基于LSTM的文本分类3——模型训练
前言
之前已经完成了模型搭建和文本数据处理,现在做一下模型训练。
源码
# -*- coding: UTF-8 -*-
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics # 导入评估指标
import time
from utils import get_time_dif # 自定义时间计算工具
# 权重初始化函数
def init_network(model, method='xavier', exclude='embedding', seed=123):
"""初始化神经网络权重
Args:
model: 待初始化模型
method: 初始化方法,可选xavier/kaiming/normal
exclude: 不需要初始化的层名称包含的关键字
seed: 随机种子
"""
# 设置随机种子保证可重复性
torch.manual_seed(seed)
np.random.seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True # 保证CUDA卷积运算结果确定
# 遍历模型所有参数
for name, w in model.named_parameters():
if exclude not in name: # 排除指定层的参数
if 'weight' in name:
# 权重初始化策略
if method == 'xavier':
nn.init.xavier_normal_(w) # Xavier正态分布初始化
elif method == 'kaiming':
nn.init.kaiming_normal_(w) # Kaiming正态分布初始化
else:
nn.init.normal_(w) # 普通正态分布初始化
elif 'bias' in name:
nn.init.constant_(w, 0) # 偏置项初始化为0
else:
pass # 其他参数保持默认
def train(config, model, train_iter, dev_iter, test_iter, writer):
"""模型训练函数
Args:
config: 配置参数对象
model: 待训练模型
train_iter: 训练数据迭代器
dev_iter: 验证数据迭代器
test_iter: 测试数据迭代器
writer: TensorBoard写入对象
"""
start_time = time.time()
model.train() # 设置模型为训练模式
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate) # Adam优化器
# 初始化训练状态跟踪变量
total_batch = 0 # 全局batch计数器
dev_best_loss = float('inf') # 最佳验证集损失
last_improve = 0 # 上一次提升的batch数
flag = False # 早停标志
# 训练主循环
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
# 遍历训练数据
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains) # 前向传播
model.zero_grad() # 梯度清零
loss = F.cross_entropy(outputs, labels) # 计算交叉熵损失
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 每100个batch进行验证和记录
if total_batch % 100 == 0:
# 计算训练集准确率
true = labels.data.cpu()
predic = torch.max(outputs.data, 1).cpu()
train_acc = metrics.accuracy_score(true, predic)
# 在验证集评估
dev_acc, dev_loss = evaluate(config, model, dev_iter)
# 保存最佳模型
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path) # 保存模型参数
last_improve = total_batch # 更新最后提升位置
improve = '*' # 标记有提升
else:
improve = ''
# 打印训练信息
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
# 记录TensorBoard数据
writer.add_scalar("loss/train", loss.item(), total_batch)
writer.add_scalar("loss/dev", dev_loss, total_batch)
writer.add_scalar("acc/train", train_acc, total_batch)
writer.add_scalar("acc/dev", dev_acc, total_batch)
model.train() # 重置模型为训练模式(evaluate会设为eval模式)
total_batch += 1 # 更新全局batch计数
# 早停检查(超过指定batch数没有提升)
if total_batch - last_improve > config.require_improvement:
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break # 终止外层循环
writer.close() # 关闭TensorBoard写入器
test(config, model, test_iter) # 训练结束后进行最终测试
def test(config, model, test_iter):
"""模型测试函数
Args:
config: 配置参数对象
model: 已训练模型
test_iter: 测试数据迭代器
"""
# 加载最佳模型参数
model.load_state_dict(torch.load(config.save_path))
model.eval() # 设置评估模式
start_time = time.time()
# 在测试集上评估
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)
# 输出测试结果
msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score...")
print(test_report) # 分类报告(精确率、召回率、F1值)
print("Confusion Matrix...")
