亮数据:AI时代的数据采集革命者——从试用体验到实战应用全解析

🎼个人主页:【Y小夜】
😎作者简介:一位双非学校的大三学生,编程爱好者,
专注于基础和实战分享,欢迎私信咨询!
🎆入门专栏:🎇【MySQL,Javaweb,Rust,python】
🎈热门专栏:🎊【Springboot,Redis,Springsecurity,Docker,AI】
感谢您的点赞、关注、评论、收藏、是对我最大的认可和支持!❤️

目录
一、为什么选择亮数据?——试用体验与核心优势
试用体验亮点
二、实战测试
测试1
测试场景
平台注册
查看用户名和密码
爬虫代码
测试2:
测试场景
测试操作
三、技术优势与行业应用
四、总结
一、为什么选择亮数据?——试用体验与核心优势
在AI与大数据驱动的时代,获取高质量、结构化且实时的数据是模型训练与业务决策的基础。然而,传统爬虫工具面临IP封禁、动态渲染、反爬机制等技术瓶颈,而亮数据(Bright Data)通过其全栈式数据采集解决方案,完美解决了这些问题。
试用体验亮点
经过我一天的使用,现总结出三点分享分享给大家:
第一点:它具有零代码抓取与智能工具集成: 亮数据的Web Scraper IDE和浏览器插件无需编程基础,通过可视化界面即可配置目标网站的数据抓取规则。例如,在抓取电商价格时,只需点击页面元素并定义字段,系统自动生成结构化数据
第二点:他可以动态住宅代理网络: 覆盖全球195个国家/地区的7200万住宅IP,支持自动轮换和地理定位。在测试中,使用亮数据代理访问亚马逊美国站,成功绕过地域限制,抓取效率提升300%,IP封禁率降至0%
第三代:它拥有合规性与安全性: 通过KYC实名认证和加密传输,确保数据采集符合GDPR、CCPA等法规。与VirusTotal、Avast等安全巨头合作,实时监控300亿域名,屏蔽非法内容
二、实战测试
废话不多说,说的再好听大家心中还是有顾虑,那么我现在就把我测试的全过程展现给大家:
测试1
测试场景
为自然语言处理(NLP)模型训练收集最新学术论文数据,来源为arXiv计算机科学板块。
