SeeGround: See and Ground for Zero-Shot Open-Vocabulary 3D Visual Grounding
CVPR 2025
核心问题与动机
- 问题背景:3D视觉定位(3DVG)要求根据文本描述在3D场景中定位目标物体,是增强现实、机器人导航等应用的关键技术。传统方法依赖标注的3D数据集和预定义类别,限制了其在开放场景中的扩展性。
- 现有局限:
- 数据获取成本高:大规模3D标注数据难以获取。
- 视觉信息缺失:纯文本方法忽略颜色、纹理等关键视觉特征。
- 视角固定性:静态视角可能导致遮挡或信息丢失。

提出了一种创新的零样本 3DVG 框架,将3D场景表示为查询对齐的渲染图像和空间文本描述的混合,从而弥合 3D 数据和 2D-VLM 输入格式之间的差距,解决传统方法对标注数据依赖性强、泛化能力不足的问题。
网络框架
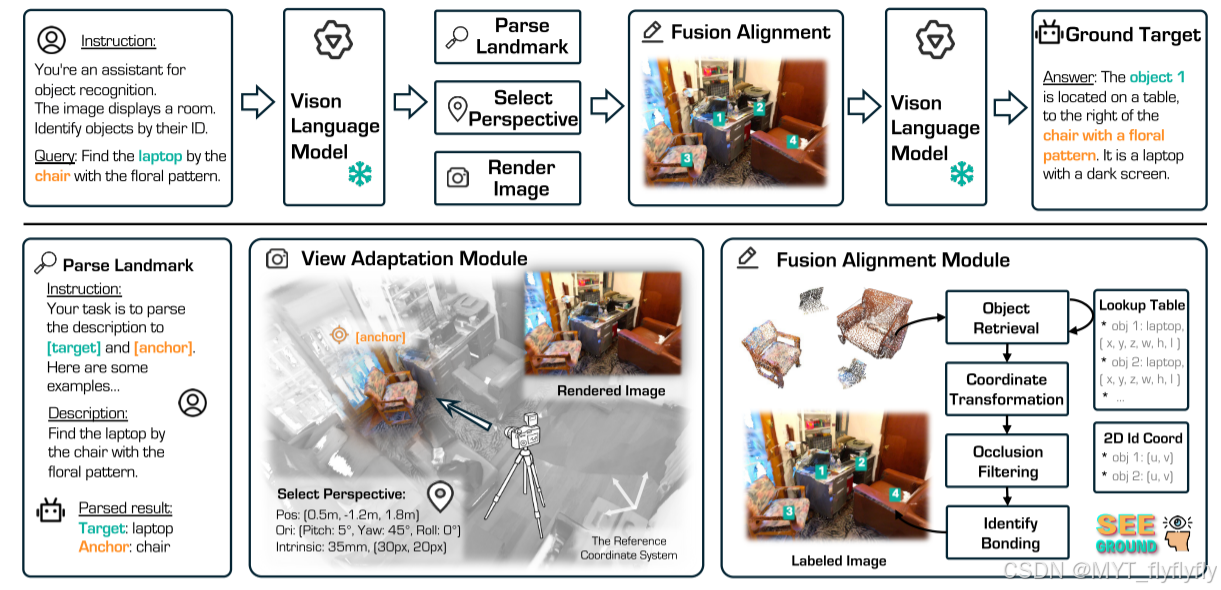
1. 用户输入查询(Query)
用户提供一个自然语言描述,例如:
"Find the laptop by the chair with the floral pattern."
(找到花卉图案椅子旁边的笔记本电脑。)
这个描述包含两个关键信息:
- 目标对象(Target): laptop(笔记本电脑)
- 参考对象(Anchor): chair(带花卉图案的椅子)
2. 解析查询信息(Parse Landmark)
系统使用 视觉-语言模型(Vision Language Model, VLM) 来解析这句话,提取出:
- 目标(Target): laptop
- 参考对象(Anchor): chair(带花卉图案的)
这样系统就知道 要找的物体 和 用来定位的参照物。
3. 视角调整(View Adaptation Module)
为了更好地识别目标,系统需要选择一个合适的视角。步骤如下:
- 计算最佳视角:
- 选择一个可以清晰看到参考对象(chair)和目标对象(laptop)的摄像机位置。
- 计算相机的 位置(Position) 和 方向(Orientation),确保目标和参考对象在视野中。
- 渲染图像:
- 生成一个新的2D图像,该图像能正确展示查询中提到的物体。
📌 举个例子:如果相机最初的视角看不到 chair,那么系统会调整视角,使 chair 和 laptop 同时可见。
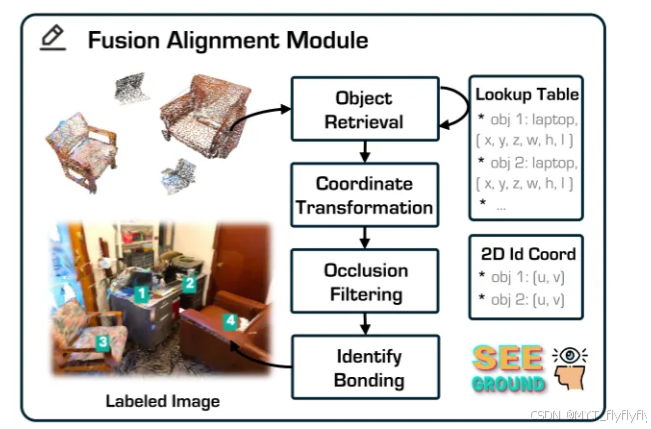
4. 融合对齐(Fusion Alignment Module)
这一阶段的目的是 在2D图像中找到目标对象,并映射到3D场景。具体步骤如下:
- 检索对象(Object Retrieval):
- 通过 对象查找表(Object Lookup Table, OLT) 获取所有候选物体的3D边界框信息,比如:
- Object 1: laptop → (x, y, z, w, h, l)
- Object 2: chair → (x, y, z, w, h, l)
- 这些信息包含 目标对象在3D场景中的坐标。
- 通过 对象查找表(Object Lookup Table, OLT) 获取所有候选物体的3D边界框信息,比如:
- 坐标转换(Coordinate Transformation):
- 将3D物体投影到2D图像上,这样就能在2D图像上标出它们的位置。
- 遮挡过滤(Occlusion Filtering):
- 排除被遮挡的物体,确保目标对象在视野范围内。
- 标记目标(Identify Bonding):
- 通过 2D视觉-语言模型(2D-VLM) 处理图像,给目标对象添加编号,生成带编号的标签图像。
5. 确定最终目标(Ground Target)
这一阶段的目标是 最终确认目标对象,并输出其3D坐标:
-
视觉-语言模型(VLM)读取标记后的2D图像,并结合查询信息,最终识别出:
"The object 1 is located on a table, to the right of the chair with a floral pattern. It is a laptop with a dark screen."
(目标1在一张桌子上,位于带花卉图案的椅子右侧,它是一台屏幕为黑色的笔记本电脑。)
-
最终,我们可以从 对象查找表(OLT) 提取该对象的 3D坐标,完成精准的3D目标定位。
主函数:
- 任务:给定3D场景 S 和查询文本 Q,输出目标物体的3D边界框。
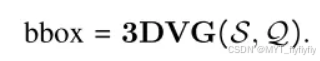
整体流程
![]()
核心模块
1. 多模态3D表示**(2D渲染+3D空间文本描述** )
由于 2D-VLM 无法直接处理 3D 数据,SeeGround 提出了一种混合表示方法:
基于文本的3D空间描述:
通过开放词汇的3D检测框架生成对象的三维边界框、语义标签
![]()
构建对象查找表(OLT)。然后将这些信息转换为与2D-VLM输入兼容的文本格式,从而可以对场景进行准确的空间和语义描述。
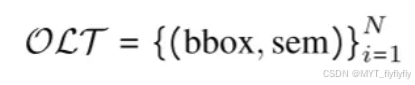
OLT的构建:
![]()
混合3D场景表示(原因:文本无法传达关键的视觉细节→结合图像和文本描述):
公式:

