【从0到1搞懂大模型】transformer先导:seq2seq、注意力机制、残差网络等(6)
(一)Seq2Seq&编码器-解码器
1. Seq2Seq
seq2seq 表示序列到到序列,即你的输入是一个序列数据,输出也是一个序列数据,我们常见的 seq2seq 有以下几种类型(区别于基于多个零散特征的分类问题)
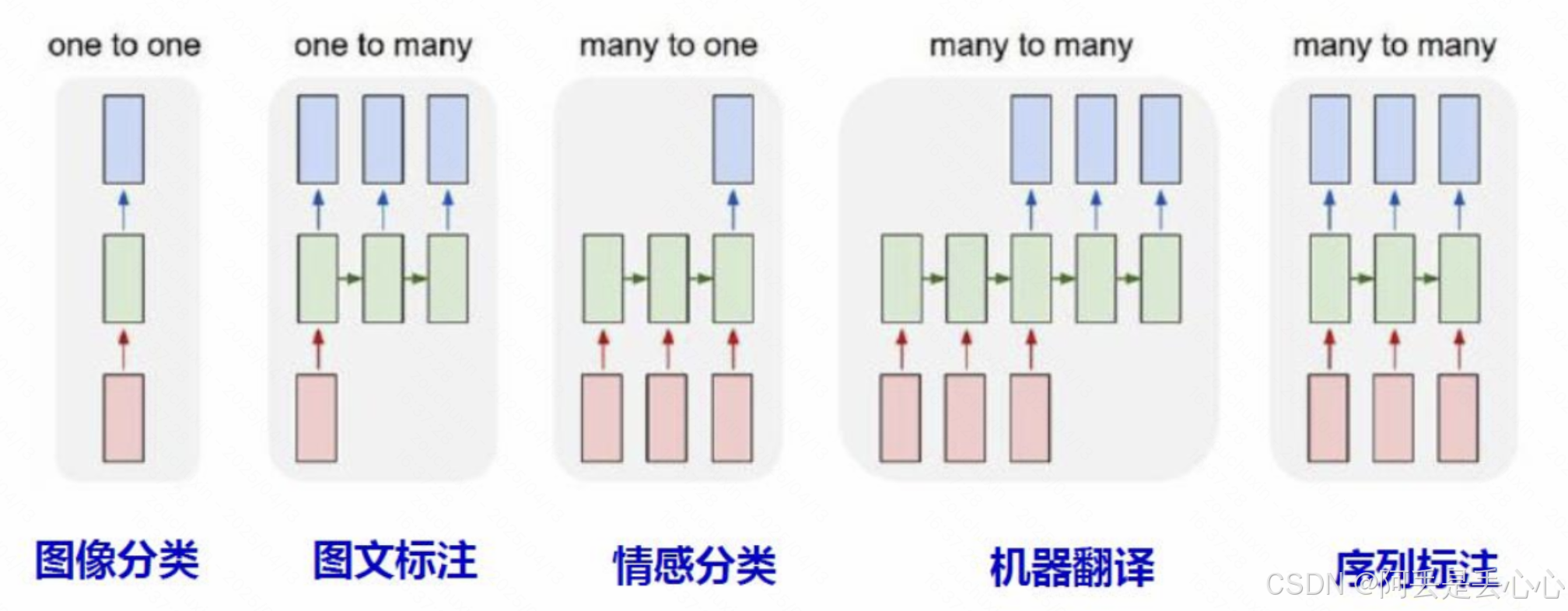
- 一对多
每个输入是独立的,与相邻输入无关,输出是由多个单词(不是字母)组成的序列。
每个单词(而不是一个字母,也不是一句话)是一个输出,为了满足自然语言的特征,单词与单词之间,是有关联的,不是相互独立的。即输入虽然没有序列,但输出是有序列的。
例子:文本生成、音乐生成、图文标注
- 多对一
多个输入之间是有时序关系。即多个输入,如“我”、“打”、“你”,如果时序关系不同,其含义也是不相同的,即为不同的输入,也就需要有不同的输出。
例子:情感分析、新闻分类、关键词提取
-
多对多
- 数量相同的多对多
输入与输出,都是有多个独立单元组成的序列,但输入和输出单元的个数是相同的。
例子:视频标注、视频识别行为
- 数量不相同的多对多
输入与输出,都是有多个独立单元组成的序列,但输入和输出单元的个数是不一定相同的。
例子:语音识别、机器翻译
2. 编码器解码器结构
机器翻译是序列转换模型的一个核心问题, 其输入和输出都是长度可变的序列。 为了处理这种类型的输入和输出, 我们可以设计一个包含两个主要组件的架构: 第一个组件是一个编码器(encoder): 它接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态。 第二个组件是解码器(decoder): 它将固定形状的编码状态映射到长度可变的序列。
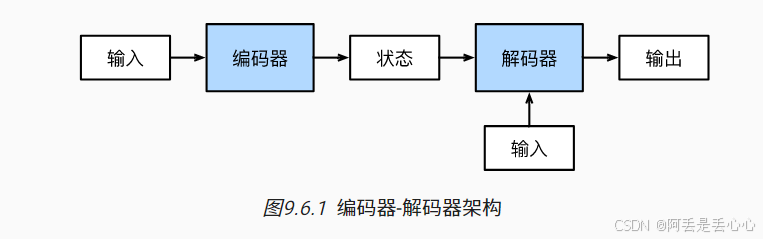
假设我们当前的编码器和解码器都是 RNN 结构, 编码器的作用是将输入数据编码成一个特征向量,然后解码器将这个特征向量解码成预测结果
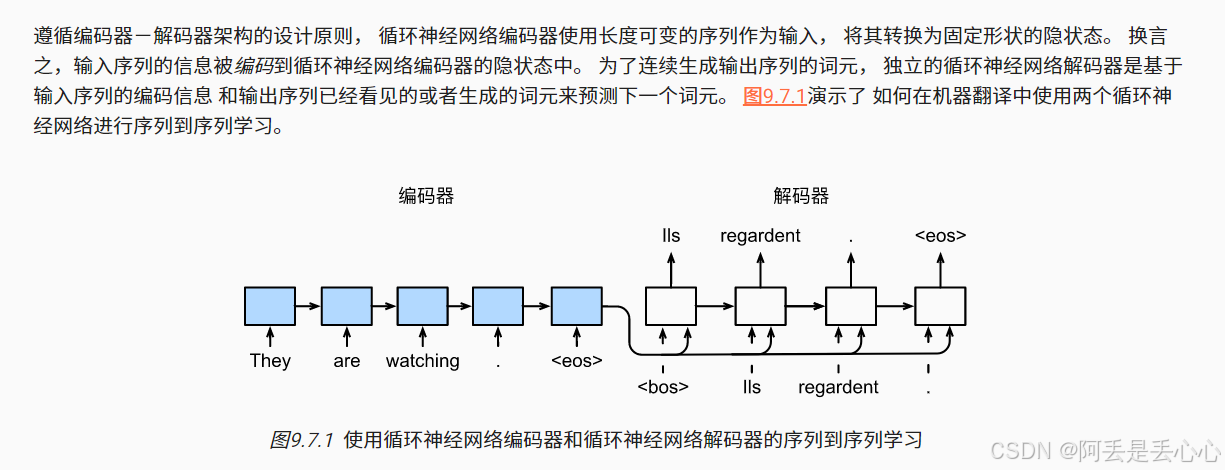
(1) 编码器

#@save
class Seq2SeqEncoder():