print(test_confusion) # 混淆矩阵
# 打印时间消耗
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
def evaluate(config, model, data_iter, test=False):
"""模型评估函数
Args:
config: 配置参数
model: 待评估模型
data_iter: 数据迭代器
test: 是否为测试模式
Returns:
测试模式:返回准确率、损失、分类报告、混淆矩阵
验证模式:返回准确率、损失
"""
model.eval() # 设置评估模式
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad(): # 禁用梯度计算
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total += loss # 累计损失
# 转换数据为numpy数组
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1).cpu().numpy()
# 收集预测结果和真实标签
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
# 计算整体准确率
acc = metrics.accuracy_score(labels_all, predict_all)
# 测试模式返回详细报告
if test:
report = metrics.classification_report(
labels_all, predict_all,
target_names=config.class_list, # 类别名称
digits=4 # 小数点精度
)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(data_iter), report, confusion
return acc, loss_total / len(data_iter) # 验证模式返回平均损失
权重初始化
def init_network(model, method='xavier', exclude='embedding', seed=123):
for name, w in model.named_parameters():
if exclude not in name:
if 'weight' in name:
if method == 'xavier':
nn.init.xavier_normal_(w)
elif method == 'kaiming':
nn.init.kaiming_normal_(w)
else:
nn.init.normal_(w)
elif 'bias' in name:
nn.init.constant_(w, 0)
不同网络层的初始化策略
| 层类型 | 推荐初始化方法 | 适用场景 |
|---|---|---|
| 全连接层 | Xavier | 普通前馈网络 |
| 卷积层 | Kaiming | 使用ReLU激活的CNN |
| Embedding层 | 保留预训练参数 | 迁移学习场景 |
在代码里将embedding层不做处理,仅处理其他层参数。
前向与反向传播
outputs = model(trains) # 前向传播
model.zero_grad() # 梯度清零
loss = F.cross_entropy(outputs, labels) # 计算交叉熵损失
loss.backward() # 反向传播
optimizer.step() # 参数更新在每一个批次中左前向传播与反向传播,需要注意在反向传播前要做梯度清零,避免收到上一批次的梯度影响。
训练监控
if total_batch % 100 == 0:
# 每多少轮输出在训练集和验证集上的效果
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)每一百个批次的训练之后要进行一次模型评估(调用评估函数),将最好的网络参数保留下来。