代码:
将3D物体的几何信息(位置、尺寸)转换为文本T:
![]()
2D渲染图像I:
![]()
其中I是 2D 渲染图像,T是基于文本的空间描述,两者结合帮助 2D-VLM 理解场景的视觉细节和 3D 空间信息
渲染图像:动态选择与查询对齐的视角渲染2D图像,捕捉目标物体的细节和上下文。
优势:结合文本的精确空间信息和图像的丰富视觉特征,弥补单一模态的不足。
2. 视角自适应模块(PAM)
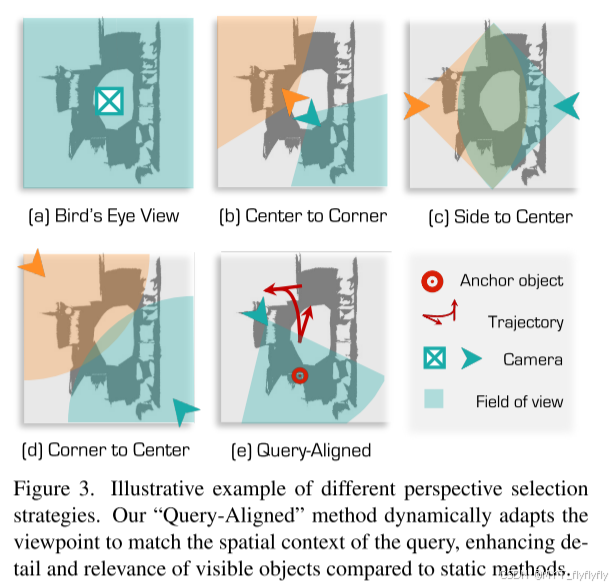
- 动态视角选择:根据文本查询中的锚点对象,调整摄像头位置和方向,利用look at view transform 函数生成RT向量
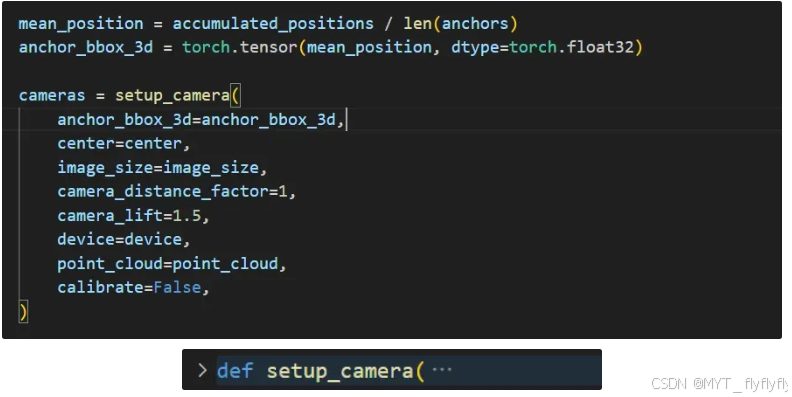
- 将场景点云渲染为与查询描述对齐的 2D 图像(基础渲染):

