全局id生成器生产方案
1.只要求不重复版本(常用于分布式确定一个实体的id)
uuid( MAC 地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,计算机基于这些规则生成的 UUID 是肯定不会重复的。)
UUID 作为 MySQL 数据库主键的时候就非常不合适
- 优点:生成速度通常比较快、简单易用
- 缺点:存储消耗空间大(32 个字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID
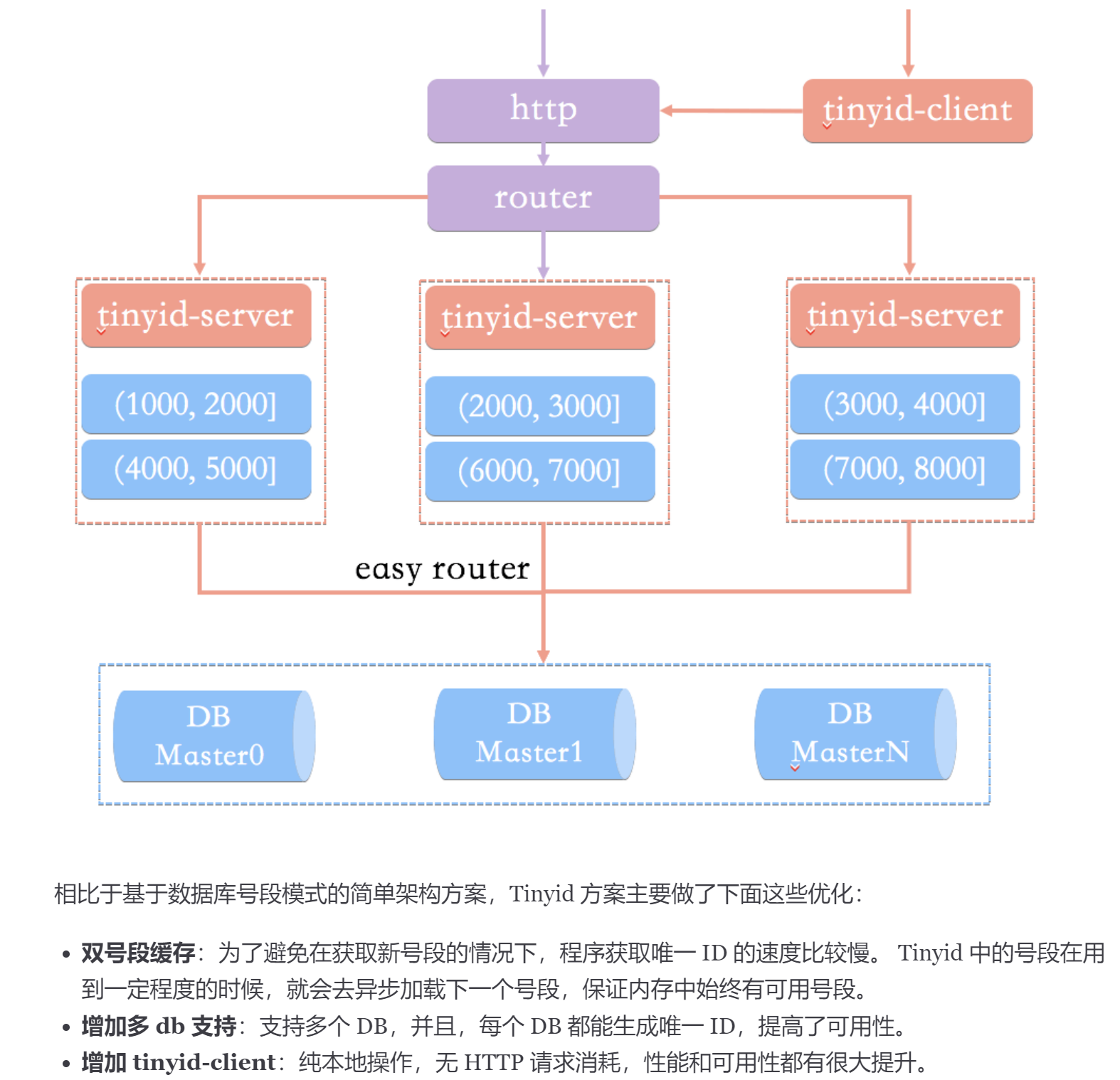
滴滴的tinyid
tinynyid是这么做的,让A只生成偶数id,B只生产奇数id,对应的db设计增加了两个字段

雪花算法

Leaf 提供了 号段模式 和 Snowflake(雪花算法) 这两种模式来生成分布式 ID。并且,它支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper(使用 Zookeeper 作为注册中心,通过在特定路径下读取和创建子节点来管理 workId) 。
美团Leaf框架通过多维度协同机制解决雪花算法的时钟回拨问题,具体实现逻辑如下:
-
启动阶段双重校验机制
- 节点首次启动时,需在ZooKeeper创建持久节点
leaf_forever/${self}并写入当前系统时间;非首次启动则需对比本地时间与节点历史记录时间,若本地时间小于历史值则判定为时钟回退,直接阻断服务启动并触发报警27。 - 新节点还需通过RPC获取其他运行中Leaf节点的系统时间,计算集群平均时间。若本地时间与平均时间偏差超过预设阈值(如10秒),同样判定为时钟异常并拒绝启动57。
- 节点首次启动时,需在ZooKeeper创建持久节点
-
运行时持续同步监控
- 运行过程中,每3秒向ZooKeeper临时节点
leaf_temporary/${self}上报当前系统时间,维持节点租约有效性,同时动态感知集群时间基线7。 - 若检测到本地时间突然后退且超过可接受范围(如短时NTP同步误差阈值),立即停止ID生成服务,避免产生重复ID28。