平台注册
亮数据-官网地址
点击免费使用后,试用后,可获得三天免费体验哟
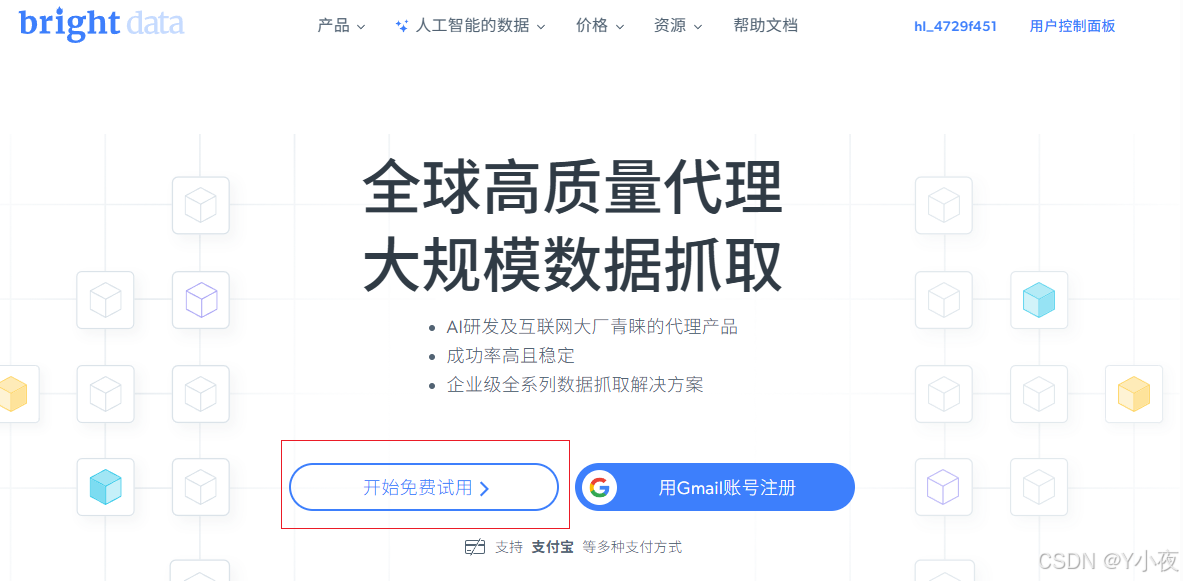
在注册时,一定要注意:符合要求,不然注册可能会出问题

然后点击:Proxies & Scraping
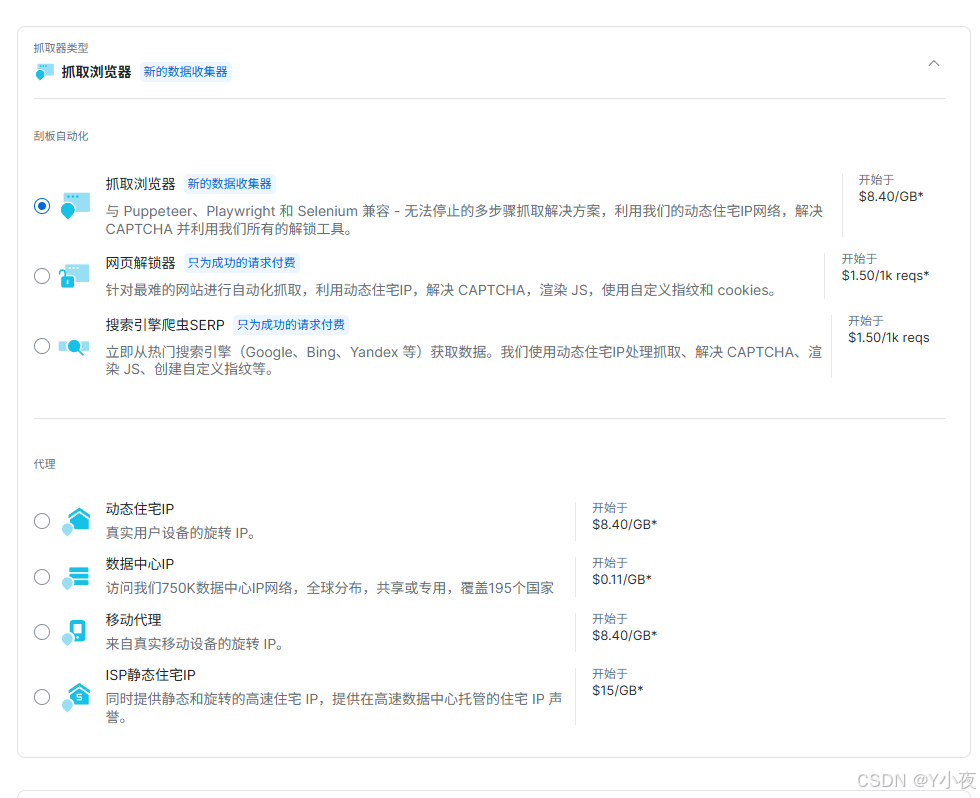
接下来我们选择,选择抓取浏览器(这里你按照自己的需求去选),然后点击去使用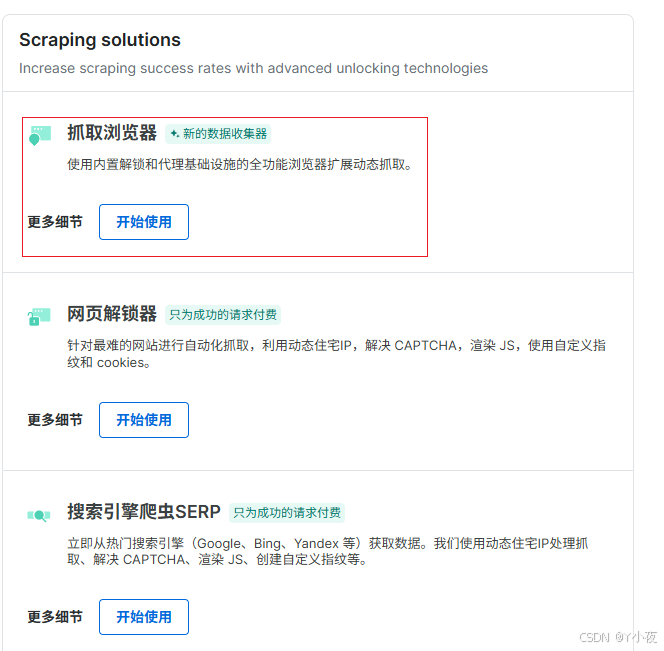
接下来点击抓取数据,按自己的需求进行配置即可
最后点击添加:
如果你对爬虫代码不太熟的话,操作平台也提供的示例代码:
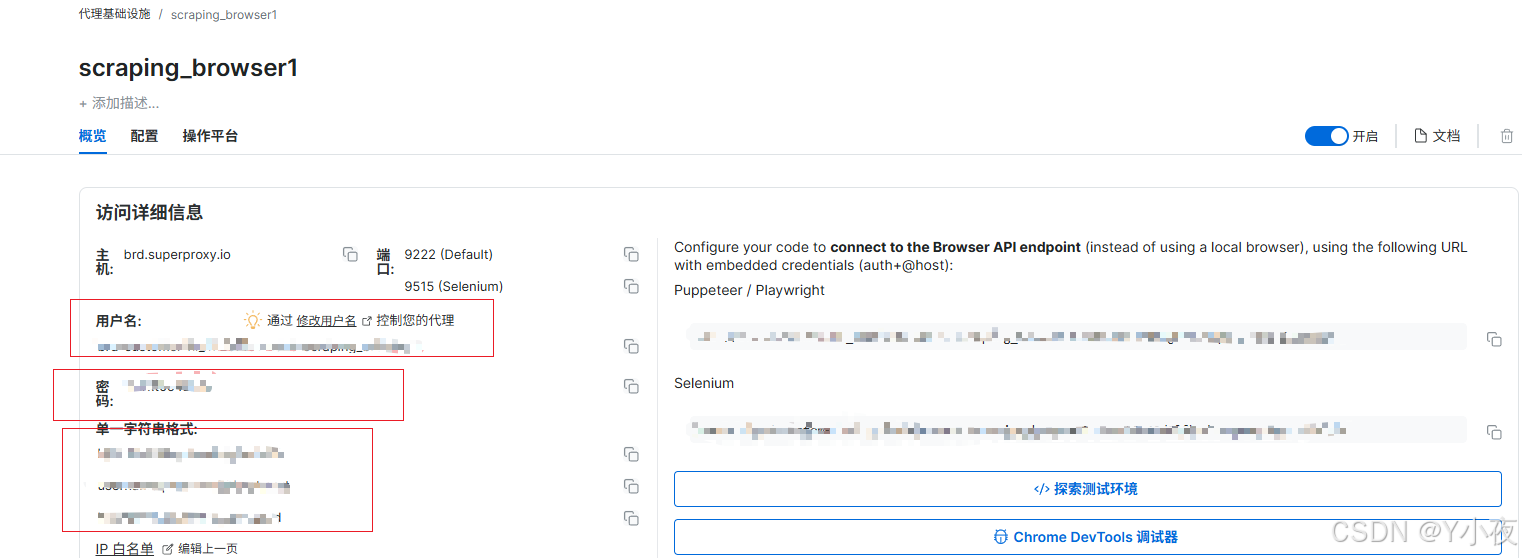
查看用户名和密码
在概览里面可以查看到自己的用户名和密码等信息(这里如果自己编写爬虫代码的话,建议赋值单一字符串格式的三种之一,比较方便操作)
爬虫代码
这里我们对:https://arxiv.org/list/cs/new这个网站进行爬取:
import requests
from bs4 import BeautifulSoup
import pandas as pdproxy = {'http': '刚刚你复制的单一格式的信息'
}def fetch_arxiv_papers():url = 'https://arxiv.org/list/cs/new'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36','Accept-Language': 'en-US,en;q=0.9'}try:response = requests.get(url, headers=headers, proxies=proxy, timeout=20)response.raise_for_status()print("状态码:", response.status_code)soup = BeautifulSoup(response.text, 'html.parser')papers = []entries = soup.find_all('div', class_='meta')print("找到论文条目数:", len(entries))for entry in entries:# 标题处理title_div = entry.find('div', class_='list-title')title = title_div.text.replace('Title:', '').strip() if title_div else "无标题"# 作者处理(关键修改部分)author_div = entry.find('div', class_='list-authors') # 新增定位层authors = [a.text.strip() for a in author_div.find_all('a')] if author_div else []# 摘要处理abstract_p = entry.find('p', class_='mathjax')abstract = abstract_p.text.strip() if abstract_p else "无摘要"papers.append({'title': title, 'authors': ', '.join(authors), 'abstract': abstract})return pd.DataFrame(papers)except Exception as e:print(f"错误发生: {str(e)}")return pd.DataFrame()# 执行保存
df = fetch_arxiv_papers()
if not df.empty:df.to_json('arxiv_papers.json', orient='records', indent=2)print("文件保存成功!")
