AI时代来临将带来文科复兴
“问渠那得清如许?为有源头活水来。”——朱熹《观书有感·其一》
要问池塘里的水为何这样清澈呢?是因为有永不枯竭的源头源源不断地为它输送活水。在AI时代,文科思维就如同这源头活水,为AI的发展和应用带来新的思路和方法。文科思维所具备的洞察事物本质、清晰阐述底层逻辑的能力,能够为AI的有效运用提供源源不断的动力,使AI在各个领域发挥更大的作用。

今日,同事向我们展示了其在AI助手研究领域的前期成果,并就当前面临的挑战展开了深入探讨。那么,AI助手究竟具备哪些具体功能呢?
简而言之,在企业级软件管理控制台中,以往管理员需通过点击操作来完成诸如创建用户、查询用户等任务。随着AI技术的迅猛发展,我们萌生了一个大胆的想法:能否像呼唤小爱同学那样,直接向AI下达“帮我创建一个用户”或“帮我查询一个用户”之类的指令呢?基于这一设想,我们开展了相关研究,并开发出了初步的原型。
然而,我们很快便发现了其中存在的挑战。具体而言,主要有以下四个方面的挑战:
第一个挑战在于,大模型语言AI在单个Function Call上的成功率较低。这意味着什么呢?当用户向AI助手提出需求时,后台会将用户的指令与软件支持的操作(即Function Call)一同发送给大语言模型(LLM)。大语言模型会对用户指令进行语义解析,并尝试匹配相应的操作。
例如,若用户指令是查询一个用户,大语言模型就需要从众多操作(如1000个)中找出与用户自然语言指令相匹配的Function Call,进而正确调用并完成查询操作,这便是AI调用的过程。
但该过程并非十全十美,存在一定的错误率。有时,AI虽能理解语义并找到对应的Function Call,却无法按照正确格式返回结果,此即指令遵从性问题。
伯克利大学设计了一个评测集,其中包含操作指令集和一系列Function Call,用于评估市面上流行的大语言模型。根据伯克利大学的评测结果,单次Function Call的正确调用率最高仅能达到80%左右,这便是我们面临的首个挑战。
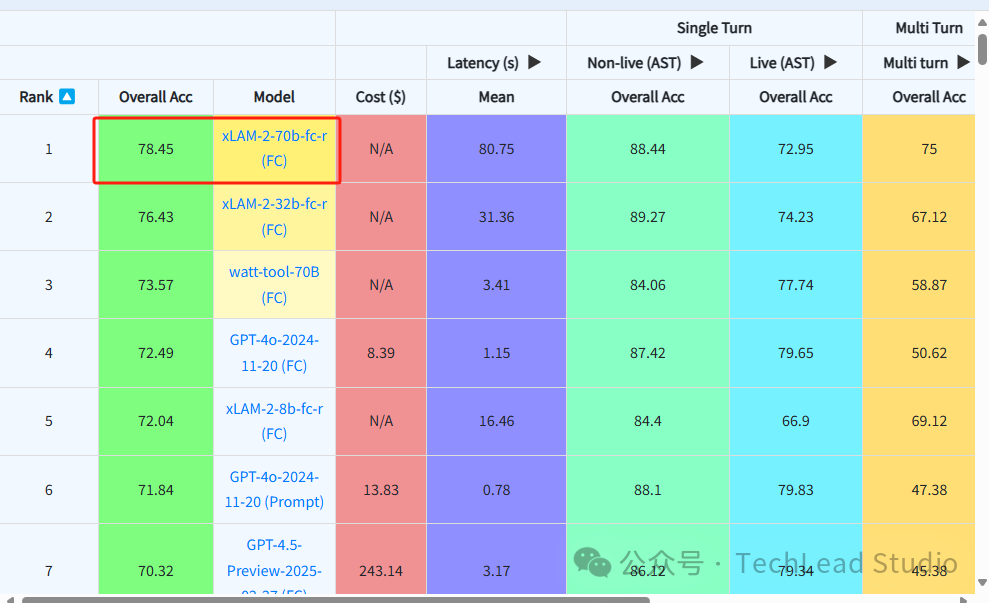
那么,如何解决这一问题呢?我们可以借助提示词工程的方法来提高大语言模型(LLM)找到Function Call的准确率。
首先,我们需要针对自身业务场景设计专属的评测集,其中涵盖自然语言操作指令集以及对应的Function Call操作描述集合。
什么是自然语言操作指令集呢?以我们的场景为例,用户操作包括创建用户、删除用户、查询用户、重置用户密码等一系列操作,这些操作共同构成了一个指令集。
随后,我们还需针对各个操作准备与之对应的详细操作接口描述,即Function Call的描述。例如,针对创建用户、重置用户信息、查询用户等操作,分别进行细致入微的描述。
接下来,我们要运用提示词工程的方法对提示词进行精心优化,使大模型能够依据这些提示词,精准无误地将用户的自然语言指令与对应的Function Call相匹配。为满足商业应用的要求,准确率需提升至90%以上,这便是应对首个挑战的解决之道。
那么,第二个挑战是什么呢?