- 运行过程中,每3秒向ZooKeeper临时节点
-
异常处理策略
- 针对短时间回拨(如≤5ms),采用阻塞等待策略直至本地时钟恢复,期间暂停ID生成以避免冲突2。
- 对长时间不可恢复的时钟回退(如人工误操作导致),依赖ZooKeeper协调切换备用节点,保证服务高可用性25。
-
WorkerID动态管理
通过ZooKeeper自动分配唯一WorkerID,避免人工配置错误导致多节点共用相同WorkerID,从根源上减少因WorkerID重复引发的ID冲突风险78。
该方案通过启动校验、实时监控、异常熔断三层防御,在保障服务连续性的同时有效规避时钟回拨导致的ID重复问题25。
2.要求不重复版本且非严格递增(TSO服务和常用于分布式确定一个实体的id)
TiDB/TiKV PD服务
整个集群的 TSO 授时工作都集中在了 PD 身上,所以怎样做到低延迟,高性能和良好的容错,是我们在实现时需要关注的几个目标点。
TSO 是一个 int64 的整型,它由 Physical time 和 Logical time 两个部分组成。Physical time 是当前的 Unix 系统时间戳(毫秒),而 Logical time 则是一个范围在 [0, 1 << 18] 的计数器。这样一来便做到了在每毫秒的物理时间粒度上又可以继续细化成最多 262144 个 TSO,足以满足绝大多数使用场景了
PD 的 TSO 授时工作是由集群中 leader 来完成的。为了在 PD 集群中持久化当前分配的最大 TSO,避免因为 leader 挂掉而影响 TiDB 的事务,我们需要把 TSO 的物理时间戳存储到 etcd 中去。同时为了提高响应授时 RPC 请求的速度,我们也要避免与 etcd 交互得过于频繁,不能每有一次 TSO 更新就进行一次 etcd 读写。所以我们要存储的并不能是最近一次的授时结果,而是一个时间窗口的范围,这一点我们会在稍后的时间戳递进实现中做进一步阐述。
于是需要通过使用 last 并强制增加一个精度范围来进行控制,从而保证新上任的 leader 所分配的 TSO 一定大于之前所有已分配的 TSO。
