希哈表的学习
#include <stdio.h>
#include <stdlib.h>
#include "uthash.h"
typedef struct {
int id; // 学号,作为key
char name[20]; // 姓名,作为value
UT_hash_handle hh; // 必须有这个字段
} Student;
Student* students = NULL; // 哈希表的头指针(初始为NULL)
int main() {
Student* s1 = (Student*)malloc(sizeof(Student));
Student* s2 = (Student*)malloc(sizeof(Student));
s1->id = 1001;
s2->id = 1002;
strcpy(s1->name, "张三");
strcpy(s2->name, "李四");
// 把s1加入哈希表,按id做key
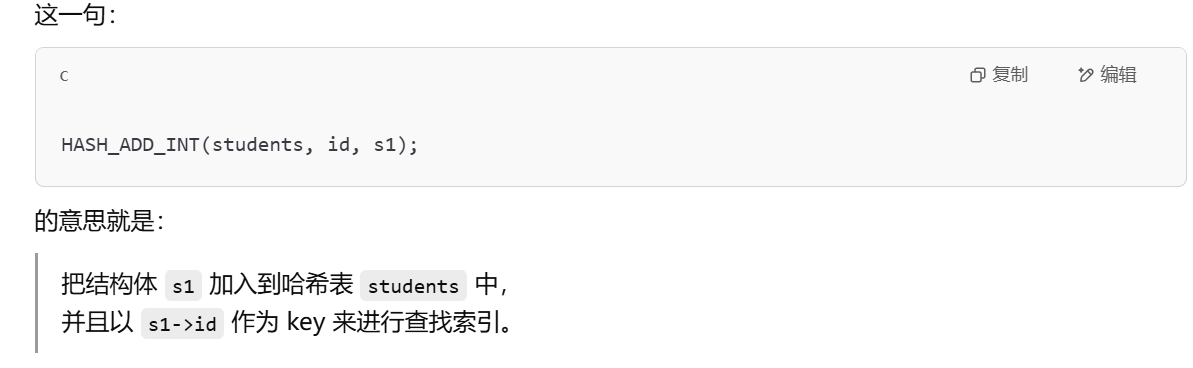
HASH_ADD_INT(students, id, s2); //HASH_ADD_INT(哈希表名, 键字段名, 条目指针);
HASH_ADD_INT(students, id, s1);
// 查找学号的学生
Student* find = NULL;
int search_id = 1001;
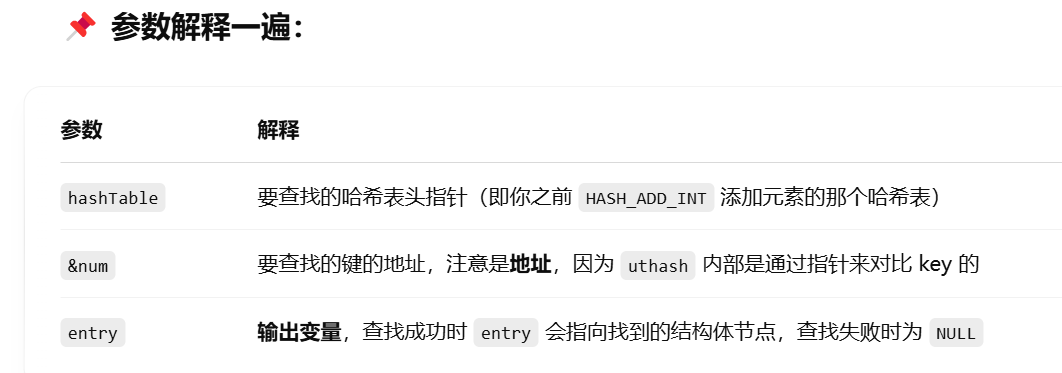
HASH_FIND_INT(students, &search_id, find); //HASH_FIND_INT(哈希表名, 键字段值的地址, 找到的条目指针);
if (find) {
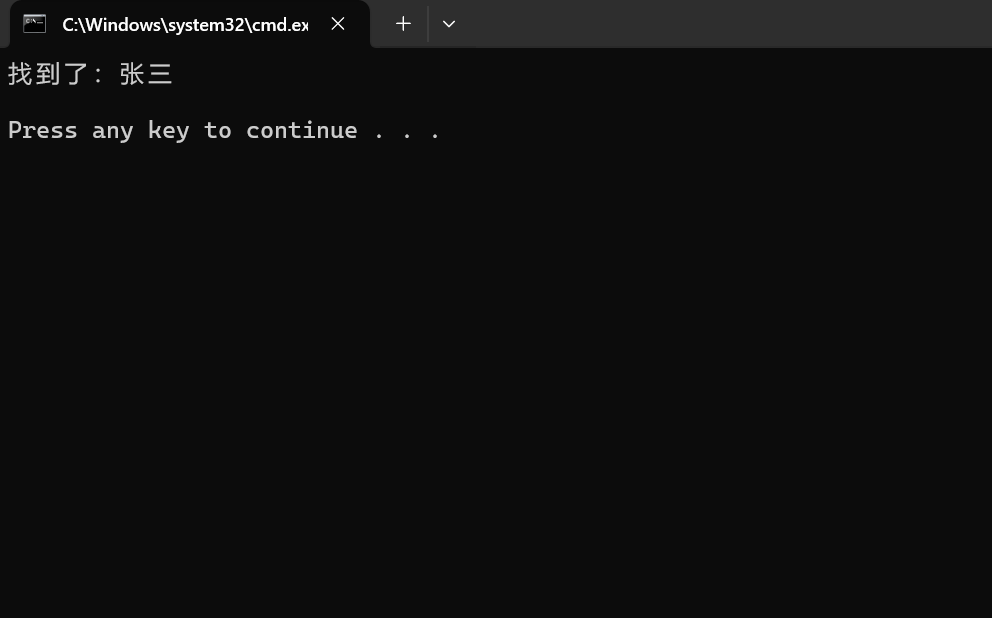
printf("找到了:%s\n", find->name);
}
else {
printf("没找到\n");
}
// 释放内存
HASH_DEL(students, s1); //HASH_DEL() 的作用就是:从哈希表中删除一个指定的结构体(条目)。HASH_DEL(哈希表名, 条目指针);
free(s1);
return 0;
}
HASH_ADD_INT(哈希表头指针, key字段名, 结构体指针);

HASH_FIND_INT(哈希表名, key指针, 输出结果指针);

HASH_DEL(哈希表头指针, 要删除的结构体指针);


HASH_ITER(hh, head, elt, tmp)


例题
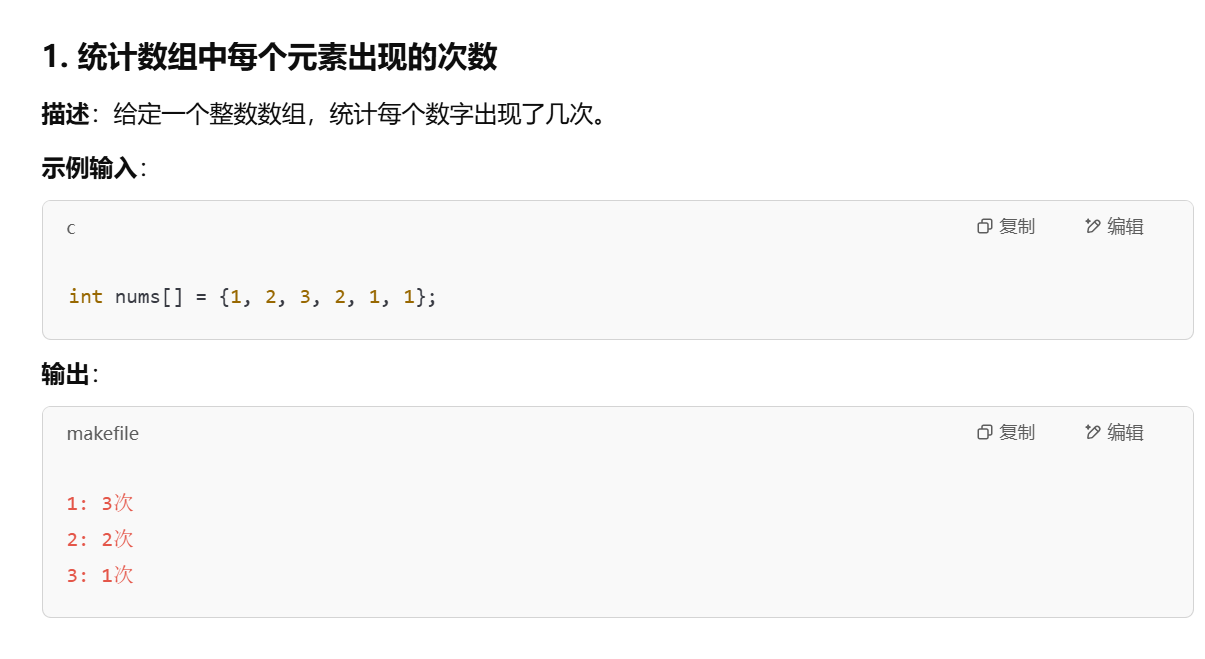
统计数组中每个元素出现的次数
#include <stdio.h>
#include "uthash.h"
#include <stdlib.h>