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,
dropout=dropout)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步
X = X.permute(1, 0, 2)
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state(2)解码器

class Seq2SeqDecoder():
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播context,使其具有与X相同的num_steps
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state(3)串起来
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
dtype = torch.FloatTensor
char_list = [c for c in 'SEPabcdefghijklmnopqrstuvwxyz']
char_dic = {n:i for i,n in enumerate(char_list)}
seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
seq_len = 8
n_hidden = 128
n_class = len(char_list)
batch_size = len(seq_data)
def make_batch(seq_data):
batch_size = len(seq_data)
input_batch,output_batch,target_batch = [],[],[]
for seq in seq_data:
for i in range(2):
seq[i] += 'P' * (seq_len - len(seq[i]))
input = [char_dic[n] for n in seq[0]]
output = [char_dic[n] for n in ('S' + seq[1])]
target = [char_dic[n] for n in (seq[1] + 'E')]
input_batch.append(np.eye(n_class)[input])
output_batch.append(np.eye(n_class)[output])
target_batch.append(target)
return Variable(torch.Tensor(input_batch)),Variable(torch.Tensor(output_batch)),Variable(torch.LongTensor(target_batch))
input_batch,output_batch,target_batch = make_batch(seq_data)
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq,self).__init__()
self.encoder = nn.RNN(input_size = n_class,hidden_size = n_hidden)
self.decoder = nn.RNN(input_size = n_class,hidden_size = n_hidden)
self.fc = nn.Linear(n_hidden,n_class)
def forward(self,enc_input,enc_hidden,dec_input):
enc_input = enc_input.transpose(0,1)
dec_input = dec_input.transpose(0,1)
_,h_states = self.encoder(enc_input,enc_hidden)
outputs,_ = self.decoder(dec_input,h_states)
outputs = self.fc(outputs)
return outputs
model = Seq2Seq()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
for epoch in range(5001):
hidden = Variable(torch.zeros(1,batch_size,n_hidden))