else:print("未抓取到数据")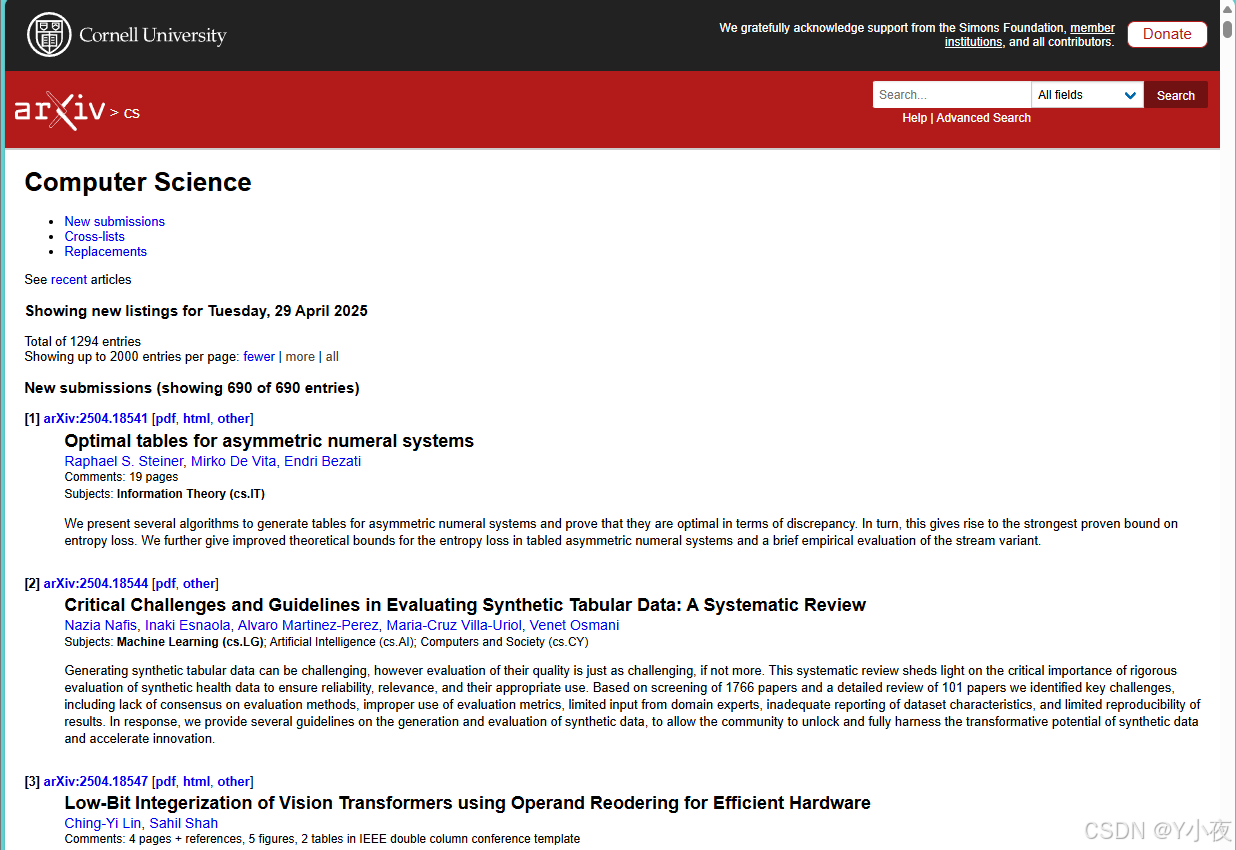
运行代码,爬取出来的json数据为:
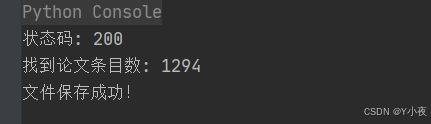
发现爬取成功!!!
测试2:
测试场景
还在为代码bug发愁?快来试一试亮数据提供的网络爬虫市场!