typedef struct
{
int Key; //数字
int count; //出现次数
UT_hash_handle hh; //哈希句柄
}HashEntry;
int main()
{
int nums[] = {1, 2, 3, 2, 1, 1};
int n = sizeof(nums) / sizeof(nums[0]);
HashEntry*hashTable = NULL;
for (int i = 0; i < n; i++)
{
int num = nums[i];
HashEntry*entry;
HASH_FIND_INT(hashTable, &num, entry);
if(entry)
{
entry->count += 1;
}
else
{
entry = (HashEntry*)malloc(sizeof(HashEntry));
entry->Key = num;
entry->count = 1;
HASH_ADD_INT(hashTable, Key, entry);
}
}
HashEntry*e, *tmp;
HASH_ITER(hh, hashTable, e, tmp)
{
printf("%d: %d次\n", e->Key, e->count);
}
HASH_ITER(hh, hashTable, e, tmp)
{
HASH_DEL(hashTable, e);
free(e);
}
} 
数组中第一个只出现一次的元素

#include <stdio.h>
#include "uthash.h"
#include <stdlib.h>
// 定义哈希表结构
typedef struct {
int key; // 数字
int count; // 出现次数
UT_hash_handle hh; // 哈希句柄
} HashEntry;
int findFirstUnique(int* nums, int n) {
HashEntry *hashTable = NULL;
// 第一次遍历:统计每个数字出现次数
for (int i = 0; i < n; i++) {
int num = nums[i];
HashEntry *entry;
HASH_FIND_INT(hashTable, &num, entry);
if (entry) {
entry->count += 1;
} else {
entry = (HashEntry*)malloc(sizeof(HashEntry));
entry->key = num;
entry->count = 1;
HASH_ADD_INT(hashTable, key, entry);
}
}
// 第二次遍历:找出第一个只出现一次的数字
int result = -1;