optimizer.zero_grad()
outputs = model(input_batch,hidden,output_batch)
outputs = outputs.transpose(0,1)
loss = 0
for i in range(batch_size):
loss += criterion(outputs[i],target_batch[i])
if (epoch % 500) == 0:
print('epoch:{},loss:{}'.format(epoch,loss))
loss.backward()
optimizer.step()
def translated(word):
input_batch,output_batch,_ = make_batch([[word,'P'*len(word)]])
hidden = Variable(torch.zeros(1,1,n_hidden))
outputs = model(input_batch,hidden,output_batch)
predict = outputs.data.max(2,keepdim=True)[1]
decode = [char_list[i] for i in predict]
end = decode.index('P')
translated = ''.join(decode[:end])
print(translated)
(二)seq2Seq + Attention
可以发现上面的 Seq2Seq 方式只是将编码器的最后一个节点的结果进行了输出,但是对于一个序列长度特别长的特征来说,这种方式无疑将会遗忘大量的前面时间片的特征
我们如何给解码器提供更好的特征呢,与其输入最后一个时间片的结果,不如将每个时间片的输出都提供给解码器。那么解码器如何使用这些特征?——attention
1. 解释 Attention
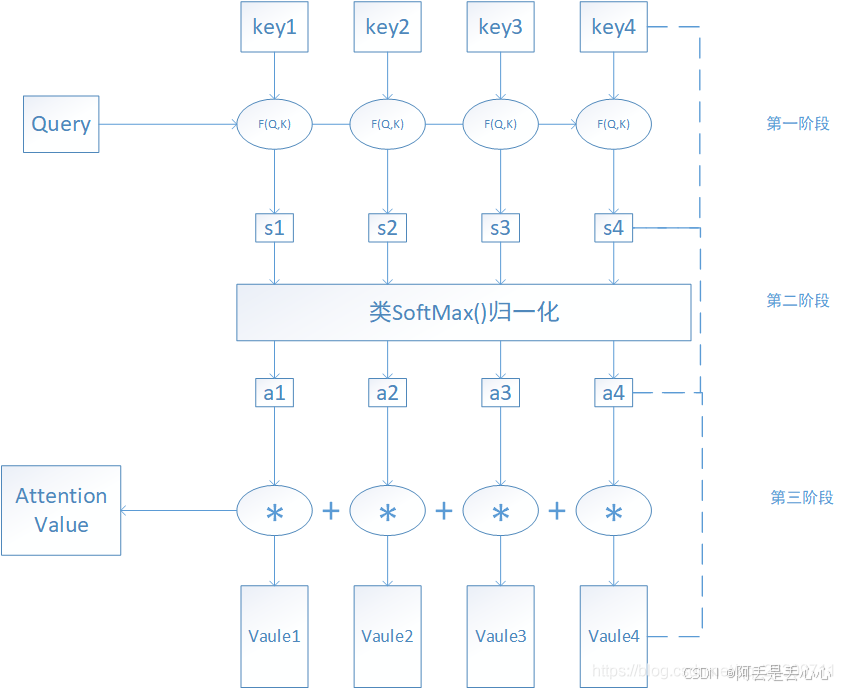
注意力机制核心:关注重点的信息,忽略非重点信息
这里就涉及到 QKV

怎么理解QKV——以搜索为例
- Query(Q):用户的搜索词(如
"巴黎旅游攻略"),表示当前需要解决的问题。 - Key(K):网页的关键词(如