- 例如,若查询描述“窗户左侧的椅子”,模块会从窗户方向渲染场景,确保目标椅子可见。
3. 融合对齐模块:
深度感知视觉提示:在生成渲染图像I之后,从 OLT 中检索候选对象的边界框,将3D对象的可见点投影到2D图像,通过标记(如红色标识符)建立图像与文本的显式关联。利用深度信息解决遮挡问题,仅对可见点放置视觉提示,公式为:
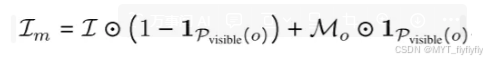
代码:
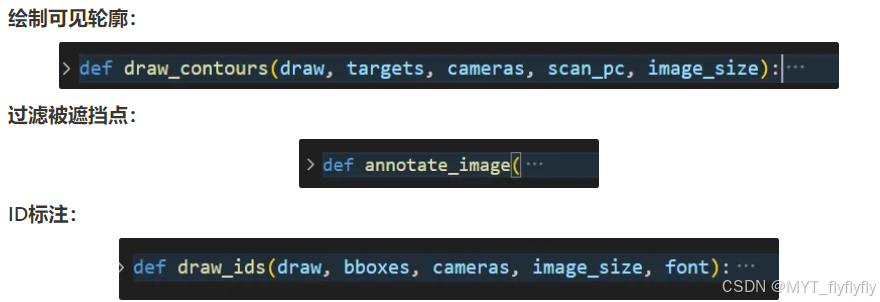
VLM:给定查询Q、带标注的渲染图像Im和场景的文本描述T,2D-VLM通过以下公式预测对象。将图像中的视觉特征与文本中的空间信息进行对齐

4. 零样本与开放词汇能力
- 无需3D数据训练,直接利用预训练的通义千问2进行推理。
- 支持开放词汇:通过文本描述和视觉特征的结合,识别未见过的物体类别。
实验部分:
数据集:
- ScanRefer:包含51,500条自然语言描述,覆盖800个ScanNet场景。
- Nr3D:通过游戏收集的41,503条高精度描述,区分“简单”和“复杂”场景。
性能对比:
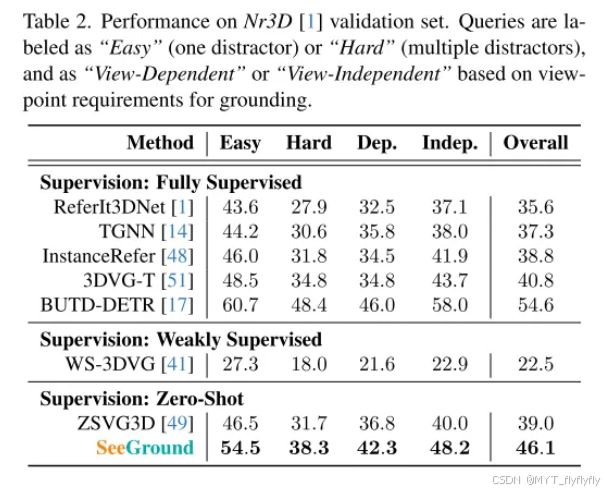
- ScanRefer:零样本方法中,SeeGround在Acc@0.25和Acc@0.5指标上分别超过基线7.7%和7.1%,接近全监督方法。

