猫咪如厕检测与分类识别系统系列【二】多图上传及猫咪分类特征提取更新
前情提要
家里养了三只猫咪,其中一只布偶猫经常出入厕所。但因为平时忙于学业,没法时刻关注牠的行为。我知道猫咪的如厕频率和时长与健康状况密切相关,频繁如厕可能是泌尿问题,停留过久也可能是便秘或不适。为了更科学地了解牠的如厕习惯,我计划搭建一个基于视频监控和AI识别的系统,自动识别猫咪进出厕所的行为,记录如厕时间和停留时长,并区分不同猫咪。这样即使我不在家,也能掌握猫咪的健康状态,更安心地照顾它们。
已完成工作:
✅猫咪如厕检测与分类识别系统系列【一】 功能需求分析及猫咪分类特征提取
✅ 计划工作:
· 猫咪管理(添加猫照片及名字)【进行】
· 区域选择(绘制检测区域)【待更新】
· 检测记录【待更新】 【待更新】
❓ 目前存在问题:
1.每只猫只能录入一张图片效率较低,同时对于多猫家庭来说更是任务艰巨。
2.之前的匹配逻辑准确率较低,能否根据多张图片来进行特征点匹配?
🐱 匹配算法需求更新:
✅ 实现:
-
每只猫可以上传多张脸部图片
-
批量上传图片(一次性上传多张图)
-
系统自动提取所有图片的特征,并将这些特征汇总为一个猫的特征集合
-
识别时与集合中的多个向量比对,提升准确率(可用平均、最大相似度等策略)
✅ 新设计方案:
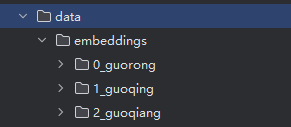
🧠 数据结构调整(database.py):
- 每只猫的多个向量单独保存,例如:
embeddings/
├── 0_Mimi/
│ ├── 1.npy
│ ├── 2.npy
│ └── ...
├── 1_Kaka/
│ ├── 1.npy
│ └── ...
✅ 1. 修改 database.py 支持多图上传:
class CatDatabase:
def __init__(self, db_path='data/embeddings'):
self.db_path = db_path
os.makedirs(db_path, exist_ok=True)
def add_cat_images(self, name, embeddings):
# 创建文件夹
cat_id = self._next_id(name)
cat_folder = os.path.join(self.db_path, cat_id)
os.makedirs(cat_folder, exist_ok=True)
for idx, emb in enumerate(embeddings):
np.save(os.path.join(cat_folder, f"{idx}.npy"), emb)
def _next_id(self, name):
# 用名称做 ID
existing = [f for f in os.listdir(self.db_path) if os.path.isdir(os.path.join(self.db_path, f))]
base = f"{len(existing)}_{name}"
return base
def get_all(self):
embeddings = []
names = []
for folder in os.listdir(self.db_path):
full_path = os.path.join(self.db_path, folder)
if os.path.isdir(full_path):
for file in os.listdir(full_path):
if file.endswith('.npy'):
vec = np.load(os.path.join(full_path, file))
embeddings.append(vec)
names.append(folder.split("_", 1)[1])
return embeddings, names
✅ 2. 修改 app.py 支持批量上传
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
name = request.form['name']
files = request.files.getlist('images')
if name and files:
embeddings = []
for file in files:
img_path = os.path.join(app.config['UPLOAD_FOLDER'], file.filename)
file.save(img_path)
try:
vec = embedder.extract(img_path)
embeddings.append(vec)
except:
print(f"跳过无效图像: {file.filename}")
if embeddings:
db.add_cat_images(name, embeddings)
return redirect(url_for('index'))
_, names = db.get_all()
return render_template('index.html', cats=set(names))
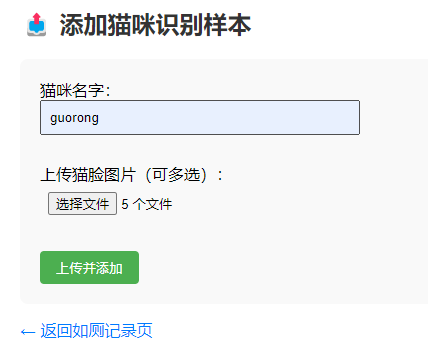
✅ 3. 修改前端支持批量上传
<form method="POST" enctype="multipart/form-data">
<input type="text" name="name" placeholder="猫咪名字" required><br><br>
<input type="file" name="images" multiple accept="image/*" required><br><br>
<input type="submit" value="批量添加猫咪图像">
</form>
✅ 工作流程示意:
[上传多张图 + 猫名] → [逐张提取特征] → [保存特征集合]
识别时 → 与所有特征比对 → 选择相似度最高的那只猫
🧠 识别逻辑更新(matcher.py):
用最近邻(最大相似度匹配)来做猫咪识别,识别时只要有一张特征相似度高于阈值就判定为该猫,这样在有多个角度或不同光照条件下也能更稳定。
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
class CatMatcher:
def __init__(self, db):
self.db = db
def match(self, query_vec, threshold=0.7):
embeddings, names = self.db.get_all()
if not embeddings:
return "Unknown"
sims = cosine_similarity([query_vec], embeddings)[0]
best_idx = np.argmax(sims)
best_score = sims[best_idx]
if best_score > threshold:
return names[best_idx]
return "Unknown"
✅ 项目状态总结:
| 模块 | 进度 | 功能描述 |
|---|---|---|
| 猫咪录入系统 | ✅ 完成 | 多张图片批量上传,提特征保存,Web UI 展示 |
| 猫咪识别系统 | ✅ 完成 | 最近邻匹配策略,返回匹配猫的名字 |
| 摄像头检测 | 🔜 待做 | YOLOv11 检测猫是否进入区域,裁剪图并识别 |
| 事件记录系统 | 🔜 待做 | 进入/离开时间记录、保存图像、生成如厕时长 |
| Web 展示记录 | 🔜 待做 | Flask 页面展示记录,支持导出 / 查询 |