"巴黎景点"、"旅行住宿"),用于匹配Query的相关性。 - Value(V):网页的实际内容(如景点介绍文本),是被提取的信息主体。
注意力机制通过 Q-K匹配确定权重,再对 V加权求和提取信息。


整体如下图
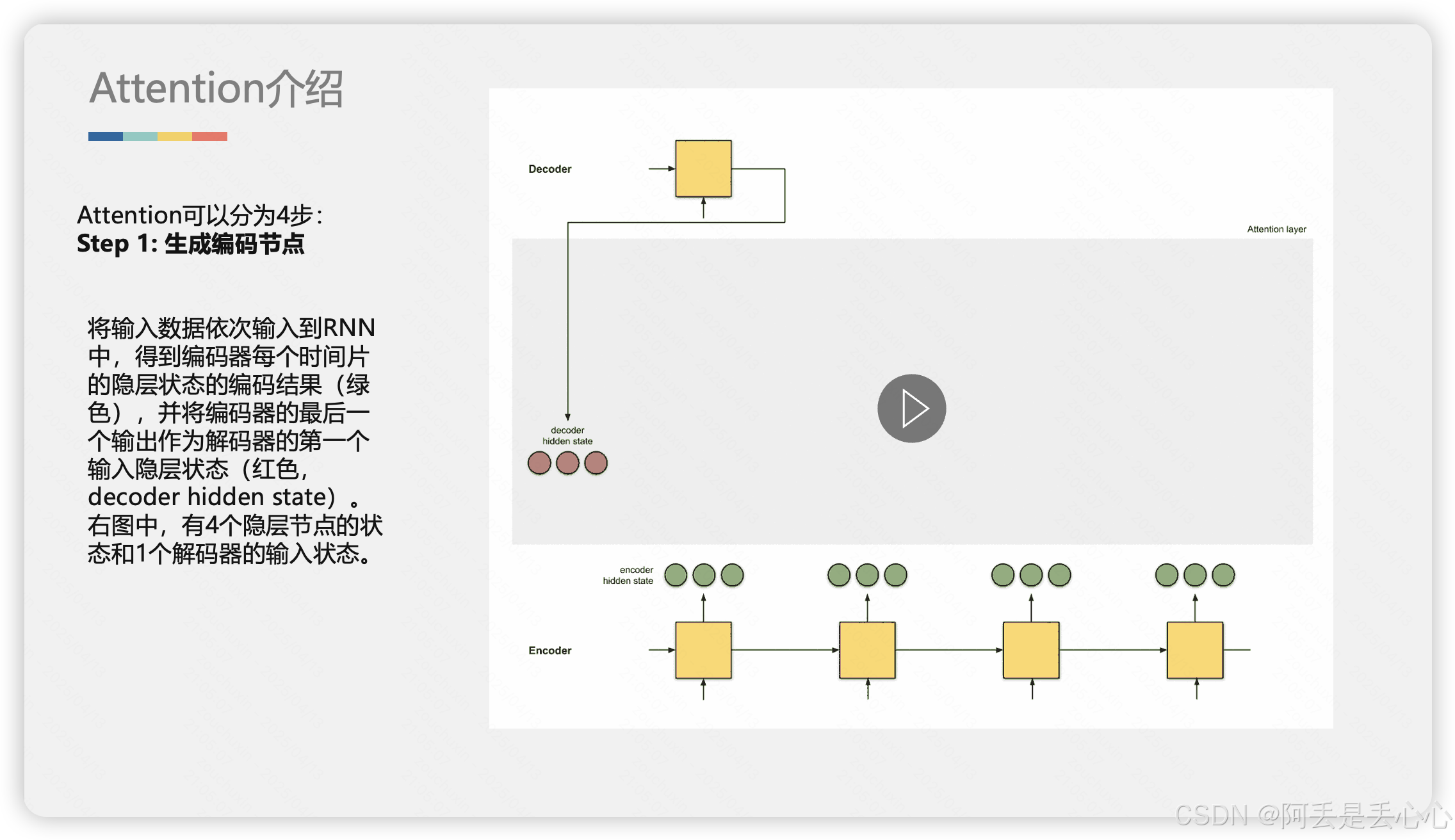
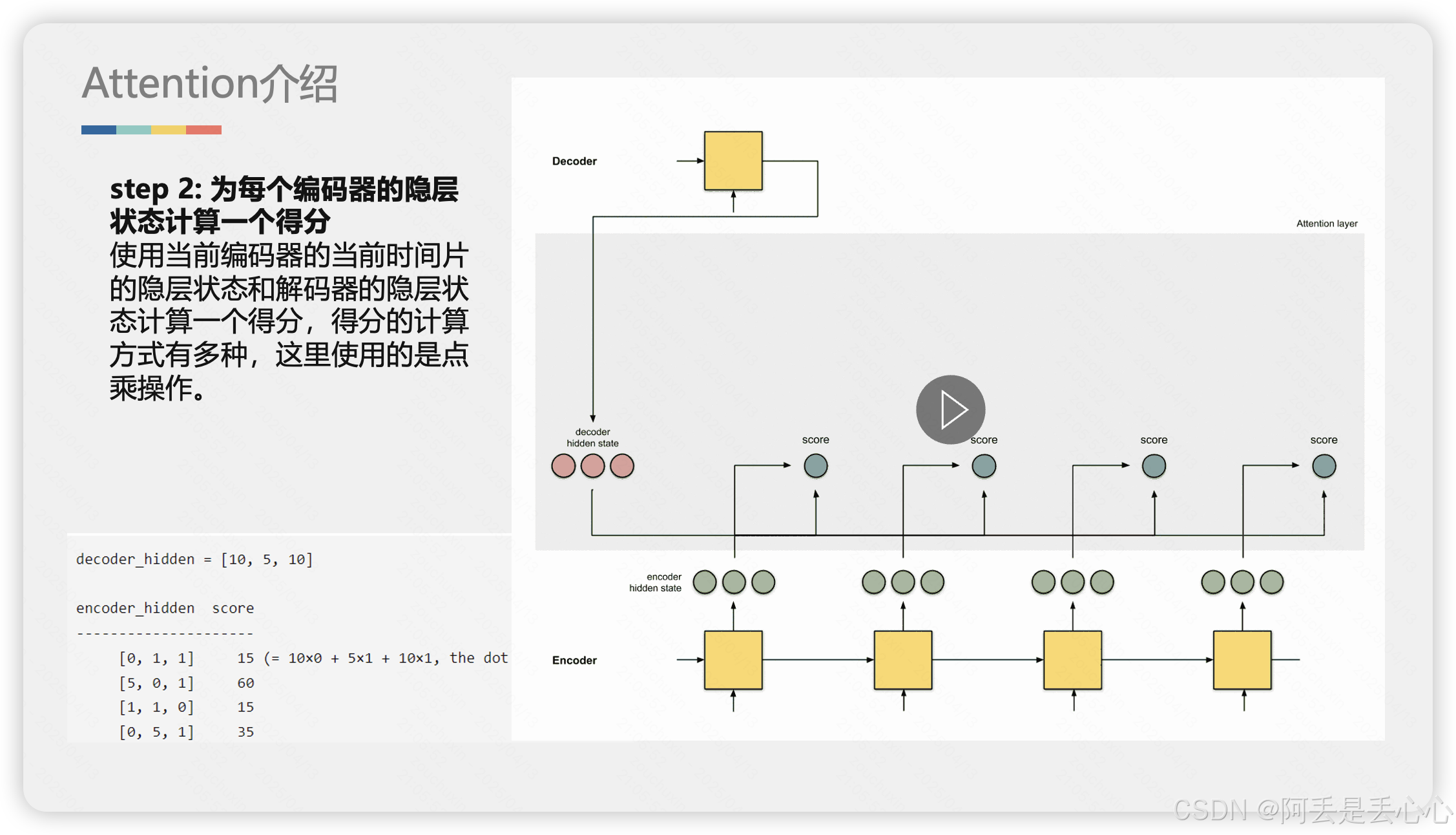
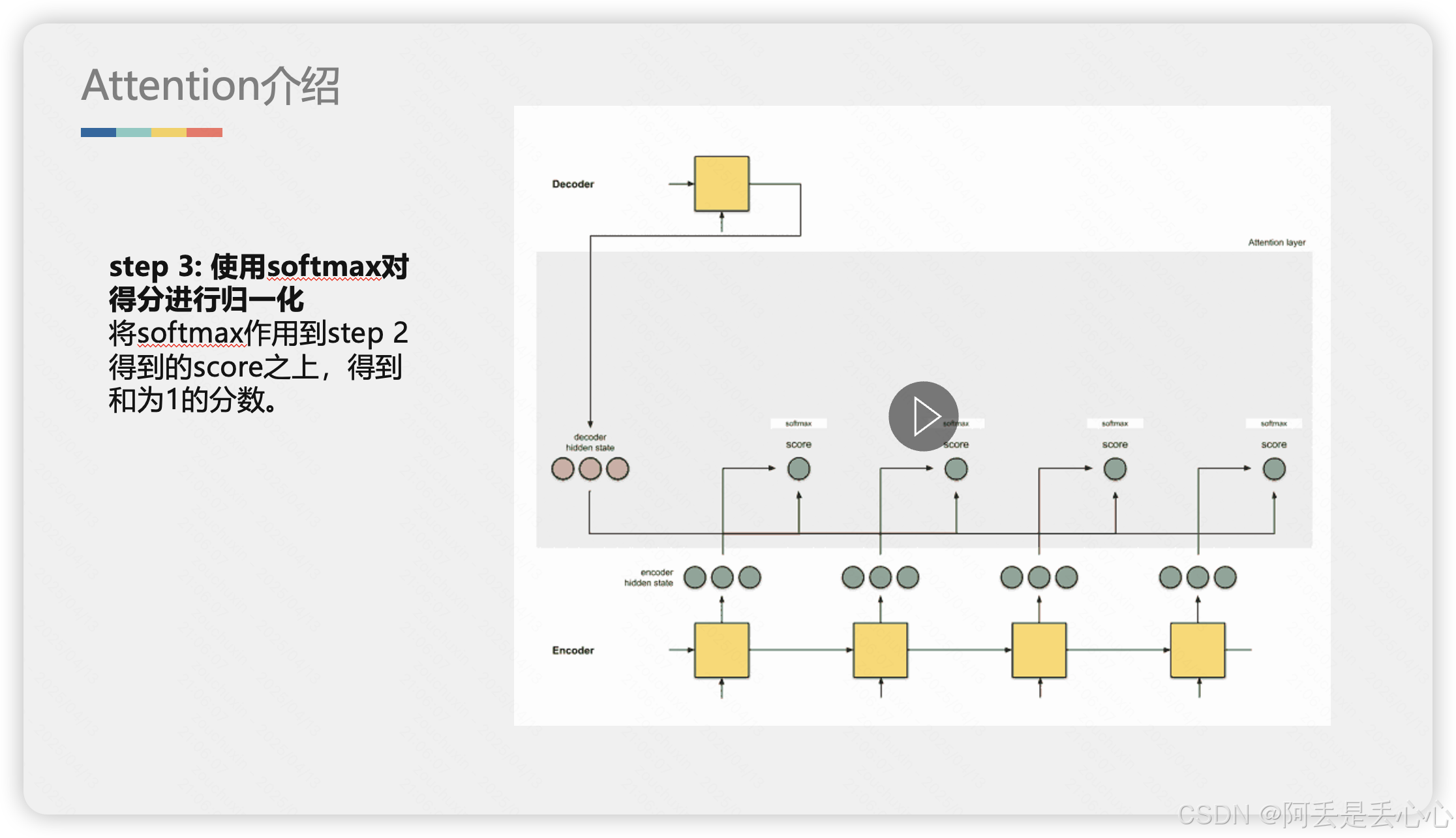
2. 详细解释Attention
下面我用更详细的动图和示例解释一下 Attention 是如何工作的,动态情况可以详情见资源包(动图没办法上传了)
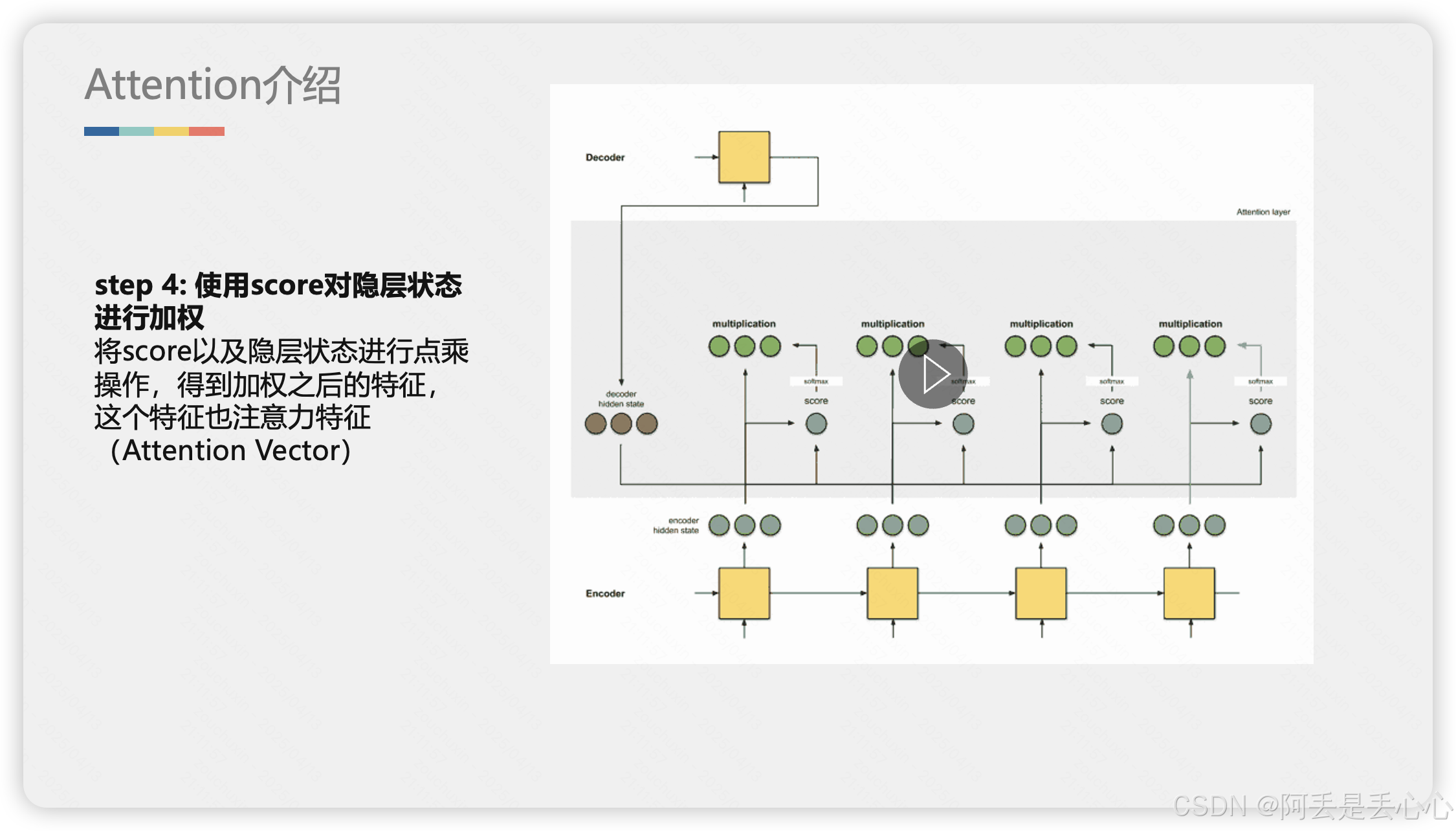
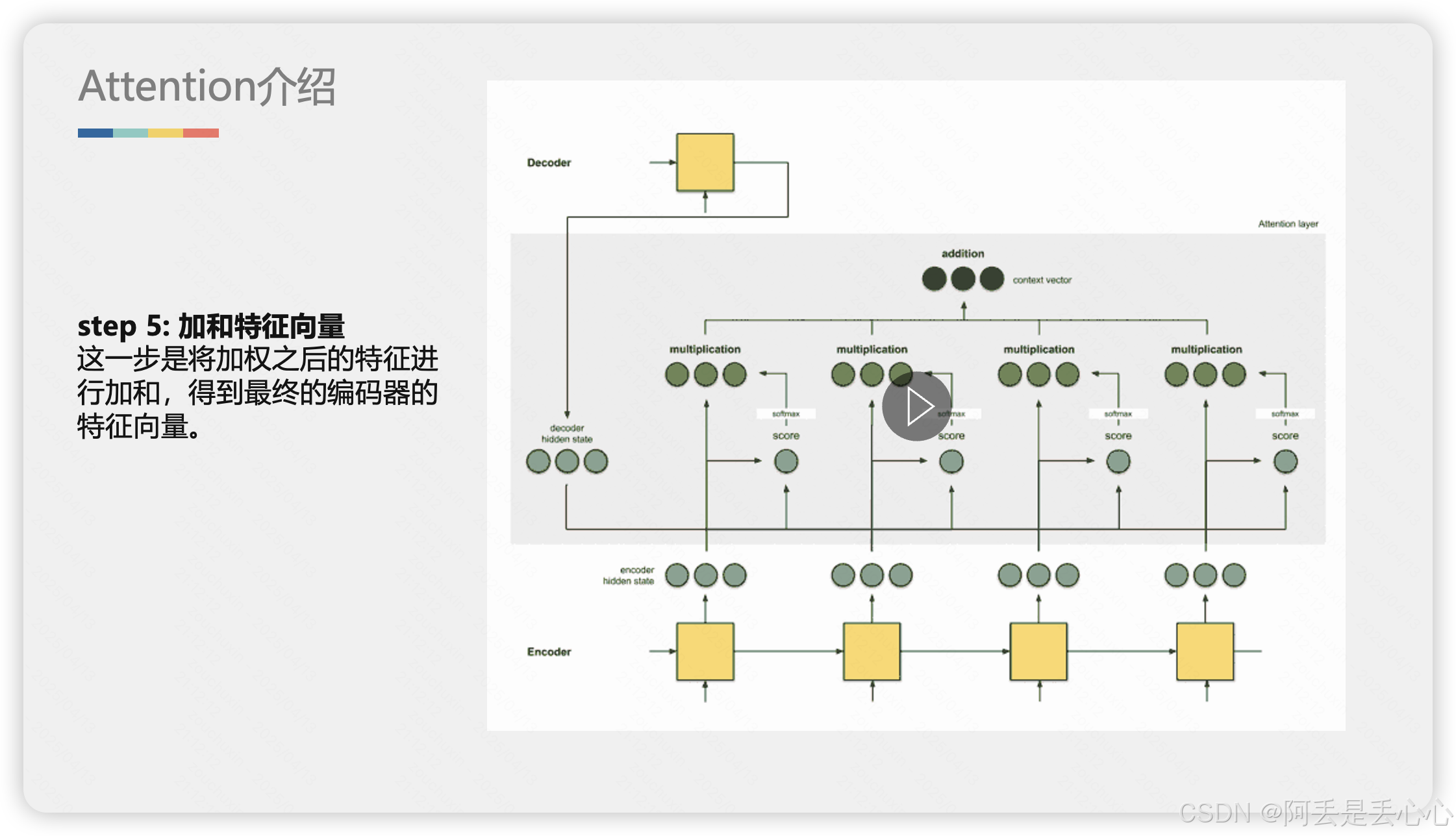
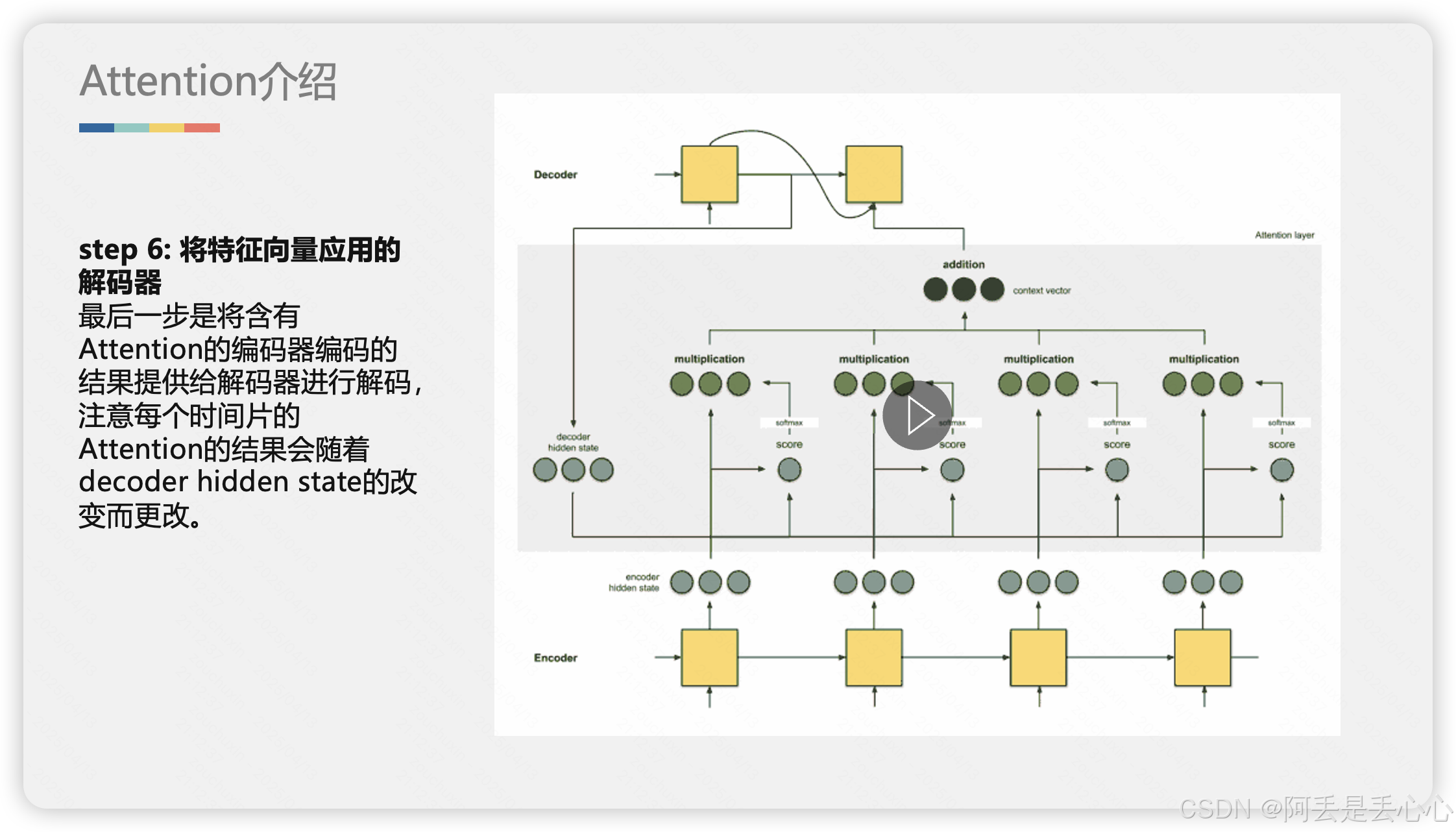
3. 代码解释
(这里不方便写公式直接截图了)
(1)encoder

class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional = True)
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
'''
src = [src_len, batch_size]
'''
src = src.transpose(0, 1) # src = [batch_size, src_len]
embedded = self.dropout(self.embedding(src)).transpose(0, 1)
enc_output, enc_hidden = self.rnn(embedded)
s = torch.tanh(self.fc(torch.cat((enc_hidden[-2,:,:], enc_hidden[-1,:,:]), dim = 1)))
return enc_output, s(2)Attention

class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim, bias=False)
