机器学习的一百个概念(12)学习率
前言
本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见[《机器学习的一百个概念》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
思维导图
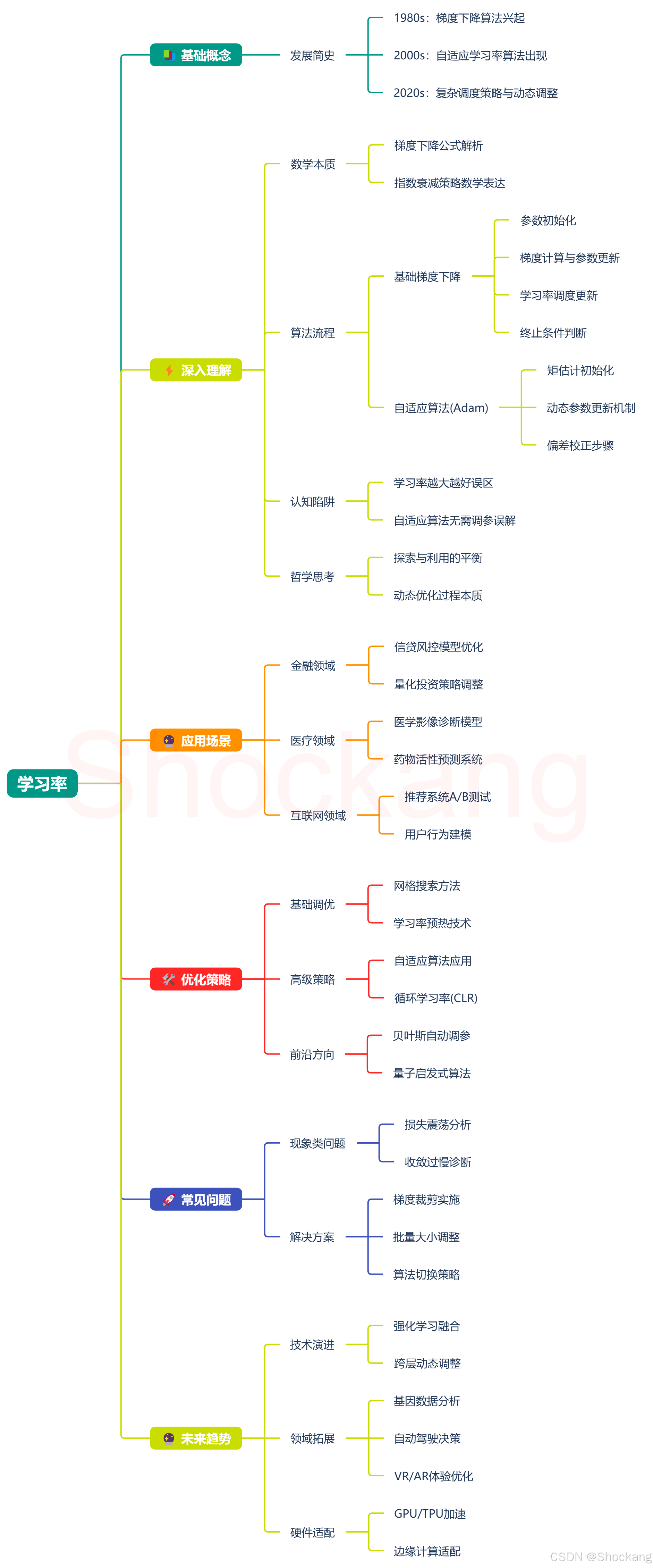
📚基础概念:学习率在机器学习中的重要性与发展历程
📌|🌟在机器学习这片广袤的领域中,学习率(Learning Rate)可是个至关重要的概念呢。它就好比我们日常走路时的步长大小呀。想象一下哦,你正在一片陌生的山林中探寻一处宝藏(这宝藏就代表着模型的最优解啦),你得依据一些线索(类似于损失函数的梯度)来决定每一步往哪个方向迈。而学习率呢,就是你每次迈出脚步的长度哦。要是步长太大,说不定一下子就跨过了宝藏所在的位置,那就遗憾地错过了呀;可要是步长太小呢,那可能要花费老长的时间才能走到宝藏附近,甚至还没走到就灰心放弃了呢。在梯度下降公式 θ = θ − α ∂ ∂ θ J ( θ ) \theta = \theta - \alpha\frac{\partial}{\partial \theta}J(\theta) θ=θ−α∂θ∂J(θ)里, α \alpha α就是学习率哟,它本质上掌控着模型在每次迭代中对梯度下降方向的响应程度呢,也就决定了模型修改参数速度的快慢,也就是参数抵达最优值过程的节奏啦。
👉核心要素清单如下哦:
❗️要点一:学习率可是优化算法每次更新模型参数时所采用的步长大小呀。这意味着它直接影响着模型参数在每次迭代中的变化幅度呢,就如同调整走路步长会改变你在山林中前进的距离一样哦。
❗️要点二:它把控着模型对梯度下降方向的响应程度呢。模型是依据损失函数的梯度来决定参数更新方向的,而学习率决定了沿着这个方向要迈出多大的步子呀,过大或过小都可能导致找不到宝藏(也就是最优解)哦。
❗️要点三:学习率的取值对于模型训练效果那可太关键啦。合适的学习率能让模型又快又稳地收敛到最优解呢,就好比选对了步长能让你高效又准确地找到宝藏呀;而不合适的学习率则可能惹出诸如训练不稳定、收敛过慢甚至没法收敛等一系列麻烦事儿呢。
🕰️发展简史:
- 1980s:
🚀在这个时期呀,随着机器学习领域渐渐兴起,梯度下降等优化算法开始被广泛研究和应用起来啦。学习率作为梯度下降算法中的一个关键参数也就应运而生咯。当时的研究重点呢,就是想着怎么利用这些算法来把损失函数最小化,而学习率在其中可是扮演着控制参数更新步长的重要角色哦。它的出现呀,为后续更复杂的模型训练打下了基础呢,让模型能够依据损失函数的梯度一步步地调整参数,朝着最优解慢慢靠近哦。 - 2000s:
⚡进入2000年代啦,随着神经网络等模型不断发展,复杂程度也越来越高,对于学习率的理解和应用也有了关键改进呢。研究人员开始意识到不同的模型结构和数据集呀,可能需要不同的学习率设置哦。于是呢,一些自适应学习率的算法就被提出来啦,比如Adagrad等哟。这些算法可厉害啦,能够根据模型训练过程中的情况自动调整学习率呢,使得模型在训练初期可以采用较大的学习率快速下降,到后期呢就能自动减小学习率,以便更精细地收敛到最优解,大大提高了模型训练的效率和效果呀。 - 2020s:
🔮到了2020年代呀,随着深度学习技术飞速发展,尤其是像大语言模型(LLMs)等超大型模型的出现,学习率的设置和优化变得更加复杂和关键咯。一方面呢,针对这些大规模模型,得更加精细地调整学习率,以适应其庞大的参数数量和复杂的训练过程哦。例如呀,采用更复杂的学习率衰减策略,如余弦退火等,来确保模型能够稳定且高效地收敛呢。另一方面呢,研究人员也在不断探索怎么根据模型的不同阶段、不同层甚至不同参数来动态设置学习率,好进一步提升模型的性能呀,让学习率的应用更加灵活和精准呢。
