从代码学习深度学习 - 目标检测前置知识(一) PyTorch 版
文章目录
- 前言
- 一、边界框 (Bounding Box)
- 1.1 边界框表示法转换
- 1.2 绘制边界框
- 二、锚框 (Anchor Box)
- 三、交并比 (Intersection over Union, IoU)
- 四、在训练数据中标注锚框
- 4.1 将真实边界框分配给锚框
- 4.2 标记类别和偏移量
- 五、使用非极大值抑制 (NMS) 预测边界框
- 六、绘图工具函数 (来自 utils\_for\_huitu.py)
- 七、功能测试
- 7.1 测试 `multibox_prior` 生成锚框
- 7.2 可视化生成的锚框
- 7.3 测试锚框标注 (`multibox_target`)
- 7.4 测试 NMS 和 `multibox_detection`
- 总结
前言
目标检测是计算机视觉领域中的一个核心问题,它的任务是识别图像中物体的类别并定位它们的位置。近年来,基于深度学习的目标检测算法取得了显著的进展。PyTorch 作为主流的深度学习框架之一,为目标检测的研究和应用提供了强大的支持。
本篇博客旨在通过代码实例,介绍目标检测任务中一些重要的前置知识,特别是与边界框 (Bounding Box) 和锚框 (Anchor Box) 相关的概念和常用工具函数。理解这些基础知识对于后续学习和实现更复杂的目标检测模型至关重要。我们将使用 PyTorch 来实现这些工具函数,并结合代码注释进行详细讲解。
完整的代码:下载链接
一、边界框 (Bounding Box)
在目标检测任务中,我们通常使用边界框来表示物体的位置。边界框是一个矩形框,能够框出图像中的目标物体。
1.1 边界框表示法转换
边界框有两种常见的表示方式:
- (左上角x, 左上角y, 右下角x, 右下角y):直接给出矩形框左上角和右下角顶点的坐标。
- (中心点x, 中心点y, 宽度, 高度):给出矩形框中心点的坐标以及矩形的宽度和高度。
在不同的算法或应用场景中,可能需要在这两种表示法之间进行转换。下面我们提供两个 PyTorch 函数来实现这两种表示法之间的相互转换。
import torch # 导入 PyTorch 库,用于张量操作def box_corner_to_center(boxes):"""将边界框从(左上角,右下角)表示法转换为(中心点,宽度,高度)表示法该函数接收以(x1, y1, x2, y2)格式表示的边界框张量,其中:- (x1, y1):表示边界框左上角的坐标- (x2, y2):表示边界框右下角的坐标然后将其转换为(cx, cy, w, h)格式,其中:- (cx, cy):表示边界框中心点的坐标- w:表示边界框的宽度- h:表示边界框的高度参数:boxes (torch.Tensor): 形状为(N, 4)的张量,包含N个边界框的左上角和右下角坐标返回:torch.Tensor: 形状为(N, 4)的张量,包含N个边界框的中心点坐标、宽度和高度"""# 分别提取所有边界框的左上角和右下角坐标x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]# 计算中心点坐标cx = (x1 + x2) / 2 # 中心点x坐标 = (左边界x + 右边界x) / 2cy = (y1 + y2) / 2 # 中心点y坐标 = (上边界y + 下边界y) / 2# 计算宽度和高度w = x2 - x1 # 宽度 = 右边界x - 左边界xh = y2 - y1 # 高度 = 下边界y - 上边界y# 将计算得到的中心点坐标、宽度和高度堆叠成新的张量boxes = torch.stack((cx, cy, w, h), axis=-1)return boxesdef box_center_to_corner(boxes):"""将边界框从(中心点,宽度,高度)表示法转换为(左上角,右下角)表示法该函数接收以(cx, cy, w, h)格式表示的边界框张量,其中:- (cx, cy):表示边界框中心点的坐标- w:表示边界框的宽度- h:表示边界框的高度然后将其转换为(x1, y1, x2, y2)格式,其中:- (x1, y1):表示边界框左上角的坐标- (x2, y2):表示边界框右下角的坐标参数:boxes (torch.Tensor): 形状为(N, 4)的张量,包含N个边界框的中心点坐标、宽度和高度返回:torch.Tensor: 形状为(N, 4)的张量,包含N个边界框的左上角和右下角坐标"""# 分别提取所有边界框的中心点坐标、宽度和高度cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]# 计算左上角坐标x1 = cx - 0.5 * w # 左边界x = 中心点x - 宽度/2y1 = cy - 0.5 * h # 上边界y = 中心点y - 高度/2# 计算右下角坐标x2 = cx + 0.5 * w # 右边界x = 中心点x + 宽度/2y2 = cy + 0.5 * h # 下边界y = 中心点y + 高度/2# 将计算得到的左上角和右下角坐标堆叠成新的张量boxes = torch.stack((x1, y1, x2, y2), axis=-1)return boxes
1.2 绘制边界框
为了直观地展示边界框,我们可以使用 Matplotlib 库来绘制它们。下面的代码展示了如何将常用的边界框表示法转换为 Matplotlib 能够识别的矩形格式,并在图像上绘制出来。
import matplotlib.pyplot as plt # 用于创建和操作 Matplotlib 图表