self.v = nn.Linear(dec_hid_dim, 1, bias = False)
def forward(self, s, enc_output):
batch_size = enc_output.shape[1]
src_len = enc_output.shape[0]
s = s.unsqueeze(1).repeat(1, src_len, 1)
enc_output = enc_output.transpose(0, 1)
energy = torch.tanh(self.attn(torch.cat((s, enc_output), dim = 2)))
attention = self.v(energy).squeeze(2)
return F.softmax(attention, dim=1)(3) decoder

class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.fc_out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, dec_input, s, enc_output):
dec_input = dec_input.unsqueeze(1)
embedded = self.dropout(self.embedding(dec_input)).transpose(0, 1)
a = self.attention(s, enc_output).unsqueeze(1)
enc_output = enc_output.transpose(0, 1)
c = torch.bmm(a, enc_output).transpose(0, 1)
rnn_input = torch.cat((embedded, c), dim = 2)
dec_output, dec_hidden = self.rnn(rnn_input, s.unsqueeze(0))
embedded = embedded.squeeze(0)
dec_output = dec_output.squeeze(0)
c = c.squeeze(0)
pred = self.fc_out(torch.cat((dec_output, c, embedded), dim = 1))
return pred, dec_hidden.squeeze(0)(4) Seq2Seq

class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
batch_size = src.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
enc_output, s = self.encoder(src)
dec_input = trg[0,:]
for t in range(1, trg_len):
dec_output, s = self.decoder(dec_input, s, enc_output)
outputs[t] = dec_output
teacher_force = random.random() < teacher_forcing_ratio
top1 = dec_output.argmax(1)
dec_input = trg[t] if teacher_force else top1
return outputs之后再进行训练就 ok 啦
上面主要是讲了注意力机制的基本原理和使用方法(也算是之后 transform 的多头自注意力机制的基础)
(三)残差网络
在深度学习中,网络层数增多一般会伴着下面几个问题
问题1可以通过GPU集群来解决,对于一个企业资源并不是很大的问题;
问题2的过拟合通过采集海量数据,并配合Dropout正则化等方法也可以有效避免;
问题3通过Batch Normalization也可以避免。
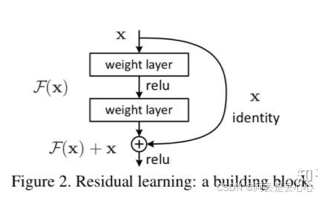
但有研究发现,随着网络层数的增加,网络发生了退化(degradation)的现象:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当你再增加网络深度的话,训练集loss反而会增大。注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。
这里提供了一种想法:既然深层网络相比于浅层网络具有退化问题,那么是否可以保留深层网络的深度,又可以有浅层网络的优势去避免退化问题呢?
