二、TorchRec中的分片
TorchRec中的分片
文章目录
- TorchRec中的分片
- 前言
- 一、Planner
- 二、EmbeddingTable 的分片
- TorchRec 中所有可用的分片类型列表
- 三、使用 TorchRec 分片模块进行分布式训练
- TorchRec 在三个主要阶段处理此问题
- 四、DistributedModelParallel(分布式模型并行)
- 总结
前言
- 我们来了解TorchRec架构中是如何分片的
一、Planner
-
TorchRec planner 帮助确定模型的最佳分片配置。
-
它评估嵌入表分片的多种可能性,并优化性能。
-
planner 执行以下操作:
- 评估硬件的内存约束。
- 根据内存获取(例如嵌入查找)估算计算需求。
- 解决特定于数据的因素。
- 考虑其他硬件细节,例如带宽,以生成最佳分片计划。
二、EmbeddingTable 的分片
- TorchRec sharder 为各种用例提供了多种分片策略,我们概述了一些分片策略及其工作原理,以及它们的优点和局限性。通常,我们建议使用 TorchRec planner 为您生成分片计划,因为它将为模型中的每个嵌入表找到最佳分片策略。
- 每个分片策略都确定如何进行表拆分、是否应拆分表以及如何拆分、是否保留某些表的一个或几个副本等等。分片结果中的每个表片段,无论是一个嵌入表还是其中的一部分,都称为分片。
- 可视化 TorchRec 中提供的不同分片方案下表分片的放置
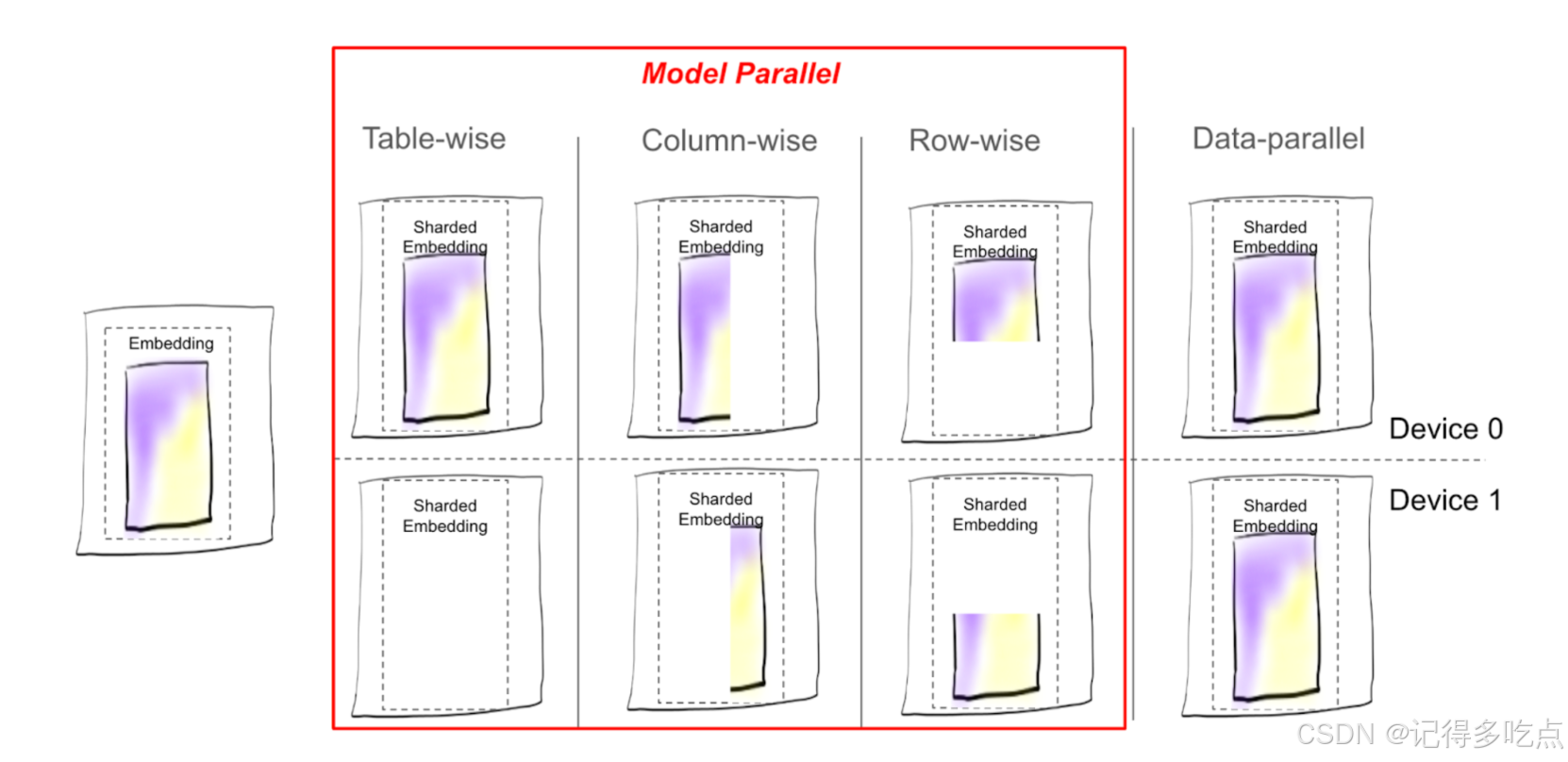
TorchRec 中所有可用的分片类型列表
- 表式 (TW):顾名思义,嵌入表作为一个整体保留并放置在一个 rank 上。
- 列式 (CW):表沿 emb_dim 维度拆分,例如,emb_dim=256 拆分为 4 个分片:[64, 64, 64, 64]。
- 行式 (RW):表沿 hash_size 维度拆分,通常在所有 rank 之间均匀拆分。
- 表式-行式 (TWRW):表放置在一个主机上,在该主机上的 rank 之间进行行式拆分。
- 网格分片 (GS):表是 CW 分片的,每个 CW 分片都以 TWRW 方式放置在主机上。
- 数据并行 (DP):每个 rank 保留表的副本。
分片后,模块将转换为它们自身的分片版本,在 TorchRec 中称为 ShardedEmbeddingCollection 和 ShardedEmbeddingBagCollection。这些模块处理输入数据的通信、嵌入查找和梯度。