评估函数
def evaluate(config, model, data_iter, test=False):
loss_total = 0
predict_all = np.array([])
labels_all = np.array([])
with torch.no_grad():
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
# 结果收集
labels_all = np.append(labels_all, labels.cpu())
predic = torch.max(outputs, 1).cpu()
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total/len(data_iter), report, confusion
return acc, loss_total/len(data_iter)
评估函数里有一句代码比较别扭,是:
predic = torch.max(outputs.data, 1)[1].cpu().numpy()这一句代码做了不少事情,需要拆分做分析。
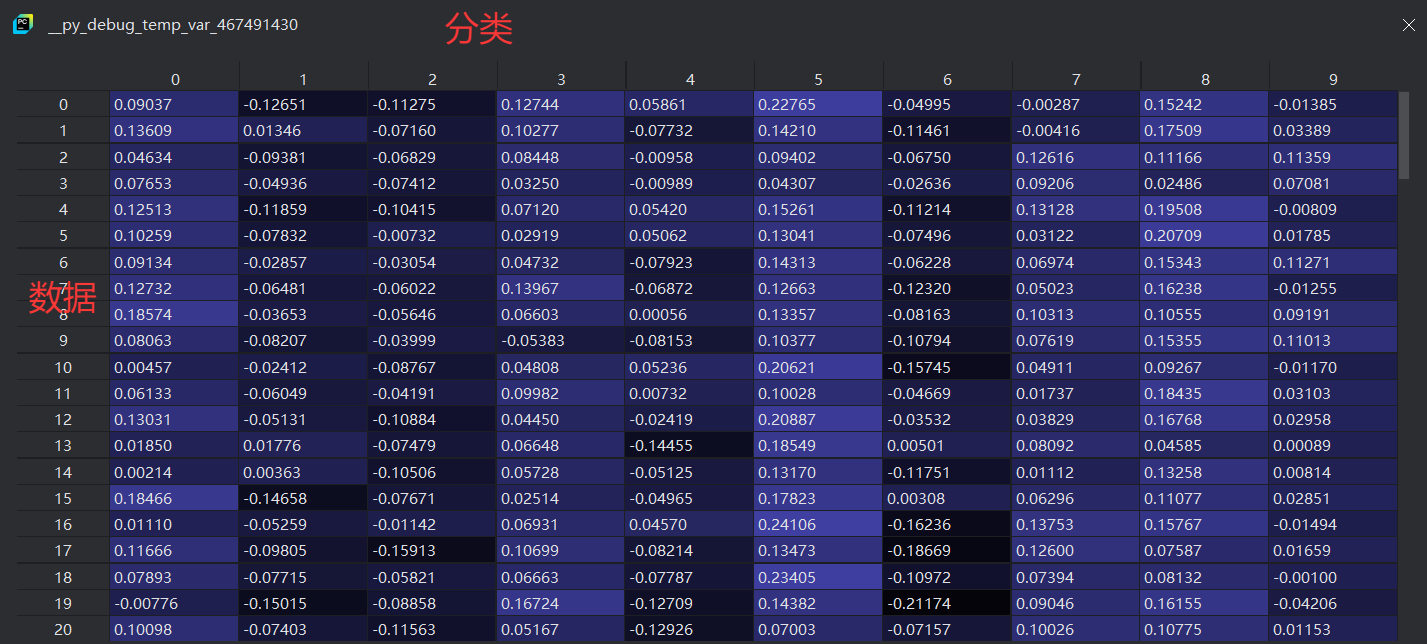
首先outputs.data是模型输出的原始张量。
![]()
从断点中看,output的张量维度是(128,10),其中128是该批次的数据量,10是某个数据在10分类任务中每个分类中的得分。
torch.max函数在这里的作用是找出每个样本预测得分最高的类别。
torch.max有两个参数,第一个是输入张量,第二个是维度。这里维度设为1,表示在每一行(即每个样本)的各个类别中找最大值。torch.max返回的是一个元组,包含两个张量:第一个是最大值,第二个是最大值的索引。
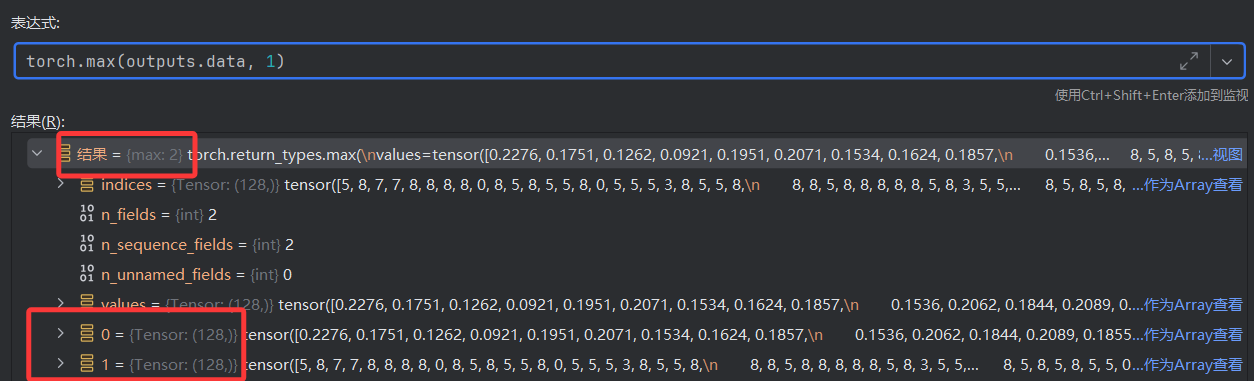
取第二个元组,里面就是每个数据的分类预测值。

使用np.array将张量转换成数组,在pycharm里面点击“作为Array查看”,可以直观看到128个数据的分类预测值。
充电-torch.max
补习下torch.max的知识
torch.max(input, dim=None, keepdim=False, out=None)
| 参数 | 类型 | 作用 |
|---|---|---|
input | Tensor | 输入张量(必选) |
dim | int (可选) | 指定计算维度,默认返回全局最大值 |
keepdim | bool (可选) | 是否保持输出维度与原张量一致,默认False |
out | tuple (可选) | 输出元组 (max_values, max_indices) |
torch.max主要支持以下玩法:
- 全局最大值:返回张量中所有元素的最大值
- 维度最大值:沿指定维度计算最大值及对应索引
求全局最大值
x = torch.tensor([[1, 5], [8, 2]])
max_val = torch.max(x) # 返回 tensor(8)
可以看到,torch.max最简单的用法就是求出一个张量里的最大元素。
求维度最大值
x = torch.tensor([[1, 5], [8, 2]])
values, indices = torch.max(x, dim=1)
# values = tensor([5, 8]), indices = tensor([1, 0])
上面的代码遵循维度计算规则,元组的第一个元素是每行最大值的集合,分别是5和8;元组的第二个元素是每行最大值在该行的序号,即0和1。
维度计算规则:
对 N维张量 的维度解释(以三维张量 (B, C, H) 为例):
dim 值 | 计算方向 | 输出形状 |
|---|---|---|
| 0 | 沿批次维度B计算 | (C, H) |
| 1 | 沿通道维度C计算 | (B, H) |
| 2 | 沿空间维度H计算 | (B, C) |
二维张量中,dim=0是按列计算,dim=1是按行计算。将dim=1,意思是求二维张量每行的最大值。