残差网络依旧让非线形层满足 H(w,x),然后从输入直接引入一个短连接到非线形层的输出上,使得整个映射变为
Y = H(w,x) + x
(四)Layer normalization
针对 LN,我们要先了解一下 BN
(1)Batch Normalization
Batch Normalization是2015年一篇论文中提出的数据归一化方法,往往用在深度神经网络中激活层之前。其作用可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。
对同一特征通道的所有样本进行归一化,适用于批量数据。
- 计算方式:对每个特征维度(通道)在批量的所有样本上计算均值和方差。
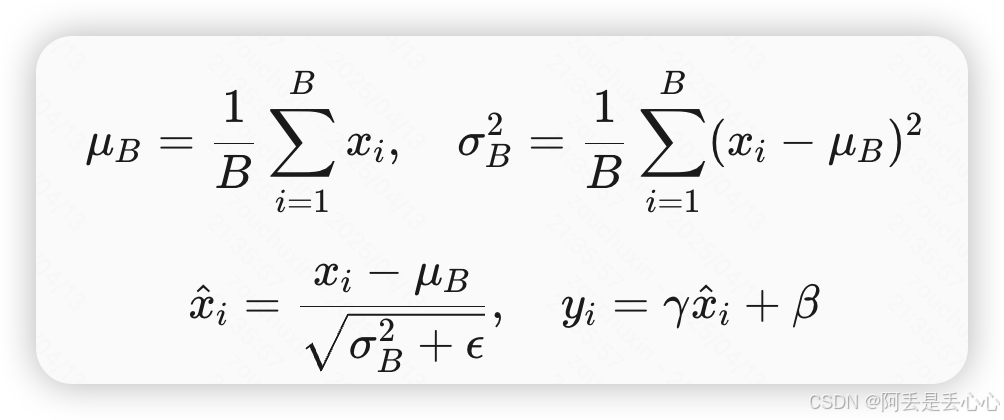
(2)Layer Normalization
Layer Normalization (LN) 对单个样本的所有特征进行归一化,独立于批量大小。
- 计算方式:对每个样本的所有特征维度计算均值和方差。
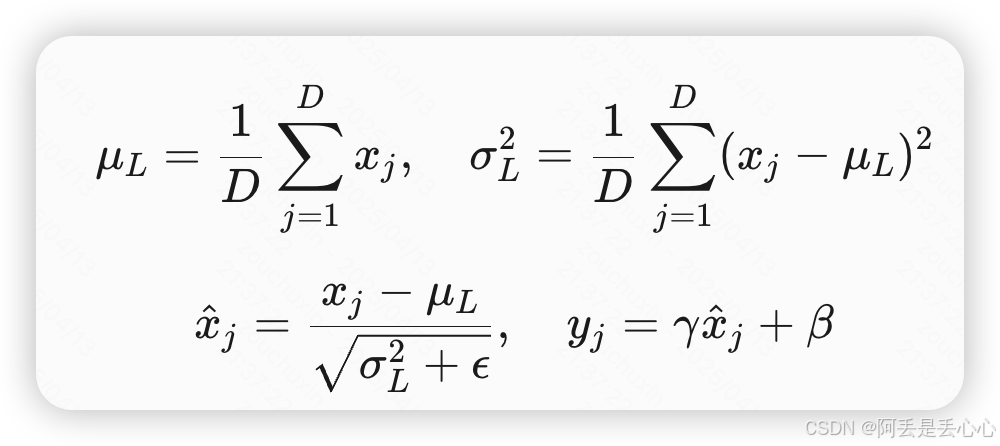
更直观区别如下
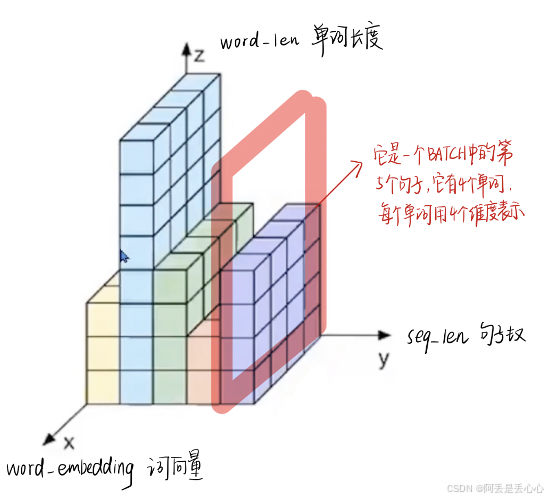
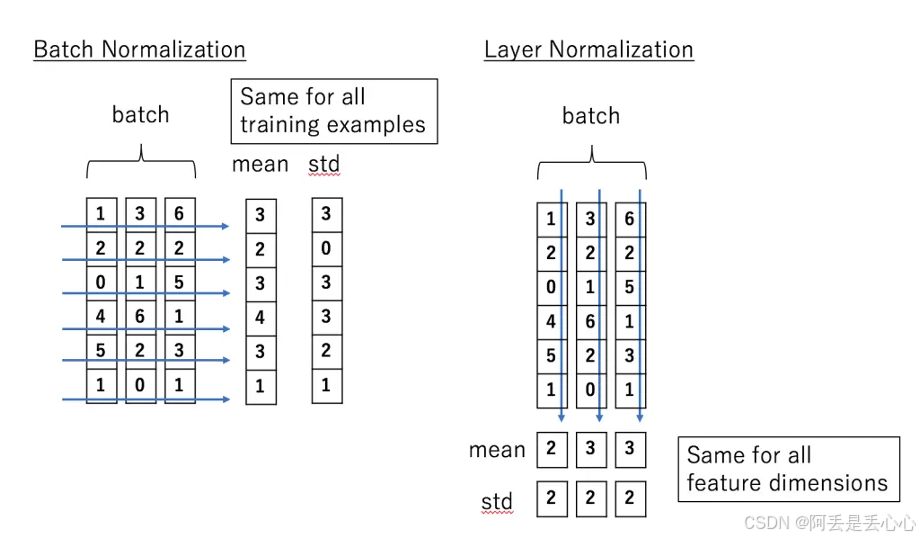 如果用三维表示的话
如果用三维表示的话
如果我们将一批文本组成一个batch,那么BN的操作方向是,对每句话的按单词进行操作。但语言文本的复杂性是很高的,任何一个词都有可能放在初始位置,且词序可能并不影响我们对句子的理解。而BN是针对每个位置进行缩放,这不符合NLP的规律。
而LN则是针对一句话进行缩放的,且LN一般用在第三维度,如[batchsize, seq_len, dims]中的dims,一般为词向量的维度,或者是RNN的输出维度等等,这一维度各个特征的量纲应该相同。因此也不会遇到上面因为特征的量纲不同而导致的缩放问题
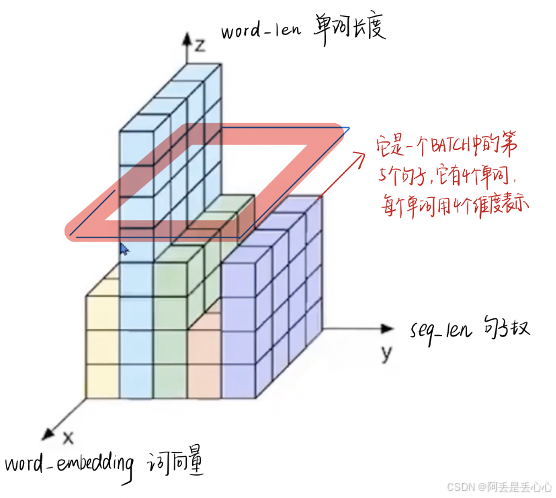
以上就是在详细了解 transform 前可以提前掌握的知识啦 下篇文章就可以迎来我们最最最最经典的神——transformer 了!