了解上述过程后,我们很快意识到企业级软件中Function Call数量增长可能带来的问题,这构成了我们需要应对的第二个挑战。
设想企业软件的管理控制台,若要全面支持AI助手调用,其背后的API操作集可能多达数百乃至上千个。每次用户输入自然指令后,我们都需以Function Call的格式清晰准确地描述每个API,并将其全部传递给LLM大模型。如此一来,内容会变得极为冗长,进而引发两个主要问题:
其一,成本会显著增加。调用LLM大模型时,输入内容越多,成本就越高,这与token数量的消耗直接相关。
其二,准确率会受到影响。显然,在10个操作中寻找正确方法,要比在1000个操作中寻找容易得多。因此,当Function Call数量过多时,准确率会随之降低。
为解决这些问题,我们需要制定一套Function Call分类策略。这样,LLM大模型在查找时,可将搜索范围缩小至特定领域,从而提高效率和准确率。
为缩小一次性向大模型传递的Function Call列表范围,在调用LLM大模型之前,我们可依据语义进行筛选。例如,若判断用户的意图是进行与用户相关的操作,那么我们只需传递用户相关的Function Call集合,而无需传递机构操作或其他无关操作的集合。
如此一来,原本可能需传递的500个Function Call,现在或许仅需传递10个,大模型便能完成所有与用户相关的操作。
这便是应对我们所面临的第二个挑战的可行思路。
接下来,我们探讨第三个挑战。
当前,大模型在多轮任务调用场景下的成功率普遍偏低。以伯克利的评测结果为例,DeepSeek在多轮调用场景中的成功率仅为18%,尚未达到20%。
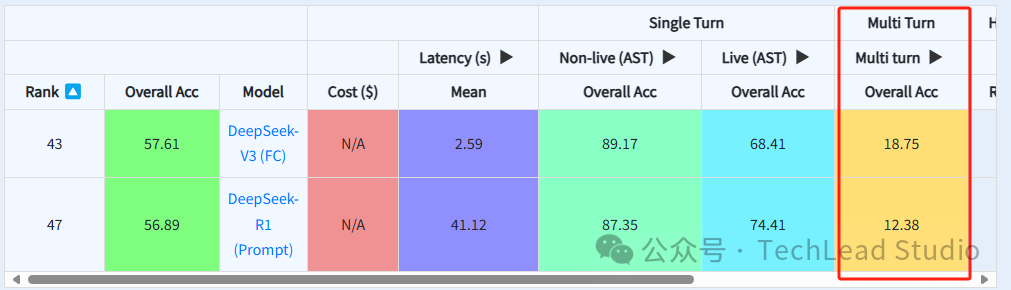
那么,什么是多轮调度呢?我们以“创建用户”这一指令为例进行说明。假设我们需要在武汉创建一位特定用户,用户姓名为某某某,期望AI助手协助完成此任务。在此过程中,AI需要调用多个后台服务:首先,查询武汉该机构的信息,获取其ID;接着,调用创建用户的服务,因为需要把机构的ID作为参数传递进去。
然而,大模型在执行这种多任务调用时会频繁出错。为解决这一问题,我们需要赋予大模型规划能力,使其能够将任务拆解为多个步骤,并制定执行计划,就像前段时间备受瞩目的Manus那样。
以“在武汉下面创建用户”这一指令为例,大模型需要将其拆解为两个步骤:先查找武汉这个节点,再调用创建用户的功能。通过这种任务拆解方式,大模型的执行成功率将显著提高。
接下来,我们探讨第四个挑战:AI的容错机制。
无论AI多么智能,错误率问题都难以避免。因此,在与AI助手交互时,我们必须设计一些容错机制来应对这些错误情况。例如,当AI无法识别某个指令时,应能够礼貌回应:“对不起,我听不懂。”
