Adam为什么能加速收敛和自适应学习率?
在深度学习和优化算法中,一阶动量矩阵和二阶动量矩阵是自适应优化方法(如Adam)的核心概念。以下是它们的定义、作用及数学形式的详细说明:
一、基本定义与数学形式
1. 一阶动量矩阵
- 定义:一阶动量(First-order Momentum)是历史梯度的加权平均,用于捕捉梯度的方向趋势,加速收敛并减少震荡。
数学形式: vt=β1⋅v(t−1)+(1−β1)⋅∇J(θt) 其中:
- vt 为当前时刻的一阶动量;
- ∇J(θt) 是当前梯度;
- β1 是衰减率(通常取0.9)
物理意义:类似于物理学中的动量效应,通过累积历史梯度方向,增强参数更新的方向性
2. 二阶动量矩阵
- 定义:二阶动量(Second-order Momentum)是梯度平方的加权平均,用于自适应调整每个参数的学习率,解决不同参数梯度尺度差异的问题。
- 数学形式: st=β2⋅s(t−1)+(1−β2)⋅(∇J(θt))^2 其中:
- st为当前时刻的二阶动量;
- β2 是衰减率(通常取0.999)
- 物理意义:反映梯度的波动性,对频繁变化的梯度进行抑制,稳定训练过程
二、在优化算法中的应用
1. Adam优化器
Adam结合了一阶和二阶动量,参数更新公式为:
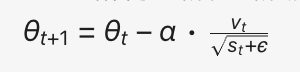
- 特点:
- vt 修正梯度方向,加速收敛;
- st自适应缩放学习率,避免梯度爆炸或消失;
- ϵ 是防止分母为零的小常数(如1e-8)
三、为什么能自适应学习率
自适应调整的直观理解
-
梯度波动大(stst 大): 若某个参数的梯度历史波动剧烈(即 stst 较大),则 stst 较大,导致实际学习率 α/stα/st 自动减小。这抑制了该参数的更新幅度,避免因梯度不稳定而震荡。
-
梯度波动小(stst 小): 若某个参数的梯度长期稳定(即 stst 较小),则 stst 较小,实际学习率 α/stα/st 相对增大。这加速了稳定参数的收敛。
物理意义
二阶动量本质上是梯度幅度的指数移动平均,通过以下方式实现自适应:
- 抑制频繁变化的参数:对梯度变化剧烈的参数,降低其学习率以稳定训练。
- 放大稳定参数的更新:对梯度平缓的参数,保持较高的学习率以加速收敛。
3. 具体例子说明
假设神经网络有两个参数 θ1 和 θ2:
-
参数 θ1:梯度历史为 [0.1,0.2,0.15],波动较小。 二阶动量 stst 较小(如0.03),实际学习率接近原始 α,更新幅度较大。
-
参数 θ2:梯度历史为 [1.0,−0.8,0.9],波动剧烈。 二阶动量 stst 较大(如0.8),实际学习率变为 0.89α,更新幅度被抑制。