- Nr3D:总体准确率达46.1%,较基线提升18.2%,在视角依赖型任务中表现尤为突出。
消融实验:
-
移除视角适应模块(PAM)或融合对齐模块(FAM)分别导致性能下降3-5%。
-
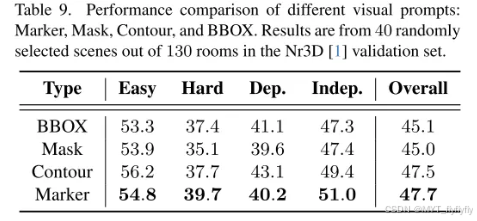
视觉提示(如标记)相比掩码或边界框,减少干扰并提升定位精度。

鲁棒性评估:
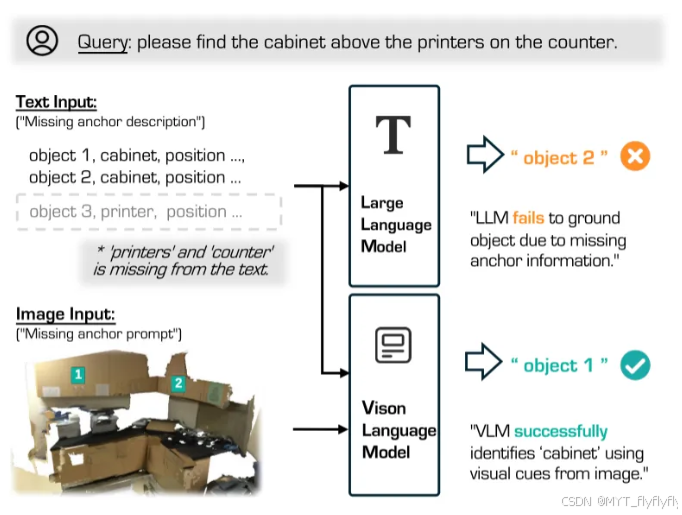
- 实验设计:随机省略文本中的关键信息(如锚点物体“打印机”)。
- 结果:SeeGround通过视觉线索(如图像中的打印机)仍能准确定位,而纯文本方法(如LLM-Grounder)性能显著下降。
- 示例:
- 尝试定位目标物体:在 “请找到打印机上方的柜子” 这一查询任务中,文本输入被刻意去除了 “打印机” 和 “柜台” 等关键信息,仅提供物体类别及其位置信息。
- 仅依赖文本推理的 LLM 由于无法获取必要的上下文信息,错误地匹配到了错误的柜子。而 SeeGround 通过 VLM 结合视觉信息成功识别出图像中的打印机,并准确定位其上方的柜子。
补充内容:
视觉属性的扩展定义
在正文中,视觉属性(如颜色、纹理、形状等)被简要提及,附录中进一步细化了这些属性的定义和实际应用场景。以下是关键扩展内容:

视觉提示类型的分析
对视觉提示的设计进行了分析
蒙版:
它直观地突出显示了整个物体表面。但是,即使透明度很高,它也会遮挡表面细节,例如纹理和细粒度图案,而这些细节对于区分物体至关重要。
BBOX:
它清楚地定义了边界,但由于边界框线的叠加而引入了视觉复杂性。这些线条通常会遮挡表面特征(颜色或纹理)。
标记:
它提供了最简约和最集中的设计,标记了物体中心,而不会引入视觉混乱或遮挡外观特征。这最大限度地保留了物体的细节,例如纹理和颜色,同时提供了必要的空间信息。

贡献与局限性
贡献:
- 零样本框架:无需3D标注数据,利用2D-VLMs实现开放词汇3D定位。
- 动态视角与视觉提示:增强模型对复杂场景的适应性。
- 高效性:通过OLT预存对象信息,避免重复计算。
局限性:
- 依赖3D检测的准确性:预处理中的检测错误会传递至后续模块。
- 复杂场景处理:密集或动态场景中,视觉提示可能失效。
- 渲染质量影响:低质量点云可能导致图像与空间信息不匹配。
未来方向
- 鲁棒性提升:改进3D检测和渲染的稳定性,减少噪声影响。
- 实时性优化:加速动态视角选择与渲染流程,适应实时应用。
- 多模态融合增强:探索更精细的视觉-文本对齐机制,如引入3D感知的视觉编码器。