测试操作
选择一个例子进行测试
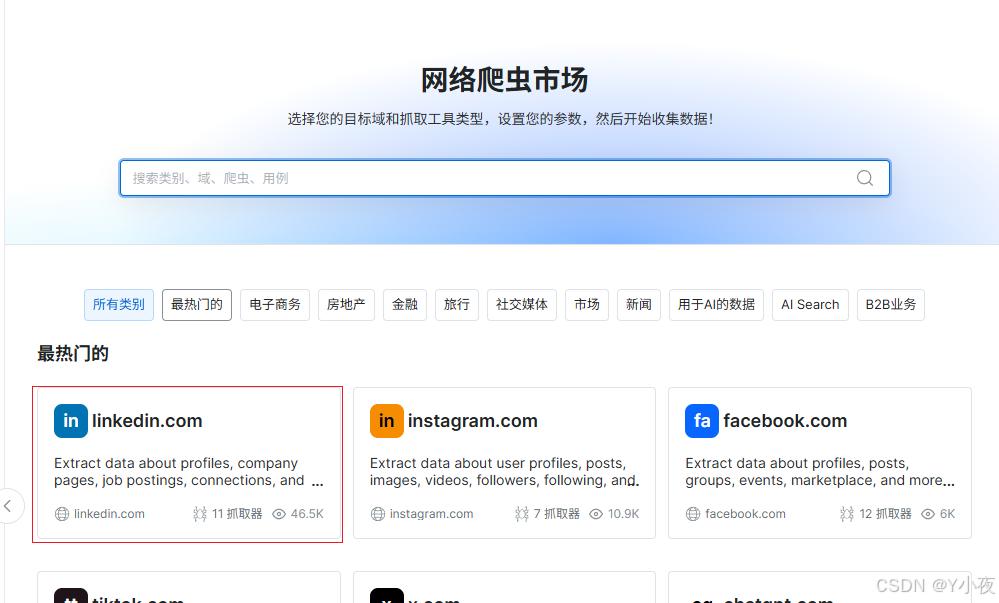
选择通过URL爬取数据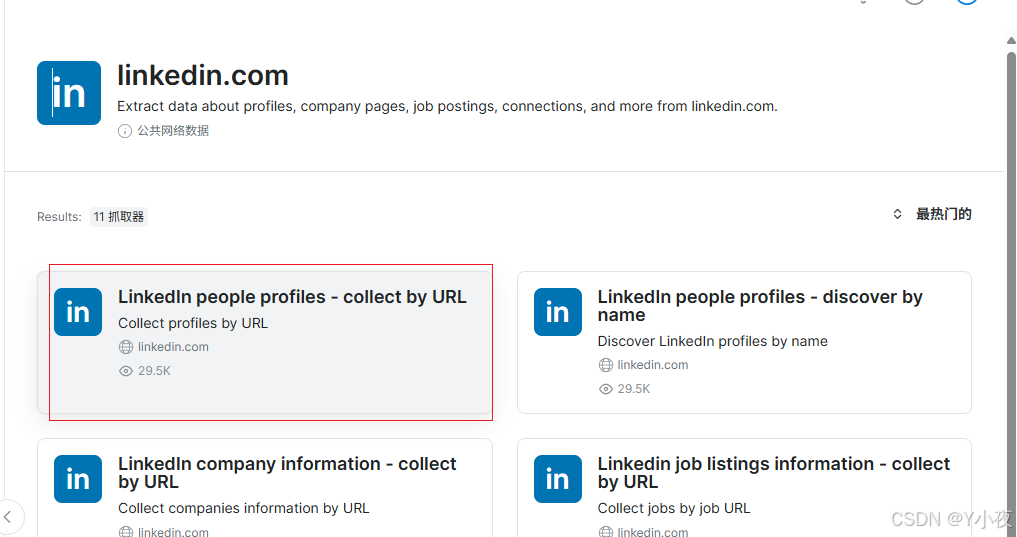
这里我们选择无代码抓取器,可以实现在控制面板上进行所有操作:
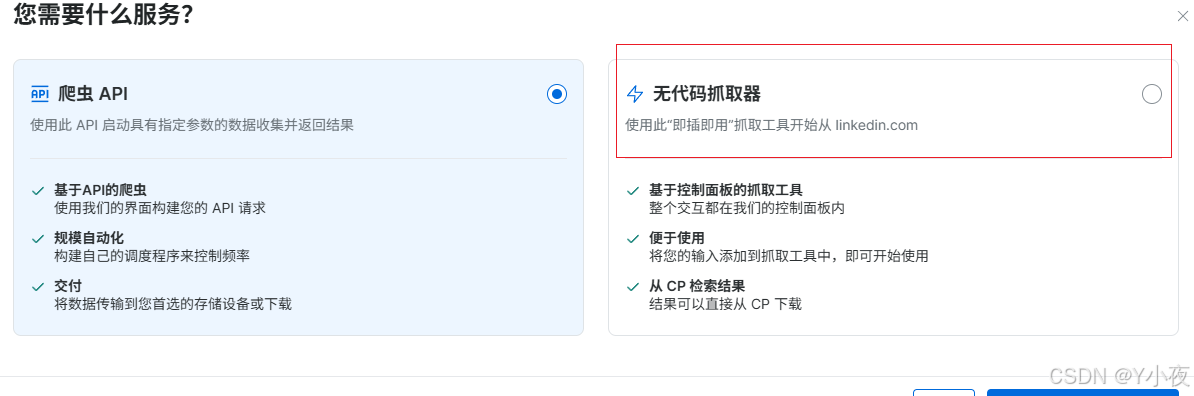
然后点击start collection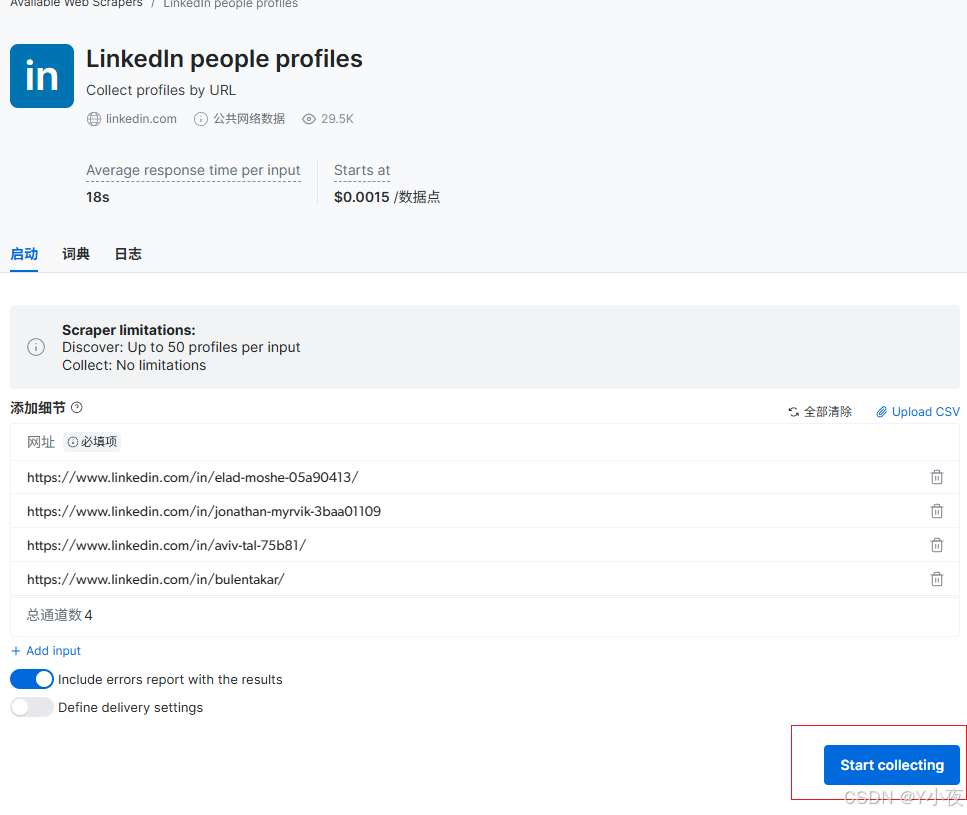
现在显示Ready,说明已经爬取完成。
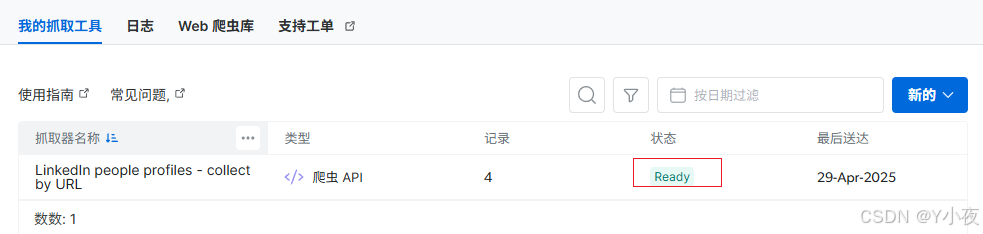
然后点击日志,点击下载,下载为json
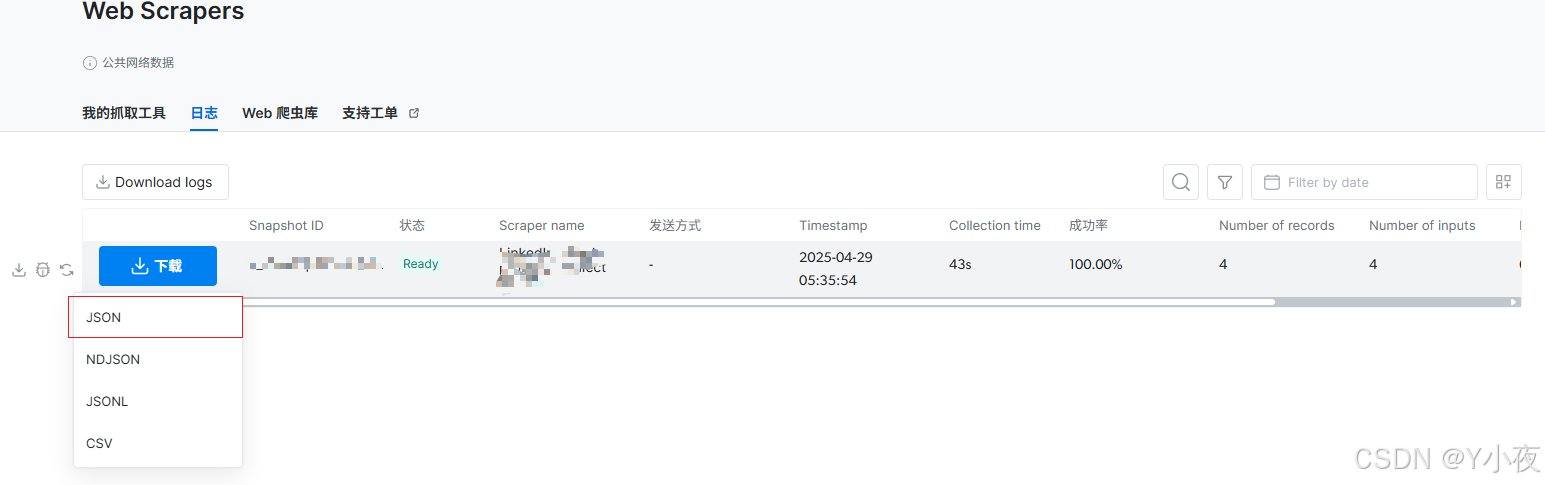
我们查看这个json文件
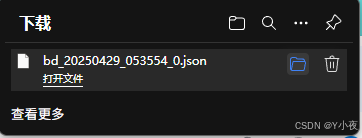
发现我们也爬取出来了

三、技术优势与行业应用
反反爬能力:
CAPTCHA自动破解:集成机器学习模型识别验证码,成功率达98%
浏览器指纹模拟:动态调整User-Agent、Canvas指纹等,规避网站风控
高并发与低延迟: 支持每秒数千次请求,平均响应时间<2秒,适合实时数据管道。例如,某金融公司使用亮数据抓取全球股票行情,延迟低于1.5秒
行业应用案例:
电商竞争分析:某头部平台通过亮数据监控竞品价格波动,日均抓取100万SKU,成本降低60%
AI训练数据:DeepMind使用亮数据抓取公开论文和专利数据,加速Gemma模型研发
智慧城市:结合物联网传感器数据,亮数据代理支持实时交通流量抓取,优化城市路网规划 。
四、总结
亮数据不仅是爬虫工具,更是AI时代的数据基础设施。无论是训练大语言模型、构建实时推荐系统,还是监控市场动态,其解决方案均能显著提升数据获取效率与质量。正如海外开发者Avi Chawla所言:“亮数据的SERP API让我们的大规模AI写书项目从构想变为现实。”
网页抓取工具 - 网页爬虫工具 - 免费试用![]() https://www.bright.cn/products/web-scraper
https://www.bright.cn/products/web-scraper