💬理解了这些基础的知识呀,就能帮助我们更深入地去探究学习率在数学原理、算法流程以及底层机制等方面的内容啦,这也为后面【深入理解】章节奠定了扎实的基础哦。
▶️接下来呀,我们就要进入【深入理解】章节啦,进一步去剖析学习率在机器学习中的更多奥秘哦。
⚡深入理解:学习率的数学本质、算法流程及认知陷阱
经过前面对于学习率基础概念的了解,让我们更深入地去探究它的内在原理吧 → 🚀
📐数学本质
在机器学习领域呀,学习率有着清晰明确的数学本质体现呢。我们先回顾一下在梯度下降算法中的核心公式:
θ n e w = θ o l d − η ⋅ a b l a J ( θ ) \theta_{new} = \theta_{old} - \eta \cdot \ abla J(\theta) θnew=θold−η⋅ ablaJ(θ)(这里面呀, θ \theta θ表示模型参数, η \eta η就是学习率, a b l a J ( θ ) \ abla J(\theta) ablaJ(θ)是损失函数 J ( θ ) J(\theta) J(θ)关于参数 θ \theta θ的梯度哦)。
这个公式简洁又有力地展示了学习率的数学作用呢。从数学角度来看呀,学习率 η \eta η就是一个用来缩放梯度向量的标量哦。当我们算出损失函数关于模型参数的梯度后,学习率就决定了我们依据这个梯度去更新模型参数时的步长大小啦。比如说呀,如果学习率较大,那么在梯度方向上参数更新的幅度就会比较大;反之呢,如果学习率较小,参数更新的幅度也就相应较小咯。
再看看学习率调度中的指数衰减策略公式: η t = η 0 ⋅ e − k t \eta_t = \eta_0 \cdot e^{-kt} ηt=η0⋅e−kt(这里面呀, η t \eta_t ηt是在时刻 t t t的学习率, η 0 \eta_0 η0是初始学习率, k k k是衰减系数哦)。这里通过指数函数的形式呀,实现了随着训练时间(或者迭代次数等可量化的训练进程指标,这里用时刻 t t t表示)的推移,学习率逐渐变小的效果呢。从数学本质上讲呀,它是基于指数函数的特性来对学习率进行动态调整,以适应模型训练不同阶段的需求哦。
📈算法流程图
接下来我们以简单梯度下降算法结合学习率更新参数为例,来讲讲它的算法流程图哦:
步骤一:初始化
🔄首先要初始化模型参数 θ \theta θ,设置初始学习率 η \eta η,并且设定迭代次数 m a x _ i t e r max\_iter max_iter哦。这一步呢,是为整个训练过程做好准备呀,确定了模型参数的初始状态以及学习率的初始值,同时也明确了训练要进行的迭代次数上限呢。
步骤二:迭代计算梯度与更新参数
🔄然后就进入循环啦,循环条件是迭代次数 i i i小于等于 m a x _ i t e r max\_iter max_iter哦。在每次迭代中呢:
- 首先要计算损失函数 J ( θ ) J(\theta) J(θ)关于 θ \theta θ的梯度 a b l a J ( θ ) \ abla J(\theta) ablaJ(θ)哦。这一步呀,是通过对损失函数求导等数学运算,得到当前模型参数下损失函数变化最陡峭的方向,也就是梯度方向呢。
- 接着根据公式 θ = θ − η ⋅ a b l a J ( θ ) \theta = \theta - \eta \cdot \ abla J(\theta) θ=θ−η⋅ abla