由于逻辑时钟有范围限制,如果超出这个限制,leader 会选择睡眠 UpdateTimestampStep 长度的时间(默认 50 毫秒)来等待时间被推进
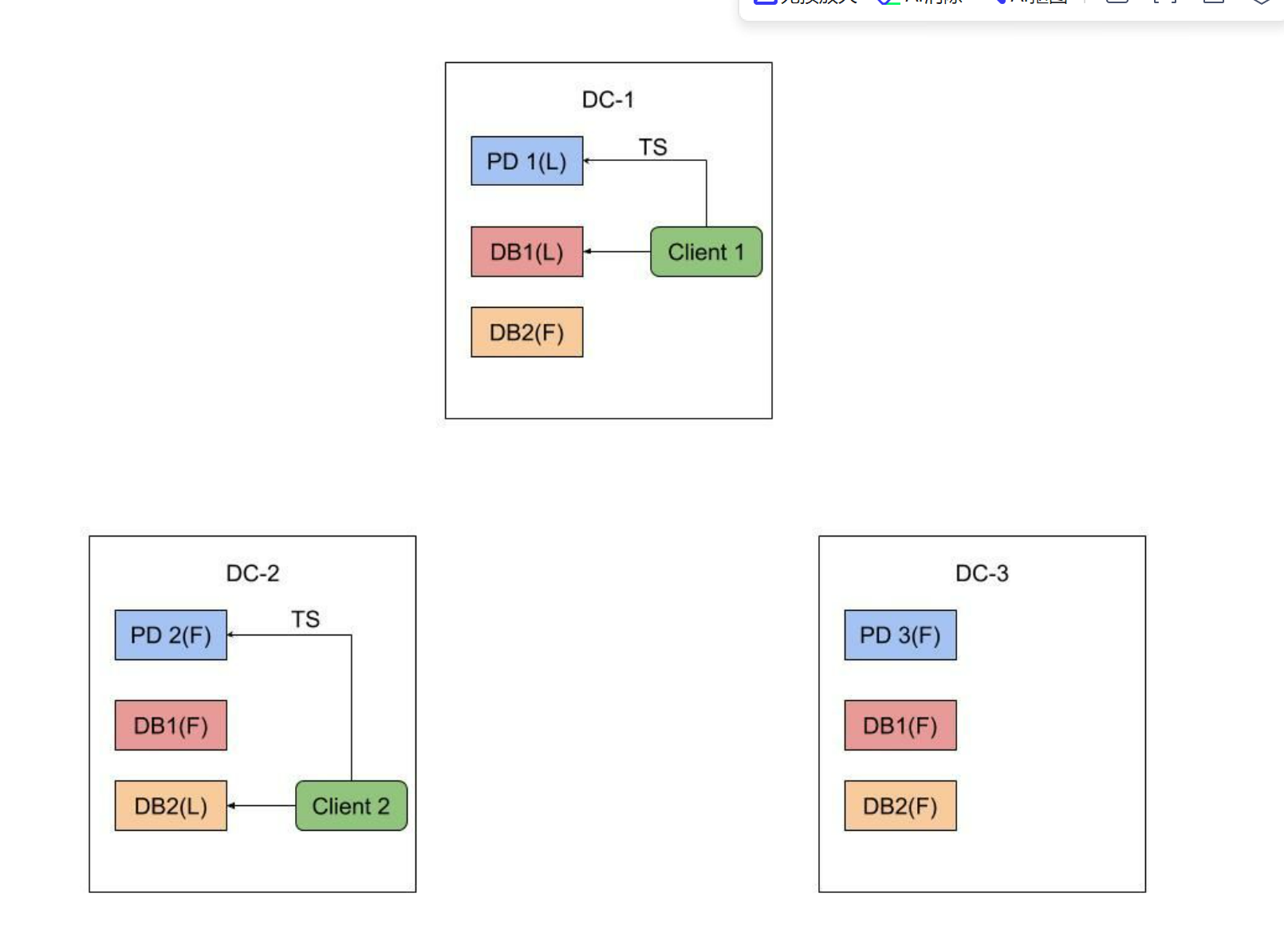
PD 采用了中心式的时钟解决方案,本质上还是混合逻辑时钟。但是由于其是单点授时,所以是全序的。中心式的解决方案实现简单,但是跨区域的性能损耗大,因此实际部署时,会将 PD 集群部署在同一个区域,避免跨区域的性能损耗。但是有一个绕不开的场景便是跨 DC 授时,上图展示了这样一种情况——我们只能通过 PD leader 来分配 TS,所以对于 client 2 来说,它需要跨 DC 先从 DC1 的 PD 上面拿 TSO,而这样做势必会影响到 client 2 的延迟。但往往用户的业务是有 DC 关联特性的,如果一次事务所涉及的数据读写只会发生在一个 DC 上面,那么我们其实只需要保证当前 DC 内的 Linearizability
Go 的 runtime 调度并没有优先级的概念,当 goroutine 越多时,TSO 更新分配的 goroutine 越容易迟迟拿不到执行的机会,从而会致获取 TSO 变慢
此外,PD 通过引入 etcd 解决了单点的可用性问题,一旦 leader 节点故障,会立刻选举新的 leader 继续提供服务,理论上来讲由于 TSO 授时只通过 PD 的一个 leader 提供,所以可能是一个潜在的瓶颈,但是从目前使用情况看,PD 的 TSO 分配性能并没有成为过 TiDB 事务中的瓶颈。
即只有当系统时间大于当前(也就是旧)TSO 物理时间戳时才会对其进行更新
我们发现上一次存储在 etcd 中的值和当前时间已经接近到一毫秒及以内时,说明上一个窗口时间即将或已经到期耗尽,需要我们对时间窗口进行滑动,开辟新的可用时间空间,即加上默认的 3s 时间间隔并写入 etcd
基于Redis和mysql的单调TSO服务(安全非严格递增问题)
高可用保障,redis主从,切片(保障的是非递增)
mysql HA集群