迭代器中拿到内容需要遍历迭代器,拿里面内容要用方法.group()
for i in it:print(i.group())
#3-search返回的是match对象,想拿数据同样需要.group()
s = re.search(r"\d+","我的电话号码是:15683298476,你的电话号码是:23142349765")
print(s)
print(s.group())#但是只返回第一个,因为search就是全文检索,只要找到一个就返回
#4-match只能从头开始匹配
m = re.match(r"\d+","15683298476(必须开头就是数字,否则就报错),你的电话号码是:23142349765")
print(m)
print(m.group())
#预加载正则表达式(复杂的正则表达式需要反复的调用,就提前定义变量预编译一个正则表达式)
obj = re.compile(r"\d+")
o = obj.finditer("我的电话号码是15683298476,你的是23142349765")
print(o)
for it in o:print(it.group())
#例子
s1 = """
<div class='yuSi'><span id='1'>虞书欣</span></div>
<div class='luLi'><span id='2'>赵露思</span></div>
<div class='diLi'><span id='3'>迪丽热巴</span></div>
<div class='ziMi'><span id='4'>杨紫</span></div>
"""
obj2 = re.compile(r"<div class='.*?'><span id='\d+'>.*?</span></div>",re.S)#re.S使得.能够匹配换行符
result = obj2.finditer(s1)
for it in result:print(it.group())
#但是实际上想要的内容比现在打印的少,不想要html格式内容,方法:将.*?用()框起来,并用?P<名字>命名
obj3 = re.compile(r"<div class='(?P<class>.*?)'><span id='(?P<id>\d+)'>(?P<name>.*?)</span></div>",re.S)#re.S使得.能够匹配换行符
result = obj3.finditer(s1)
for it in result:print(it.group("class", "id", "name"))结果打印: