transform-实现Encoder 编码器模块
Encoder
-
论文地址
https://arxiv.org/pdf/1706.03762
Encoder结构介绍
-
Transformer Encoder是Transformer模型的核心组件,负责对输入序列进行特征提取和语义编码。通过堆叠多层结构相同的编码层(Encoder Layer),每层包含自注意力机制和前馈神经网络,实现对输入信息的逐层抽象。
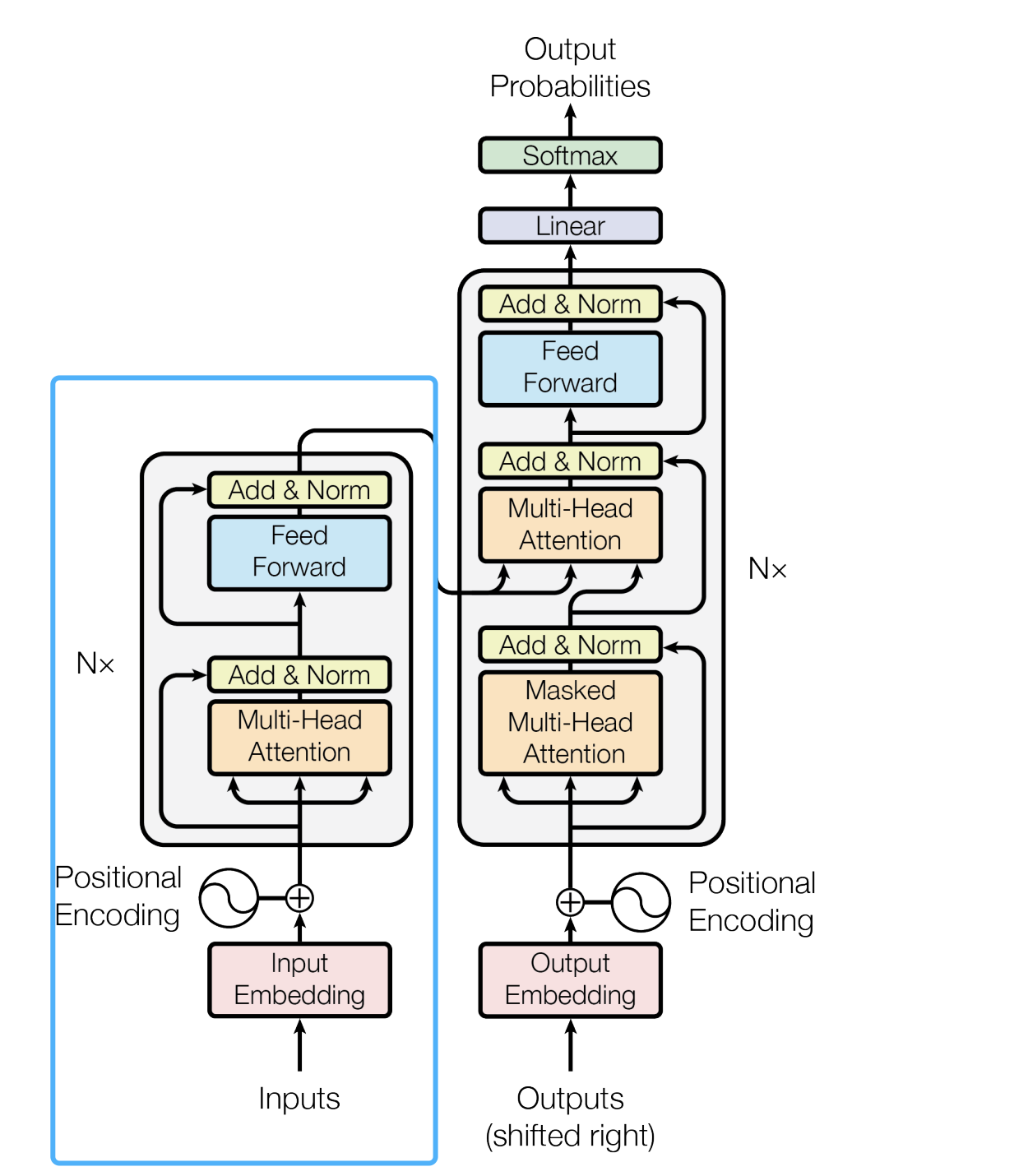
这里实现上图蓝色框中的整个Encoder结构
主要组件包含:
- 词嵌入层:将离散的token索引映射为连续向量
- 位置编码:注入序列的位置信息
- 多层编码层:通过多头注意力和前馈网络进行特征变换
数学流程
-
编码器的计算过程可形式化为:
Embedding : X e m b e d = Embedding ( X i n p u t ) PositionEncode : X p o s = X e m b e d + PositionEncoding ( s e q _ l e n ) EncoderLayers : H o u t = LayerNorm ( FFN ( MHA ( X p o s ) + X p o s ) \begin{aligned} \text{Embedding} &: X_{embed} = \text{Embedding}(X_{input}) \\ \text{PositionEncode} &: X_{pos} = X_{embed} + \text{PositionEncoding}(seq\_len) \\ \text{EncoderLayers} &: H_{out} = \text{LayerNorm}( \text{FFN}( \text{MHA}(X_{pos}) + X_{pos} ) \end{aligned} EmbeddingPositionEncodeEncoderLayers:Xembed=Embedding(Xinput):Xpos=Xembed+PositionEncoding(seq_len):Hout=LayerNorm(FFN(MHA(Xpos)+Xpos)
其中每个编码层包含:- 多头自注意力(Multi-Head Self-Attention)
- 残差连接 + 层归一化
- 前馈神经网络(Feed-Forward Network)
- 二次残差连接 + 层归一化
代码实现
-
其他层的实现
层名 链接 PositionEncoding https://blog.csdn.net/hbkybkzw/article/details/147431820 calculate_attention https://blog.csdn.net/hbkybkzw/article/details/147462845 MultiHeadAttention https://blog.csdn.net/hbkybkzw/article/details/147490387 FeedForward https://blog.csdn.net/hbkybkzw/article/details/147515883 LayerNorm https://blog.csdn.net/hbkybkzw/article/details/147516529 EncoderLayer https://blog.csdn.net/hbkybkzw/article/details/147591824 下面统一在before.py中导入
-
实现 transformer 编码器 Encoder
import torch from torch import nnfrom before import PositionEncoding,calculate_attention,MultiHeadAttention,FeedForward,LayerNorm,EncoderLayerclass Encoder(nn.Module):def __init__(self, vocab_size, padding_idx, d_model, n_heads, ffn_hidden, dropout_prob=0.1, num_layers=6, max_seq_len=512):super(Encoder, self).__init__()# 词嵌入层(含padding掩码)self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=d_model, padding_idx=padding_idx)# 位置编码器self.position_encode = PositionEncoding(d_model=d_model, max_seq_len=max_seq_len)# 编码层堆叠self.encode_layers = nn.ModuleList([EncoderLayer(n_heads=n_heads, d_model=d_model, ffn_hidden=ffn_hidden, dropout_prob=dropout_prob) for _ in range(num_layers)])def forward(self, x, src_mask=None):# 输入形状: [batch_size, seq_len]embed_x = self.embedding(x) # 词向量映射pos_encode_x = self.position_encode(embed_x) # 位置编码# 逐层处理for layer in self.encode_layers:pos_encode_x = layer(pos_encode_x, mask=src_mask)return pos_encode_x # 输出形状: [batch_size, seq_len, d_model]关键组件说明
- 词嵌入层(Embedding):将离散的token索引转换为d_model维连续向量,自动处理padding位置的零值屏蔽
- 位置编码(PositionEncoding):使用正弦/余弦函数生成位置特征,与词向量相加实现位置信息注入
- 编码层堆叠(encode_layers):每个编码层包含:多头自注意力机制;前馈神经网络;残差连接;层归一化
-
维度变化
处理阶段 张量形状变化示例 原始输入 [batch_size, seq_len] 词嵌入层输出 [batch_size, seq_len, d_model] 位置编码后 [batch_size, seq_len, d_model] 每个编码层输出 [batch_size, seq_len, d_model]
使用示例
-
测试用例
if __name__ == "__main__":# 模拟输入:batch_size=4, 序列长度64x = torch.randint(0, 100, (4, 64))# 实例化编码器:词表100,模型维度512,8头,2048前馈维度,8层encoder = Encoder(vocab_size=100, padding_idx=0, d_model=512, n_heads=8, ffn_hidden=2048, num_layers=8, max_seq_len=512)# 前向传播out = encoder(x)print("输入形状:", x.shape) # torch.Size([4, 64])print("输出形状:", out.shape) # torch.Size([4, 64, 512]) -
上述参数解释
参数名 典型值 作用描述 vocab_size 30000 词表大小 padding_idx 0 指定padding token的索引 d_model 512 模型隐藏层维度 n_heads 8 注意力头数量 ffn_hidden 2048 前馈网络中间层维度 num_layers 6/8 编码层堆叠数量 max_seq_len 512 支持的最大序列长度