for (int i = 0; i < n; i++) {
HashEntry *entry;
HASH_FIND_INT(hashTable, &nums[i], entry);
if (entry && entry->count == 1) {
result = nums[i];
break;
}
}
// 清理哈希表
HashEntry *e, *tmp;
HASH_ITER(hh, hashTable, e, tmp) {
HASH_DEL(hashTable, e);
free(e);
}
return result;
}
int main() {
int nums[] = {4, 5, 1, 2, 1, 2, 0};
int n = sizeof(nums) / sizeof(nums[0]);
int result = findFirstUnique(nums, n);
if (result != -1) {
printf("第一个只出现一次的元素是:%d\n", result);
} else {
printf("没有只出现一次的元素\n");
}
return 0;
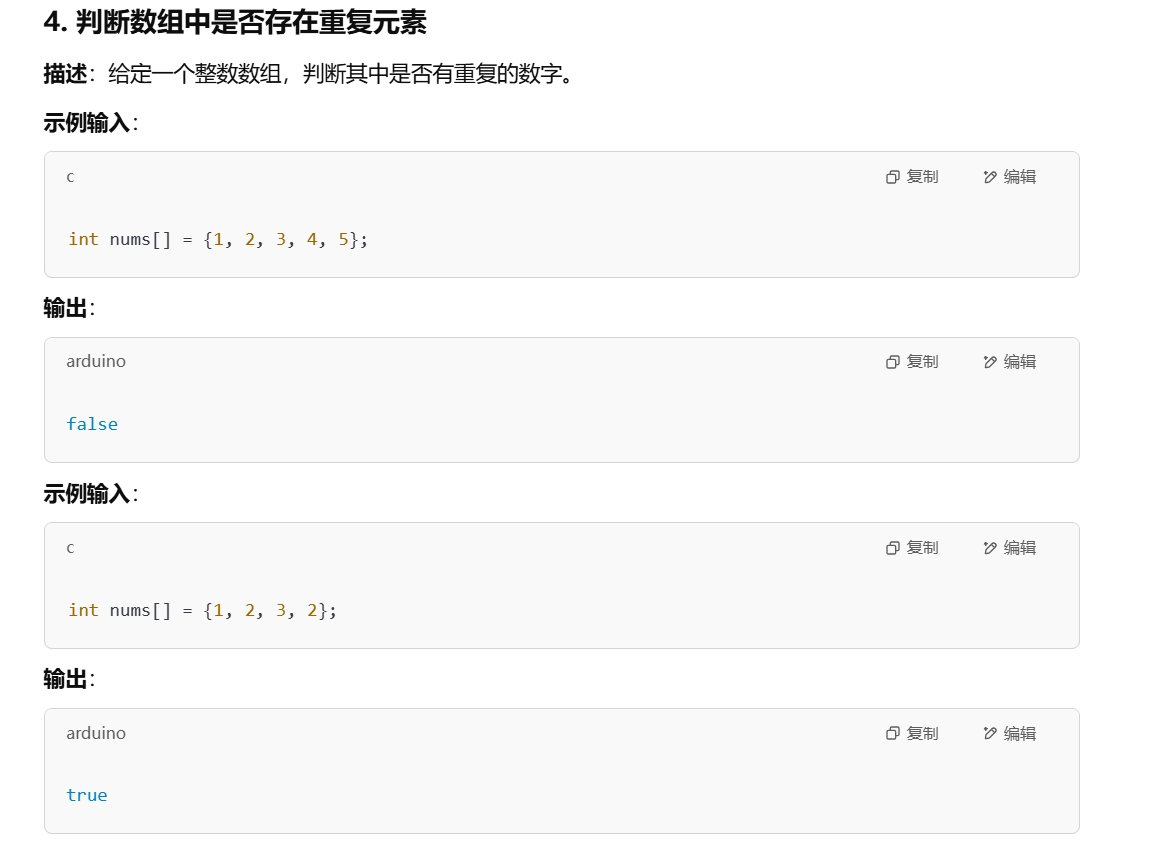
}判断数组中是否存在重复元素

#include <stdio.h>
#include <stdlib.h>
#include "uthash.h"
// 定义哈希结构
typedef struct {
int key; // 数组元素值
UT_hash_handle hh; // 哈希句柄
} HashEntry;
int containsDuplicate(int* nums, int numsSize) {
HashEntry *hashTable = NULL;
for (int i = 0; i < numsSize; i++) {
int num = nums[i];
HashEntry *entry;
HASH_FIND_INT(hashTable, &num, entry);
if (entry) {
// 找到了,说明重复
// 清理哈希表
HashEntry *e, *tmp;
HASH_ITER(hh, hashTable, e, tmp) {
HASH_DEL(hashTable, e);
free(e);
}
return 1; // true
} else {
// 没找到,加入哈希表
entry = (HashEntry*)malloc(sizeof(HashEntry));
entry->key = num;
HASH_ADD_INT(hashTable, key, entry);
}
}
// 清理哈希表
HashEntry *e, *tmp;
HASH_ITER(hh, hashTable, e, tmp) {
HASH_DEL(hashTable, e);