还有一种情况是,AI可能误解指令。比如,我让AI查询某个用户,它却误以为是重置用户密码。为了防范此类极端错误,我们需要在交互设计中融入一些容错机制。
具体来说,我们可以让AI在执行指令前进行确认。例如,AI可以询问:“您是要查询某某某用户吗?” 待用户确认后,AI再开始执行查询。通过这种方式,能够有效减少极端错误的发生。
回顾我们在企业级软件中应用AI的初步探索中发现的挑战,起初,我们认为此事看似简单,但深入实践后,才发现其中充满了各种复杂性和挑战,事情并非想象中那么容易。因此,面对任何问题,我们都不应轻易下结论,而应深入实践、亲身体验,才能做出更准确的评估。这是我的第一点感悟。
那么,这四种挑战的解决思路能否成功呢?我坚信,在业界长期使用AI的过程中,每个问题都已经有了相应的解决方案,只是我们目前尚未完全掌握。随着研究的不断深入,我们一定能够克服这些困难。
此外,我还有第二点感悟:对提示词工程有了更为深刻的理解。特别是在探讨第一个挑战时,调整提示词成为了关键步骤。
我突然意识到,调整提示词本质上与传统编码中调试计算机语言代码并无差异。过去,我们习惯使用计算机语言精确下达指令,控制计算机和网络执行各种任务,这就是传统的编码模式。而进入AI时代,提示词工程师实际上开创了一种全新的编码方式,他们不再使用Java、Python等计算机编程语言,而是运用自然语言,并且指令的对象也不再是计算机,而是AI大模型。
简言之,过去,我们借助计算机语言来操控计算机和网络;未来,自然语言将成为操控AI大模型的主要手段。
当前,理科在社会中占据主导地位,文科则逐渐衰落——复旦大学甚至裁撤了许多文科专业。这是因为在计算机时代,社会对文科生的需求相对较少,而对计算机工程师的需求却持续增长,毕竟计算机是当今世界的基础。
然而,当AI取代计算机成为世界的新基石时,情况将大不相同。我们更需要的是引导AI,向它准确地描述问题、构建问题框架,而这正是文科思维的优势所在。
我想未来社会所需的大量人才,不再是精通计算机语言的传统程序员,而是擅长描述问题和解决方案的提示词工程师,这一转变必将引发文科的复兴。
回顾AI的发展历程,不难发现,许多突破都受到了文科生思维的启发。
例如,丹尼尔·卡尼曼的《思考,快与慢》对OpenAI的研究起到了至关重要的作用。还有像凯文·凯利、尤瓦尔·赫拉利等文科作者撰写的《失控》《人类简史》等一系列书籍,他们虽是文科生,却能洞察事物的本质,清晰阐述事物的底层逻辑,进而准确预测未来。
这正是文科的核心价值所在。文科的终极是哲学,哲学探究的是世界的本质。而要充分发挥AI的效能,我们需要清晰认知事物的本质,从而向AI发出准确的指令。
诚然,理科人才在AI时代依旧不可或缺,但仅需少量顶尖人才负责基础设施的维护即可。社会的大量需求将转变为具备文科思维、能够向AI精准阐述需求的人才。
因此,AI时代的到来必将推动文科生群体的复兴。未来10到20年,大学文科专业有望比理科专业更受青睐。