三、使用 TorchRec 分片模块进行分布式训练
- 有许多可用的分片策略,我们如何确定使用哪一个?
- 每种分片方案都有相关的成本,这与模型大小和 GPU 数量相结合,决定了哪种分片策略最适合模型。
- 在没有分片的情况下,每个 GPU 保留嵌入表的副本 (DP),主要成本是计算,其中每个 GPU 在前向传递中查找其内存中的嵌入向量,并在后向传递中更新梯度。
- 使用分片时,会增加通信成本:
- 每个 GPU 都需要向其他 GPU 请求嵌入向量查找,并通信计算出的梯度。这通常被称为 all2all 通信。
- 在 TorchRec 中,对于给定 GPU 上的输入数据,我们确定数据每个部分的嵌入分片所在的位置,并将其发送到目标 GPU。
- 然后,目标 GPU 将嵌入向量返回给原始 GPU。在后向传递中,梯度被发送回目标 GPU,并且分片会通过优化器进行相应的更新。
- 如上所述,分片需要我们通信输入数据和嵌入查找。
TorchRec 在三个主要阶段处理此问题
我们将此称为分片嵌入模块前向传递,该传递用于 TorchRec 模型的训练和推理
-
特征 All to All / 输入分布 (input_dist)
- 将输入数据(以 KeyedJaggedTensor 的形式)通信到包含相关嵌入表分片的适当设备
-
嵌入查找
- 使用特征 all to all 交换后形成的新输入数据查找嵌入
-
嵌入 All to All/输出分布 (output_dist)
- 将嵌入查找数据通信回请求它的适当设备(根据设备接收到的输入数据)
-
后向传递执行相同的操作,但顺序相反。
四、DistributedModelParallel(分布式模型并行)
- 以上所有内容最终汇集成 TorchRec 用于分片和集成计划的主要入口点。
- 在高层次上,DistributedModelParallel 执行以下操作:
- 通过设置进程组和分配设备类型来初始化环境。
- 如果没有提供 sharder,则使用默认的 sharder,默认 sharder 包括 EmbeddingBagCollectionSharder。
- 接收提供的分片计划,如果未提供,则生成一个。
- 创建模块的分片版本,并用它们替换原始模块,例如,将 EmbeddingCollection 转换为 ShardedEmbeddingCollection。
- 默认情况下,使用 DistributedDataParallel 包装 DistributedModelParallel,使模块既是模型并行又是数据并行。
总结
- 对TorchRec中的分块策略进行了解。