# 假设 utils_for_huitu.py 文件存在并已正确导入
import utils_for_huituutils_for_huitu.set_figsize() # 如果使用了自定义的绘图工具
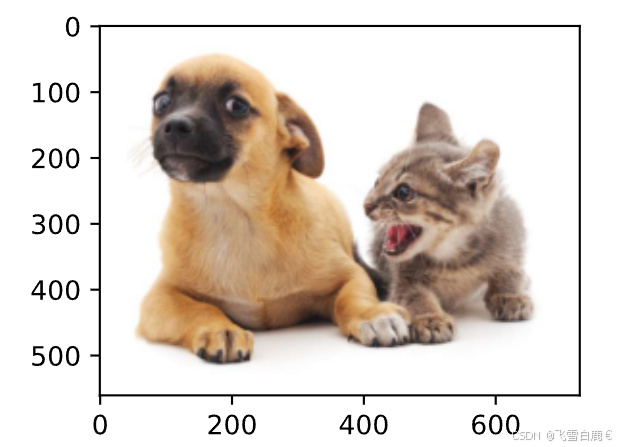
img = plt.imread('img/03_catdog.jpg') # 示例图片路径
plt.imshow(img); # 显示示例图片# 猫狗图像边界框坐标(左上角x,左上角y,右下角x,右下角y)
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]def bbox_to_rect(bbox, color):"""将边界框从(左上x, 左上y, 右下x, 右下y)格式转换为matplotlib的Rectangle格式在目标检测中,边界框通常使用左上角和右下角坐标表示,但matplotlib的Rectangle需要使用左上角坐标、宽度和高度来绘制矩形。此函数实现这一转换。参数:bbox (list): 包含4个元素的列表 [左上x, 左上y, 右下x, 右下y]color (str): 边界框的颜色,例如'red'、'blue'等返回:matplotlib.patches.Rectangle: 可添加到matplotlib图像上的矩形对象"""# 使用左上角坐标作为矩形起点# 宽度 = 右下角x - 左上角x# 高度 = 右下角y - 左上角yreturn plt.Rectangle(xy=(bbox[0], bbox[1]), # 矩形的左上角坐标width=bbox[2] - bbox[0], # 矩形的宽度height=bbox[3] - bbox[1], # 矩形的高度fill=False, # 设置为不填充矩形内部edgecolor=color, # 设置边界线颜色linewidth=2 # 设置边界线宽度为2)# 下面的代码假设已有一个图像对象 img 和 matplotlib axes 对象 fig.axes
fig = plt.imshow(img) # 示例:显示图像# 添加狗的边界框,使用蓝色
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue')) # 示例:绘制狗的边界框# 添加猫的边界框,使用红色
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red')) # 示例:绘制猫的边界框
plt.show() # 示例:显示带有边界框的图像

二、锚框 (Anchor Box)
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的 真实边界框 (ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。其中一种方法是以每个像素为中心,生成多个具有不同缩放比 (scale) 和宽高比 (aspect ratio) 的边界框。这些边界框被称为 锚框 (anchor box)。
假设输入图像的高度为 h h h,宽度为 w w w。我们以图像的每个像素为中心生成不同形状的锚框:缩放比为 s ∈ ( 0 , 1 ] s \in (0, 1] s∈(0,1],宽高比为 r > 0 r > 0 r>0。那么锚框的宽度和高度分别是 w s r ws\sqrt{r} wsr 和 h s / r hs/\sqrt{r} hs/r。请注意,当中心位置给定时,已知宽和高的锚框是确定的。
为了生成多个不同形状的锚框,可以设置多个缩放比 s 1 , … , s n s_1, \dots, s_n s1,…,sn 和多个宽高比 r 1 , … , r m r_1, \dots, r_m r1,…,rm。当使用这些缩放比和宽高比的所有组合以每个像素为中心时,输入图像将总共有 w h n m whnm whnm 个锚框。但这样计算复杂度会很高。实践中,通常只考虑包含 s 1 s_1 s1 或 r 1 r_1 r1 的组合:
( s 1 , r 1 ) , ( s 1 , r 2 ) , … , ( s 1 , r m ) , ( s 2 , r 1 ) , … , ( s n , r 1 ) (s_1, r_1), (s_1, r_2), \dots, (s_1, r_m), (s_2, r_1), \dots, (s_n, r_1) (s1,r1),(s1,r2),…,(s1,rm),(s2,r1),…,(sn,r1)
也就是说,以同一像素为中心的锚框数量是 n + m − 1 n + m - 1 n+m−1。对于整个输入图像,将共生成 w h ( n + m − 1 ) wh(n + m - 1) wh(n+m−1) 个锚框。
下面是生成锚框的 PyTorch 函数实现:
import torch
torch.set_printoptions(2) # 精简输出精度def multibox_prior(data, sizes, ratios):"""生成以每个像素为中心具有不同形状的锚框参数:data:输入图像张量,维度为(批量大小, 通道数, 高度, 宽度)sizes:锚框缩放比列表,元素个数为num_sizes,每个元素∈(0,1]ratios:锚框宽高比列表,元素个数为num_ratios,每个元素>0返回:输出张量,维度为(1, 像素总数*每像素锚框数, 4),表示所有锚框的坐标"""# 获取输入数据的高度和宽度# in_height, in_width: 标量in_height, in_width = data.shape[-2:]#