free(e);
}
return 0; // false
}
int main() {
int nums1[] = {1, 2, 3, 4}; // 无重复
int nums2[] = {1, 2, 3, 2}; // 有重复
printf("nums1 是否有重复:%s\n", containsDuplicate(nums1, 4) ? "是" : "否");
printf("nums2 是否有重复:%s\n", containsDuplicate(nums2, 4) ? "是" : "否");
return 0;
}
#include <stdio.h>
#include <stdlib.h>
#include "uthash.h"
// 定义哈希结构
typedef struct {
int key; // 数组元素值
UT_hash_handle hh; // 哈希句柄
} HashEntry;
int containsDuplicate(int* nums, int numsSize) {
HashEntry *hashTable = NULL;
for (int i = 0; i < numsSize; i++) {
int num = nums[i];
HashEntry *entry;
HASH_FIND_INT(hashTable, &num, entry);
if (entry) {
// 找到了,说明重复
// 清理哈希表
HashEntry *e, *tmp;
HASH_ITER(hh, hashTable, e, tmp) {
HASH_DEL(hashTable, e);
free(e);
}
return 1; // true
} else {
// 没找到,加入哈希表
entry = (HashEntry*)malloc(sizeof(HashEntry));
entry->key = num;
HASH_ADD_INT(hashTable, key, entry);
}
}
// 清理哈希表
HashEntry *e, *tmp;
HASH_ITER(hh, hashTable, e, tmp) {
HASH_DEL(hashTable, e);
free(e);
}
return 0; // false
}
int main() {
int nums1[] = {1, 2, 3, 4}; // 无重复
int nums2[] = {1, 2, 3, 2}; // 有重复
printf("nums1 是否有重复:%s\n", containsDuplicate(nums1, 4) ? "是" : "否");
printf("nums2 是否有重复:%s\n", containsDuplicate(nums2, 4) ? "是" : "否");
return 0;
}